1/* Copyright 2019 The TensorFlow Authors. All Rights Reserved. 2 3Licensed under the Apache License, Version 2.0 (the "License"); 4you may not use this file except in compliance with the License. 5You may obtain a copy of the License at 6 7 http://www.apache.org/licenses/LICENSE-2.0 8 9Unless required by applicable law or agreed to in writing, software 10distributed under the License is distributed on an "AS IS" BASIS, 11WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12See the License for the specific language governing permissions and 13limitations under the License. 14==============================================================================*/ 15 16// This is the auto-generated operation definition file for TensorFlow. 17// 18// PLEASE DO NOT MANUALLY EDIT THIS FILE! 19// 20// If you absolutely need to modify the generated fields of an op, move the op 21// definition to `tf_ops.td` and perform the modification there. 22// 23// This file contains TensorFlow ops whose definitions are programmatically 24// generated from the TF op registration and the api-def-files in the following 25// folder: 26// tensorflow/core/api_def/base_api 27// The generated fields for an op include name, summary, description, traits, 28// arguments, results, derived attributes. Therefore, modifications to these 29// fields will NOT be respected upon subsequent refreshes. However, additional 30// fields after those fields will be retained. 31// 32// Ops in this file are sorted alphabetically. 33 34include "tensorflow/compiler/mlir/tensorflow/ir/tf_op_base.td" 35include "mlir/Interfaces/CallInterfaces.td" 36include "mlir/Interfaces/InferTypeOpInterface.td" 37include "mlir/IR/OpAsmInterface.td" 38include "mlir/IR/SymbolInterfaces.td" 39 40def TF_AbsOp : TF_Op<"Abs", [Idempotent, NoSideEffect, SameOperandsAndResultType]> { 41 let summary = "Computes the absolute value of a tensor."; 42 43 let description = [{ 44Given a tensor `x`, this operation returns a tensor containing the absolute 45value of each element in `x`. For example, if x is an input element and y is 46an output element, this operation computes \\(y = |x|\\). 47 }]; 48 49 let arguments = (ins 50 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x 51 ); 52 53 let results = (outs 54 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 55 ); 56 57 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 58 59 let extraClassDeclaration = [{ 60 static bool isCompatibleReturnTypes(TypeRange inferred, TypeRange actual) { 61 return ArraysAreCastCompatible(inferred, actual); 62 } 63 }]; 64} 65 66def TF_AcosOp : TF_Op<"Acos", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 67 let summary = "Computes acos of x element-wise."; 68 69 let description = [{ 70Provided an input tensor, the `tf.math.acos` operation returns the inverse cosine of each element of the tensor. If `y = tf.math.cos(x)` then, `x = tf.math.acos(y)`. 71 72 Input range is `[-1, 1]` and the output has a range of `[0, pi]`. 73 }]; 74 75 let arguments = (ins 76 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x 77 ); 78 79 let results = (outs 80 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 81 ); 82 83 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 84} 85 86def TF_AcoshOp : TF_Op<"Acosh", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 87 let summary = "Computes inverse hyperbolic cosine of x element-wise."; 88 89 let description = [{ 90Given an input tensor, the function computes inverse hyperbolic cosine of every element. 91Input range is `[1, inf]`. It returns `nan` if the input lies outside the range. 92 93```python 94x = tf.constant([-2, -0.5, 1, 1.2, 200, 10000, float("inf")]) 95tf.math.acosh(x) ==> [nan nan 0. 0.62236255 5.9914584 9.903487 inf] 96``` 97 }]; 98 99 let arguments = (ins 100 TF_FpOrComplexTensor:$x 101 ); 102 103 let results = (outs 104 TF_FpOrComplexTensor:$y 105 ); 106 107 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 108} 109 110def TF_AddOp : TF_Op<"Add", [NoSideEffect, ResultsBroadcastableShape, TF_LayoutAgnostic, TF_SameOperandsAndResultElementTypeResolveRef]>, 111 WithBroadcastableBinOpBuilder { 112 let summary = "Returns x + y element-wise."; 113 114 let description = [{ 115*NOTE*: `Add` supports broadcasting. `AddN` does not. More about broadcasting 116[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 117 118Given two input tensors, the `tf.add` operation computes the sum for every element in the tensor. 119 120Both input and output have a range `(-inf, inf)`. 121 }]; 122 123 let arguments = (ins 124 TF_NumberNotQuantizedOrStrTensor:$x, 125 TF_NumberNotQuantizedOrStrTensor:$y 126 ); 127 128 let results = (outs 129 TF_NumberNotQuantizedOrStrTensor:$z 130 ); 131 132 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 133 134 let hasCanonicalizer = 1; 135} 136 137def TF_AddNOp : TF_Op<"AddN", [Commutative, NoSideEffect]> { 138 let summary = "Add all input tensors element wise."; 139 140 let description = [{ 141Inputs must be of same size and shape. 142 143 ```python 144 x = [9, 7, 10] 145 tf.math.add_n(x) ==> 26 146 ``` 147 }]; 148 149 let arguments = (ins 150 Variadic<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8, TF_Variant]>>:$inputs 151 ); 152 153 let results = (outs 154 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8, TF_Variant]>:$sum 155 ); 156 157 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 158 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 159 160 let hasFolder = 1; 161} 162 163def TF_AddV2Op : TF_Op<"AddV2", [Commutative, NoSideEffect, ResultsBroadcastableShape, TF_CwiseBinary, TF_LayoutAgnostic, TF_SameOperandsAndResultElementTypeResolveRef]>, 164 WithBroadcastableBinOpBuilder { 165 let summary = "Returns x + y element-wise."; 166 167 let description = [{ 168*NOTE*: `Add` supports broadcasting. `AddN` does not. More about broadcasting 169[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 170 }]; 171 172 let arguments = (ins 173 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$x, 174 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$y 175 ); 176 177 let results = (outs 178 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$z 179 ); 180 181 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 182 183 let hasCanonicalizer = 1; 184 185 let hasFolder = 1; 186} 187 188def TF_AdjustContrastv2Op : TF_Op<"AdjustContrastv2", [NoSideEffect]> { 189 let summary = "Adjust the contrast of one or more images."; 190 191 let description = [{ 192`images` is a tensor of at least 3 dimensions. The last 3 dimensions are 193interpreted as `[height, width, channels]`. The other dimensions only 194represent a collection of images, such as `[batch, height, width, channels].` 195 196Contrast is adjusted independently for each channel of each image. 197 198For each channel, the Op first computes the mean of the image pixels in the 199channel and then adjusts each component of each pixel to 200`(x - mean) * contrast_factor + mean`. 201 }]; 202 203 let arguments = (ins 204 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{Images to adjust. At least 3-D.}]>:$images, 205 Arg<TF_Float32Tensor, [{A float multiplier for adjusting contrast.}]>:$contrast_factor 206 ); 207 208 let results = (outs 209 Res<TensorOf<[TF_Float16, TF_Float32]>, [{The contrast-adjusted image or images.}]>:$output 210 ); 211 212 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 213} 214 215def TF_AdjustHueOp : TF_Op<"AdjustHue", [NoSideEffect]> { 216 let summary = "Adjust the hue of one or more images."; 217 218 let description = [{ 219`images` is a tensor of at least 3 dimensions. The last dimension is 220interpreted as channels, and must be three. 221 222The input image is considered in the RGB colorspace. Conceptually, the RGB 223colors are first mapped into HSV. A delta is then applied all the hue values, 224and then remapped back to RGB colorspace. 225 }]; 226 227 let arguments = (ins 228 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{Images to adjust. At least 3-D.}]>:$images, 229 Arg<TF_Float32Tensor, [{A float delta to add to the hue.}]>:$delta 230 ); 231 232 let results = (outs 233 Res<TensorOf<[TF_Float16, TF_Float32]>, [{The hue-adjusted image or images.}]>:$output 234 ); 235 236 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 237} 238 239def TF_AdjustSaturationOp : TF_Op<"AdjustSaturation", [NoSideEffect]> { 240 let summary = "Adjust the saturation of one or more images."; 241 242 let description = [{ 243`images` is a tensor of at least 3 dimensions. The last dimension is 244interpreted as channels, and must be three. 245 246The input image is considered in the RGB colorspace. Conceptually, the RGB 247colors are first mapped into HSV. A scale is then applied all the saturation 248values, and then remapped back to RGB colorspace. 249 }]; 250 251 let arguments = (ins 252 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{Images to adjust. At least 3-D.}]>:$images, 253 Arg<TF_Float32Tensor, [{A float scale to add to the saturation.}]>:$scale 254 ); 255 256 let results = (outs 257 Res<TensorOf<[TF_Float16, TF_Float32]>, [{The hue-adjusted image or images.}]>:$output 258 ); 259 260 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 261} 262 263def TF_AllOp : TF_Op<"All", [NoSideEffect]> { 264 let summary = [{ 265Computes the "logical and" of elements across dimensions of a tensor. 266 }]; 267 268 let description = [{ 269Reduces `input` along the dimensions given in `axis`. Unless 270`keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in 271`axis`. If `keep_dims` is true, the reduced dimensions are 272retained with length 1. 273 }]; 274 275 let arguments = (ins 276 Arg<TF_BoolTensor, [{The tensor to reduce.}]>:$input, 277 Arg<TF_I32OrI64Tensor, [{The dimensions to reduce. Must be in the range 278`[-rank(input), rank(input))`.}]>:$reduction_indices, 279 280 DefaultValuedAttr<BoolAttr, "false">:$keep_dims 281 ); 282 283 let results = (outs 284 Res<TF_BoolTensor, [{The reduced tensor.}]>:$output 285 ); 286 287 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 288 289 let hasVerifier = 1; 290} 291 292def TF_AllToAllOp : TF_Op<"AllToAll", [NoSideEffect, TF_NoConstantFold]> { 293 let summary = "An Op to exchange data across TPU replicas."; 294 295 let description = [{ 296On each replica, the input is split into `split_count` blocks along 297`split_dimension` and send to the other replicas given group_assignment. After 298receiving `split_count` - 1 blocks from other replicas, we concatenate the 299blocks along `concat_dimension` as the output. 300 301For example, suppose there are 2 TPU replicas: 302replica 0 receives input: `[[A, B]]` 303replica 1 receives input: `[[C, D]]` 304 305group_assignment=`[[0, 1]]` 306concat_dimension=0 307split_dimension=1 308split_count=2 309 310replica 0's output: `[[A], [C]]` 311replica 1's output: `[[B], [D]]` 312 }]; 313 314 let arguments = (ins 315 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The local input to the sum.}]>:$input, 316 Arg<TF_Int32Tensor, [{An int32 tensor with shape 317[num_groups, num_replicas_per_group]. `group_assignment[i]` represents the 318replica ids in the ith subgroup.}]>:$group_assignment, 319 320 I64Attr:$concat_dimension, 321 I64Attr:$split_dimension, 322 I64Attr:$split_count 323 ); 324 325 let results = (outs 326 Res<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The exchanged result.}]>:$output 327 ); 328 329 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 330} 331 332def TF_AngleOp : TF_Op<"Angle", [NoSideEffect, SameOperandsAndResultShape]> { 333 let summary = "Returns the argument of a complex number."; 334 335 let description = [{ 336Given a tensor `input` of complex numbers, this operation returns a tensor of 337type `float` that is the argument of each element in `input`. All elements in 338`input` must be complex numbers of the form \\(a + bj\\), where *a* 339is the real part and *b* is the imaginary part. 340 341The argument returned by this operation is of the form \\(atan2(b, a)\\). 342 343For example: 344 345``` 346# tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] 347tf.angle(input) ==> [2.0132, 1.056] 348``` 349 350@compatibility(numpy) 351Equivalent to np.angle. 352@end_compatibility 353 }]; 354 355 let arguments = (ins 356 TensorOf<[TF_Complex128, TF_Complex64]>:$input 357 ); 358 359 let results = (outs 360 TF_F32OrF64Tensor:$output 361 ); 362 363 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 364 TF_DerivedResultTypeAttr Tout = TF_DerivedResultTypeAttr<0>; 365} 366 367def TF_AnonymousIteratorOp : TF_Op<"AnonymousIterator", [TF_UniqueResourceAllocation]> { 368 let summary = "A container for an iterator resource."; 369 370 let arguments = (ins 371 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 372 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 373 ); 374 375 let results = (outs 376 Res<TF_ResourceTensor, [{A handle to the iterator that can be passed to a "MakeIterator" or 377"IteratorGetNext" op. In contrast to Iterator, AnonymousIterator prevents 378resource sharing by name, and does not keep a reference to the resource 379container.}], [TF_DatasetIteratorAlloc]>:$handle 380 ); 381} 382 383def TF_AnonymousIteratorV2Op : TF_Op<"AnonymousIteratorV2", [TF_UniqueResourceAllocation]> { 384 let summary = "A container for an iterator resource."; 385 386 let arguments = (ins 387 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 388 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 389 ); 390 391 let results = (outs 392 Res<TF_ResourceTensor, [{A handle to the iterator that can be passed to a "MakeIterator" or 393"IteratorGetNext" op. In contrast to Iterator, AnonymousIterator prevents 394resource sharing by name, and does not keep a reference to the resource 395container.}], [TF_DatasetIteratorAlloc]>:$handle, 396 Res<TF_VariantTensor, [{A variant deleter that should be passed into the op that deletes the iterator.}]>:$deleter 397 ); 398} 399 400def TF_AnonymousIteratorV3Op : TF_Op<"AnonymousIteratorV3", [TF_UniqueResourceAllocation]> { 401 let summary = "A container for an iterator resource."; 402 403 let arguments = (ins 404 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 405 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 406 ); 407 408 let results = (outs 409 Res<TF_ResourceTensor, [{A handle to the iterator that can be passed to a "MakeIterator" or 410"IteratorGetNext" op. In contrast to Iterator, AnonymousIterator prevents 411resource sharing by name, and does not keep a reference to the resource 412container.}], [TF_DatasetIteratorAlloc]>:$handle 413 ); 414} 415 416def TF_AnonymousMemoryCacheOp : TF_Op<"AnonymousMemoryCache", [TF_UniqueResourceAllocation]> { 417 let summary = ""; 418 419 let arguments = (ins); 420 421 let results = (outs 422 Res<TF_ResourceTensor, "", [TF_DatasetMemoryCacheAlloc]>:$handle, 423 TF_VariantTensor:$deleter 424 ); 425} 426 427def TF_AnonymousMultiDeviceIteratorOp : TF_Op<"AnonymousMultiDeviceIterator", [TF_UniqueResourceAllocation]> { 428 let summary = "A container for a multi device iterator resource."; 429 430 let arguments = (ins 431 ConfinedAttr<StrArrayAttr, [ArrayMinCount<1>]>:$devices, 432 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 433 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 434 ); 435 436 let results = (outs 437 Res<TF_ResourceTensor, [{A handle to a multi device iterator that can be passed to a 438"MultiDeviceIteratorGetNextFromShard" op. In contrast to MultiDeviceIterator, 439AnonymousIterator prevents resource sharing by name, and does not keep a 440reference to the resource container.}], [TF_DatasetIteratorAlloc]>:$handle, 441 Res<TF_VariantTensor, [{A variant deleter that should be passed into the op that deletes the iterator.}]>:$deleter 442 ); 443} 444 445def TF_AnonymousMultiDeviceIteratorV3Op : TF_Op<"AnonymousMultiDeviceIteratorV3", [TF_UniqueResourceAllocation]> { 446 let summary = "A container for a multi device iterator resource."; 447 448 let arguments = (ins 449 ConfinedAttr<StrArrayAttr, [ArrayMinCount<1>]>:$devices, 450 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 451 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 452 ); 453 454 let results = (outs 455 Res<TF_ResourceTensor, [{A handle to a multi device iterator that can be passed to a 456"MultiDeviceIteratorGetNextFromShard" op. In contrast to MultiDeviceIterator, 457AnonymousIterator prevents resource sharing by name, and does not keep a 458reference to the resource container.}], [TF_DatasetIteratorAlloc]>:$handle 459 ); 460} 461 462def TF_AnonymousRandomSeedGeneratorOp : TF_Op<"AnonymousRandomSeedGenerator", [TF_UniqueResourceAllocation]> { 463 let summary = ""; 464 465 let arguments = (ins 466 TF_Int64Tensor:$seed, 467 TF_Int64Tensor:$seed2 468 ); 469 470 let results = (outs 471 Res<TF_ResourceTensor, "", [TF_DatasetSeedGeneratorAlloc]>:$handle, 472 TF_VariantTensor:$deleter 473 ); 474} 475 476def TF_AnonymousSeedGeneratorOp : TF_Op<"AnonymousSeedGenerator", [TF_UniqueResourceAllocation]> { 477 let summary = ""; 478 479 let arguments = (ins 480 TF_Int64Tensor:$seed, 481 TF_Int64Tensor:$seed2, 482 TF_BoolTensor:$reshuffle 483 ); 484 485 let results = (outs 486 Res<TF_ResourceTensor, "", [TF_DatasetSeedGeneratorAlloc]>:$handle, 487 TF_VariantTensor:$deleter 488 ); 489} 490 491def TF_AnyOp : TF_Op<"Any", [NoSideEffect]> { 492 let summary = [{ 493Computes the "logical or" of elements across dimensions of a tensor. 494 }]; 495 496 let description = [{ 497Reduces `input` along the dimensions given in `axis`. Unless 498`keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in 499`axis`. If `keep_dims` is true, the reduced dimensions are 500retained with length 1. 501 }]; 502 503 let arguments = (ins 504 Arg<TF_BoolTensor, [{The tensor to reduce.}]>:$input, 505 Arg<TF_I32OrI64Tensor, [{The dimensions to reduce. Must be in the range 506`[-rank(input), rank(input))`.}]>:$reduction_indices, 507 508 DefaultValuedAttr<BoolAttr, "false">:$keep_dims 509 ); 510 511 let results = (outs 512 Res<TF_BoolTensor, [{The reduced tensor.}]>:$output 513 ); 514 515 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 516 517 let hasVerifier = 1; 518} 519 520def TF_ApproxTopKOp : TF_Op<"ApproxTopK", [NoSideEffect]> { 521 let summary = [{ 522Returns min/max k values and their indices of the input operand in an approximate manner. 523 }]; 524 525 let description = [{ 526See https://arxiv.org/abs/2206.14286 for the algorithm details. 527This op is only optimized on TPU currently. 528 }]; 529 530 let arguments = (ins 531 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{Array to search. Must be at least 1-D of the floating type}]>:$input, 532 533 ConfinedAttr<I64Attr, [IntMinValue<0>]>:$k, 534 DefaultValuedAttr<I64Attr, "-1">:$reduction_dimension, 535 DefaultValuedAttr<F32Attr, "0.95f">:$recall_target, 536 DefaultValuedAttr<BoolAttr, "true">:$is_max_k, 537 DefaultValuedAttr<I64Attr, "-1">:$reduction_input_size_override, 538 DefaultValuedAttr<BoolAttr, "true">:$aggregate_to_topk 539 ); 540 541 let results = (outs 542 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{The min/max k values along the `reduction_dimension` of the `input` operand. 543The dimension are the same as the `input` operand except for the 544`reduction_dimension`: when `aggregate_to_topk` is true, the reduction 545dimension is `k`; otherwise, it is greater equals to `k` where the size is 546implementation-defined.}]>:$values, 547 Res<TF_Int32Tensor, [{The indices of `values` along the `reduction_dimension` of the `input` operand.}]>:$indices 548 ); 549 550 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 551} 552 553def TF_ApproximateEqualOp : TF_Op<"ApproximateEqual", [Commutative, NoSideEffect]> { 554 let summary = "Returns the truth value of abs(x-y) < tolerance element-wise."; 555 556 let arguments = (ins 557 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$x, 558 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$y, 559 560 DefaultValuedAttr<F32Attr, "1e-05f">:$tolerance 561 ); 562 563 let results = (outs 564 TF_BoolTensor:$z 565 ); 566 567 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 568} 569 570def TF_ArgMaxOp : TF_Op<"ArgMax", [NoSideEffect]> { 571 let summary = [{ 572Returns the index with the largest value across dimensions of a tensor. 573 }]; 574 575 let description = [{ 576Note that in case of ties the identity of the return value is not guaranteed. 577 578Usage: 579 ```python 580 import tensorflow as tf 581 a = [1, 10, 26.9, 2.8, 166.32, 62.3] 582 b = tf.math.argmax(input = a) 583 c = tf.keras.backend.eval(b) 584 # c = 4 585 # here a[4] = 166.32 which is the largest element of a across axis 0 586 ``` 587 }]; 588 589 let arguments = (ins 590 TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$input, 591 Arg<TensorOf<[TF_Int16, TF_Int32, TF_Int64]>, [{int16, int32 or int64, must be in the range `[-rank(input), rank(input))`. 592Describes which dimension of the input Tensor to reduce across. For vectors, 593use dimension = 0.}]>:$dimension 594 ); 595 596 let results = (outs 597 TensorOf<[TF_Int16, TF_Int32, TF_Int64, TF_Uint16]>:$output 598 ); 599 600 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 601 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 602 TF_DerivedResultTypeAttr output_type = TF_DerivedResultTypeAttr<0>; 603} 604 605def TF_ArgMinOp : TF_Op<"ArgMin", [NoSideEffect]> { 606 let summary = [{ 607Returns the index with the smallest value across dimensions of a tensor. 608 }]; 609 610 let description = [{ 611Note that in case of ties the identity of the return value is not guaranteed. 612 613Usage: 614 ```python 615 import tensorflow as tf 616 a = [1, 10, 26.9, 2.8, 166.32, 62.3] 617 b = tf.math.argmin(input = a) 618 c = tf.keras.backend.eval(b) 619 # c = 0 620 # here a[0] = 1 which is the smallest element of a across axis 0 621 ``` 622 }]; 623 624 let arguments = (ins 625 TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$input, 626 Arg<TF_I32OrI64Tensor, [{int32 or int64, must be in the range `[-rank(input), rank(input))`. 627Describes which dimension of the input Tensor to reduce across. For vectors, 628use dimension = 0.}]>:$dimension 629 ); 630 631 let results = (outs 632 TF_I32OrI64Tensor:$output 633 ); 634 635 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 636 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 637 TF_DerivedResultTypeAttr output_type = TF_DerivedResultTypeAttr<0>; 638} 639 640def TF_AsStringOp : TF_Op<"AsString", [NoSideEffect, SameOperandsAndResultShape]> { 641 let summary = "Converts each entry in the given tensor to strings."; 642 643 let description = [{ 644Supports many numeric types and boolean. 645 646For Unicode, see the 647[https://www.tensorflow.org/tutorials/representation/unicode](Working with Unicode text) 648tutorial. 649 650Examples: 651 652>>> tf.strings.as_string([3, 2]) 653<tf.Tensor: shape=(2,), dtype=string, numpy=array([b'3', b'2'], dtype=object)> 654>>> tf.strings.as_string([3.1415926, 2.71828], precision=2).numpy() 655array([b'3.14', b'2.72'], dtype=object) 656 }]; 657 658 let arguments = (ins 659 TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8, TF_Variant]>:$input, 660 661 DefaultValuedAttr<I64Attr, "-1">:$precision, 662 DefaultValuedAttr<BoolAttr, "false">:$scientific, 663 DefaultValuedAttr<BoolAttr, "false">:$shortest, 664 DefaultValuedAttr<I64Attr, "-1">:$width, 665 DefaultValuedAttr<StrAttr, "\"\"">:$fill 666 ); 667 668 let results = (outs 669 TF_StrTensor:$output 670 ); 671 672 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 673} 674 675def TF_AsinOp : TF_Op<"Asin", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 676 let summary = "Computes the trignometric inverse sine of x element-wise."; 677 678 let description = [{ 679The `tf.math.asin` operation returns the inverse of `tf.math.sin`, such that 680if `y = tf.math.sin(x)` then, `x = tf.math.asin(y)`. 681 682**Note**: The output of `tf.math.asin` will lie within the invertible range 683of sine, i.e [-pi/2, pi/2]. 684 685For example: 686 687```python 688# Note: [1.047, 0.785] ~= [(pi/3), (pi/4)] 689x = tf.constant([1.047, 0.785]) 690y = tf.math.sin(x) # [0.8659266, 0.7068252] 691 692tf.math.asin(y) # [1.047, 0.785] = x 693``` 694 }]; 695 696 let arguments = (ins 697 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x 698 ); 699 700 let results = (outs 701 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 702 ); 703 704 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 705} 706 707def TF_AsinhOp : TF_Op<"Asinh", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 708 let summary = "Computes inverse hyperbolic sine of x element-wise."; 709 710 let description = [{ 711Given an input tensor, this function computes inverse hyperbolic sine 712 for every element in the tensor. Both input and output has a range of 713 `[-inf, inf]`. 714 715 ```python 716 x = tf.constant([-float("inf"), -2, -0.5, 1, 1.2, 200, 10000, float("inf")]) 717 tf.math.asinh(x) ==> [-inf -1.4436355 -0.4812118 0.8813736 1.0159732 5.991471 9.903487 inf] 718 ``` 719 }]; 720 721 let arguments = (ins 722 TF_FpOrComplexTensor:$x 723 ); 724 725 let results = (outs 726 TF_FpOrComplexTensor:$y 727 ); 728 729 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 730} 731 732def TF_AssertOp : TF_Op<"Assert", []> { 733 let summary = "Asserts that the given condition is true."; 734 735 let description = [{ 736If `condition` evaluates to false, print the list of tensors in `data`. 737`summarize` determines how many entries of the tensors to print. 738 }]; 739 740 let arguments = (ins 741 Arg<TF_BoolTensor, [{The condition to evaluate.}]>:$condition, 742 Arg<Variadic<TF_Tensor>, [{The tensors to print out when condition is false.}]>:$data, 743 744 DefaultValuedAttr<I64Attr, "3">:$summarize 745 ); 746 747 let results = (outs); 748 749 TF_DerivedOperandTypeListAttr T = TF_DerivedOperandTypeListAttr<1>; 750 751 let hasCanonicalizer = 1; 752} 753 754def TF_AssignOp : TF_Op<"Assign", []> { 755 let summary = "Update 'ref' by assigning 'value' to it."; 756 757 let description = [{ 758This operation outputs "ref" after the assignment is done. 759This makes it easier to chain operations that need to use the reset value. 760 }]; 761 762 let arguments = (ins 763 Arg<TF_Tensor, [{Should be from a `Variable` node. May be uninitialized.}]>:$ref, 764 Arg<TF_Tensor, [{The value to be assigned to the variable.}]>:$value, 765 766 DefaultValuedAttr<BoolAttr, "true">:$validate_shape, 767 DefaultValuedAttr<BoolAttr, "true">:$use_locking 768 ); 769 770 let results = (outs 771 Res<TF_Tensor, [{= Same as "ref". Returned as a convenience for operations that want 772to use the new value after the variable has been reset.}]>:$output_ref 773 ); 774 775 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 776} 777 778def TF_AssignAddVariableOp : TF_Op<"AssignAddVariableOp", []> { 779 let summary = "Adds a value to the current value of a variable."; 780 781 let description = [{ 782Any ReadVariableOp with a control dependency on this op is guaranteed to 783see the incremented value or a subsequent newer one. 784 }]; 785 786 let arguments = (ins 787 Arg<TF_ResourceTensor, [{handle to the resource in which to store the variable.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 788 Arg<TF_Tensor, [{the value by which the variable will be incremented.}]>:$value 789 ); 790 791 let results = (outs); 792 793 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<1>; 794} 795 796def TF_AssignSubVariableOp : TF_Op<"AssignSubVariableOp", []> { 797 let summary = "Subtracts a value from the current value of a variable."; 798 799 let description = [{ 800Any ReadVariableOp with a control dependency on this op is guaranteed to 801see the decremented value or a subsequent newer one. 802 }]; 803 804 let arguments = (ins 805 Arg<TF_ResourceTensor, [{handle to the resource in which to store the variable.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 806 Arg<TF_Tensor, [{the value by which the variable will be incremented.}]>:$value 807 ); 808 809 let results = (outs); 810 811 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<1>; 812} 813 814def TF_AssignVariableOp : TF_Op<"AssignVariableOp", []> { 815 let summary = "Assigns a new value to a variable."; 816 817 let description = [{ 818Any ReadVariableOp with a control dependency on this op is guaranteed to return 819this value or a subsequent newer value of the variable. 820 }]; 821 822 let arguments = (ins 823 Arg<TF_ResourceTensor, [{handle to the resource in which to store the variable.}], [TF_VariableWrite]>:$resource, 824 Arg<TF_Tensor, [{the value to set the new tensor to use.}]>:$value, 825 826 DefaultValuedAttr<BoolAttr, "false">:$validate_shape 827 ); 828 829 let results = (outs); 830 831 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<1>; 832} 833 834def TF_AtanOp : TF_Op<"Atan", [NoSideEffect, SameOperandsAndResultType]> { 835 let summary = "Computes the trignometric inverse tangent of x element-wise."; 836 837 let description = [{ 838The `tf.math.atan` operation returns the inverse of `tf.math.tan`, such that 839if `y = tf.math.tan(x)` then, `x = tf.math.atan(y)`. 840 841**Note**: The output of `tf.math.atan` will lie within the invertible range 842of tan, i.e (-pi/2, pi/2). 843 844For example: 845 846```python 847# Note: [1.047, 0.785] ~= [(pi/3), (pi/4)] 848x = tf.constant([1.047, 0.785]) 849y = tf.math.tan(x) # [1.731261, 0.99920404] 850 851tf.math.atan(y) # [1.047, 0.785] = x 852``` 853 }]; 854 855 let arguments = (ins 856 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x 857 ); 858 859 let results = (outs 860 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 861 ); 862 863 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 864} 865 866def TF_Atan2Op : TF_Op<"Atan2", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 867 WithBroadcastableBinOpBuilder { 868 let summary = [{ 869Computes arctangent of `y/x` element-wise, respecting signs of the arguments. 870 }]; 871 872 let description = [{ 873This is the angle \\( \theta \in [-\pi, \pi] \\) such that 874\\[ x = r \cos(\theta) \\] 875and 876\\[ y = r \sin(\theta) \\] 877where \\(r = \sqrt{x^2 + y^2} \\). 878 879For example: 880 881>>> x = [1., 1.] 882>>> y = [1., -1.] 883>>> print((tf.math.atan2(y,x) * (180 / np.pi)).numpy()) 884[ 45. -45.] 885 }]; 886 887 let arguments = (ins 888 TF_FloatTensor:$y, 889 TF_FloatTensor:$x 890 ); 891 892 let results = (outs 893 TF_FloatTensor:$z 894 ); 895 896 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 897} 898 899def TF_AtanhOp : TF_Op<"Atanh", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 900 let summary = "Computes inverse hyperbolic tangent of x element-wise."; 901 902 let description = [{ 903Given an input tensor, this function computes inverse hyperbolic tangent 904 for every element in the tensor. Input range is `[-1,1]` and output range is 905 `[-inf, inf]`. If input is `-1`, output will be `-inf` and if the 906 input is `1`, output will be `inf`. Values outside the range will have 907 `nan` as output. 908 909 ```python 910 x = tf.constant([-float("inf"), -1, -0.5, 1, 0, 0.5, 10, float("inf")]) 911 tf.math.atanh(x) ==> [nan -inf -0.54930615 inf 0. 0.54930615 nan nan] 912 ``` 913 }]; 914 915 let arguments = (ins 916 TF_FpOrComplexTensor:$x 917 ); 918 919 let results = (outs 920 TF_FpOrComplexTensor:$y 921 ); 922 923 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 924} 925 926def TF_AvgPoolOp : TF_Op<"AvgPool", [NoSideEffect]> { 927 let summary = "Performs average pooling on the input."; 928 929 let description = [{ 930Each entry in `output` is the mean of the corresponding size `ksize` 931window in `value`. 932 }]; 933 934 let arguments = (ins 935 Arg<TF_FloatTensor, [{4-D with shape `[batch, height, width, channels]`.}]>:$value, 936 937 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$ksize, 938 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$strides, 939 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 940 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format 941 ); 942 943 let results = (outs 944 Res<TF_FloatTensor, [{The average pooled output tensor.}]>:$output 945 ); 946 947 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 948} 949 950def TF_AvgPool3DOp : TF_Op<"AvgPool3D", [NoSideEffect]> { 951 let summary = "Performs 3D average pooling on the input."; 952 953 let description = [{ 954Each entry in `output` is the mean of the corresponding size `ksize` window in 955`value`. 956 }]; 957 958 let arguments = (ins 959 Arg<TF_FloatTensor, [{Shape `[batch, depth, rows, cols, channels]` tensor to pool over.}]>:$input, 960 961 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$ksize, 962 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$strides, 963 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 964 DefaultValuedAttr<TF_AnyStrAttrOf<["NDHWC", "NCDHW"]>, "\"NDHWC\"">:$data_format 965 ); 966 967 let results = (outs 968 Res<TF_FloatTensor, [{The average pooled output tensor.}]>:$output 969 ); 970 971 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 972} 973 974def TF_AvgPool3DGradOp : TF_Op<"AvgPool3DGrad", [NoSideEffect]> { 975 let summary = "Computes gradients of average pooling function."; 976 977 let arguments = (ins 978 Arg<TF_Int32Tensor, [{The original input dimensions.}]>:$orig_input_shape, 979 Arg<TF_FloatTensor, [{Output backprop of shape `[batch, depth, rows, cols, channels]`.}]>:$grad, 980 981 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$ksize, 982 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$strides, 983 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 984 DefaultValuedAttr<TF_AnyStrAttrOf<["NDHWC", "NCDHW"]>, "\"NDHWC\"">:$data_format 985 ); 986 987 let results = (outs 988 Res<TF_FloatTensor, [{The backprop for input.}]>:$output 989 ); 990 991 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 992} 993 994def TF_AvgPoolGradOp : TF_Op<"AvgPoolGrad", [NoSideEffect]> { 995 let summary = "Computes gradients of the average pooling function."; 996 997 let arguments = (ins 998 Arg<TF_Int32Tensor, [{1-D. Shape of the original input to `avg_pool`.}]>:$orig_input_shape, 999 Arg<TF_FloatTensor, [{4-D with shape `[batch, height, width, channels]`. Gradients w.r.t. 1000the output of `avg_pool`.}]>:$grad, 1001 1002 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$ksize, 1003 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$strides, 1004 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 1005 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format 1006 ); 1007 1008 let results = (outs 1009 Res<TF_FloatTensor, [{4-D. Gradients w.r.t. the input of `avg_pool`.}]>:$output 1010 ); 1011 1012 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 1013} 1014 1015def TF_BatchDatasetV2Op : TF_Op<"BatchDatasetV2", [NoSideEffect]> { 1016 let summary = [{ 1017Creates a dataset that batches `batch_size` elements from `input_dataset`. 1018 }]; 1019 1020 let arguments = (ins 1021 TF_VariantTensor:$input_dataset, 1022 Arg<TF_Int64Tensor, [{A scalar representing the number of elements to accumulate in a batch.}]>:$batch_size, 1023 Arg<TF_BoolTensor, [{A scalar representing whether the last batch should be dropped in case its size 1024is smaller than desired.}]>:$drop_remainder, 1025 1026 DefaultValuedAttr<BoolAttr, "false">:$parallel_copy, 1027 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 1028 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 1029 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 1030 ); 1031 1032 let results = (outs 1033 TF_VariantTensor:$handle 1034 ); 1035} 1036 1037def TF_BatchFunctionOp : TF_Op<"BatchFunction", [AttrSizedOperandSegments, NoSideEffect]> { 1038 let summary = [{ 1039Batches all the inputs tensors to the computation done by the function. 1040 }]; 1041 1042 let description = [{ 1043So, for example, in the following code 1044 1045 ```python 1046 1047 # This input will be captured. 1048 y = tf.placeholder_with_default(1.0, shape=[]) 1049 1050 @tf.Defun(tf.float32) 1051 def computation(a): 1052 return tf.matmul(a, a) + y 1053 1054 b = gen_batch_ops.batch_function( 1055 f=computation 1056 in_tensors=[a], 1057 captured_tensors=computation.captured_inputs, 1058 Tout=[o.type for o in computation.definition.signature.output_arg], 1059 num_batch_threads=1, 1060 max_batch_size=10, 1061 batch_timeout_micros=100000, # 100ms 1062 allowed_batch_sizes=[3, 10], 1063 batching_queue="") 1064 ``` 1065 1066If more than one session.run call is simultaneously trying to compute `b` 1067the values of `a` will be gathered, non-deterministically concatenated 1068along the first axis, and only one thread will run the computation. 1069 1070Assumes that all arguments of the function are Tensors which will be batched 1071along their first dimension. 1072 1073Arguments that are captured, are not batched. The session.run call which does 1074the concatenation, will use the values of the captured tensors available to it. 1075Therefore, typical uses of captured tensors should involve values which remain 1076unchanged across session.run calls. Inference is a good example of this. 1077 1078SparseTensor is not supported. The return value of the decorated function 1079must be a Tensor or a list/tuple of Tensors. 1080 }]; 1081 1082 let arguments = (ins 1083 Arg<Variadic<TF_Tensor>, [{The tensors to be batched.}]>:$in_tensors, 1084 Arg<Variadic<TF_Tensor>, [{The tensors which are captured in the function, and don't need 1085to be batched.}]>:$captured_tensors, 1086 1087 SymbolRefAttr:$f, 1088 I64Attr:$num_batch_threads, 1089 I64Attr:$max_batch_size, 1090 I64Attr:$batch_timeout_micros, 1091 DefaultValuedAttr<I64Attr, "10">:$max_enqueued_batches, 1092 DefaultValuedAttr<I64ArrayAttr, "{}">:$allowed_batch_sizes, 1093 DefaultValuedAttr<StrAttr, "\"\"">:$container, 1094 DefaultValuedAttr<StrAttr, "\"\"">:$shared_name, 1095 DefaultValuedAttr<StrAttr, "\"\"">:$batching_queue, 1096 DefaultValuedAttr<BoolAttr, "false">:$enable_large_batch_splitting 1097 ); 1098 1099 let results = (outs 1100 Res<Variadic<TF_Tensor>, [{The output tensors.}]>:$out_tensors 1101 ); 1102 1103 TF_DerivedOperandTypeListAttr Tcaptured = TF_DerivedOperandTypeListAttr<1>; 1104 TF_DerivedOperandTypeListAttr Tin = TF_DerivedOperandTypeListAttr<0>; 1105 TF_DerivedResultTypeListAttr Tout = TF_DerivedResultTypeListAttr<0>; 1106} 1107 1108def TF_BatchMatMulOp : TF_Op<"BatchMatMul", [NoSideEffect, TF_SameOperandsAndResultElementTypeResolveRef]> { 1109 let summary = "Multiplies slices of two tensors in batches."; 1110 1111 let description = [{ 1112Multiplies all slices of `Tensor` `x` and `y` (each slice can be 1113viewed as an element of a batch), and arranges the individual results 1114in a single output tensor of the same batch size. Each of the 1115individual slices can optionally be adjointed (to adjoint a matrix 1116means to transpose and conjugate it) before multiplication by setting 1117the `adj_x` or `adj_y` flag to `True`, which are by default `False`. 1118 1119The input tensors `x` and `y` are 2-D or higher with shape `[..., r_x, c_x]` 1120and `[..., r_y, c_y]`. 1121 1122The output tensor is 2-D or higher with shape `[..., r_o, c_o]`, where: 1123 1124 r_o = c_x if adj_x else r_x 1125 c_o = r_y if adj_y else c_y 1126 1127It is computed as: 1128 1129 output[..., :, :] = matrix(x[..., :, :]) * matrix(y[..., :, :]) 1130 }]; 1131 1132 let arguments = (ins 1133 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{2-D or higher with shape `[..., r_x, c_x]`.}]>:$x, 1134 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{2-D or higher with shape `[..., r_y, c_y]`.}]>:$y, 1135 1136 DefaultValuedAttr<BoolAttr, "false">:$adj_x, 1137 DefaultValuedAttr<BoolAttr, "false">:$adj_y 1138 ); 1139 1140 let results = (outs 1141 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{3-D or higher with shape `[..., r_o, c_o]`}]>:$output 1142 ); 1143 1144 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1145 1146 let hasCanonicalizer = 1; 1147 1148 let hasVerifier = 1; 1149} 1150 1151def TF_BatchMatMulV2Op : TF_Op<"BatchMatMulV2", [NoSideEffect, TF_SameOperandsAndResultElementTypeResolveRef]> { 1152 let summary = "Multiplies slices of two tensors in batches."; 1153 1154 let description = [{ 1155Multiplies all slices of `Tensor` `x` and `y` (each slice can be 1156viewed as an element of a batch), and arranges the individual results 1157in a single output tensor of the same batch size. Each of the 1158individual slices can optionally be adjointed (to adjoint a matrix 1159means to transpose and conjugate it) before multiplication by setting 1160the `adj_x` or `adj_y` flag to `True`, which are by default `False`. 1161 1162The input tensors `x` and `y` are 2-D or higher with shape `[..., r_x, c_x]` 1163and `[..., r_y, c_y]`. 1164 1165The output tensor is 2-D or higher with shape `[..., r_o, c_o]`, where: 1166 1167 r_o = c_x if adj_x else r_x 1168 c_o = r_y if adj_y else c_y 1169 1170It is computed as: 1171 1172 output[..., :, :] = matrix(x[..., :, :]) * matrix(y[..., :, :]) 1173 1174*NOTE*: `BatchMatMulV2` supports broadcasting in the batch dimensions. More 1175about broadcasting 1176[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html). 1177 }]; 1178 1179 let arguments = (ins 1180 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64]>, [{2-D or higher with shape `[..., r_x, c_x]`.}]>:$x, 1181 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64]>, [{2-D or higher with shape `[..., r_y, c_y]`.}]>:$y, 1182 1183 DefaultValuedAttr<BoolAttr, "false">:$adj_x, 1184 DefaultValuedAttr<BoolAttr, "false">:$adj_y 1185 ); 1186 1187 let results = (outs 1188 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64]>, [{3-D or higher with shape `[..., r_o, c_o]`}]>:$output 1189 ); 1190 1191 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1192 1193 let hasVerifier = 1; 1194 1195 let hasCanonicalizer = 1; 1196} 1197 1198def TF_BatchMatMulV3Op : TF_Op<"BatchMatMulV3", [NoSideEffect]> { 1199 let summary = "Multiplies slices of two tensors in batches."; 1200 1201 let description = [{ 1202Multiplies all slices of `Tensor` `x` and `y` (each slice can be 1203viewed as an element of a batch), and arranges the individual results 1204in a single output tensor of the same batch size. Each of the 1205individual slices can optionally be adjointed (to adjoint a matrix 1206means to transpose and conjugate it) before multiplication by setting 1207the `adj_x` or `adj_y` flag to `True`, which are by default `False`. 1208 1209The input tensors `x` and `y` are 2-D or higher with shape `[..., r_x, c_x]` 1210and `[..., r_y, c_y]`. 1211 1212The output tensor is 2-D or higher with shape `[..., r_o, c_o]`, where: 1213 1214 r_o = c_x if adj_x else r_x 1215 c_o = r_y if adj_y else c_y 1216 1217It is computed as: 1218 1219 output[..., :, :] = matrix(x[..., :, :]) * matrix(y[..., :, :]) 1220 1221*NOTE*: `BatchMatMulV3` supports broadcasting in the batch dimensions. More 1222about broadcasting 1223[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html). 1224 }]; 1225 1226 let arguments = (ins 1227 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint8]>, [{2-D or higher with shape `[..., r_x, c_x]`.}]>:$x, 1228 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint8]>, [{2-D or higher with shape `[..., r_y, c_y]`.}]>:$y, 1229 1230 DefaultValuedAttr<BoolAttr, "false">:$adj_x, 1231 DefaultValuedAttr<BoolAttr, "false">:$adj_y 1232 ); 1233 1234 let results = (outs 1235 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64]>, [{3-D or higher with shape `[..., r_o, c_o]`}]>:$output 1236 ); 1237 1238 TF_DerivedOperandTypeAttr Ta = TF_DerivedOperandTypeAttr<0>; 1239 TF_DerivedOperandTypeAttr Tb = TF_DerivedOperandTypeAttr<1>; 1240 TF_DerivedResultTypeAttr Tout = TF_DerivedResultTypeAttr<0>; 1241} 1242 1243def TF_BatchNormWithGlobalNormalizationOp : TF_Op<"BatchNormWithGlobalNormalization", [NoSideEffect]> { 1244 let summary = "Batch normalization."; 1245 1246 let description = [{ 1247This op is deprecated. Prefer `tf.nn.batch_normalization`. 1248 }]; 1249 1250 let arguments = (ins 1251 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A 4D input Tensor.}]>:$t, 1252 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A 1D mean Tensor with size matching the last dimension of t. 1253This is the first output from tf.nn.moments, 1254or a saved moving average thereof.}]>:$m, 1255 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A 1D variance Tensor with size matching the last dimension of t. 1256This is the second output from tf.nn.moments, 1257or a saved moving average thereof.}]>:$v, 1258 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A 1D beta Tensor with size matching the last dimension of t. 1259An offset to be added to the normalized tensor.}]>:$beta, 1260 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A 1D gamma Tensor with size matching the last dimension of t. 1261If "scale_after_normalization" is true, this tensor will be multiplied 1262with the normalized tensor.}]>:$gamma, 1263 1264 F32Attr:$variance_epsilon, 1265 BoolAttr:$scale_after_normalization 1266 ); 1267 1268 let results = (outs 1269 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$result 1270 ); 1271 1272 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1273} 1274 1275def TF_BatchToSpaceOp : TF_Op<"BatchToSpace", [NoSideEffect]> { 1276 let summary = "BatchToSpace for 4-D tensors of type T."; 1277 1278 let description = [{ 1279This is a legacy version of the more general BatchToSpaceND. 1280 1281Rearranges (permutes) data from batch into blocks of spatial data, followed by 1282cropping. This is the reverse transformation of SpaceToBatch. More specifically, 1283this op outputs a copy of the input tensor where values from the `batch` 1284dimension are moved in spatial blocks to the `height` and `width` dimensions, 1285followed by cropping along the `height` and `width` dimensions. 1286 }]; 1287 1288 let arguments = (ins 1289 Arg<TF_Tensor, [{4-D tensor with shape 1290`[batch*block_size*block_size, height_pad/block_size, width_pad/block_size, 1291 depth]`. Note that the batch size of the input tensor must be divisible by 1292`block_size * block_size`.}]>:$input, 1293 Arg<TF_I32OrI64Tensor, [{2-D tensor of non-negative integers with shape `[2, 2]`. It specifies 1294how many elements to crop from the intermediate result across the spatial 1295dimensions as follows: 1296 1297 crops = [[crop_top, crop_bottom], [crop_left, crop_right]]}]>:$crops, 1298 1299 ConfinedAttr<I64Attr, [IntMinValue<2>]>:$block_size 1300 ); 1301 1302 let results = (outs 1303 Res<TF_Tensor, [{4-D with shape `[batch, height, width, depth]`, where: 1304 1305 height = height_pad - crop_top - crop_bottom 1306 width = width_pad - crop_left - crop_right 1307 1308The attr `block_size` must be greater than one. It indicates the block size. 1309 1310Some examples: 1311 1312(1) For the following input of shape `[4, 1, 1, 1]` and block_size of 2: 1313 1314``` 1315[[[[1]]], [[[2]]], [[[3]]], [[[4]]]] 1316``` 1317 1318The output tensor has shape `[1, 2, 2, 1]` and value: 1319 1320``` 1321x = [[[[1], [2]], [[3], [4]]]] 1322``` 1323 1324(2) For the following input of shape `[4, 1, 1, 3]` and block_size of 2: 1325 1326``` 1327[[[[1, 2, 3]]], [[[4, 5, 6]]], [[[7, 8, 9]]], [[[10, 11, 12]]]] 1328``` 1329 1330The output tensor has shape `[1, 2, 2, 3]` and value: 1331 1332``` 1333x = [[[[1, 2, 3], [4, 5, 6]], 1334 [[7, 8, 9], [10, 11, 12]]]] 1335``` 1336 1337(3) For the following input of shape `[4, 2, 2, 1]` and block_size of 2: 1338 1339``` 1340x = [[[[1], [3]], [[9], [11]]], 1341 [[[2], [4]], [[10], [12]]], 1342 [[[5], [7]], [[13], [15]]], 1343 [[[6], [8]], [[14], [16]]]] 1344``` 1345 1346The output tensor has shape `[1, 4, 4, 1]` and value: 1347 1348``` 1349x = [[[[1], [2], [3], [4]], 1350 [[5], [6], [7], [8]], 1351 [[9], [10], [11], [12]], 1352 [[13], [14], [15], [16]]]] 1353``` 1354 1355(4) For the following input of shape `[8, 1, 2, 1]` and block_size of 2: 1356 1357``` 1358x = [[[[1], [3]]], [[[9], [11]]], [[[2], [4]]], [[[10], [12]]], 1359 [[[5], [7]]], [[[13], [15]]], [[[6], [8]]], [[[14], [16]]]] 1360``` 1361 1362The output tensor has shape `[2, 2, 4, 1]` and value: 1363 1364``` 1365x = [[[[1], [3]], [[5], [7]]], 1366 [[[2], [4]], [[10], [12]]], 1367 [[[5], [7]], [[13], [15]]], 1368 [[[6], [8]], [[14], [16]]]] 1369```}]>:$output 1370 ); 1371 1372 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1373 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 1374 1375 let hasVerifier = 1; 1376 1377 let hasCanonicalizer = 1; 1378} 1379 1380def TF_BatchToSpaceNDOp : TF_Op<"BatchToSpaceND", [NoSideEffect]> { 1381 let summary = "BatchToSpace for N-D tensors of type T."; 1382 1383 let description = [{ 1384This operation reshapes the "batch" dimension 0 into `M + 1` dimensions of shape 1385`block_shape + [batch]`, interleaves these blocks back into the grid defined by 1386the spatial dimensions `[1, ..., M]`, to obtain a result with the same rank as 1387the input. The spatial dimensions of this intermediate result are then 1388optionally cropped according to `crops` to produce the output. This is the 1389reverse of SpaceToBatch. See below for a precise description. 1390 }]; 1391 1392 let arguments = (ins 1393 Arg<TF_Tensor, [{N-D with shape `input_shape = [batch] + spatial_shape + remaining_shape`, 1394where spatial_shape has M dimensions.}]>:$input, 1395 Arg<TF_I32OrI64Tensor, [{1-D with shape `[M]`, all values must be >= 1.}]>:$block_shape, 1396 Arg<TF_I32OrI64Tensor, [{2-D with shape `[M, 2]`, all values must be >= 0. 1397 `crops[i] = [crop_start, crop_end]` specifies the amount to crop from input 1398 dimension `i + 1`, which corresponds to spatial dimension `i`. It is 1399 required that 1400 `crop_start[i] + crop_end[i] <= block_shape[i] * input_shape[i + 1]`. 1401 1402This operation is equivalent to the following steps: 1403 14041. Reshape `input` to `reshaped` of shape: 1405 [block_shape[0], ..., block_shape[M-1], 1406 batch / prod(block_shape), 1407 input_shape[1], ..., input_shape[N-1]] 1408 14092. Permute dimensions of `reshaped` to produce `permuted` of shape 1410 [batch / prod(block_shape), 1411 1412 input_shape[1], block_shape[0], 1413 ..., 1414 input_shape[M], block_shape[M-1], 1415 1416 input_shape[M+1], ..., input_shape[N-1]] 1417 14183. Reshape `permuted` to produce `reshaped_permuted` of shape 1419 [batch / prod(block_shape), 1420 1421 input_shape[1] * block_shape[0], 1422 ..., 1423 input_shape[M] * block_shape[M-1], 1424 1425 input_shape[M+1], 1426 ..., 1427 input_shape[N-1]] 1428 14294. Crop the start and end of dimensions `[1, ..., M]` of 1430 `reshaped_permuted` according to `crops` to produce the output of shape: 1431 [batch / prod(block_shape), 1432 1433 input_shape[1] * block_shape[0] - crops[0,0] - crops[0,1], 1434 ..., 1435 input_shape[M] * block_shape[M-1] - crops[M-1,0] - crops[M-1,1], 1436 1437 input_shape[M+1], ..., input_shape[N-1]] 1438 1439Some examples: 1440 1441(1) For the following input of shape `[4, 1, 1, 1]`, `block_shape = [2, 2]`, and 1442 `crops = [[0, 0], [0, 0]]`: 1443 1444``` 1445[[[[1]]], [[[2]]], [[[3]]], [[[4]]]] 1446``` 1447 1448The output tensor has shape `[1, 2, 2, 1]` and value: 1449 1450``` 1451x = [[[[1], [2]], [[3], [4]]]] 1452``` 1453 1454(2) For the following input of shape `[4, 1, 1, 3]`, `block_shape = [2, 2]`, and 1455 `crops = [[0, 0], [0, 0]]`: 1456 1457``` 1458[[[[1, 2, 3]]], [[[4, 5, 6]]], [[[7, 8, 9]]], [[[10, 11, 12]]]] 1459``` 1460 1461The output tensor has shape `[1, 2, 2, 3]` and value: 1462 1463``` 1464x = [[[[1, 2, 3], [4, 5, 6]], 1465 [[7, 8, 9], [10, 11, 12]]]] 1466``` 1467 1468(3) For the following input of shape `[4, 2, 2, 1]`, `block_shape = [2, 2]`, and 1469 `crops = [[0, 0], [0, 0]]`: 1470 1471``` 1472x = [[[[1], [3]], [[9], [11]]], 1473 [[[2], [4]], [[10], [12]]], 1474 [[[5], [7]], [[13], [15]]], 1475 [[[6], [8]], [[14], [16]]]] 1476``` 1477 1478The output tensor has shape `[1, 4, 4, 1]` and value: 1479 1480``` 1481x = [[[[1], [2], [3], [4]], 1482 [[5], [6], [7], [8]], 1483 [[9], [10], [11], [12]], 1484 [[13], [14], [15], [16]]]] 1485``` 1486 1487(4) For the following input of shape `[8, 1, 3, 1]`, `block_shape = [2, 2]`, and 1488 `crops = [[0, 0], [2, 0]]`: 1489 1490``` 1491x = [[[[0], [1], [3]]], [[[0], [9], [11]]], 1492 [[[0], [2], [4]]], [[[0], [10], [12]]], 1493 [[[0], [5], [7]]], [[[0], [13], [15]]], 1494 [[[0], [6], [8]]], [[[0], [14], [16]]]] 1495``` 1496 1497The output tensor has shape `[2, 2, 4, 1]` and value: 1498 1499``` 1500x = [[[[1], [2], [3], [4]], 1501 [[5], [6], [7], [8]]], 1502 [[[9], [10], [11], [12]], 1503 [[13], [14], [15], [16]]]] 1504```}]>:$crops 1505 ); 1506 1507 let results = (outs 1508 TF_Tensor:$output 1509 ); 1510 1511 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1512 TF_DerivedOperandTypeAttr Tblock_shape = TF_DerivedOperandTypeAttr<1>; 1513 TF_DerivedOperandTypeAttr Tcrops = TF_DerivedOperandTypeAttr<2>; 1514 1515 let hasVerifier = 1; 1516} 1517 1518def TF_BetaincOp : TF_Op<"Betainc", [NoSideEffect]> { 1519 let summary = [{ 1520Compute the regularized incomplete beta integral \\(I_x(a, b)\\). 1521 }]; 1522 1523 let description = [{ 1524The regularized incomplete beta integral is defined as: 1525 1526 1527\\(I_x(a, b) = \frac{B(x; a, b)}{B(a, b)}\\) 1528 1529where 1530 1531 1532\\(B(x; a, b) = \int_0^x t^{a-1} (1 - t)^{b-1} dt\\) 1533 1534 1535is the incomplete beta function and \\(B(a, b)\\) is the *complete* 1536beta function. 1537 }]; 1538 1539 let arguments = (ins 1540 TF_F32OrF64Tensor:$a, 1541 TF_F32OrF64Tensor:$b, 1542 TF_F32OrF64Tensor:$x 1543 ); 1544 1545 let results = (outs 1546 TF_F32OrF64Tensor:$z 1547 ); 1548 1549 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1550} 1551 1552def TF_BiasAddOp : TF_Op<"BiasAdd", [NoSideEffect, TF_LayoutSensitiveInterface]> { 1553 let summary = "Adds `bias` to `value`."; 1554 1555 let description = [{ 1556This is a special case of `tf.add` where `bias` is restricted to be 1-D. 1557Broadcasting is supported, so `value` may have any number of dimensions. 1558 }]; 1559 1560 let arguments = (ins 1561 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Any number of dimensions.}]>:$value, 1562 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{1-D with size the last dimension of `value`.}]>:$bias, 1563 1564 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format 1565 ); 1566 1567 let results = (outs 1568 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Broadcasted sum of `value` and `bias`.}]>:$output 1569 ); 1570 1571 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1572 1573 let extraClassDeclaration = [{ 1574 // TF_LayoutSensitiveInterface: 1575 SmallVector<unsigned, 4> GetLayoutDependentArgs() { return {0}; } 1576 SmallVector<unsigned, 4> GetLayoutDependentResults() { return {0}; } 1577 StringRef GetOptimalLayout(const RuntimeDevices& devices); 1578 LogicalResult UpdateDataFormat(StringRef data_format); 1579 }]; 1580 1581 let hasVerifier = 1; 1582} 1583 1584def TF_BiasAddGradOp : TF_Op<"BiasAddGrad", [NoSideEffect]> { 1585 let summary = [{ 1586The backward operation for "BiasAdd" on the "bias" tensor. 1587 }]; 1588 1589 let description = [{ 1590It accumulates all the values from out_backprop into the feature dimension. 1591For NHWC data format, the feature dimension is the last. For NCHW data format, 1592the feature dimension is the third-to-last. 1593 }]; 1594 1595 let arguments = (ins 1596 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Any number of dimensions.}]>:$out_backprop, 1597 1598 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format 1599 ); 1600 1601 let results = (outs 1602 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{1-D with size the feature dimension of `out_backprop`.}]>:$output 1603 ); 1604 1605 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1606 1607 let hasVerifier = 1; 1608} 1609 1610def TF_BiasAddV1Op : TF_Op<"BiasAddV1", [NoSideEffect]> { 1611 let summary = "Adds `bias` to `value`."; 1612 1613 let description = [{ 1614This is a deprecated version of BiasAdd and will be soon removed. 1615 1616This is a special case of `tf.add` where `bias` is restricted to be 1-D. 1617Broadcasting is supported, so `value` may have any number of dimensions. 1618 }]; 1619 1620 let arguments = (ins 1621 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Any number of dimensions.}]>:$value, 1622 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{1-D with size the last dimension of `value`.}]>:$bias 1623 ); 1624 1625 let results = (outs 1626 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Broadcasted sum of `value` and `bias`.}]>:$output 1627 ); 1628 1629 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1630 1631 let hasCanonicalizer = 1; 1632} 1633 1634def TF_BincountOp : TF_Op<"Bincount", [NoSideEffect]> { 1635 let summary = [{ 1636Counts the number of occurrences of each value in an integer array. 1637 }]; 1638 1639 let description = [{ 1640Outputs a vector with length `size` and the same dtype as `weights`. If 1641`weights` are empty, then index `i` stores the number of times the value `i` is 1642counted in `arr`. If `weights` are non-empty, then index `i` stores the sum of 1643the value in `weights` at each index where the corresponding value in `arr` is 1644`i`. 1645 1646Values in `arr` outside of the range [0, size) are ignored. 1647 }]; 1648 1649 let arguments = (ins 1650 Arg<TF_Int32Tensor, [{int32 `Tensor`.}]>:$arr, 1651 Arg<TF_Int32Tensor, [{non-negative int32 scalar `Tensor`.}]>:$size, 1652 Arg<TensorOf<[TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{is an int32, int64, float32, or float64 `Tensor` with the same 1653shape as `arr`, or a length-0 `Tensor`, in which case it acts as all weights 1654equal to 1.}]>:$weights 1655 ); 1656 1657 let results = (outs 1658 Res<TensorOf<[TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{1D `Tensor` with length equal to `size`. The counts or summed weights for 1659each value in the range [0, size).}]>:$bins 1660 ); 1661 1662 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 1663} 1664 1665def TF_BitcastOp : TF_Op<"Bitcast", [NoSideEffect]> { 1666 let summary = [{ 1667Bitcasts a tensor from one type to another without copying data. 1668 }]; 1669 1670 let description = [{ 1671Given a tensor `input`, this operation returns a tensor that has the same buffer 1672data as `input` with datatype `type`. 1673 1674If the input datatype `T` is larger than the output datatype `type` then the 1675shape changes from [...] to [..., sizeof(`T`)/sizeof(`type`)]. 1676 1677If `T` is smaller than `type`, the operator requires that the rightmost 1678dimension be equal to sizeof(`type`)/sizeof(`T`). The shape then goes from 1679[..., sizeof(`type`)/sizeof(`T`)] to [...]. 1680 1681tf.bitcast() and tf.cast() work differently when real dtype is casted as a complex dtype 1682(e.g. tf.complex64 or tf.complex128) as tf.cast() make imaginary part 0 while tf.bitcast() 1683gives module error. 1684For example, 1685 1686Example 1: 1687 1688>>> a = [1., 2., 3.] 1689>>> equality_bitcast = tf.bitcast(a, tf.complex128) 1690Traceback (most recent call last): 1691... 1692InvalidArgumentError: Cannot bitcast from 1 to 18 [Op:Bitcast] 1693>>> equality_cast = tf.cast(a, tf.complex128) 1694>>> print(equality_cast) 1695tf.Tensor([1.+0.j 2.+0.j 3.+0.j], shape=(3,), dtype=complex128) 1696 1697Example 2: 1698 1699>>> tf.bitcast(tf.constant(0xffffffff, dtype=tf.uint32), tf.uint8) 1700<tf.Tensor: shape=(4,), dtype=uint8, numpy=array([255, 255, 255, 255], dtype=uint8)> 1701 1702Example 3: 1703 1704>>> x = [1., 2., 3.] 1705>>> y = [0., 2., 3.] 1706>>> equality= tf.equal(x,y) 1707>>> equality_cast = tf.cast(equality,tf.float32) 1708>>> equality_bitcast = tf.bitcast(equality_cast,tf.uint8) 1709>>> print(equality) 1710tf.Tensor([False True True], shape=(3,), dtype=bool) 1711>>> print(equality_cast) 1712tf.Tensor([0. 1. 1.], shape=(3,), dtype=float32) 1713>>> print(equality_bitcast) 1714tf.Tensor( 1715 [[ 0 0 0 0] 1716 [ 0 0 128 63] 1717 [ 0 0 128 63]], shape=(3, 4), dtype=uint8) 1718 1719*NOTE*: Bitcast is implemented as a low-level cast, so machines with different 1720endian orderings will give different results. 1721 }]; 1722 1723 let arguments = (ins 1724 TF_NumberTensor:$input 1725 ); 1726 1727 let results = (outs 1728 TF_NumberTensor:$output 1729 ); 1730 1731 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1732 TF_DerivedResultTypeAttr type = TF_DerivedResultTypeAttr<0>; 1733 1734 let hasVerifier = 1; 1735 1736 let hasCanonicalizer = 1; 1737} 1738 1739def TF_BitwiseAndOp : TF_Op<"BitwiseAnd", [Commutative, NoSideEffect, ResultsBroadcastableShape]>, 1740 WithBroadcastableBinOpBuilder { 1741 let summary = "Elementwise computes the bitwise AND of `x` and `y`."; 1742 1743 let description = [{ 1744The result will have those bits set, that are set in both `x` and `y`. The 1745computation is performed on the underlying representations of `x` and `y`. 1746 1747For example: 1748 1749```python 1750import tensorflow as tf 1751from tensorflow.python.ops import bitwise_ops 1752dtype_list = [tf.int8, tf.int16, tf.int32, tf.int64, 1753 tf.uint8, tf.uint16, tf.uint32, tf.uint64] 1754 1755for dtype in dtype_list: 1756 lhs = tf.constant([0, 5, 3, 14], dtype=dtype) 1757 rhs = tf.constant([5, 0, 7, 11], dtype=dtype) 1758 exp = tf.constant([0, 0, 3, 10], dtype=tf.float32) 1759 1760 res = bitwise_ops.bitwise_and(lhs, rhs) 1761 tf.assert_equal(tf.cast(res, tf.float32), exp) # TRUE 1762``` 1763 }]; 1764 1765 let arguments = (ins 1766 TF_IntTensor:$x, 1767 TF_IntTensor:$y 1768 ); 1769 1770 let results = (outs 1771 TF_IntTensor:$z 1772 ); 1773 1774 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1775} 1776 1777def TF_BitwiseOrOp : TF_Op<"BitwiseOr", [Commutative, NoSideEffect, ResultsBroadcastableShape]>, 1778 WithBroadcastableBinOpBuilder { 1779 let summary = "Elementwise computes the bitwise OR of `x` and `y`."; 1780 1781 let description = [{ 1782The result will have those bits set, that are set in `x`, `y` or both. The 1783computation is performed on the underlying representations of `x` and `y`. 1784 1785For example: 1786 1787```python 1788import tensorflow as tf 1789from tensorflow.python.ops import bitwise_ops 1790dtype_list = [tf.int8, tf.int16, tf.int32, tf.int64, 1791 tf.uint8, tf.uint16, tf.uint32, tf.uint64] 1792 1793for dtype in dtype_list: 1794 lhs = tf.constant([0, 5, 3, 14], dtype=dtype) 1795 rhs = tf.constant([5, 0, 7, 11], dtype=dtype) 1796 exp = tf.constant([5, 5, 7, 15], dtype=tf.float32) 1797 1798 res = bitwise_ops.bitwise_or(lhs, rhs) 1799 tf.assert_equal(tf.cast(res, tf.float32), exp) # TRUE 1800``` 1801 }]; 1802 1803 let arguments = (ins 1804 TF_IntTensor:$x, 1805 TF_IntTensor:$y 1806 ); 1807 1808 let results = (outs 1809 TF_IntTensor:$z 1810 ); 1811 1812 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1813} 1814 1815def TF_BitwiseXorOp : TF_Op<"BitwiseXor", [Commutative, NoSideEffect, ResultsBroadcastableShape]>, 1816 WithBroadcastableBinOpBuilder { 1817 let summary = "Elementwise computes the bitwise XOR of `x` and `y`."; 1818 1819 let description = [{ 1820The result will have those bits set, that are different in `x` and `y`. The 1821computation is performed on the underlying representations of `x` and `y`. 1822 1823For example: 1824 1825```python 1826import tensorflow as tf 1827from tensorflow.python.ops import bitwise_ops 1828dtype_list = [tf.int8, tf.int16, tf.int32, tf.int64, 1829 tf.uint8, tf.uint16, tf.uint32, tf.uint64] 1830 1831for dtype in dtype_list: 1832 lhs = tf.constant([0, 5, 3, 14], dtype=dtype) 1833 rhs = tf.constant([5, 0, 7, 11], dtype=dtype) 1834 exp = tf.constant([5, 5, 4, 5], dtype=tf.float32) 1835 1836 res = bitwise_ops.bitwise_xor(lhs, rhs) 1837 tf.assert_equal(tf.cast(res, tf.float32), exp) # TRUE 1838``` 1839 }]; 1840 1841 let arguments = (ins 1842 TF_IntTensor:$x, 1843 TF_IntTensor:$y 1844 ); 1845 1846 let results = (outs 1847 TF_IntTensor:$z 1848 ); 1849 1850 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1851} 1852 1853def TF_BoostedTreesBucketizeOp : TF_Op<"BoostedTreesBucketize", [NoSideEffect, SameVariadicOperandSize]> { 1854 let summary = "Bucketize each feature based on bucket boundaries."; 1855 1856 let description = [{ 1857An op that returns a list of float tensors, where each tensor represents the 1858bucketized values for a single feature. 1859 }]; 1860 1861 let arguments = (ins 1862 Arg<Variadic<TF_Float32Tensor>, [{float; List of Rank 1 Tensor each containing float values for a single feature.}]>:$float_values, 1863 Arg<Variadic<TF_Float32Tensor>, [{float; List of Rank 1 Tensors each containing the bucket boundaries for a single 1864feature.}]>:$bucket_boundaries 1865 ); 1866 1867 let results = (outs 1868 Res<Variadic<TF_Int32Tensor>, [{int; List of Rank 1 Tensors each containing the bucketized values for a single feature.}]>:$buckets 1869 ); 1870 1871 TF_DerivedOperandSizeAttr num_features = TF_DerivedOperandSizeAttr<0>; 1872} 1873 1874def TF_BroadcastArgsOp : TF_Op<"BroadcastArgs", [NoSideEffect]> { 1875 let summary = "Return the shape of s0 op s1 with broadcast."; 1876 1877 let description = [{ 1878Given `s0` and `s1`, tensors that represent shapes, compute `r0`, the 1879broadcasted shape. `s0`, `s1` and `r0` are all integer vectors. 1880 }]; 1881 1882 let arguments = (ins 1883 TF_I32OrI64Tensor:$s0, 1884 TF_I32OrI64Tensor:$s1 1885 ); 1886 1887 let results = (outs 1888 TF_I32OrI64Tensor:$r0 1889 ); 1890 1891 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1892} 1893 1894def TF_BroadcastGradientArgsOp : TF_Op<"BroadcastGradientArgs", [NoSideEffect, SameOperandsAndResultElementType, TF_OperandHasRank<0, 1>, TF_OperandHasRank<1, 1>, TF_ResultHasRank<0, 1>, TF_ResultHasRank<1, 1>]> { 1895 let summary = [{ 1896Return the reduction indices for computing gradients of s0 op s1 with broadcast. 1897 }]; 1898 1899 let description = [{ 1900This is typically used by gradient computations for a broadcasting operation. 1901 }]; 1902 1903 let arguments = (ins 1904 TF_I32OrI64Tensor:$s0, 1905 TF_I32OrI64Tensor:$s1 1906 ); 1907 1908 let results = (outs 1909 TF_I32OrI64Tensor:$r0, 1910 TF_I32OrI64Tensor:$r1 1911 ); 1912 1913 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1914 1915 let hasVerifier = 1; 1916 1917 let hasFolder = 1; 1918} 1919 1920def TF_BroadcastToOp : TF_Op<"BroadcastTo", [NoSideEffect]> { 1921 let summary = "Broadcast an array for a compatible shape."; 1922 1923 let description = [{ 1924Broadcasting is the process of making arrays to have compatible shapes 1925for arithmetic operations. Two shapes are compatible if for each 1926dimension pair they are either equal or one of them is one. 1927 1928For example: 1929 1930>>> x = tf.constant([[1, 2, 3]]) # Shape (1, 3,) 1931>>> y = tf.broadcast_to(x, [2, 3]) 1932>>> print(y) 1933tf.Tensor( 1934 [[1 2 3] 1935 [1 2 3]], shape=(2, 3), dtype=int32) 1936 1937In the above example, the input Tensor with the shape of `[1, 3]` 1938is broadcasted to output Tensor with shape of `[2, 3]`. 1939 1940When broadcasting, if a tensor has fewer axes than necessary its shape is 1941padded on the left with ones. So this gives the same result as the previous 1942example: 1943 1944>>> x = tf.constant([1, 2, 3]) # Shape (3,) 1945>>> y = tf.broadcast_to(x, [2, 3]) 1946 1947 1948When doing broadcasted operations such as multiplying a tensor 1949by a scalar, broadcasting (usually) confers some time or space 1950benefit, as the broadcasted tensor is never materialized. 1951 1952However, `broadcast_to` does not carry with it any such benefits. 1953The newly-created tensor takes the full memory of the broadcasted 1954shape. (In a graph context, `broadcast_to` might be fused to 1955subsequent operation and then be optimized away, however.) 1956 }]; 1957 1958 let arguments = (ins 1959 Arg<TF_Tensor, [{A Tensor to broadcast.}]>:$input, 1960 Arg<TF_I32OrI64Tensor, [{An 1-D `int` Tensor. The shape of the desired output.}]>:$shape 1961 ); 1962 1963 let results = (outs 1964 Res<TF_Tensor, [{A Tensor.}]>:$output 1965 ); 1966 1967 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 1968 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 1969 1970 let hasVerifier = 1; 1971 let hasFolder = 1; 1972} 1973 1974def TF_BucketizeOp : TF_Op<"Bucketize", [NoSideEffect, SameOperandsAndResultShape]> { 1975 let summary = "Bucketizes 'input' based on 'boundaries'."; 1976 1977 let description = [{ 1978For example, if the inputs are 1979 boundaries = [0, 10, 100] 1980 input = [[-5, 10000] 1981 [150, 10] 1982 [5, 100]] 1983 1984then the output will be 1985 output = [[0, 3] 1986 [3, 2] 1987 [1, 3]] 1988 }]; 1989 1990 let arguments = (ins 1991 Arg<TensorOf<[TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{Any shape of Tensor contains with int or float type.}]>:$input, 1992 1993 F32ArrayAttr:$boundaries 1994 ); 1995 1996 let results = (outs 1997 Res<TF_Int32Tensor, [{Same shape with 'input', each value of input replaced with bucket index. 1998 1999@compatibility(numpy) 2000Equivalent to np.digitize. 2001@end_compatibility}]>:$output 2002 ); 2003 2004 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2005} 2006 2007def TF_CacheDatasetV2Op : TF_Op<"CacheDatasetV2", []> { 2008 let summary = ""; 2009 2010 let arguments = (ins 2011 TF_VariantTensor:$input_dataset, 2012 TF_StrTensor:$filename, 2013 Arg<TF_ResourceTensor, "", [TF_DatasetMemoryCacheRead, TF_DatasetMemoryCacheWrite]>:$cache, 2014 2015 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 2016 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 2017 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 2018 ); 2019 2020 let results = (outs 2021 TF_VariantTensor:$handle 2022 ); 2023} 2024 2025def TF_CastOp : TF_Op<"Cast", [NoSideEffect, SameOperandsAndResultShape]> { 2026 let summary = "Cast x of type SrcT to y of DstT."; 2027 2028 let arguments = (ins 2029 TF_Tensor:$x, 2030 2031 DefaultValuedAttr<BoolAttr, "false">:$Truncate 2032 ); 2033 2034 let results = (outs 2035 TF_Tensor:$y 2036 ); 2037 2038 TF_DerivedOperandTypeAttr SrcT = TF_DerivedOperandTypeAttr<0>; 2039 TF_DerivedResultTypeAttr DstT = TF_DerivedResultTypeAttr<0>; 2040 2041 let hasFolder = 1; 2042} 2043 2044def TF_CeilOp : TF_Op<"Ceil", [Idempotent, NoSideEffect, SameOperandsAndResultType]> { 2045 let summary = "Returns element-wise smallest integer not less than x."; 2046 2047 let arguments = (ins 2048 TF_FloatTensor:$x 2049 ); 2050 2051 let results = (outs 2052 TF_FloatTensor:$y 2053 ); 2054 2055 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2056} 2057 2058def TF_CheckNumericsOp : TF_Op<"CheckNumerics", [TF_SameOperandsAndResultTypeResolveRef]> { 2059 let summary = "Checks a tensor for NaN and Inf values."; 2060 2061 let description = [{ 2062When run, reports an `InvalidArgument` error if `tensor` has any values 2063that are not a number (NaN) or infinity (Inf). Otherwise, returns the input 2064tensor. 2065 2066Example usage: 2067 2068``` python 2069a = tf.Variable(1.0) 2070tf.debugging.check_numerics(a, message='') 2071 2072b = tf.Variable(np.nan) 2073try: 2074 tf.debugging.check_numerics(b, message='Checking b') 2075except Exception as e: 2076 assert "Checking b : Tensor had NaN values" in e.message 2077 2078c = tf.Variable(np.inf) 2079try: 2080 tf.debugging.check_numerics(c, message='Checking c') 2081except Exception as e: 2082 assert "Checking c : Tensor had Inf values" in e.message 2083``` 2084 }]; 2085 2086 let arguments = (ins 2087 TF_FloatTensor:$tensor, 2088 2089 StrAttr:$message 2090 ); 2091 2092 let results = (outs 2093 TF_FloatTensor:$output 2094 ); 2095 2096 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2097} 2098 2099def TF_CholeskyOp : TF_Op<"Cholesky", [NoSideEffect]> { 2100 let summary = [{ 2101Computes the Cholesky decomposition of one or more square matrices. 2102 }]; 2103 2104 let description = [{ 2105The input is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions 2106form square matrices. 2107 2108The input has to be symmetric and positive definite. Only the lower-triangular 2109part of the input will be used for this operation. The upper-triangular part 2110will not be read. 2111 2112The output is a tensor of the same shape as the input 2113containing the Cholesky decompositions for all input submatrices `[..., :, :]`. 2114 2115**Note**: The gradient computation on GPU is faster for large matrices but 2116not for large batch dimensions when the submatrices are small. In this 2117case it might be faster to use the CPU. 2118 }]; 2119 2120 let arguments = (ins 2121 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Shape is `[..., M, M]`.}]>:$input 2122 ); 2123 2124 let results = (outs 2125 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Shape is `[..., M, M]`.}]>:$output 2126 ); 2127 2128 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2129} 2130 2131def TF_ClipByValueOp : TF_Op<"ClipByValue", [NoSideEffect, TF_SameOperandsAndResultElementTypeResolveRef]> { 2132 let summary = "Clips tensor values to a specified min and max."; 2133 2134 let description = [{ 2135Given a tensor `t`, this operation returns a tensor of the same type and 2136shape as `t` with its values clipped to `clip_value_min` and `clip_value_max`. 2137Any values less than `clip_value_min` are set to `clip_value_min`. Any values 2138greater than `clip_value_max` are set to `clip_value_max`. 2139 }]; 2140 2141 let arguments = (ins 2142 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A `Tensor`.}]>:$t, 2143 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A 0-D (scalar) `Tensor`, or a `Tensor` with the same shape 2144as `t`. The minimum value to clip by.}]>:$clip_value_min, 2145 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A 0-D (scalar) `Tensor`, or a `Tensor` with the same shape 2146as `t`. The maximum value to clip by.}]>:$clip_value_max 2147 ); 2148 2149 let results = (outs 2150 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A clipped `Tensor` with the same shape as input 't'.}]>:$output 2151 ); 2152 2153 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2154} 2155 2156def TF_CollateTPUEmbeddingMemoryOp : TF_Op<"CollateTPUEmbeddingMemory", []> { 2157 let summary = [{ 2158An op that merges the string-encoded memory config protos from all hosts. 2159 }]; 2160 2161 let arguments = (ins 2162 Arg<Variadic<TF_StrTensor>, [{String-encoded memory config protos containing metadata about 2163the memory allocations reserved for TPUEmbedding across all hosts.}]>:$memory_configs 2164 ); 2165 2166 let results = (outs 2167 TF_StrTensor:$merged_memory_config 2168 ); 2169 2170 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 2171} 2172 2173def TF_CollectiveAssignGroupV2Op : TF_Op<"CollectiveAssignGroupV2", [NoSideEffect, TF_NoConstantFold]> { 2174 let summary = "Assign group keys based on group assignment."; 2175 2176 let arguments = (ins 2177 TF_Int32Tensor:$group_assignment, 2178 TF_Int32Tensor:$device_index, 2179 TF_Int32Tensor:$base_key 2180 ); 2181 2182 let results = (outs 2183 TF_Int32Tensor:$group_size, 2184 TF_Int32Tensor:$group_key 2185 ); 2186} 2187 2188def TF_CollectiveBcastRecvOp : TF_Op<"CollectiveBcastRecv", []> { 2189 let summary = "Receives a tensor value broadcast from another device."; 2190 2191 let arguments = (ins 2192 I64Attr:$group_size, 2193 I64Attr:$group_key, 2194 I64Attr:$instance_key, 2195 TF_ShapeAttr:$shape, 2196 DefaultValuedAttr<StrAttr, "\"auto\"">:$communication_hint, 2197 DefaultValuedAttr<F32Attr, "0.0f">:$timeout_seconds 2198 ); 2199 2200 let results = (outs 2201 TensorOf<[TF_Bool, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$data 2202 ); 2203 2204 TF_DerivedResultTypeAttr T = TF_DerivedResultTypeAttr<0>; 2205} 2206 2207def TF_CollectiveBcastSendOp : TF_Op<"CollectiveBcastSend", []> { 2208 let summary = "Broadcasts a tensor value to one or more other devices."; 2209 2210 let arguments = (ins 2211 TensorOf<[TF_Bool, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$input, 2212 2213 I64Attr:$group_size, 2214 I64Attr:$group_key, 2215 I64Attr:$instance_key, 2216 TF_ShapeAttr:$shape, 2217 DefaultValuedAttr<StrAttr, "\"auto\"">:$communication_hint, 2218 DefaultValuedAttr<F32Attr, "0.0f">:$timeout_seconds 2219 ); 2220 2221 let results = (outs 2222 TensorOf<[TF_Bool, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$data 2223 ); 2224 2225 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2226} 2227 2228def TF_CollectiveGatherOp : TF_Op<"CollectiveGather", []> { 2229 let summary = [{ 2230Mutually accumulates multiple tensors of identical type and shape. 2231 }]; 2232 2233 let arguments = (ins 2234 TensorOf<[TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$input, 2235 2236 I64Attr:$group_size, 2237 I64Attr:$group_key, 2238 I64Attr:$instance_key, 2239 TF_ShapeAttr:$shape, 2240 DefaultValuedAttr<StrAttr, "\"auto\"">:$communication_hint, 2241 DefaultValuedAttr<F32Attr, "0.0f">:$timeout_seconds 2242 ); 2243 2244 let results = (outs 2245 TensorOf<[TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$data 2246 ); 2247 2248 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2249} 2250 2251def TF_CollectivePermuteOp : TF_Op<"CollectivePermute", []> { 2252 let summary = "An Op to permute tensors across replicated TPU instances."; 2253 2254 let description = [{ 2255Each instance supplies its own input. 2256 2257For example, suppose there are 4 TPU instances: `[A, B, C, D]`. Passing 2258source_target_pairs=`[[0,1],[1,2],[2,3],[3,0]]` gets the outputs: 2259`[D, A, B, C]`. 2260 }]; 2261 2262 let arguments = (ins 2263 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The local input to be permuted. Currently only supports float and 2264bfloat16.}]>:$input, 2265 Arg<TF_Int32Tensor, [{A tensor with shape [num_pairs, 2].}]>:$source_target_pairs 2266 ); 2267 2268 let results = (outs 2269 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The permuted input.}]>:$output 2270 ); 2271 2272 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2273} 2274 2275def TF_CollectiveReduceOp : TF_Op<"CollectiveReduce", [TF_SameOperandsAndResultTypeResolveRef]> { 2276 let summary = [{ 2277Mutually reduces multiple tensors of identical type and shape. 2278 }]; 2279 2280 let arguments = (ins 2281 TF_FpOrI32OrI64Tensor:$input, 2282 2283 I64Attr:$group_size, 2284 I64Attr:$group_key, 2285 I64Attr:$instance_key, 2286 TF_AnyStrAttrOf<["Min", "Max", "Mul", "Add"]>:$merge_op, 2287 TF_AnyStrAttrOf<["Id", "Div"]>:$final_op, 2288 I64ArrayAttr:$subdiv_offsets, 2289 DefaultValuedAttr<I64ArrayAttr, "{}">:$wait_for, 2290 DefaultValuedAttr<StrAttr, "\"auto\"">:$communication_hint, 2291 DefaultValuedAttr<F32Attr, "0.0f">:$timeout_seconds 2292 ); 2293 2294 let results = (outs 2295 TF_FpOrI32OrI64Tensor:$data 2296 ); 2297 2298 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2299} 2300 2301def TF_CollectiveReduceV2Op : TF_Op<"CollectiveReduceV2", [TF_CollectiveReduceOrderingEffect]> { 2302 let summary = [{ 2303Mutually reduces multiple tensors of identical type and shape. 2304 }]; 2305 2306 let arguments = (ins 2307 TF_FpOrI32OrI64Tensor:$input, 2308 TF_Int32Tensor:$group_size, 2309 TF_Int32Tensor:$group_key, 2310 TF_Int32Tensor:$instance_key, 2311 Variadic<TF_ResourceTensor>:$ordering_token, 2312 2313 TF_AnyStrAttrOf<["Min", "Max", "Mul", "Add"]>:$merge_op, 2314 TF_AnyStrAttrOf<["Id", "Div"]>:$final_op, 2315 DefaultValuedAttr<StrAttr, "\"auto\"">:$communication_hint, 2316 DefaultValuedAttr<F32Attr, "0.0f">:$timeout_seconds, 2317 DefaultValuedAttr<I64Attr, "-1">:$max_subdivs_per_device 2318 ); 2319 2320 let results = (outs 2321 TF_FpOrI32OrI64Tensor:$data 2322 ); 2323 2324 TF_DerivedOperandSizeAttr Nordering_token = TF_DerivedOperandSizeAttr<4>; 2325 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2326} 2327 2328def TF_ComplexOp : TF_Op<"Complex", [NoSideEffect, ResultsBroadcastableShape]> { 2329 let summary = "Converts two real numbers to a complex number."; 2330 2331 let description = [{ 2332Given a tensor `real` representing the real part of a complex number, and a 2333tensor `imag` representing the imaginary part of a complex number, this 2334operation returns complex numbers elementwise of the form \\(a + bj\\), where 2335*a* represents the `real` part and *b* represents the `imag` part. 2336 2337The input tensors `real` and `imag` must have the same shape. 2338 2339For example: 2340 2341``` 2342# tensor 'real' is [2.25, 3.25] 2343# tensor `imag` is [4.75, 5.75] 2344tf.complex(real, imag) ==> [[2.25 + 4.75j], [3.25 + 5.75j]] 2345``` 2346 }]; 2347 2348 let arguments = (ins 2349 TF_F32OrF64Tensor:$real, 2350 TF_F32OrF64Tensor:$imag 2351 ); 2352 2353 let results = (outs 2354 TensorOf<[TF_Complex128, TF_Complex64]>:$out 2355 ); 2356 2357 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2358 TF_DerivedResultTypeAttr Tout = TF_DerivedResultTypeAttr<0>; 2359} 2360 2361def TF_ComplexAbsOp : TF_Op<"ComplexAbs", [NoSideEffect, SameOperandsAndResultShape]> { 2362 let summary = "Computes the complex absolute value of a tensor."; 2363 2364 let description = [{ 2365Given a tensor `x` of complex numbers, this operation returns a tensor of type 2366`float` or `double` that is the absolute value of each element in `x`. All 2367elements in `x` must be complex numbers of the form \\(a + bj\\). The absolute 2368value is computed as \\( \sqrt{a^2 + b^2}\\). 2369 2370For example: 2371 2372>>> x = tf.complex(3.0, 4.0) 2373>>> print((tf.raw_ops.ComplexAbs(x=x, Tout=tf.dtypes.float32, name=None)).numpy()) 23745.0 2375 }]; 2376 2377 let arguments = (ins 2378 TensorOf<[TF_Complex128, TF_Complex64]>:$x 2379 ); 2380 2381 let results = (outs 2382 TF_F32OrF64Tensor:$y 2383 ); 2384 2385 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2386 TF_DerivedResultTypeAttr Tout = TF_DerivedResultTypeAttr<0>; 2387} 2388 2389def TF_ConcatOp : TF_Op<"Concat", [NoSideEffect]> { 2390 let summary = "Concatenates tensors along one dimension."; 2391 2392 let arguments = (ins 2393 Arg<TF_Int32Tensor, [{0-D. The dimension along which to concatenate. Must be in the 2394range [0, rank(values)).}]>:$concat_dim, 2395 Arg<Variadic<TF_Tensor>, [{The `N` Tensors to concatenate. Their ranks and types must match, 2396and their sizes must match in all dimensions except `concat_dim`.}]>:$values 2397 ); 2398 2399 let results = (outs 2400 Res<TF_Tensor, [{A `Tensor` with the concatenation of values stacked along the 2401`concat_dim` dimension. This tensor's shape matches that of `values` except 2402in `concat_dim` where it has the sum of the sizes.}]>:$output 2403 ); 2404 2405 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<1>; 2406 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 2407 2408 let hasVerifier = 1; 2409 2410 let hasCanonicalizer = 1; 2411} 2412 2413def TF_ConcatOffsetOp : TF_Op<"ConcatOffset", [NoSideEffect]> { 2414 let summary = "Computes offsets of concat inputs within its output."; 2415 2416 let description = [{ 2417For example: 2418 2419``` 2420# 'x' is [2, 2, 7] 2421# 'y' is [2, 3, 7] 2422# 'z' is [2, 5, 7] 2423concat_offset(2, [x, y, z]) => [0, 0, 0], [0, 2, 0], [0, 5, 0] 2424``` 2425 2426This is typically used by gradient computations for a concat operation. 2427 }]; 2428 2429 let arguments = (ins 2430 Arg<TF_Int32Tensor, [{The dimension along which to concatenate.}]>:$concat_dim, 2431 Arg<Variadic<TF_Int32Tensor>, [{The `N` int32 vectors representing shape of tensors being concatenated.}]>:$shape 2432 ); 2433 2434 let results = (outs 2435 Res<Variadic<TF_Int32Tensor>, [{The `N` int32 vectors representing the starting offset 2436of input tensors within the concatenated output.}]>:$offset 2437 ); 2438 2439 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<1>; 2440 2441 let hasVerifier = 1; 2442 2443 let hasFolder = 1; 2444} 2445 2446def TF_ConcatV2Op : TF_Op<"ConcatV2", [NoSideEffect]> { 2447 let summary = "Concatenates tensors along one dimension."; 2448 2449 let arguments = (ins 2450 Arg<Variadic<TF_Tensor>, [{List of `N` Tensors to concatenate. Their ranks and types must match, 2451and their sizes must match in all dimensions except `concat_dim`.}]>:$values, 2452 Arg<TF_I32OrI64Tensor, [{0-D. The dimension along which to concatenate. Must be in the 2453range [-rank(values), rank(values)).}]>:$axis 2454 ); 2455 2456 let results = (outs 2457 Res<TF_Tensor, [{A `Tensor` with the concatenation of values stacked along the 2458`concat_dim` dimension. This tensor's shape matches that of `values` except 2459in `concat_dim` where it has the sum of the sizes.}]>:$output 2460 ); 2461 2462 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 2463 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2464 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 2465 2466 let hasVerifier = 1; 2467 2468 let hasCanonicalizer = 1; 2469} 2470 2471def TF_ConfigureDistributedTPUOp : TF_Op<"ConfigureDistributedTPU", []> { 2472 let summary = [{ 2473Sets up the centralized structures for a distributed TPU system. 2474 }]; 2475 2476 let arguments = (ins 2477 DefaultValuedAttr<StrAttr, "\"\"">:$embedding_config, 2478 DefaultValuedAttr<StrAttr, "\"\"">:$tpu_embedding_config, 2479 DefaultValuedAttr<BoolAttr, "false">:$is_global_init, 2480 DefaultValuedAttr<BoolAttr, "false">:$enable_whole_mesh_compilations, 2481 DefaultValuedAttr<BoolAttr, "true">:$compilation_failure_closes_chips, 2482 DefaultValuedAttr<I64Attr, "0">:$tpu_cancellation_closes_chips 2483 ); 2484 2485 let results = (outs 2486 Res<TF_StrTensor, [{A serialized tensorflow.tpu.TopologyProto that describes the TPU 2487topology.}]>:$topology 2488 ); 2489} 2490 2491def TF_ConfigureTPUEmbeddingOp : TF_Op<"ConfigureTPUEmbedding", []> { 2492 let summary = "Sets up TPUEmbedding in a distributed TPU system."; 2493 2494 let arguments = (ins 2495 StrAttr:$config 2496 ); 2497 2498 let results = (outs); 2499} 2500 2501def TF_ConfigureTPUEmbeddingHostOp : TF_Op<"ConfigureTPUEmbeddingHost", []> { 2502 let summary = "An op that configures the TPUEmbedding software on a host."; 2503 2504 let arguments = (ins 2505 Arg<TF_StrTensor, [{A string-encoded common configuration proto containing metadata 2506about the TPUEmbedding partitioner output.}]>:$common_config, 2507 Arg<TF_StrTensor, [{A string-encoded memory config proto containing metadata about 2508the memory allocations reserved for TPUEmbedding.}]>:$memory_config, 2509 2510 StrAttr:$config 2511 ); 2512 2513 let results = (outs 2514 Res<TF_StrTensor, [{A string containing metadata about the hostname and RPC port 2515used for communication with this host.}]>:$network_config 2516 ); 2517} 2518 2519def TF_ConfigureTPUEmbeddingMemoryOp : TF_Op<"ConfigureTPUEmbeddingMemory", []> { 2520 let summary = "An op that configures the TPUEmbedding software on a host."; 2521 2522 let arguments = (ins 2523 Arg<TF_StrTensor, [{A string-encoded CommonConfiguration proto containing metadata 2524about the TPUEmbedding partitioner output and the HBM size (in bytes) required 2525for operation.}]>:$common_config 2526 ); 2527 2528 let results = (outs 2529 Res<TF_StrTensor, [{A string-encoded memory configuration containing metadata about 2530the memory allocations reserved for TPUEmbedding.}]>:$memory_config 2531 ); 2532} 2533 2534def TF_ConjOp : TF_Op<"Conj", [Involution, NoSideEffect, SameOperandsAndResultType]> { 2535 let summary = "Returns the complex conjugate of a complex number."; 2536 2537 let description = [{ 2538Given a tensor `input` of complex numbers, this operation returns a tensor of 2539complex numbers that are the complex conjugate of each element in `input`. The 2540complex numbers in `input` must be of the form \\(a + bj\\), where *a* is the 2541real part and *b* is the imaginary part. 2542 2543The complex conjugate returned by this operation is of the form \\(a - bj\\). 2544 2545For example: 2546 2547``` 2548# tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] 2549tf.conj(input) ==> [-2.25 - 4.75j, 3.25 - 5.75j] 2550``` 2551 }]; 2552 2553 let arguments = (ins 2554 TensorOf<[TF_Complex128, TF_Complex64, TF_Variant]>:$input 2555 ); 2556 2557 let results = (outs 2558 TensorOf<[TF_Complex128, TF_Complex64, TF_Variant]>:$output 2559 ); 2560 2561 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2562} 2563 2564def TF_ConjugateTransposeOp : TF_Op<"ConjugateTranspose", [NoSideEffect]> { 2565 let summary = [{ 2566Shuffle dimensions of x according to a permutation and conjugate the result. 2567 }]; 2568 2569 let description = [{ 2570The output `y` has the same rank as `x`. The shapes of `x` and `y` satisfy: 2571 `y.shape[i] == x.shape[perm[i]] for i in [0, 1, ..., rank(x) - 1]` 2572 `y[i,j,k,...,s,t,u] == conj(x[perm[i], perm[j], perm[k],...,perm[s], perm[t], perm[u]])` 2573 }]; 2574 2575 let arguments = (ins 2576 TF_Tensor:$x, 2577 TF_I32OrI64Tensor:$perm 2578 ); 2579 2580 let results = (outs 2581 TF_Tensor:$y 2582 ); 2583 2584 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2585 TF_DerivedOperandTypeAttr Tperm = TF_DerivedOperandTypeAttr<1>; 2586} 2587 2588def TF_ConnectTPUEmbeddingHostsOp : TF_Op<"ConnectTPUEmbeddingHosts", []> { 2589 let summary = [{ 2590An op that sets up communication between TPUEmbedding host software instances 2591 }]; 2592 2593 let description = [{ 2594after ConfigureTPUEmbeddingHost has been called on each host. 2595 }]; 2596 2597 let arguments = (ins 2598 Arg<Variadic<TF_StrTensor>, [{Strings containing metadata about the hostname and RPC port 2599used for communication with all hosts.}]>:$network_configs 2600 ); 2601 2602 let results = (outs); 2603 2604 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 2605} 2606 2607def TF_Conv2DOp : TF_Op<"Conv2D", [InferTensorType, NoSideEffect, TF_LayoutSensitiveInterface]> { 2608 let summary = [{ 2609Computes a 2-D convolution given 4-D `input` and `filter` tensors. 2610 }]; 2611 2612 let description = [{ 2613Given an input tensor of shape `[batch, in_height, in_width, in_channels]` 2614and a filter / kernel tensor of shape 2615`[filter_height, filter_width, in_channels, out_channels]`, this op 2616performs the following: 2617 26181. Flattens the filter to a 2-D matrix with shape 2619 `[filter_height * filter_width * in_channels, output_channels]`. 26202. Extracts image patches from the input tensor to form a *virtual* 2621 tensor of shape `[batch, out_height, out_width, 2622 filter_height * filter_width * in_channels]`. 26233. For each patch, right-multiplies the filter matrix and the image patch 2624 vector. 2625 2626In detail, with the default NHWC format, 2627 2628 output[b, i, j, k] = 2629 sum_{di, dj, q} input[b, strides[1] * i + di, strides[2] * j + dj, q] * 2630 filter[di, dj, q, k] 2631 2632Must have `strides[0] = strides[3] = 1`. For the most common case of the same 2633horizontal and vertices strides, `strides = [1, stride, stride, 1]`. 2634 }]; 2635 2636 let arguments = (ins 2637 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int32]>, [{A 4-D tensor. The dimension order is interpreted according to the value 2638of `data_format`, see below for details.}]>:$input, 2639 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int32]>, [{A 4-D tensor of shape 2640`[filter_height, filter_width, in_channels, out_channels]`}]>:$filter, 2641 2642 I64ArrayAttr:$strides, 2643 DefaultValuedAttr<BoolAttr, "true">:$use_cudnn_on_gpu, 2644 TF_AnyStrAttrOf<["SAME", "VALID", "EXPLICIT"]>:$padding, 2645 DefaultValuedAttr<I64ArrayAttr, "{}">:$explicit_paddings, 2646 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 2647 DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1}">:$dilations 2648 ); 2649 2650 let results = (outs 2651 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int32]>, [{A 4-D tensor. The dimension order is determined by the value of 2652`data_format`, see below for details.}]>:$output 2653 ); 2654 2655 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2656 2657 let hasVerifier = 1; 2658 2659 let extraClassDeclaration = [{ 2660 // TF_LayoutSensitiveInterface: 2661 SmallVector<unsigned, 4> GetLayoutDependentArgs() { return {0}; } 2662 SmallVector<unsigned, 4> GetLayoutDependentResults() { return {0}; } 2663 StringRef GetOptimalLayout(const RuntimeDevices& devices); 2664 LogicalResult UpdateDataFormat(StringRef data_format); 2665 // InferTypeOpInterface: 2666 static bool isCompatibleReturnTypes(TypeRange l, TypeRange r) { 2667 return ArraysAreCastCompatible(l, r); 2668 } 2669 }]; 2670} 2671 2672def TF_Conv2DBackpropFilterOp : TF_Op<"Conv2DBackpropFilter", [NoSideEffect, TF_LayoutSensitiveInterface]> { 2673 let summary = [{ 2674Computes the gradients of convolution with respect to the filter. 2675 }]; 2676 2677 let arguments = (ins 2678 Arg<TF_FloatTensor, [{4-D with shape `[batch, in_height, in_width, in_channels]`.}]>:$input, 2679 Arg<TF_Int32Tensor, [{An integer vector representing the tensor shape of `filter`, 2680where `filter` is a 4-D 2681`[filter_height, filter_width, in_channels, out_channels]` tensor.}]>:$filter_sizes, 2682 Arg<TF_FloatTensor, [{4-D with shape `[batch, out_height, out_width, out_channels]`. 2683Gradients w.r.t. the output of the convolution.}]>:$out_backprop, 2684 2685 I64ArrayAttr:$strides, 2686 DefaultValuedAttr<BoolAttr, "true">:$use_cudnn_on_gpu, 2687 TF_AnyStrAttrOf<["SAME", "VALID", "EXPLICIT"]>:$padding, 2688 DefaultValuedAttr<I64ArrayAttr, "{}">:$explicit_paddings, 2689 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 2690 DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1}">:$dilations 2691 ); 2692 2693 let results = (outs 2694 Res<TF_FloatTensor, [{4-D with shape 2695`[filter_height, filter_width, in_channels, out_channels]`. Gradient w.r.t. 2696the `filter` input of the convolution.}]>:$output 2697 ); 2698 2699 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2700 2701 let extraClassDeclaration = [{ 2702 // TF_LayoutSensitiveInterface: 2703 SmallVector<unsigned, 4> GetLayoutDependentArgs() { return {0, 2}; } 2704 SmallVector<unsigned, 4> GetLayoutDependentResults() { return {}; } 2705 StringRef GetOptimalLayout(const RuntimeDevices& devices); 2706 LogicalResult UpdateDataFormat(StringRef data_format); 2707 }]; 2708} 2709 2710def TF_Conv2DBackpropInputOp : TF_Op<"Conv2DBackpropInput", [NoSideEffect, TF_LayoutSensitiveInterface]> { 2711 let summary = [{ 2712Computes the gradients of convolution with respect to the input. 2713 }]; 2714 2715 let arguments = (ins 2716 Arg<TF_Int32Tensor, [{An integer vector representing the shape of `input`, 2717where `input` is a 4-D `[batch, height, width, channels]` tensor.}]>:$input_sizes, 2718 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int32]>, [{4-D with shape 2719`[filter_height, filter_width, in_channels, out_channels]`.}]>:$filter, 2720 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int32]>, [{4-D with shape `[batch, out_height, out_width, out_channels]`. 2721Gradients w.r.t. the output of the convolution.}]>:$out_backprop, 2722 2723 I64ArrayAttr:$strides, 2724 DefaultValuedAttr<BoolAttr, "true">:$use_cudnn_on_gpu, 2725 TF_AnyStrAttrOf<["SAME", "VALID", "EXPLICIT"]>:$padding, 2726 DefaultValuedAttr<I64ArrayAttr, "{}">:$explicit_paddings, 2727 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 2728 DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1}">:$dilations 2729 ); 2730 2731 let results = (outs 2732 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int32]>, [{4-D with shape `[batch, in_height, in_width, in_channels]`. Gradient 2733w.r.t. the input of the convolution.}]>:$output 2734 ); 2735 2736 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 2737 2738 let hasVerifier = 1; 2739 2740 let extraClassDeclaration = [{ 2741 // TF_LayoutSensitiveInterface: 2742 SmallVector<unsigned, 4> GetLayoutDependentArgs() { return {2}; } 2743 SmallVector<unsigned, 4> GetLayoutDependentResults() { return {0}; } 2744 StringRef GetOptimalLayout(const RuntimeDevices& devices); 2745 LogicalResult UpdateDataFormat(StringRef data_format); 2746 }]; 2747} 2748 2749def TF_Conv3DOp : TF_Op<"Conv3D", [InferTensorType, NoSideEffect]> { 2750 let summary = [{ 2751Computes a 3-D convolution given 5-D `input` and `filter` tensors. 2752 }]; 2753 2754 let description = [{ 2755In signal processing, cross-correlation is a measure of similarity of 2756two waveforms as a function of a time-lag applied to one of them. This 2757is also known as a sliding dot product or sliding inner-product. 2758 2759Our Conv3D implements a form of cross-correlation. 2760 }]; 2761 2762 let arguments = (ins 2763 Arg<TF_FloatTensor, [{Shape `[batch, in_depth, in_height, in_width, in_channels]`.}]>:$input, 2764 Arg<TF_FloatTensor, [{Shape `[filter_depth, filter_height, filter_width, in_channels, 2765out_channels]`. `in_channels` must match between `input` and `filter`.}]>:$filter, 2766 2767 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$strides, 2768 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 2769 DefaultValuedAttr<TF_AnyStrAttrOf<["NDHWC", "NCDHW"]>, "\"NDHWC\"">:$data_format, 2770 DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1, 1}">:$dilations 2771 ); 2772 2773 let results = (outs 2774 TF_FloatTensor:$output 2775 ); 2776 2777 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2778 2779 let hasVerifier = 1; 2780 2781 let extraClassDeclaration = [{ 2782 // InferTypeOpInterface: 2783 static bool isCompatibleReturnTypes(TypeRange l, TypeRange r) { 2784 return ArraysAreCastCompatible(l, r); 2785 } 2786 }]; 2787 2788} 2789 2790def TF_Conv3DBackpropFilterV2Op : TF_Op<"Conv3DBackpropFilterV2", [NoSideEffect]> { 2791 let summary = [{ 2792Computes the gradients of 3-D convolution with respect to the filter. 2793 }]; 2794 2795 let arguments = (ins 2796 Arg<TF_FloatTensor, [{Shape `[batch, depth, rows, cols, in_channels]`.}]>:$input, 2797 Arg<TF_Int32Tensor, [{An integer vector representing the tensor shape of `filter`, 2798where `filter` is a 5-D 2799`[filter_depth, filter_height, filter_width, in_channels, out_channels]` 2800tensor.}]>:$filter_sizes, 2801 Arg<TF_FloatTensor, [{Backprop signal of shape `[batch, out_depth, out_rows, out_cols, 2802out_channels]`.}]>:$out_backprop, 2803 2804 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$strides, 2805 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 2806 DefaultValuedAttr<TF_AnyStrAttrOf<["NDHWC", "NCDHW"]>, "\"NDHWC\"">:$data_format, 2807 DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1, 1}">:$dilations 2808 ); 2809 2810 let results = (outs 2811 TF_FloatTensor:$output 2812 ); 2813 2814 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2815} 2816 2817def TF_Conv3DBackpropInputV2Op : TF_Op<"Conv3DBackpropInputV2", [NoSideEffect]> { 2818 let summary = [{ 2819Computes the gradients of 3-D convolution with respect to the input. 2820 }]; 2821 2822 let arguments = (ins 2823 Arg<TF_I32OrI64Tensor, [{An integer vector representing the tensor shape of `input`, 2824where `input` is a 5-D 2825`[batch, depth, rows, cols, in_channels]` tensor.}]>:$input_sizes, 2826 Arg<TF_FloatTensor, [{Shape `[depth, rows, cols, in_channels, out_channels]`. 2827`in_channels` must match between `input` and `filter`.}]>:$filter, 2828 Arg<TF_FloatTensor, [{Backprop signal of shape `[batch, out_depth, out_rows, out_cols, 2829out_channels]`.}]>:$out_backprop, 2830 2831 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$strides, 2832 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 2833 DefaultValuedAttr<TF_AnyStrAttrOf<["NDHWC", "NCDHW"]>, "\"NDHWC\"">:$data_format, 2834 DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1, 1}">:$dilations 2835 ); 2836 2837 let results = (outs 2838 TF_FloatTensor:$output 2839 ); 2840 2841 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 2842 TF_DerivedOperandTypeAttr Tshape = TF_DerivedOperandTypeAttr<0>; 2843} 2844 2845def TF_CosOp : TF_Op<"Cos", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 2846 let summary = "Computes cos of x element-wise."; 2847 2848 let description = [{ 2849Given an input tensor, this function computes cosine of every 2850 element in the tensor. Input range is `(-inf, inf)` and 2851 output range is `[-1,1]`. If input lies outside the boundary, `nan` 2852 is returned. 2853 2854 ```python 2855 x = tf.constant([-float("inf"), -9, -0.5, 1, 1.2, 200, 10000, float("inf")]) 2856 tf.math.cos(x) ==> [nan -0.91113025 0.87758255 0.5403023 0.36235774 0.48718765 -0.95215535 nan] 2857 ``` 2858 }]; 2859 2860 let arguments = (ins 2861 TF_FpOrComplexTensor:$x 2862 ); 2863 2864 let results = (outs 2865 TF_FpOrComplexTensor:$y 2866 ); 2867 2868 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2869} 2870 2871def TF_CoshOp : TF_Op<"Cosh", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 2872 let summary = "Computes hyperbolic cosine of x element-wise."; 2873 2874 let description = [{ 2875Given an input tensor, this function computes hyperbolic cosine of every 2876 element in the tensor. Input range is `[-inf, inf]` and output range 2877 is `[1, inf]`. 2878 2879 ```python 2880 x = tf.constant([-float("inf"), -9, -0.5, 1, 1.2, 2, 10, float("inf")]) 2881 tf.math.cosh(x) ==> [inf 4.0515420e+03 1.1276259e+00 1.5430807e+00 1.8106556e+00 3.7621956e+00 1.1013233e+04 inf] 2882 ``` 2883 }]; 2884 2885 let arguments = (ins 2886 TF_FpOrComplexTensor:$x 2887 ); 2888 2889 let results = (outs 2890 TF_FpOrComplexTensor:$y 2891 ); 2892 2893 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2894} 2895 2896def TF_CrossOp : TF_Op<"Cross", [NoSideEffect, SameOperandsAndResultType]> { 2897 let summary = "Compute the pairwise cross product."; 2898 2899 let description = [{ 2900`a` and `b` must be the same shape; they can either be simple 3-element vectors, 2901or any shape where the innermost dimension is 3. In the latter case, each pair 2902of corresponding 3-element vectors is cross-multiplied independently. 2903 }]; 2904 2905 let arguments = (ins 2906 Arg<TF_IntOrFpTensor, [{A tensor containing 3-element vectors.}]>:$a, 2907 Arg<TF_IntOrFpTensor, [{Another tensor, of same type and shape as `a`.}]>:$b 2908 ); 2909 2910 let results = (outs 2911 Res<TF_IntOrFpTensor, [{Pairwise cross product of the vectors in `a` and `b`.}]>:$product 2912 ); 2913 2914 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2915} 2916 2917def TF_CrossReplicaSumOp : TF_Op<"CrossReplicaSum", [NoSideEffect, TF_AllTypesMatch<["input", "output"]>, TF_NoConstantFold]> { 2918 let summary = "An Op to sum inputs across replicated TPU instances."; 2919 2920 let description = [{ 2921Each instance supplies its own input. 2922 2923For example, suppose there are 8 TPU instances: `[A, B, C, D, E, F, G, H]`. 2924Passing group_assignment=`[[0,2,4,6],[1,3,5,7]]` sets `A, C, E, G` as group 0, 2925and `B, D, F, H` as group 1. Thus we get the outputs: 2926`[A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H]`. 2927 }]; 2928 2929 let arguments = (ins 2930 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Uint32]>, [{The local input to the sum.}]>:$input, 2931 Arg<TF_Int32Tensor, [{An int32 tensor with shape 2932[num_groups, num_replicas_per_group]. `group_assignment[i]` represents the 2933replica ids in the ith subgroup.}]>:$group_assignment 2934 ); 2935 2936 let results = (outs 2937 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Uint32]>, [{The sum of all the distributed inputs.}]>:$output 2938 ); 2939 2940 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2941} 2942 2943def TF_CumprodOp : TF_Op<"Cumprod", [NoSideEffect, TF_AllTypesMatch<["x", "out"]>]> { 2944 let summary = [{ 2945Compute the cumulative product of the tensor `x` along `axis`. 2946 }]; 2947 2948 let description = [{ 2949By default, this op performs an inclusive cumprod, which means that the first 2950element of the input is identical to the first element of the output: 2951 2952```python 2953tf.cumprod([a, b, c]) # => [a, a * b, a * b * c] 2954``` 2955 2956By setting the `exclusive` kwarg to `True`, an exclusive cumprod is 2957performed instead: 2958 2959```python 2960tf.cumprod([a, b, c], exclusive=True) # => [1, a, a * b] 2961``` 2962 2963By setting the `reverse` kwarg to `True`, the cumprod is performed in the 2964opposite direction: 2965 2966```python 2967tf.cumprod([a, b, c], reverse=True) # => [a * b * c, b * c, c] 2968``` 2969 2970This is more efficient than using separate `tf.reverse` ops. 2971 2972The `reverse` and `exclusive` kwargs can also be combined: 2973 2974```python 2975tf.cumprod([a, b, c], exclusive=True, reverse=True) # => [b * c, c, 1] 2976``` 2977 }]; 2978 2979 let arguments = (ins 2980 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A `Tensor`. Must be one of the following types: `float32`, `float64`, 2981`int64`, `int32`, `uint8`, `uint16`, `int16`, `int8`, `complex64`, 2982`complex128`, `qint8`, `quint8`, `qint32`, `half`.}]>:$x, 2983 Arg<TF_I32OrI64Tensor, [{A `Tensor` of type `int32` (default: 0). Must be in the range 2984`[-rank(x), rank(x))`.}]>:$axis, 2985 2986 DefaultValuedAttr<BoolAttr, "false">:$exclusive, 2987 DefaultValuedAttr<BoolAttr, "false">:$reverse 2988 ); 2989 2990 let results = (outs 2991 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$out 2992 ); 2993 2994 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 2995 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 2996 2997 let hasVerifier = 1; 2998} 2999 3000def TF_CumsumOp : TF_Op<"Cumsum", [NoSideEffect, TF_AllTypesMatch<["x", "out"]>]> { 3001 let summary = "Compute the cumulative sum of the tensor `x` along `axis`."; 3002 3003 let description = [{ 3004By default, this op performs an inclusive cumsum, which means that the first 3005element of the input is identical to the first element of the output: 3006 3007```python 3008tf.cumsum([a, b, c]) # => [a, a + b, a + b + c] 3009``` 3010 3011By setting the `exclusive` kwarg to `True`, an exclusive cumsum is 3012performed instead: 3013 3014```python 3015tf.cumsum([a, b, c], exclusive=True) # => [0, a, a + b] 3016``` 3017 3018By setting the `reverse` kwarg to `True`, the cumsum is performed in the 3019opposite direction: 3020 3021```python 3022tf.cumsum([a, b, c], reverse=True) # => [a + b + c, b + c, c] 3023``` 3024 3025This is more efficient than using separate `tf.reverse` ops. 3026 3027The `reverse` and `exclusive` kwargs can also be combined: 3028 3029```python 3030tf.cumsum([a, b, c], exclusive=True, reverse=True) # => [b + c, c, 0] 3031``` 3032 }]; 3033 3034 let arguments = (ins 3035 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A `Tensor`. Must be one of the following types: `float32`, `float64`, 3036`int64`, `int32`, `uint8`, `uint16`, `int16`, `int8`, `complex64`, 3037`complex128`, `qint8`, `quint8`, `qint32`, `half`.}]>:$x, 3038 Arg<TF_I32OrI64Tensor, [{A `Tensor` of type `int32` (default: 0). Must be in the range 3039`[-rank(x), rank(x))`.}]>:$axis, 3040 3041 DefaultValuedAttr<BoolAttr, "false">:$exclusive, 3042 DefaultValuedAttr<BoolAttr, "false">:$reverse 3043 ); 3044 3045 let results = (outs 3046 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$out 3047 ); 3048 3049 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3050 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 3051 3052 let hasVerifier = 1; 3053} 3054 3055def TF_DataFormatDimMapOp : TF_Op<"DataFormatDimMap", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 3056 let summary = [{ 3057Returns the dimension index in the destination data format given the one in 3058 }]; 3059 3060 let description = [{ 3061the source data format. 3062 }]; 3063 3064 let arguments = (ins 3065 Arg<TF_I32OrI64Tensor, [{A Tensor with each element as a dimension index in source data format. 3066Must be in the range [-4, 4).}]>:$x, 3067 3068 DefaultValuedAttr<StrAttr, "\"NHWC\"">:$src_format, 3069 DefaultValuedAttr<StrAttr, "\"NCHW\"">:$dst_format 3070 ); 3071 3072 let results = (outs 3073 Res<TF_I32OrI64Tensor, [{A Tensor with each element as a dimension index in destination data format.}]>:$y 3074 ); 3075 3076 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3077} 3078 3079def TF_DataFormatVecPermuteOp : TF_Op<"DataFormatVecPermute", [NoSideEffect, SameOperandsAndResultType]> { 3080 let summary = "Permute input tensor from `src_format` to `dst_format`."; 3081 3082 let description = [{ 3083Given source and destination format strings of length n=4 or 5, the input 3084tensor must be a vector of size n or n-2, or a 2D tensor of shape 3085(n, 2) or (n-2, 2). 3086 3087If the first dimension of the input tensor is n-2, it is assumed that 3088non-spatial dimensions are omitted (i.e `N`, `C`). 3089 3090For example, with `src_format` of `NHWC`, `dst_format` of `NCHW`, and input: 3091``` 3092[1, 2, 3, 4] 3093``` 3094, the output will be: 3095``` 3096[1, 4, 2, 3] 3097``` 3098With `src_format` of `NDHWC`, `dst_format` of `NCDHW`, and input: 3099``` 3100[[1, 6], [2, 7], [3, 8], [4, 9], [5, 10]] 3101``` 3102, the output will be: 3103``` 3104[[1, 6], [5, 10], [2, 7], [3, 8], [4, 9]] 3105``` 3106With `src_format` of `NHWC`, `dst_format` of `NCHW`, and input: 3107``` 3108[1, 2] 3109``` 3110, the output will be: 3111``` 3112[1, 2] 3113``` 3114 }]; 3115 3116 let arguments = (ins 3117 Arg<TF_I32OrI64Tensor, [{Tensor of rank 1 or 2 in source data format.}]>:$x, 3118 3119 DefaultValuedAttr<StrAttr, "\"NHWC\"">:$src_format, 3120 DefaultValuedAttr<StrAttr, "\"NCHW\"">:$dst_format 3121 ); 3122 3123 let results = (outs 3124 Res<TF_I32OrI64Tensor, [{Tensor of rank 1 or 2 in destination data format.}]>:$y 3125 ); 3126 3127 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3128 3129 let hasVerifier = 1; 3130} 3131 3132def TF_DebugIdentityV2Op : TF_Op<"DebugIdentityV2", []> { 3133 let summary = "Debug Identity V2 Op."; 3134 3135 let description = [{ 3136Provides an identity mapping from input to output, while writing the content of 3137the input tensor by calling DebugEventsWriter. 3138 3139The semantics of the input tensor depends on tensor_debug_mode. In typical 3140usage, the input tensor comes directly from the user computation only when 3141graph_debug_mode is FULL_TENSOR (see protobuf/debug_event.proto for a 3142list of all the possible values of graph_debug_mode). For the other debug modes, 3143the input tensor should be produced by an additional op or subgraph that 3144computes summary information about one or more tensors. 3145 }]; 3146 3147 let arguments = (ins 3148 Arg<TF_Tensor, [{Input tensor, non-Reference type}]>:$input, 3149 3150 DefaultValuedAttr<StrAttr, "\"\"">:$tfdbg_context_id, 3151 DefaultValuedAttr<StrAttr, "\"\"">:$op_name, 3152 DefaultValuedAttr<I64Attr, "-1">:$output_slot, 3153 DefaultValuedAttr<I64Attr, "-1">:$tensor_debug_mode, 3154 DefaultValuedAttr<StrArrayAttr, "{}">:$debug_urls, 3155 DefaultValuedAttr<I64Attr, "1000">:$circular_buffer_size, 3156 DefaultValuedAttr<StrAttr, "\"\"">:$tfdbg_run_id 3157 ); 3158 3159 let results = (outs 3160 TF_Tensor:$output 3161 ); 3162 3163 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3164} 3165 3166def TF_DecodeAndCropJpegOp : TF_Op<"DecodeAndCropJpeg", [NoSideEffect]> { 3167 let summary = "Decode and Crop a JPEG-encoded image to a uint8 tensor."; 3168 3169 let description = [{ 3170The attr `channels` indicates the desired number of color channels for the 3171decoded image. 3172 3173Accepted values are: 3174 3175* 0: Use the number of channels in the JPEG-encoded image. 3176* 1: output a grayscale image. 3177* 3: output an RGB image. 3178 3179If needed, the JPEG-encoded image is transformed to match the requested number 3180of color channels. 3181 3182The attr `ratio` allows downscaling the image by an integer factor during 3183decoding. Allowed values are: 1, 2, 4, and 8. This is much faster than 3184downscaling the image later. 3185 3186 3187It is equivalent to a combination of decode and crop, but much faster by only 3188decoding partial jpeg image. 3189 }]; 3190 3191 let arguments = (ins 3192 Arg<TF_StrTensor, [{0-D. The JPEG-encoded image.}]>:$contents, 3193 Arg<TF_Int32Tensor, [{1-D. The crop window: [crop_y, crop_x, crop_height, crop_width].}]>:$crop_window, 3194 3195 DefaultValuedAttr<I64Attr, "0">:$channels, 3196 DefaultValuedAttr<I64Attr, "1">:$ratio, 3197 DefaultValuedAttr<BoolAttr, "true">:$fancy_upscaling, 3198 DefaultValuedAttr<BoolAttr, "false">:$try_recover_truncated, 3199 DefaultValuedAttr<F32Attr, "1.0f">:$acceptable_fraction, 3200 DefaultValuedAttr<StrAttr, "\"\"">:$dct_method 3201 ); 3202 3203 let results = (outs 3204 Res<TF_Uint8Tensor, [{3-D with shape `[height, width, channels]`..}]>:$image 3205 ); 3206} 3207 3208def TF_DecodeGifOp : TF_Op<"DecodeGif", [NoSideEffect]> { 3209 let summary = "Decode the frame(s) of a GIF-encoded image to a uint8 tensor."; 3210 3211 let description = [{ 3212GIF images with frame or transparency compression are not supported. 3213On Linux and MacOS systems, convert animated GIFs from compressed to 3214uncompressed by running: 3215 3216 convert $src.gif -coalesce $dst.gif 3217 3218This op also supports decoding JPEGs and PNGs, though it is cleaner to use 3219`tf.io.decode_image`. 3220 }]; 3221 3222 let arguments = (ins 3223 Arg<TF_StrTensor, [{0-D. The GIF-encoded image.}]>:$contents 3224 ); 3225 3226 let results = (outs 3227 Res<TF_Uint8Tensor, [{4-D with shape `[num_frames, height, width, 3]`. RGB channel order.}]>:$image 3228 ); 3229} 3230 3231def TF_DecodeJpegOp : TF_Op<"DecodeJpeg", [NoSideEffect]> { 3232 let summary = "Decode a JPEG-encoded image to a uint8 tensor."; 3233 3234 let description = [{ 3235The attr `channels` indicates the desired number of color channels for the 3236decoded image. 3237 3238Accepted values are: 3239 3240* 0: Use the number of channels in the JPEG-encoded image. 3241* 1: output a grayscale image. 3242* 3: output an RGB image. 3243 3244If needed, the JPEG-encoded image is transformed to match the requested number 3245of color channels. 3246 3247The attr `ratio` allows downscaling the image by an integer factor during 3248decoding. Allowed values are: 1, 2, 4, and 8. This is much faster than 3249downscaling the image later. 3250 3251 3252This op also supports decoding PNGs and non-animated GIFs since the interface is 3253the same, though it is cleaner to use `tf.io.decode_image`. 3254 }]; 3255 3256 let arguments = (ins 3257 Arg<TF_StrTensor, [{0-D. The JPEG-encoded image.}]>:$contents, 3258 3259 DefaultValuedAttr<I64Attr, "0">:$channels, 3260 DefaultValuedAttr<I64Attr, "1">:$ratio, 3261 DefaultValuedAttr<BoolAttr, "true">:$fancy_upscaling, 3262 DefaultValuedAttr<BoolAttr, "false">:$try_recover_truncated, 3263 DefaultValuedAttr<F32Attr, "1.0f">:$acceptable_fraction, 3264 DefaultValuedAttr<StrAttr, "\"\"">:$dct_method 3265 ); 3266 3267 let results = (outs 3268 Res<TF_Uint8Tensor, [{3-D with shape `[height, width, channels]`..}]>:$image 3269 ); 3270} 3271 3272def TF_DecodePaddedRawOp : TF_Op<"DecodePaddedRaw", [NoSideEffect]> { 3273 let summary = "Reinterpret the bytes of a string as a vector of numbers."; 3274 3275 let arguments = (ins 3276 Arg<TF_StrTensor, [{Tensor of string to be decoded.}]>:$input_bytes, 3277 Arg<TF_Int32Tensor, [{Length in bytes for each element of the decoded output. Must be a multiple 3278of the size of the output type.}]>:$fixed_length, 3279 3280 DefaultValuedAttr<BoolAttr, "true">:$little_endian 3281 ); 3282 3283 let results = (outs 3284 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint8]>, [{A Tensor with one more dimension than the input `bytes`. The added dimension 3285will have size equal to the length of the elements of `bytes` divided by the 3286number of bytes to represent `out_type`.}]>:$output 3287 ); 3288 3289 TF_DerivedResultTypeAttr out_type = TF_DerivedResultTypeAttr<0>; 3290} 3291 3292def TF_DecodePngOp : TF_Op<"DecodePng", [NoSideEffect]> { 3293 let summary = "Decode a PNG-encoded image to a uint8 or uint16 tensor."; 3294 3295 let description = [{ 3296The attr `channels` indicates the desired number of color channels for the 3297decoded image. 3298 3299Accepted values are: 3300 3301* 0: Use the number of channels in the PNG-encoded image. 3302* 1: output a grayscale image. 3303* 3: output an RGB image. 3304* 4: output an RGBA image. 3305 3306If needed, the PNG-encoded image is transformed to match the requested number 3307of color channels. 3308 3309This op also supports decoding JPEGs and non-animated GIFs since the interface 3310is the same, though it is cleaner to use `tf.io.decode_image`. 3311 }]; 3312 3313 let arguments = (ins 3314 Arg<TF_StrTensor, [{0-D. The PNG-encoded image.}]>:$contents, 3315 3316 DefaultValuedAttr<I64Attr, "0">:$channels 3317 ); 3318 3319 let results = (outs 3320 Res<TensorOf<[TF_Uint16, TF_Uint8]>, [{3-D with shape `[height, width, channels]`.}]>:$image 3321 ); 3322 3323 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 3324} 3325 3326def TF_DeleteIteratorOp : TF_Op<"DeleteIterator", []> { 3327 let summary = "A container for an iterator resource."; 3328 3329 let arguments = (ins 3330 Arg<TF_ResourceTensor, [{A handle to the iterator to delete.}], [TF_DatasetIteratorFree]>:$handle, 3331 Arg<TF_VariantTensor, [{A variant deleter.}]>:$deleter 3332 ); 3333 3334 let results = (outs); 3335} 3336 3337def TF_DeleteMemoryCacheOp : TF_Op<"DeleteMemoryCache", []> { 3338 let summary = ""; 3339 3340 let arguments = (ins 3341 Arg<TF_ResourceTensor, "", [TF_DatasetMemoryCacheFree]>:$handle, 3342 TF_VariantTensor:$deleter 3343 ); 3344 3345 let results = (outs); 3346} 3347 3348def TF_DeleteMultiDeviceIteratorOp : TF_Op<"DeleteMultiDeviceIterator", []> { 3349 let summary = "A container for an iterator resource."; 3350 3351 let arguments = (ins 3352 Arg<TF_ResourceTensor, [{A handle to the multi device iterator to delete.}], [TF_DatasetIteratorFree]>:$multi_device_iterator, 3353 Arg<Variadic<TF_ResourceTensor>, [{A list of iterator handles (unused). This is added so that automatic control dependencies get added during function tracing that ensure this op runs after all the dependent iterators are deleted.}], [TF_DatasetIteratorRead]>:$iterators, 3354 Arg<TF_VariantTensor, [{A variant deleter.}]>:$deleter 3355 ); 3356 3357 let results = (outs); 3358 3359 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<1>; 3360} 3361 3362def TF_DeleteRandomSeedGeneratorOp : TF_Op<"DeleteRandomSeedGenerator", []> { 3363 let summary = ""; 3364 3365 let arguments = (ins 3366 Arg<TF_ResourceTensor, "", [TF_DatasetSeedGeneratorFree]>:$handle, 3367 TF_VariantTensor:$deleter 3368 ); 3369 3370 let results = (outs); 3371} 3372 3373def TF_DeleteSeedGeneratorOp : TF_Op<"DeleteSeedGenerator", []> { 3374 let summary = ""; 3375 3376 let arguments = (ins 3377 Arg<TF_ResourceTensor, "", [TF_DatasetSeedGeneratorFree]>:$handle, 3378 TF_VariantTensor:$deleter 3379 ); 3380 3381 let results = (outs); 3382} 3383 3384def TF_DepthToSpaceOp : TF_Op<"DepthToSpace", [NoSideEffect]> { 3385 let summary = "DepthToSpace for tensors of type T."; 3386 3387 let description = [{ 3388Rearranges data from depth into blocks of spatial data. 3389This is the reverse transformation of SpaceToDepth. More specifically, 3390this op outputs a copy of the input tensor where values from the `depth` 3391dimension are moved in spatial blocks to the `height` and `width` dimensions. 3392The attr `block_size` indicates the input block size and how the data is moved. 3393 3394 * Chunks of data of size `block_size * block_size` from depth are rearranged 3395 into non-overlapping blocks of size `block_size x block_size` 3396 * The width of the output tensor is `input_depth * block_size`, whereas the 3397 height is `input_height * block_size`. 3398 * The Y, X coordinates within each block of the output image are determined 3399 by the high order component of the input channel index. 3400 * The depth of the input tensor must be divisible by 3401 `block_size * block_size`. 3402 3403The `data_format` attr specifies the layout of the input and output tensors 3404with the following options: 3405 "NHWC": `[ batch, height, width, channels ]` 3406 "NCHW": `[ batch, channels, height, width ]` 3407 "NCHW_VECT_C": 3408 `qint8 [ batch, channels / 4, height, width, 4 ]` 3409 3410It is useful to consider the operation as transforming a 6-D Tensor. 3411e.g. for data_format = NHWC, 3412 Each element in the input tensor can be specified via 6 coordinates, 3413 ordered by decreasing memory layout significance as: 3414 n,iY,iX,bY,bX,oC (where n=batch index, iX, iY means X or Y coordinates 3415 within the input image, bX, bY means coordinates 3416 within the output block, oC means output channels). 3417 The output would be the input transposed to the following layout: 3418 n,iY,bY,iX,bX,oC 3419 3420This operation is useful for resizing the activations between convolutions 3421(but keeping all data), e.g. instead of pooling. It is also useful for training 3422purely convolutional models. 3423 3424For example, given an input of shape `[1, 1, 1, 4]`, data_format = "NHWC" and 3425block_size = 2: 3426 3427``` 3428x = [[[[1, 2, 3, 4]]]] 3429 3430``` 3431 3432This operation will output a tensor of shape `[1, 2, 2, 1]`: 3433 3434``` 3435 [[[[1], [2]], 3436 [[3], [4]]]] 3437``` 3438 3439Here, the input has a batch of 1 and each batch element has shape `[1, 1, 4]`, 3440the corresponding output will have 2x2 elements and will have a depth of 34411 channel (1 = `4 / (block_size * block_size)`). 3442The output element shape is `[2, 2, 1]`. 3443 3444For an input tensor with larger depth, here of shape `[1, 1, 1, 12]`, e.g. 3445 3446``` 3447x = [[[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]]]] 3448``` 3449 3450This operation, for block size of 2, will return the following tensor of shape 3451`[1, 2, 2, 3]` 3452 3453``` 3454 [[[[1, 2, 3], [4, 5, 6]], 3455 [[7, 8, 9], [10, 11, 12]]]] 3456 3457``` 3458 3459Similarly, for the following input of shape `[1 2 2 4]`, and a block size of 2: 3460 3461``` 3462x = [[[[1, 2, 3, 4], 3463 [5, 6, 7, 8]], 3464 [[9, 10, 11, 12], 3465 [13, 14, 15, 16]]]] 3466``` 3467 3468the operator will return the following tensor of shape `[1 4 4 1]`: 3469 3470``` 3471x = [[[ [1], [2], [5], [6]], 3472 [ [3], [4], [7], [8]], 3473 [ [9], [10], [13], [14]], 3474 [ [11], [12], [15], [16]]]] 3475 3476``` 3477 }]; 3478 3479 let arguments = (ins 3480 TF_Tensor:$input, 3481 3482 ConfinedAttr<I64Attr, [IntMinValue<2>]>:$block_size, 3483 DefaultValuedAttr<TF_AnyStrAttrOf<["NHWC", "NCHW", "NCHW_VECT_C"]>, "\"NHWC\"">:$data_format 3484 ); 3485 3486 let results = (outs 3487 TF_Tensor:$output 3488 ); 3489 3490 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3491} 3492 3493def TF_DepthwiseConv2dNativeOp : TF_Op<"DepthwiseConv2dNative", [NoSideEffect]> { 3494 let summary = [{ 3495Computes a 2-D depthwise convolution given 4-D `input` and `filter` tensors. 3496 }]; 3497 3498 let description = [{ 3499Given an input tensor of shape `[batch, in_height, in_width, in_channels]` 3500and a filter / kernel tensor of shape 3501`[filter_height, filter_width, in_channels, channel_multiplier]`, containing 3502`in_channels` convolutional filters of depth 1, `depthwise_conv2d` applies 3503a different filter to each input channel (expanding from 1 channel to 3504`channel_multiplier` channels for each), then concatenates the results 3505together. Thus, the output has `in_channels * channel_multiplier` channels. 3506 3507``` 3508for k in 0..in_channels-1 3509 for q in 0..channel_multiplier-1 3510 output[b, i, j, k * channel_multiplier + q] = 3511 sum_{di, dj} input[b, strides[1] * i + di, strides[2] * j + dj, k] * 3512 filter[di, dj, k, q] 3513``` 3514 3515Must have `strides[0] = strides[3] = 1`. For the most common case of the same 3516horizontal and vertices strides, `strides = [1, stride, stride, 1]`. 3517 }]; 3518 3519 let arguments = (ins 3520 TF_FloatTensor:$input, 3521 TF_FloatTensor:$filter, 3522 3523 I64ArrayAttr:$strides, 3524 TF_AnyStrAttrOf<["SAME", "VALID", "EXPLICIT"]>:$padding, 3525 DefaultValuedAttr<I64ArrayAttr, "{}">:$explicit_paddings, 3526 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 3527 DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1}">:$dilations 3528 ); 3529 3530 let results = (outs 3531 TF_FloatTensor:$output 3532 ); 3533 3534 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3535} 3536 3537def TF_DepthwiseConv2dNativeBackpropFilterOp : TF_Op<"DepthwiseConv2dNativeBackpropFilter", [NoSideEffect]> { 3538 let summary = [{ 3539Computes the gradients of depthwise convolution with respect to the filter. 3540 }]; 3541 3542 let arguments = (ins 3543 Arg<TF_FloatTensor, [{4-D with shape based on `data_format`. For example, if 3544`data_format` is 'NHWC' then `input` is a 4-D `[batch, in_height, 3545in_width, in_channels]` tensor.}]>:$input, 3546 Arg<TF_Int32Tensor, [{An integer vector representing the tensor shape of `filter`, 3547where `filter` is a 4-D 3548`[filter_height, filter_width, in_channels, depthwise_multiplier]` tensor.}]>:$filter_sizes, 3549 Arg<TF_FloatTensor, [{4-D with shape based on `data_format`. 3550For example, if `data_format` is 'NHWC' then 3551out_backprop shape is `[batch, out_height, out_width, out_channels]`. 3552Gradients w.r.t. the output of the convolution.}]>:$out_backprop, 3553 3554 I64ArrayAttr:$strides, 3555 TF_AnyStrAttrOf<["SAME", "VALID", "EXPLICIT"]>:$padding, 3556 DefaultValuedAttr<I64ArrayAttr, "{}">:$explicit_paddings, 3557 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 3558 DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1}">:$dilations 3559 ); 3560 3561 let results = (outs 3562 Res<TF_FloatTensor, [{4-D with shape 3563`[filter_height, filter_width, in_channels, out_channels]`. Gradient w.r.t. 3564the `filter` input of the convolution.}]>:$output 3565 ); 3566 3567 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3568} 3569 3570def TF_DepthwiseConv2dNativeBackpropInputOp : TF_Op<"DepthwiseConv2dNativeBackpropInput", [NoSideEffect]> { 3571 let summary = [{ 3572Computes the gradients of depthwise convolution with respect to the input. 3573 }]; 3574 3575 let arguments = (ins 3576 Arg<TF_Int32Tensor, [{An integer vector representing the shape of `input`, based 3577on `data_format`. For example, if `data_format` is 'NHWC' then 3578 `input` is a 4-D `[batch, height, width, channels]` tensor.}]>:$input_sizes, 3579 Arg<TF_FloatTensor, [{4-D with shape 3580`[filter_height, filter_width, in_channels, depthwise_multiplier]`.}]>:$filter, 3581 Arg<TF_FloatTensor, [{4-D with shape based on `data_format`. 3582For example, if `data_format` is 'NHWC' then 3583out_backprop shape is `[batch, out_height, out_width, out_channels]`. 3584Gradients w.r.t. the output of the convolution.}]>:$out_backprop, 3585 3586 I64ArrayAttr:$strides, 3587 TF_AnyStrAttrOf<["SAME", "VALID", "EXPLICIT"]>:$padding, 3588 DefaultValuedAttr<I64ArrayAttr, "{}">:$explicit_paddings, 3589 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 3590 DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1}">:$dilations 3591 ); 3592 3593 let results = (outs 3594 Res<TF_FloatTensor, [{4-D with shape according to `data_format`. For example, if 3595`data_format` is 'NHWC', output shape is `[batch, in_height, 3596in_width, in_channels]`. Gradient w.r.t. the input of the 3597convolution.}]>:$output 3598 ); 3599 3600 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 3601} 3602 3603def TF_DequantizeOp : TF_Op<"Dequantize", [NoSideEffect]> { 3604 let summary = [{ 3605Dequantize the 'input' tensor into a float or bfloat16 Tensor. 3606 }]; 3607 3608 let description = [{ 3609[min_range, max_range] are scalar floats that specify the range for 3610the output. The 'mode' attribute controls exactly which calculations are 3611used to convert the float values to their quantized equivalents. 3612 3613In 'MIN_COMBINED' mode, each value of the tensor will undergo the following: 3614 3615``` 3616if T == qint8: in[i] += (range(T) + 1)/ 2.0 3617out[i] = min_range + (in[i]* (max_range - min_range) / range(T)) 3618``` 3619here `range(T) = numeric_limits<T>::max() - numeric_limits<T>::min()` 3620 3621*MIN_COMBINED Mode Example* 3622 3623If the input comes from a QuantizedRelu6, the output type is 3624quint8 (range of 0-255) but the possible range of QuantizedRelu6 is 36250-6. The min_range and max_range values are therefore 0.0 and 6.0. 3626Dequantize on quint8 will take each value, cast to float, and multiply 3627by 6 / 255. 3628Note that if quantizedtype is qint8, the operation will additionally add 3629each value by 128 prior to casting. 3630 3631If the mode is 'MIN_FIRST', then this approach is used: 3632 3633```c++ 3634num_discrete_values = 1 << (# of bits in T) 3635range_adjust = num_discrete_values / (num_discrete_values - 1) 3636range = (range_max - range_min) * range_adjust 3637range_scale = range / num_discrete_values 3638const double offset_input = static_cast<double>(input) - lowest_quantized; 3639result = range_min + ((input - numeric_limits<T>::min()) * range_scale) 3640``` 3641 3642If the mode is `SCALED`, dequantization is performed by multiplying each 3643input value by a scaling_factor. (Thus an input of 0 always maps to 0.0). 3644 3645The scaling_factor is determined from `min_range`, `max_range`, and 3646`narrow_range` in a way that is compatible with `QuantizeAndDequantize{V2|V3}` 3647and `QuantizeV2`, using the following algorithm: 3648 3649```c++ 3650 3651 const int min_expected_T = std::numeric_limits<T>::min() + 3652 (narrow_range ? 1 : 0); 3653 const int max_expected_T = std::numeric_limits<T>::max(); 3654 const float max_expected_T = std::numeric_limits<float>::max(); 3655 3656 const float scale_factor = 3657 (std::numeric_limits<T>::min() == 0) ? (max_range / max_expected_T) 3658 : std::max(min_range / min_expected_T, 3659 max_range / max_expected_T); 3660``` 3661 }]; 3662 3663 let arguments = (ins 3664 TensorOf<[TF_Qint16, TF_Qint32, TF_Qint8, TF_Quint16, TF_Quint8]>:$input, 3665 Arg<TF_Float32Tensor, [{The minimum scalar value possibly produced for the input.}]>:$min_range, 3666 Arg<TF_Float32Tensor, [{The maximum scalar value possibly produced for the input.}]>:$max_range, 3667 3668 DefaultValuedAttr<TF_AnyStrAttrOf<["MIN_COMBINED", "MIN_FIRST", "SCALED"]>, "\"MIN_COMBINED\"">:$mode, 3669 DefaultValuedAttr<BoolAttr, "false">:$narrow_range, 3670 DefaultValuedAttr<I64Attr, "-1">:$axis 3671 ); 3672 3673 let results = (outs 3674 TensorOf<[TF_Bfloat16, TF_Float32]>:$output 3675 ); 3676 3677 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3678 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 3679} 3680 3681def TF_DeserializeIteratorOp : TF_Op<"DeserializeIterator", []> { 3682 let summary = [{ 3683Converts the given variant tensor to an iterator and stores it in the given resource. 3684 }]; 3685 3686 let arguments = (ins 3687 Arg<TF_ResourceTensor, [{A handle to an iterator resource.}], [TF_DatasetIteratorWrite]>:$resource_handle, 3688 Arg<TF_VariantTensor, [{A variant tensor storing the state of the iterator contained in the 3689resource.}]>:$serialized 3690 ); 3691 3692 let results = (outs); 3693} 3694 3695def TF_DeserializeSparseOp : TF_Op<"DeserializeSparse", [NoSideEffect]> { 3696 let summary = "Deserialize `SparseTensor` objects."; 3697 3698 let description = [{ 3699The input `serialized_sparse` must have the shape `[?, ?, ..., ?, 3]` where 3700the last dimension stores serialized `SparseTensor` objects and the other N 3701dimensions (N >= 0) correspond to a batch. The ranks of the original 3702`SparseTensor` objects must all match. When the final `SparseTensor` is 3703created, its rank is the rank of the incoming `SparseTensor` objects plus N; 3704the sparse tensors have been concatenated along new dimensions, one for each 3705batch. 3706 3707The output `SparseTensor` object's shape values for the original dimensions 3708are the max across the input `SparseTensor` objects' shape values for the 3709corresponding dimensions. The new dimensions match the size of the batch. 3710 3711The input `SparseTensor` objects' indices are assumed ordered in 3712standard lexicographic order. If this is not the case, after this 3713step run `SparseReorder` to restore index ordering. 3714 3715For example, if the serialized input is a `[2 x 3]` matrix representing two 3716original `SparseTensor` objects: 3717 3718 index = [ 0] 3719 [10] 3720 [20] 3721 values = [1, 2, 3] 3722 shape = [50] 3723 3724and 3725 3726 index = [ 2] 3727 [10] 3728 values = [4, 5] 3729 shape = [30] 3730 3731then the final deserialized `SparseTensor` will be: 3732 3733 index = [0 0] 3734 [0 10] 3735 [0 20] 3736 [1 2] 3737 [1 10] 3738 values = [1, 2, 3, 4, 5] 3739 shape = [2 50] 3740 }]; 3741 3742 let arguments = (ins 3743 Arg<TensorOf<[TF_Str, TF_Variant]>, [{The serialized `SparseTensor` objects. The last dimension 3744must have 3 columns.}]>:$serialized_sparse 3745 ); 3746 3747 let results = (outs 3748 TF_Int64Tensor:$sparse_indices, 3749 TF_Tensor:$sparse_values, 3750 TF_Int64Tensor:$sparse_shape 3751 ); 3752 3753 TF_DerivedOperandTypeAttr Tserialized = TF_DerivedOperandTypeAttr<0>; 3754 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<1>; 3755} 3756 3757def TF_DestroyResourceOp : TF_Op<"DestroyResourceOp", []> { 3758 let summary = "Deletes the resource specified by the handle."; 3759 3760 let description = [{ 3761All subsequent operations using the resource will result in a NotFound 3762error status. 3763 }]; 3764 3765 let arguments = (ins 3766 Arg<TF_ResourceTensor, [{handle to the resource to delete.}]>:$resource, 3767 3768 DefaultValuedAttr<BoolAttr, "true">:$ignore_lookup_error 3769 ); 3770 3771 let results = (outs); 3772} 3773 3774def TF_DeviceIndexOp : TF_Op<"DeviceIndex", [NoSideEffect, TF_NoConstantFold]> { 3775 let summary = "Return the index of device the op runs."; 3776 3777 let description = [{ 3778Given a list of device names, this operation returns the index of the device 3779this op runs. The length of the list is returned in two cases: 3780(1) Device does not exist in the given device list. 3781(2) It is in XLA compilation. 3782 }]; 3783 3784 let arguments = (ins 3785 StrArrayAttr:$device_names 3786 ); 3787 3788 let results = (outs 3789 TF_Int32Tensor:$index 3790 ); 3791} 3792 3793def TF_DiagOp : TF_Op<"Diag", [NoSideEffect, TF_SameOperandsAndResultElementTypeResolveRef]> { 3794 let summary = "Returns a diagonal tensor with a given diagonal values."; 3795 3796 let description = [{ 3797Given a `diagonal`, this operation returns a tensor with the `diagonal` and 3798everything else padded with zeros. The diagonal is computed as follows: 3799 3800Assume `diagonal` has dimensions [D1,..., Dk], then the output is a tensor of 3801rank 2k with dimensions [D1,..., Dk, D1,..., Dk] where: 3802 3803`output[i1,..., ik, i1,..., ik] = diagonal[i1, ..., ik]` and 0 everywhere else. 3804 3805For example: 3806 3807``` 3808# 'diagonal' is [1, 2, 3, 4] 3809tf.diag(diagonal) ==> [[1, 0, 0, 0] 3810 [0, 2, 0, 0] 3811 [0, 0, 3, 0] 3812 [0, 0, 0, 4]] 3813``` 3814 }]; 3815 3816 let arguments = (ins 3817 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{Rank k tensor where k is at most 1.}]>:$diagonal 3818 ); 3819 3820 let results = (outs 3821 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$output 3822 ); 3823 3824 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3825} 3826 3827def TF_DiagPartOp : TF_Op<"DiagPart", [NoSideEffect]> { 3828 let summary = "Returns the diagonal part of the tensor."; 3829 3830 let description = [{ 3831This operation returns a tensor with the `diagonal` part 3832of the `input`. The `diagonal` part is computed as follows: 3833 3834Assume `input` has dimensions `[D1,..., Dk, D1,..., Dk]`, then the output is a 3835tensor of rank `k` with dimensions `[D1,..., Dk]` where: 3836 3837`diagonal[i1,..., ik] = input[i1, ..., ik, i1,..., ik]`. 3838 3839For example: 3840 3841``` 3842# 'input' is [[1, 0, 0, 0] 3843 [0, 2, 0, 0] 3844 [0, 0, 3, 0] 3845 [0, 0, 0, 4]] 3846 3847tf.diag_part(input) ==> [1, 2, 3, 4] 3848``` 3849 }]; 3850 3851 let arguments = (ins 3852 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{Rank k tensor where k is even and not zero.}]>:$input 3853 ); 3854 3855 let results = (outs 3856 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{The extracted diagonal.}]>:$diagonal 3857 ); 3858 3859 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3860} 3861 3862def TF_DigammaOp : TF_Op<"Digamma", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 3863 let summary = [{ 3864Computes Psi, the derivative of Lgamma (the log of the absolute value of 3865 }]; 3866 3867 let description = [{ 3868`Gamma(x)`), element-wise. 3869 }]; 3870 3871 let arguments = (ins 3872 TF_FloatTensor:$x 3873 ); 3874 3875 let results = (outs 3876 TF_FloatTensor:$y 3877 ); 3878 3879 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3880} 3881 3882def TF_DivOp : TF_Op<"Div", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 3883 WithBroadcastableBinOpBuilder { 3884 let summary = "Returns x / y element-wise."; 3885 3886 let description = [{ 3887*NOTE*: `Div` supports broadcasting. More about broadcasting 3888[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 3889 }]; 3890 3891 let arguments = (ins 3892 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$x, 3893 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$y 3894 ); 3895 3896 let results = (outs 3897 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$z 3898 ); 3899 3900 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3901 3902 let hasCanonicalizer = 1; 3903 3904 let hasFolder = 1; 3905} 3906 3907def TF_DivNoNanOp : TF_Op<"DivNoNan", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 3908 WithBroadcastableBinOpBuilder { 3909 let summary = "Returns 0 if the denominator is zero."; 3910 3911 let description = [{ 3912*NOTE*: `DivNoNan` supports broadcasting. More about broadcasting 3913[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 3914 }]; 3915 3916 let arguments = (ins 3917 TF_FpOrComplexTensor:$x, 3918 TF_FpOrComplexTensor:$y 3919 ); 3920 3921 let results = (outs 3922 TF_FpOrComplexTensor:$z 3923 ); 3924 3925 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 3926 3927 let hasCanonicalizer = 1; 3928} 3929 3930def TF_DummyMemoryCacheOp : TF_Op<"DummyMemoryCache", []> { 3931 let summary = ""; 3932 3933 let arguments = (ins); 3934 3935 let results = (outs 3936 Res<TF_ResourceTensor, "", [TF_DatasetMemoryCacheAlloc]>:$handle 3937 ); 3938} 3939 3940def TF_DummySeedGeneratorOp : TF_Op<"DummySeedGenerator", []> { 3941 let summary = ""; 3942 3943 let arguments = (ins); 3944 3945 let results = (outs 3946 Res<TF_ResourceTensor, "", [TF_DatasetSeedGeneratorAlloc]>:$handle 3947 ); 3948} 3949 3950def TF_DynamicEnqueueTPUEmbeddingArbitraryTensorBatchOp : TF_Op<"DynamicEnqueueTPUEmbeddingArbitraryTensorBatch", [SameVariadicOperandSize, TF_TPUEmbeddingWriteEffect]> { 3951 let summary = [{ 3952Eases the porting of code that uses tf.nn.embedding_lookup_sparse(). 3953 }]; 3954 3955 let description = [{ 3956embedding_indices[i] and aggregation_weights[i] correspond 3957to the ith feature. 3958 3959The tensors at corresponding positions in the three input lists (sample_indices, 3960embedding_indices and aggregation_weights) must have the same shape, i.e. rank 1 3961with dim_size() equal to the total number of lookups into the table described by 3962the corresponding feature. 3963 }]; 3964 3965 let arguments = (ins 3966 Arg<Variadic<TF_I32OrI64Tensor>, [{A list of rank 2 Tensors specifying the training example to which the 3967corresponding embedding_indices and aggregation_weights values belong. 3968If the size of its first dimension is 0, we assume each embedding_indices 3969belongs to a different sample. Both int32 and int64 are allowed and will 3970be converted to int32 internally. 3971 3972Or a list of rank 1 Tensors specifying the row splits for splitting 3973embedding_indices and aggregation_weights into rows. It corresponds to 3974ids.row_splits in embedding_lookup(), when ids is a RaggedTensor. When 3975enqueuing N-D ragged tensor, only the last dimension is allowed to be ragged. 3976the row splits is 1-D dense tensor. When empty, we assume a dense tensor is 3977passed to the op Both int32 and int64 are allowed and will be converted to 3978int32 internally.}]>:$sample_indices_or_row_splits, 3979 Arg<Variadic<TF_I32OrI64Tensor>, [{A list of rank 1 Tensors, indices into the embedding 3980tables. Both int32 and int64 are allowed and will be converted to 3981int32 internally.}]>:$embedding_indices, 3982 Arg<Variadic<TF_F32OrF64Tensor>, [{A list of rank 1 Tensors containing per training 3983example aggregation weights. Both float32 and float64 are allowed and will 3984be converted to float32 internally.}]>:$aggregation_weights, 3985 Arg<TF_StrTensor, [{A string input that overrides the mode specified in the 3986TPUEmbeddingConfiguration. Supported values are {'unspecified', 'inference', 3987'training', 'backward_pass_only'}. When set to 'unspecified', the mode set 3988in TPUEmbeddingConfiguration is used, otherwise mode_override is used.}]>:$mode_override, 3989 Arg<TF_Int32Tensor, [{The TPU device to use. Should be >= 0 and less than the number 3990of TPU cores in the task on which the node is placed.}]>:$device_ordinal, 3991 3992 DefaultValuedAttr<StrArrayAttr, "{}">:$combiners 3993 ); 3994 3995 let results = (outs); 3996 3997 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 3998 TF_DerivedOperandTypeAttr T1 = TF_DerivedOperandTypeAttr<0>; 3999 TF_DerivedOperandTypeAttr T2 = TF_DerivedOperandTypeAttr<1>; 4000 TF_DerivedOperandTypeAttr T3 = TF_DerivedOperandTypeAttr<2>; 4001} 4002 4003def TF_DynamicStitchOp : TF_Op<"DynamicStitch", [NoSideEffect, SameVariadicOperandSize]> { 4004 let summary = [{ 4005Interleave the values from the `data` tensors into a single tensor. 4006 }]; 4007 4008 let description = [{ 4009Builds a merged tensor such that 4010 4011```python 4012 merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...] 4013``` 4014 4015For example, if each `indices[m]` is scalar or vector, we have 4016 4017```python 4018 # Scalar indices: 4019 merged[indices[m], ...] = data[m][...] 4020 4021 # Vector indices: 4022 merged[indices[m][i], ...] = data[m][i, ...] 4023``` 4024 4025Each `data[i].shape` must start with the corresponding `indices[i].shape`, 4026and the rest of `data[i].shape` must be constant w.r.t. `i`. That is, we 4027must have `data[i].shape = indices[i].shape + constant`. In terms of this 4028`constant`, the output shape is 4029 4030 merged.shape = [max(indices)] + constant 4031 4032Values are merged in order, so if an index appears in both `indices[m][i]` and 4033`indices[n][j]` for `(m,i) < (n,j)` the slice `data[n][j]` will appear in the 4034merged result. If you do not need this guarantee, ParallelDynamicStitch might 4035perform better on some devices. 4036 4037For example: 4038 4039```python 4040 indices[0] = 6 4041 indices[1] = [4, 1] 4042 indices[2] = [[5, 2], [0, 3]] 4043 data[0] = [61, 62] 4044 data[1] = [[41, 42], [11, 12]] 4045 data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]] 4046 merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42], 4047 [51, 52], [61, 62]] 4048``` 4049 4050This method can be used to merge partitions created by `dynamic_partition` 4051as illustrated on the following example: 4052 4053```python 4054 # Apply function (increments x_i) on elements for which a certain condition 4055 # apply (x_i != -1 in this example). 4056 x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4]) 4057 condition_mask=tf.not_equal(x,tf.constant(-1.)) 4058 partitioned_data = tf.dynamic_partition( 4059 x, tf.cast(condition_mask, tf.int32) , 2) 4060 partitioned_data[1] = partitioned_data[1] + 1.0 4061 condition_indices = tf.dynamic_partition( 4062 tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2) 4063 x = tf.dynamic_stitch(condition_indices, partitioned_data) 4064 # Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain 4065 # unchanged. 4066``` 4067 4068<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 4069<img style="width:100%" src="https://www.tensorflow.org/images/DynamicStitch.png" alt> 4070</div> 4071 }]; 4072 4073 let arguments = (ins 4074 Variadic<TF_Int32Tensor>:$indices, 4075 Variadic<TF_Tensor>:$data 4076 ); 4077 4078 let results = (outs 4079 TF_Tensor:$merged 4080 ); 4081 4082 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 4083 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 4084 4085 let hasVerifier = 1; 4086} 4087 4088def TF_EinsumOp : TF_Op<"Einsum", [NoSideEffect]> { 4089 let summary = [{ 4090Tensor contraction according to Einstein summation convention. 4091 }]; 4092 4093 let description = [{ 4094Implements generalized Tensor contraction and reduction. Each input Tensor must 4095have a corresponding input subscript appearing in the comma-separated left-hand 4096side of the equation. The right-hand side of the equation consists of the 4097output subscript. The input subscripts and the output subscript should consist 4098of zero or more named axis labels and at most one ellipsis (`...`). 4099 4100The named axis labels may be any single character other than those having 4101special meaning, namely `,.->`. The behavior of this Op is undefined if it 4102receives an ill-formatted equation; since the validation is done at 4103graph-building time, we omit format validation checks at runtime. 4104 4105Note: This Op is *not* intended to be called by the user; instead users should 4106call `tf.einsum` directly. It is a hidden Op used by `tf.einsum`. 4107 4108Operations are applied to the input(s) according to the following rules: 4109 4110 (a) Generalized Diagonals: For input dimensions corresponding to axis labels 4111 appearing more than once in the same input subscript, we take the 4112 generalized (`k`-dimensional) diagonal. 4113 For example, in the equation `iii->i` with input shape `[3, 3, 3]`, the 4114 generalized diagonal would consist of `3` elements at indices `(0, 0, 0)`, 4115 `(1, 1, 1)` and `(2, 2, 2)` to create a Tensor of shape `[3]`. 4116 4117 (b) Reduction: Axes corresponding to labels appearing only in one input 4118 subscript but not in the output subscript are summed over prior to Tensor 4119 contraction. 4120 For example, in the equation `ab,bc->b`, the axis labels `a` and `c` are 4121 the reduction axis labels. 4122 4123 (c) Batch Dimensions: Axes corresponding to labels appearing in each of the 4124 input subscripts and also in the output subscript make up the batch 4125 dimensions in Tensor contraction. Unnamed axis labels corresponding to 4126 ellipsis (`...`) also correspond to batch dimensions. 4127 For example, for the equation denoting batch matrix multiplication, 4128 `bij,bjk->bik`, the axis label `b` corresponds to a batch dimension. 4129 4130 (d) Contraction: In case of binary einsum, axes corresponding to labels 4131 appearing in two different inputs (and not in the output) are contracted 4132 against each other. 4133 Considering the batch matrix multiplication equation again 4134 (`bij,bjk->bik`), the contracted axis label is `j`. 4135 4136 (e) Expand Diagonal: If the output subscripts contain repeated (explicit) axis 4137 labels, the opposite operation of (a) is applied. For example, in the 4138 equation `i->iii`, and input shape `[3]`, the output of shape `[3, 3, 3]` 4139 are all zeros, except for the (generalized) diagonal which is populated 4140 with values from the input. 4141 Note: This operation is not supported by `np.einsum` or `tf.einsum`; it is 4142 provided to enable computing the symbolic gradient of `tf.einsum`. 4143 4144The output subscripts must contain only labels appearing in at least one of the 4145input subscripts. Furthermore, all dimensions mapping to the same axis label 4146must be equal. 4147 4148Any of the input and output subscripts may contain at most a single ellipsis 4149(`...`). These ellipsis are mapped against dimensions not corresponding to any 4150named axis label. If two inputs contain ellipsis, then they are broadcasted 4151according to standard NumPy broadcasting 4152[rules](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html). 4153 4154The broadcasted dimensions are placed in the corresponding location of the 4155ellipsis in the output subscript. If the broadcasted dimensions are non-empty 4156and the output subscripts do not contain ellipsis, then an InvalidArgument error 4157is raised. 4158 4159@compatibility(numpy) 4160Similar to [`numpy.einsum`](https://docs.scipy.org/doc/numpy/reference/generated/numpy.einsum.html). 4161 4162Comparison with `numpy.einsum`: 4163 4164 * This Op only supports unary and binary forms of `numpy.einsum`. 4165 * This Op does not support implicit form. (i.e. equations without `->`). 4166 * This Op also supports repeated indices in the output subscript, which is not 4167 supported by `numpy.einsum`. 4168@end_compatibility 4169 }]; 4170 4171 let arguments = (ins 4172 Arg<Variadic<TF_Tensor>, [{List of 1 or 2 Tensors.}]>:$inputs, 4173 4174 StrAttr:$equation 4175 ); 4176 4177 let results = (outs 4178 Res<TF_Tensor, [{Output Tensor with shape depending upon `equation`.}]>:$output 4179 ); 4180 4181 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 4182 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4183 4184 let hasVerifier = 1; 4185} 4186 4187def TF_EluOp : TF_Op<"Elu", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 4188 let summary = "Computes the exponential linear function."; 4189 4190 let description = [{ 4191The ELU function is defined as: 4192 4193 * $ e ^ x - 1 $ if $ x < 0 $ 4194 * $ x $ if $ x >= 0 $ 4195 4196Examples: 4197 4198>>> tf.nn.elu(1.0) 4199<tf.Tensor: shape=(), dtype=float32, numpy=1.0> 4200>>> tf.nn.elu(0.0) 4201<tf.Tensor: shape=(), dtype=float32, numpy=0.0> 4202>>> tf.nn.elu(-1000.0) 4203<tf.Tensor: shape=(), dtype=float32, numpy=-1.0> 4204 4205See [Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs) 4206](http://arxiv.org/abs/1511.07289) 4207 }]; 4208 4209 let arguments = (ins 4210 TF_FloatTensor:$features 4211 ); 4212 4213 let results = (outs 4214 TF_FloatTensor:$activations 4215 ); 4216 4217 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4218} 4219 4220def TF_EluGradOp : TF_Op<"EluGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 4221 let summary = [{ 4222Computes gradients for the exponential linear (Elu) operation. 4223 }]; 4224 4225 let arguments = (ins 4226 Arg<TF_FloatTensor, [{The backpropagated gradients to the corresponding Elu operation.}]>:$gradients, 4227 Arg<TF_FloatTensor, [{The outputs of the corresponding Elu operation.}]>:$outputs 4228 ); 4229 4230 let results = (outs 4231 Res<TF_FloatTensor, [{The gradients: `gradients * (outputs + 1)` if outputs < 0, 4232`gradients` otherwise.}]>:$backprops 4233 ); 4234 4235 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4236} 4237 4238def TF_EmptyOp : TF_Op<"Empty", []> { 4239 let summary = [{ 4240Creates a tensor with the given shape. 4241 4242This operation creates a tensor of `shape` and `dtype`. 4243 }]; 4244 4245 let arguments = (ins 4246 Arg<TF_Int32Tensor, [{1-D. Represents the shape of the output tensor.}]>:$shape, 4247 4248 DefaultValuedAttr<BoolAttr, "false">:$init 4249 ); 4250 4251 let results = (outs 4252 Res<TF_Tensor, [{A `Tensor` of type `T`.}]>:$output 4253 ); 4254 4255 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 4256 4257 let hasFolder = 1; 4258} 4259 4260def TF_EnqueueTPUEmbeddingArbitraryTensorBatchOp : TF_Op<"EnqueueTPUEmbeddingArbitraryTensorBatch", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, SameVariadicOperandSize, TF_TPUEmbeddingWriteEffect]> { 4261 let summary = [{ 4262Eases the porting of code that uses tf.nn.embedding_lookup_sparse(). 4263 }]; 4264 4265 let description = [{ 4266embedding_indices[i] and aggregation_weights[i] correspond 4267to the ith feature. 4268 4269The tensors at corresponding positions in the three input lists (sample_indices, 4270embedding_indices and aggregation_weights) must have the same shape, i.e. rank 1 4271with dim_size() equal to the total number of lookups into the table described by 4272the corresponding feature. 4273 }]; 4274 4275 let arguments = (ins 4276 Arg<Variadic<TF_I32OrI64Tensor>, [{A list of rank 2 Tensors specifying the training example to which the 4277corresponding embedding_indices and aggregation_weights values belong. 4278If the size of its first dimension is 0, we assume each embedding_indices 4279belongs to a different sample. Both int32 and int64 are allowed and will 4280be converted to int32 internally. 4281 4282Or a list of rank 1 Tensors specifying the row splits for splitting 4283embedding_indices and aggregation_weights into rows. It corresponds to 4284ids.row_splits in embedding_lookup(), when ids is a RaggedTensor. When 4285enqueuing N-D ragged tensor, only the last dimension is allowed to be ragged. 4286the row splits is 1-D dense tensor. When empty, we assume a dense tensor is 4287passed to the op Both int32 and int64 are allowed and will be converted to 4288int32 internally.}]>:$sample_indices_or_row_splits, 4289 Arg<Variadic<TF_I32OrI64Tensor>, [{A list of rank 1 Tensors, indices into the embedding 4290tables. Both int32 and int64 are allowed and will be converted to 4291int32 internally.}]>:$embedding_indices, 4292 Arg<Variadic<TF_F32OrF64Tensor>, [{A list of rank 1 Tensors containing per training 4293example aggregation weights. Both float32 and float64 are allowed and will 4294be converted to float32 internally.}]>:$aggregation_weights, 4295 Arg<TF_StrTensor, [{A string input that overrides the mode specified in the 4296TPUEmbeddingConfiguration. Supported values are {'unspecified', 'inference', 4297'training', 'backward_pass_only'}. When set to 'unspecified', the mode set 4298in TPUEmbeddingConfiguration is used, otherwise mode_override is used.}]>:$mode_override, 4299 4300 DefaultValuedAttr<I64Attr, "-1">:$device_ordinal, 4301 DefaultValuedAttr<StrArrayAttr, "{}">:$combiners 4302 ); 4303 4304 let results = (outs); 4305 4306 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 4307 TF_DerivedOperandTypeAttr T1 = TF_DerivedOperandTypeAttr<0>; 4308 TF_DerivedOperandTypeAttr T2 = TF_DerivedOperandTypeAttr<1>; 4309 TF_DerivedOperandTypeAttr T3 = TF_DerivedOperandTypeAttr<2>; 4310} 4311 4312def TF_EnqueueTPUEmbeddingBatchOp : TF_Op<"EnqueueTPUEmbeddingBatch", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, TF_TPUEmbeddingWriteEffect]> { 4313 let summary = [{ 4314An op that enqueues a list of input batch tensors to TPUEmbedding. 4315 }]; 4316 4317 let description = [{ 4318An op that enqueues a list of input batch tensors to TPUEmbedding. 4319 }]; 4320 4321 let arguments = (ins 4322 Arg<Variadic<TF_StrTensor>, [{A list of 1D tensors, one for each embedding table, containing the 4323batch inputs encoded as dist_belief.SparseFeatures protos. If the weight 4324field in the SparseFeatures proto is not populated for an ID, a weight of 43251.0 is assumed.}]>:$batch, 4326 Arg<TF_StrTensor, [{A string input that overrides the mode specified in the 4327TPUEmbeddingConfiguration. Supported values are {'unspecified', 'inference', 4328'training', 'backward_pass_only'}. When set to 'unspecified', the mode set 4329in TPUEmbeddingConfiguration is used, otherwise mode_override is used.}]>:$mode_override, 4330 4331 DefaultValuedAttr<I64Attr, "-1">:$device_ordinal, 4332 DefaultValuedAttr<StrArrayAttr, "{}">:$combiners 4333 ); 4334 4335 let results = (outs); 4336 4337 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 4338} 4339 4340def TF_EnqueueTPUEmbeddingIntegerBatchOp : TF_Op<"EnqueueTPUEmbeddingIntegerBatch", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, TF_TPUEmbeddingWriteEffect]> { 4341 let summary = [{ 4342An op that enqueues a list of input batch tensors to TPUEmbedding. 4343 }]; 4344 4345 let arguments = (ins 4346 Arg<Variadic<TF_Int32Tensor>, [{A list of 1D tensors, one for each embedding table, containing the 4347indices into the tables.}]>:$batch, 4348 Arg<TF_StrTensor, [{A string input that overrides the mode specified in the 4349TPUEmbeddingConfiguration. Supported values are {'unspecified', 'inference', 4350'training', 'backward_pass_only'}. When set to 'unspecified', the mode set 4351in TPUEmbeddingConfiguration is used, otherwise mode_override is used.}]>:$mode_override, 4352 4353 DefaultValuedAttr<I64Attr, "-1">:$device_ordinal 4354 ); 4355 4356 let results = (outs); 4357 4358 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 4359} 4360 4361def TF_EnqueueTPUEmbeddingRaggedTensorBatchOp : TF_Op<"EnqueueTPUEmbeddingRaggedTensorBatch", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, SameVariadicOperandSize, TF_TPUEmbeddingWriteEffect]> { 4362 let summary = "Eases the porting of code that uses tf.nn.embedding_lookup()."; 4363 4364 let description = [{ 4365sample_splits[i], embedding_indices[i] and aggregation_weights[i] correspond 4366to the ith feature. table_ids[i] indicates which embedding table to look up ith 4367feature. 4368 4369The tensors at corresponding positions in two of the input lists, 4370embedding_indices and aggregation_weights, must have the same shape, i.e. rank 1 4371with dim_size() equal to the total number of lookups into the table described by 4372the corresponding feature. 4373 }]; 4374 4375 let arguments = (ins 4376 Arg<Variadic<TF_I32OrI64Tensor>, [{A list of rank 1 Tensors specifying the break points for splitting 4377embedding_indices and aggregation_weights into rows. 4378It corresponds to ids.row_splits in embedding_lookup(), when ids is a 4379RaggedTensor.}]>:$sample_splits, 4380 Arg<Variadic<TF_I32OrI64Tensor>, [{A list of rank 1 Tensors, indices into the embedding tables. 4381It corresponds to ids.values in embedding_lookup(), when ids is a RaggedTensor.}]>:$embedding_indices, 4382 Arg<Variadic<TF_F32OrF64Tensor>, [{A list of rank 1 Tensors containing per training example 4383aggregation weights. It corresponds to the values field of a RaggedTensor 4384with the same row_splits as ids in embedding_lookup(), when ids is a 4385RaggedTensor.}]>:$aggregation_weights, 4386 Arg<TF_StrTensor, [{A string input that overrides the mode specified in the 4387TPUEmbeddingConfiguration. Supported values are {'unspecified', 'inference', 4388'training', 'backward_pass_only'}. When set to 'unspecified', the mode set 4389in TPUEmbeddingConfiguration is used, otherwise mode_override is used.}]>:$mode_override, 4390 4391 DefaultValuedAttr<I64Attr, "-1">:$device_ordinal, 4392 DefaultValuedAttr<StrArrayAttr, "{}">:$combiners, 4393 I64ArrayAttr:$table_ids, 4394 DefaultValuedAttr<I64ArrayAttr, "{}">:$max_sequence_lengths, 4395 DefaultValuedAttr<I64ArrayAttr, "{}">:$num_features 4396 ); 4397 4398 let results = (outs); 4399 4400 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 4401 TF_DerivedOperandTypeAttr T1 = TF_DerivedOperandTypeAttr<0>; 4402 TF_DerivedOperandTypeAttr T2 = TF_DerivedOperandTypeAttr<1>; 4403 TF_DerivedOperandTypeAttr T3 = TF_DerivedOperandTypeAttr<2>; 4404} 4405 4406def TF_EnqueueTPUEmbeddingSparseBatchOp : TF_Op<"EnqueueTPUEmbeddingSparseBatch", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, SameVariadicOperandSize, TF_TPUEmbeddingWriteEffect]> { 4407 let summary = [{ 4408An op that enqueues TPUEmbedding input indices from a SparseTensor. 4409 }]; 4410 4411 let description = [{ 4412This Op eases the porting of code that uses embedding_lookup_sparse(), 4413although some Python preprocessing of the SparseTensor arguments to 4414embedding_lookup_sparse() is required to produce the arguments to this Op, 4415since only a single EnqueueTPUEmbeddingSparseBatch Op is allowed per training 4416step. 4417 4418The tensors at corresponding positions in the three input lists 4419must have the same shape, i.e. rank 1 with dim_size() equal to the total 4420number of lookups into the table described by the corresponding table_id. 4421 }]; 4422 4423 let arguments = (ins 4424 Arg<Variadic<TF_I32OrI64Tensor>, [{A list of rank 1 Tensors specifying the training example and 4425feature to which the corresponding embedding_indices and aggregation_weights 4426values belong. sample_indices[i] must equal b * nf + f, where nf is the 4427number of features from the corresponding table, f is in [0, nf), and 4428b is in [0, batch size).}]>:$sample_indices, 4429 Arg<Variadic<TF_I32OrI64Tensor>, [{A list of rank 1 Tensors, indices into the embedding tables.}]>:$embedding_indices, 4430 Arg<Variadic<TF_F32OrF64Tensor>, [{A list of rank 1 Tensors containing per sample -- i.e. per 4431(training example, feature) -- aggregation weights.}]>:$aggregation_weights, 4432 Arg<TF_StrTensor, [{A string input that overrides the mode specified in the 4433TPUEmbeddingConfiguration. Supported values are {'unspecified', 'inference', 4434'training', 'backward_pass_only'}. When set to 'unspecified', the mode set 4435in TPUEmbeddingConfiguration is used, otherwise mode_override is used.}]>:$mode_override, 4436 4437 DefaultValuedAttr<I64Attr, "-1">:$device_ordinal, 4438 DefaultValuedAttr<StrArrayAttr, "{}">:$combiners 4439 ); 4440 4441 let results = (outs); 4442 4443 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 4444 TF_DerivedOperandTypeAttr T1 = TF_DerivedOperandTypeAttr<0>; 4445 TF_DerivedOperandTypeAttr T2 = TF_DerivedOperandTypeAttr<1>; 4446 TF_DerivedOperandTypeAttr T3 = TF_DerivedOperandTypeAttr<2>; 4447} 4448 4449def TF_EnqueueTPUEmbeddingSparseTensorBatchOp : TF_Op<"EnqueueTPUEmbeddingSparseTensorBatch", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, SameVariadicOperandSize, TF_TPUEmbeddingWriteEffect]> { 4450 let summary = [{ 4451Eases the porting of code that uses tf.nn.embedding_lookup_sparse(). 4452 }]; 4453 4454 let description = [{ 4455sample_indices[i], embedding_indices[i] and aggregation_weights[i] correspond 4456to the ith feature. table_ids[i] indicates which embedding table to look up ith 4457feature. 4458 4459The tensors at corresponding positions in the three input lists (sample_indices, 4460embedding_indices and aggregation_weights) must have the same shape, i.e. rank 1 4461with dim_size() equal to the total number of lookups into the table described by 4462the corresponding feature. 4463 }]; 4464 4465 let arguments = (ins 4466 Arg<Variadic<TF_I32OrI64Tensor>, [{A list of rank 1 Tensors specifying the training example to 4467which the corresponding embedding_indices and aggregation_weights values 4468belong. It corresponds to sp_ids.indices[:,0] in embedding_lookup_sparse().}]>:$sample_indices, 4469 Arg<Variadic<TF_I32OrI64Tensor>, [{A list of rank 1 Tensors, indices into the embedding tables. 4470It corresponds to sp_ids.values in embedding_lookup_sparse().}]>:$embedding_indices, 4471 Arg<Variadic<TF_F32OrF64Tensor>, [{A list of rank 1 Tensors containing per training example 4472aggregation weights. It corresponds to sp_weights.values in 4473embedding_lookup_sparse().}]>:$aggregation_weights, 4474 Arg<TF_StrTensor, [{A string input that overrides the mode specified in the 4475TPUEmbeddingConfiguration. Supported values are {'unspecified', 'inference', 4476'training', 'backward_pass_only'}. When set to 'unspecified', the mode set 4477in TPUEmbeddingConfiguration is used, otherwise mode_override is used.}]>:$mode_override, 4478 4479 DefaultValuedAttr<I64Attr, "-1">:$device_ordinal, 4480 DefaultValuedAttr<StrArrayAttr, "{}">:$combiners, 4481 I64ArrayAttr:$table_ids, 4482 DefaultValuedAttr<I64ArrayAttr, "{}">:$max_sequence_lengths, 4483 DefaultValuedAttr<I64ArrayAttr, "{}">:$num_features 4484 ); 4485 4486 let results = (outs); 4487 4488 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 4489 TF_DerivedOperandTypeAttr T1 = TF_DerivedOperandTypeAttr<0>; 4490 TF_DerivedOperandTypeAttr T2 = TF_DerivedOperandTypeAttr<1>; 4491 TF_DerivedOperandTypeAttr T3 = TF_DerivedOperandTypeAttr<2>; 4492} 4493 4494def TF_EnsureShapeOp : TF_Op<"EnsureShape", [NoSideEffect]> { 4495 let summary = "Ensures that the tensor's shape matches the expected shape."; 4496 4497 let description = [{ 4498Raises an error if the input tensor's shape does not match the specified shape. 4499Returns the input tensor otherwise. 4500 }]; 4501 4502 let arguments = (ins 4503 Arg<TF_Tensor, [{A tensor, whose shape is to be validated.}]>:$input, 4504 4505 TF_ShapeAttr:$shape 4506 ); 4507 4508 let results = (outs 4509 Res<TF_Tensor, [{A tensor with the same shape and contents as the input tensor or value.}]>:$output 4510 ); 4511 4512 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4513 4514 let hasFolder = 1; 4515} 4516 4517def TF_EqualOp : TF_Op<"Equal", [Commutative, NoSideEffect]> { 4518 let summary = "Returns the truth value of (x == y) element-wise."; 4519 4520 let description = [{ 4521*NOTE*: `Equal` supports broadcasting. More about broadcasting 4522[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 4523 4524```python 4525x = tf.constant([2, 4]) 4526y = tf.constant(2) 4527tf.math.equal(x, y) ==> array([True, False]) 4528 4529x = tf.constant([2, 4]) 4530y = tf.constant([2, 4]) 4531tf.math.equal(x, y) ==> array([True, True]) 4532``` 4533 }]; 4534 4535 let arguments = (ins 4536 TF_Tensor:$x, 4537 TF_Tensor:$y, 4538 4539 DefaultValuedAttr<BoolAttr, "true">:$incompatible_shape_error 4540 ); 4541 4542 let results = (outs 4543 TF_BoolTensor:$z 4544 ); 4545 4546 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4547 4548 let builders = [ 4549 OpBuilder<(ins "Value":$x, "Value":$y, 4550 "BoolAttr":$incompatible_shape_error)> 4551 ]; 4552 4553 let hasVerifier = 1; 4554 4555 let hasCanonicalizer = 1; 4556} 4557 4558def TF_ErfOp : TF_Op<"Erf", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 4559 let summary = [{ 4560Computes the [Gauss error function](https://en.wikipedia.org/wiki/Error_function) of `x` element-wise. In statistics, for non-negative values of $x$, the error function has the following interpretation: for a random variable $Y$ that is normally distributed with mean 0 and variance $1/\sqrt{2}$, $erf(x)$ is the probability that $Y$ falls in the range $[−x, x]$. 4561 }]; 4562 4563 let arguments = (ins 4564 TF_FloatTensor:$x 4565 ); 4566 4567 let results = (outs 4568 TF_FloatTensor:$y 4569 ); 4570 4571 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4572} 4573 4574def TF_ErfcOp : TF_Op<"Erfc", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 4575 let summary = [{ 4576Computes the complementary error function of `x` element-wise. 4577 }]; 4578 4579 let arguments = (ins 4580 TF_FloatTensor:$x 4581 ); 4582 4583 let results = (outs 4584 TF_FloatTensor:$y 4585 ); 4586 4587 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4588} 4589 4590def TF_ErfinvOp : TF_Op<"Erfinv", [NoSideEffect]> { 4591 let summary = ""; 4592 4593 let arguments = (ins 4594 TF_FloatTensor:$x 4595 ); 4596 4597 let results = (outs 4598 TF_FloatTensor:$y 4599 ); 4600 4601 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4602} 4603 4604def TF_ExecuteTPUEmbeddingPartitionerOp : TF_Op<"ExecuteTPUEmbeddingPartitioner", []> { 4605 let summary = [{ 4606An op that executes the TPUEmbedding partitioner on the central configuration 4607 }]; 4608 4609 let description = [{ 4610device and computes the HBM size (in bytes) required for TPUEmbedding operation. 4611 }]; 4612 4613 let arguments = (ins 4614 StrAttr:$config 4615 ); 4616 4617 let results = (outs 4618 Res<TF_StrTensor, [{A string-encoded common configuration proto 4619containing metadata about the TPUEmbedding partitioner output and 4620the HBM size (in bytes) required for operation.}]>:$common_config 4621 ); 4622} 4623 4624def TF_ExpOp : TF_Op<"Exp", [NoSideEffect, SameOperandsAndResultType]> { 4625 let summary = [{ 4626Computes exponential of x element-wise. \\(y = e^x\\). 4627 }]; 4628 4629 let description = [{ 4630This function computes the exponential of every element in the input tensor. 4631 i.e. `exp(x)` or `e^(x)`, where `x` is the input tensor. 4632 `e` denotes Euler's number and is approximately equal to 2.718281. 4633 Output is positive for any real input. 4634 4635 ```python 4636 x = tf.constant(2.0) 4637 tf.math.exp(x) ==> 7.389056 4638 4639 x = tf.constant([2.0, 8.0]) 4640 tf.math.exp(x) ==> array([7.389056, 2980.958], dtype=float32) 4641 ``` 4642 4643 For complex numbers, the exponential value is calculated as follows: 4644 4645 ``` 4646 e^(x+iy) = e^x * e^iy = e^x * (cos y + i sin y) 4647 ``` 4648 4649 Let's consider complex number 1+1j as an example. 4650 e^1 * (cos 1 + i sin 1) = 2.7182818284590 * (0.54030230586+0.8414709848j) 4651 4652 ```python 4653 x = tf.constant(1 + 1j) 4654 tf.math.exp(x) ==> 1.4686939399158851+2.2873552871788423j 4655 ``` 4656 }]; 4657 4658 let arguments = (ins 4659 TF_FpOrComplexTensor:$x 4660 ); 4661 4662 let results = (outs 4663 TF_FpOrComplexTensor:$y 4664 ); 4665 4666 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4667} 4668 4669def TF_ExpandDimsOp : TF_Op<"ExpandDims", [NoSideEffect]> { 4670 let summary = "Inserts a dimension of 1 into a tensor's shape."; 4671 4672 let description = [{ 4673Given a tensor `input`, this operation inserts a dimension of 1 at the 4674dimension index `axis` of `input`'s shape. The dimension index `axis` starts at 4675zero; if you specify a negative number for `axis` it is counted backward from 4676the end. 4677 4678This operation is useful if you want to add a batch dimension to a single 4679element. For example, if you have a single image of shape `[height, width, 4680channels]`, you can make it a batch of 1 image with `expand_dims(image, 0)`, 4681which will make the shape `[1, height, width, channels]`. 4682 4683Other examples: 4684 4685``` 4686# 't' is a tensor of shape [2] 4687shape(expand_dims(t, 0)) ==> [1, 2] 4688shape(expand_dims(t, 1)) ==> [2, 1] 4689shape(expand_dims(t, -1)) ==> [2, 1] 4690 4691# 't2' is a tensor of shape [2, 3, 5] 4692shape(expand_dims(t2, 0)) ==> [1, 2, 3, 5] 4693shape(expand_dims(t2, 2)) ==> [2, 3, 1, 5] 4694shape(expand_dims(t2, 3)) ==> [2, 3, 5, 1] 4695``` 4696 4697This operation requires that: 4698 4699`-1-input.dims() <= dim <= input.dims()` 4700 4701This operation is related to `squeeze()`, which removes dimensions of 4702size 1. 4703 }]; 4704 4705 let arguments = (ins 4706 TF_Tensor:$input, 4707 Arg<TF_I32OrI64Tensor, [{0-D (scalar). Specifies the dimension index at which to 4708expand the shape of `input`. Must be in the range 4709`[-rank(input) - 1, rank(input)]`.}]>:$dim 4710 ); 4711 4712 let results = (outs 4713 Res<TF_Tensor, [{Contains the same data as `input`, but its shape has an additional 4714dimension of size 1 added.}]>:$output 4715 ); 4716 4717 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4718 TF_DerivedOperandTypeAttr Tdim = TF_DerivedOperandTypeAttr<1>; 4719 4720 let builders = [ 4721 OpBuilder<(ins "Value":$condition, "Value":$dim)> 4722 ]; 4723} 4724 4725def TF_Expm1Op : TF_Op<"Expm1", [InferTensorType, NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 4726 let summary = "Computes `exp(x) - 1` element-wise."; 4727 4728 let description = [{ 4729i.e. `exp(x) - 1` or `e^(x) - 1`, where `x` is the input tensor. 4730 `e` denotes Euler's number and is approximately equal to 2.718281. 4731 4732 ```python 4733 x = tf.constant(2.0) 4734 tf.math.expm1(x) ==> 6.389056 4735 4736 x = tf.constant([2.0, 8.0]) 4737 tf.math.expm1(x) ==> array([6.389056, 2979.958], dtype=float32) 4738 4739 x = tf.constant(1 + 1j) 4740 tf.math.expm1(x) ==> (0.46869393991588515+2.2873552871788423j) 4741 ``` 4742 }]; 4743 4744 let arguments = (ins 4745 TF_FpOrComplexTensor:$x 4746 ); 4747 4748 let results = (outs 4749 TF_FpOrComplexTensor:$y 4750 ); 4751 4752 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4753 4754 let extraClassDeclaration = [{ 4755 // InferTypeOpInterface: 4756 static bool isCompatibleReturnTypes(TypeRange l, TypeRange r) { 4757 return ArraysAreCastCompatible(l, r); 4758 } 4759 }]; 4760 4761} 4762 4763def TF_ExtractImagePatchesOp : TF_Op<"ExtractImagePatches", [NoSideEffect]> { 4764 let summary = [{ 4765Extract `patches` from `images` and put them in the "depth" output dimension. 4766 }]; 4767 4768 let arguments = (ins 4769 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{4-D Tensor with shape `[batch, in_rows, in_cols, depth]`.}]>:$images, 4770 4771 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$ksizes, 4772 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$strides, 4773 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$rates, 4774 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding 4775 ); 4776 4777 let results = (outs 4778 Res<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{4-D Tensor with shape `[batch, out_rows, out_cols, ksize_rows * 4779ksize_cols * depth]` containing image patches with size 4780`ksize_rows x ksize_cols x depth` vectorized in the "depth" dimension. Note 4781`out_rows` and `out_cols` are the dimensions of the output patches.}]>:$patches 4782 ); 4783 4784 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 4785} 4786 4787def TF_FFTOp : TF_Op<"FFT", [NoSideEffect]> { 4788 let summary = "Fast Fourier transform."; 4789 4790 let description = [{ 4791Computes the 1-dimensional discrete Fourier transform over the inner-most 4792dimension of `input`. 4793 }]; 4794 4795 let arguments = (ins 4796 Arg<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor.}]>:$input 4797 ); 4798 4799 let results = (outs 4800 Res<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor of the same shape as `input`. The inner-most 4801 dimension of `input` is replaced with its 1D Fourier transform. 4802 4803@compatibility(numpy) 4804Equivalent to np.fft.fft 4805@end_compatibility}]>:$output 4806 ); 4807 4808 TF_DerivedOperandTypeAttr Tcomplex = TF_DerivedOperandTypeAttr<0>; 4809} 4810 4811def TF_FFT2DOp : TF_Op<"FFT2D", [NoSideEffect]> { 4812 let summary = "2D fast Fourier transform."; 4813 4814 let description = [{ 4815Computes the 2-dimensional discrete Fourier transform over the inner-most 48162 dimensions of `input`. 4817 }]; 4818 4819 let arguments = (ins 4820 Arg<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor.}]>:$input 4821 ); 4822 4823 let results = (outs 4824 Res<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor of the same shape as `input`. The inner-most 2 4825 dimensions of `input` are replaced with their 2D Fourier transform. 4826 4827@compatibility(numpy) 4828Equivalent to np.fft.fft2 4829@end_compatibility}]>:$output 4830 ); 4831 4832 TF_DerivedOperandTypeAttr Tcomplex = TF_DerivedOperandTypeAttr<0>; 4833} 4834 4835def TF_FFT3DOp : TF_Op<"FFT3D", [NoSideEffect]> { 4836 let summary = "3D fast Fourier transform."; 4837 4838 let description = [{ 4839Computes the 3-dimensional discrete Fourier transform over the inner-most 3 4840dimensions of `input`. 4841 }]; 4842 4843 let arguments = (ins 4844 Arg<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor.}]>:$input 4845 ); 4846 4847 let results = (outs 4848 Res<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor of the same shape as `input`. The inner-most 3 4849 dimensions of `input` are replaced with their 3D Fourier transform. 4850 4851@compatibility(numpy) 4852Equivalent to np.fft.fftn with 3 dimensions. 4853@end_compatibility}]>:$output 4854 ); 4855 4856 TF_DerivedOperandTypeAttr Tcomplex = TF_DerivedOperandTypeAttr<0>; 4857} 4858 4859def TF_FakeParamOp : TF_Op<"FakeParam", [NoSideEffect, TF_NoConstantFold]> { 4860 let summary = [{ 4861 This op is used as a placeholder in If branch functions. It doesn't provide a 4862 valid output when run, so must either be removed (e.g. replaced with a 4863 function input) or guaranteed not to be used (e.g. if mirroring an 4864 intermediate output needed for the gradient computation of the other branch). 4865 }]; 4866 4867 let arguments = (ins 4868 TF_ShapeAttr:$shape 4869 ); 4870 4871 let results = (outs 4872 Res<TF_Tensor, [{ \"Fake\" output value. This should not be consumed by another op.}]>:$output 4873 ); 4874 4875 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 4876} 4877 4878def TF_FakeQuantWithMinMaxArgsOp : TF_Op<"FakeQuantWithMinMaxArgs", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 4879 let summary = [{ 4880Fake-quantize the 'inputs' tensor, type float to 'outputs' tensor of same type. 4881 }]; 4882 4883 let description = [{ 4884Attributes 4885 4886* `[min; max]` define the clamping range for the `inputs` data. 4887* `inputs` values are quantized into the quantization range ( 4888`[0; 2^num_bits - 1]` when `narrow_range` is false and `[1; 2^num_bits - 1]` 4889when it is true) and then de-quantized and output as floats in `[min; max]` 4890interval. 4891* `num_bits` is the bitwidth of the quantization; between 2 and 16, inclusive. 4892 4893Before quantization, `min` and `max` values are adjusted with the following 4894logic. 4895It is suggested to have `min <= 0 <= max`. If `0` is not in the range of values, 4896the behavior can be unexpected: 4897 4898* If `0 < min < max`: `min_adj = 0` and `max_adj = max - min`. 4899* If `min < max < 0`: `min_adj = min - max` and `max_adj = 0`. 4900* If `min <= 0 <= max`: `scale = (max - min) / (2^num_bits - 1) `, 4901`min_adj = scale * round(min / scale)` and `max_adj = max + min_adj - min`. 4902 4903Quantization is called fake since the output is still in floating point. 4904 }]; 4905 4906 let arguments = (ins 4907 TF_Float32Tensor:$inputs, 4908 4909 DefaultValuedAttr<F32Attr, "-6.0f">:$min, 4910 DefaultValuedAttr<F32Attr, "6.0f">:$max, 4911 DefaultValuedAttr<I64Attr, "8">:$num_bits, 4912 DefaultValuedAttr<BoolAttr, "false">:$narrow_range 4913 ); 4914 4915 let results = (outs 4916 TF_Float32Tensor:$outputs 4917 ); 4918 4919 let hasVerifier = 1; 4920} 4921 4922def TF_FakeQuantWithMinMaxArgsGradientOp : TF_Op<"FakeQuantWithMinMaxArgsGradient", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 4923 let summary = "Compute gradients for a FakeQuantWithMinMaxArgs operation."; 4924 4925 let arguments = (ins 4926 Arg<TF_Float32Tensor, [{Backpropagated gradients above the FakeQuantWithMinMaxArgs operation.}]>:$gradients, 4927 Arg<TF_Float32Tensor, [{Values passed as inputs to the FakeQuantWithMinMaxArgs operation.}]>:$inputs, 4928 4929 DefaultValuedAttr<F32Attr, "-6.0f">:$min, 4930 DefaultValuedAttr<F32Attr, "6.0f">:$max, 4931 DefaultValuedAttr<I64Attr, "8">:$num_bits, 4932 DefaultValuedAttr<BoolAttr, "false">:$narrow_range 4933 ); 4934 4935 let results = (outs 4936 Res<TF_Float32Tensor, [{Backpropagated gradients below the FakeQuantWithMinMaxArgs operation: 4937`gradients * (inputs >= min && inputs <= max)`.}]>:$backprops 4938 ); 4939} 4940 4941def TF_FakeQuantWithMinMaxVarsOp : TF_Op<"FakeQuantWithMinMaxVars", [NoSideEffect]> { 4942 let summary = [{ 4943Fake-quantize the 'inputs' tensor of type float via global float scalars 4944 }]; 4945 4946 let description = [{ 4947Fake-quantize the `inputs` tensor of type float via global float scalars 4948`min` and `max` to `outputs` tensor of same shape as `inputs`. 4949 4950Attributes 4951 4952* `[min; max]` define the clamping range for the `inputs` data. 4953* `inputs` values are quantized into the quantization range ( 4954`[0; 2^num_bits - 1]` when `narrow_range` is false and `[1; 2^num_bits - 1]` 4955when it is true) and then de-quantized and output as floats in `[min; max]` 4956interval. 4957* `num_bits` is the bitwidth of the quantization; between 2 and 16, inclusive. 4958 4959Before quantization, `min` and `max` values are adjusted with the following 4960logic. 4961It is suggested to have `min <= 0 <= max`. If `0` is not in the range of values, 4962the behavior can be unexpected: 4963 4964* If `0 < min < max`: `min_adj = 0` and `max_adj = max - min`. 4965* If `min < max < 0`: `min_adj = min - max` and `max_adj = 0`. 4966* If `min <= 0 <= max`: `scale = (max - min) / (2^num_bits - 1) `, 4967`min_adj = scale * round(min / scale)` and `max_adj = max + min_adj - min`. 4968 4969This operation has a gradient and thus allows for training `min` and `max` 4970values. 4971 }]; 4972 4973 let arguments = (ins 4974 TF_Float32Tensor:$inputs, 4975 TF_Float32Tensor:$min, 4976 TF_Float32Tensor:$max, 4977 4978 DefaultValuedAttr<I64Attr, "8">:$num_bits, 4979 DefaultValuedAttr<BoolAttr, "false">:$narrow_range 4980 ); 4981 4982 let results = (outs 4983 TF_Float32Tensor:$outputs 4984 ); 4985 4986 let hasVerifier = 1; 4987} 4988 4989def TF_FakeQuantWithMinMaxVarsGradientOp : TF_Op<"FakeQuantWithMinMaxVarsGradient", [NoSideEffect]> { 4990 let summary = "Compute gradients for a FakeQuantWithMinMaxVars operation."; 4991 4992 let arguments = (ins 4993 Arg<TF_Float32Tensor, [{Backpropagated gradients above the FakeQuantWithMinMaxVars operation.}]>:$gradients, 4994 Arg<TF_Float32Tensor, [{Values passed as inputs to the FakeQuantWithMinMaxVars operation. 4995min, max: Quantization interval, scalar floats.}]>:$inputs, 4996 TF_Float32Tensor:$min, 4997 TF_Float32Tensor:$max, 4998 4999 DefaultValuedAttr<I64Attr, "8">:$num_bits, 5000 DefaultValuedAttr<BoolAttr, "false">:$narrow_range 5001 ); 5002 5003 let results = (outs 5004 Res<TF_Float32Tensor, [{Backpropagated gradients w.r.t. inputs: 5005`gradients * (inputs >= min && inputs <= max)`.}]>:$backprops_wrt_input, 5006 Res<TF_Float32Tensor, [{Backpropagated gradients w.r.t. min parameter: 5007`sum(gradients * (inputs < min))`.}]>:$backprop_wrt_min, 5008 Res<TF_Float32Tensor, [{Backpropagated gradients w.r.t. max parameter: 5009`sum(gradients * (inputs > max))`.}]>:$backprop_wrt_max 5010 ); 5011} 5012 5013def TF_FakeQuantWithMinMaxVarsPerChannelOp : TF_Op<"FakeQuantWithMinMaxVarsPerChannel", [NoSideEffect]> { 5014 let summary = [{ 5015Fake-quantize the 'inputs' tensor of type float via per-channel floats 5016 }]; 5017 5018 let description = [{ 5019Fake-quantize the `inputs` tensor of type float per-channel and one of the 5020shapes: `[d]`, `[b, d]` `[b, h, w, d]` via per-channel floats `min` and `max` 5021of shape `[d]` to `outputs` tensor of same shape as `inputs`. 5022 5023Attributes 5024 5025* `[min; max]` define the clamping range for the `inputs` data. 5026* `inputs` values are quantized into the quantization range ( 5027`[0; 2^num_bits - 1]` when `narrow_range` is false and `[1; 2^num_bits - 1]` 5028when it is true) and then de-quantized and output as floats in `[min; max]` 5029interval. 5030* `num_bits` is the bitwidth of the quantization; between 2 and 16, inclusive. 5031 5032Before quantization, `min` and `max` values are adjusted with the following 5033logic. 5034It is suggested to have `min <= 0 <= max`. If `0` is not in the range of values, 5035the behavior can be unexpected: 5036 5037* If `0 < min < max`: `min_adj = 0` and `max_adj = max - min`. 5038* If `min < max < 0`: `min_adj = min - max` and `max_adj = 0`. 5039* If `min <= 0 <= max`: `scale = (max - min) / (2^num_bits - 1) `, 5040`min_adj = scale * round(min / scale)` and `max_adj = max + min_adj - min`. 5041 5042This operation has a gradient and thus allows for training `min` and `max` 5043values. 5044 }]; 5045 5046 let arguments = (ins 5047 TF_Float32Tensor:$inputs, 5048 TF_Float32Tensor:$min, 5049 TF_Float32Tensor:$max, 5050 5051 DefaultValuedAttr<I64Attr, "8">:$num_bits, 5052 DefaultValuedAttr<BoolAttr, "false">:$narrow_range 5053 ); 5054 5055 let results = (outs 5056 TF_Float32Tensor:$outputs 5057 ); 5058 5059 let hasVerifier = 1; 5060} 5061 5062def TF_FakeQuantWithMinMaxVarsPerChannelGradientOp : TF_Op<"FakeQuantWithMinMaxVarsPerChannelGradient", [NoSideEffect]> { 5063 let summary = [{ 5064Compute gradients for a FakeQuantWithMinMaxVarsPerChannel operation. 5065 }]; 5066 5067 let arguments = (ins 5068 Arg<TF_Float32Tensor, [{Backpropagated gradients above the FakeQuantWithMinMaxVars operation, 5069shape one of: `[d]`, `[b, d]`, `[b, h, w, d]`.}]>:$gradients, 5070 Arg<TF_Float32Tensor, [{Values passed as inputs to the FakeQuantWithMinMaxVars operation, shape 5071 same as `gradients`. 5072min, max: Quantization interval, floats of shape `[d]`.}]>:$inputs, 5073 TF_Float32Tensor:$min, 5074 TF_Float32Tensor:$max, 5075 5076 DefaultValuedAttr<I64Attr, "8">:$num_bits, 5077 DefaultValuedAttr<BoolAttr, "false">:$narrow_range 5078 ); 5079 5080 let results = (outs 5081 Res<TF_Float32Tensor, [{Backpropagated gradients w.r.t. inputs, shape same as 5082`inputs`: 5083 `gradients * (inputs >= min && inputs <= max)`.}]>:$backprops_wrt_input, 5084 Res<TF_Float32Tensor, [{Backpropagated gradients w.r.t. min parameter, shape `[d]`: 5085`sum_per_d(gradients * (inputs < min))`.}]>:$backprop_wrt_min, 5086 Res<TF_Float32Tensor, [{Backpropagated gradients w.r.t. max parameter, shape `[d]`: 5087`sum_per_d(gradients * (inputs > max))`.}]>:$backprop_wrt_max 5088 ); 5089} 5090 5091def TF_FillOp : TF_Op<"Fill", [NoSideEffect]> { 5092 let summary = "Creates a tensor filled with a scalar value."; 5093 5094 let description = [{ 5095This operation creates a tensor of shape `dims` and fills it with `value`. 5096 5097For example: 5098 5099``` 5100# Output tensor has shape [2, 3]. 5101fill([2, 3], 9) ==> [[9, 9, 9] 5102 [9, 9, 9]] 5103``` 5104 5105`tf.fill` differs from `tf.constant` in a few ways: 5106 5107* `tf.fill` only supports scalar contents, whereas `tf.constant` supports 5108 Tensor values. 5109* `tf.fill` creates an Op in the computation graph that constructs the actual 5110 Tensor value at runtime. This is in contrast to `tf.constant` which embeds 5111 the entire Tensor into the graph with a `Const` node. 5112* Because `tf.fill` evaluates at graph runtime, it supports dynamic shapes 5113 based on other runtime Tensors, unlike `tf.constant`. 5114 }]; 5115 5116 let arguments = (ins 5117 Arg<TF_I32OrI64Tensor, [{1-D. Represents the shape of the output tensor.}]>:$dims, 5118 Arg<TF_Tensor, [{0-D (scalar). Value to fill the returned tensor. 5119 5120@compatibility(numpy) 5121Equivalent to np.full 5122@end_compatibility}]>:$value 5123 ); 5124 5125 let results = (outs 5126 TF_Tensor:$output 5127 ); 5128 5129 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 5130 TF_DerivedOperandTypeAttr index_type = TF_DerivedOperandTypeAttr<0>; 5131 5132 let hasVerifier = 1; 5133 5134 let hasFolder = 1; 5135 5136 let builders = [ 5137 OpBuilder<(ins "Value":$dims, "Value":$value)> 5138 ]; 5139} 5140 5141def TF_FinalizeDatasetOp : TF_Op<"FinalizeDataset", [NoSideEffect]> { 5142 let summary = [{ 5143Creates a dataset by applying `tf.data.Options` to `input_dataset`. 5144 }]; 5145 5146 let arguments = (ins 5147 Arg<TF_VariantTensor, [{A variant tensor representing the input dataset.}]>:$input_dataset, 5148 5149 DefaultValuedAttr<BoolAttr, "false">:$has_captured_ref, 5150 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 5151 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 5152 ); 5153 5154 let results = (outs 5155 TF_VariantTensor:$handle 5156 ); 5157} 5158 5159def TF_FinalizeTPUEmbeddingOp : TF_Op<"FinalizeTPUEmbedding", []> { 5160 let summary = "An op that finalizes the TPUEmbedding configuration."; 5161 5162 let arguments = (ins 5163 Arg<TF_StrTensor, [{A string-encoded common configuration proto containing metadata 5164about the TPUEmbedding partitioner output and the HBM size (in bytes) required 5165for operation.}]>:$common_config, 5166 Arg<TF_StrTensor, [{A string-encoded memory config proto containing metadata about 5167the memory allocations reserved for TPUEmbedding.}]>:$memory_config 5168 ); 5169 5170 let results = (outs); 5171} 5172 5173def TF_FlatMapDatasetOp : TF_Op<"FlatMapDataset", [NoSideEffect]> { 5174 let summary = [{ 5175Creates a dataset that applies `f` to the outputs of `input_dataset`. 5176 }]; 5177 5178 let description = [{ 5179Unlike MapDataset, the `f` in FlatMapDataset is expected to return a 5180Dataset variant, and FlatMapDataset will flatten successive results 5181into a single Dataset. 5182 }]; 5183 5184 let arguments = (ins 5185 TF_VariantTensor:$input_dataset, 5186 Variadic<TF_Tensor>:$other_arguments, 5187 5188 SymbolRefAttr:$f, 5189 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 5190 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 5191 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 5192 ); 5193 5194 let results = (outs 5195 TF_VariantTensor:$handle 5196 ); 5197 5198 TF_DerivedOperandTypeListAttr Targuments = TF_DerivedOperandTypeListAttr<1>; 5199} 5200 5201def TF_FloorOp : TF_Op<"Floor", [Idempotent, NoSideEffect, SameOperandsAndResultType]> { 5202 let summary = "Returns element-wise largest integer not greater than x."; 5203 5204 let arguments = (ins 5205 TF_FloatTensor:$x 5206 ); 5207 5208 let results = (outs 5209 TF_FloatTensor:$y 5210 ); 5211 5212 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5213} 5214 5215def TF_FloorDivOp : TF_Op<"FloorDiv", [NoSideEffect, ResultsBroadcastableShape]>, 5216 WithBroadcastableBinOpBuilder { 5217 let summary = "Returns x // y element-wise."; 5218 5219 let description = [{ 5220*NOTE*: `FloorDiv` supports broadcasting. More about broadcasting 5221[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 5222 }]; 5223 5224 let arguments = (ins 5225 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$x, 5226 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$y 5227 ); 5228 5229 let results = (outs 5230 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$z 5231 ); 5232 5233 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5234} 5235 5236def TF_FloorModOp : TF_Op<"FloorMod", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 5237 WithBroadcastableBinOpBuilder { 5238 let summary = "Returns element-wise remainder of division."; 5239 5240 let description = [{ 5241This follows Python semantics in that the 5242result here is consistent with a flooring divide. E.g. 5243`floor(x / y) * y + floormod(x, y) = x`, regardless of the signs of x and y. 5244 5245*NOTE*: `FloorMod` supports broadcasting. More about broadcasting 5246[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 5247 }]; 5248 5249 let arguments = (ins 5250 TF_IntOrFpTensor:$x, 5251 TF_IntOrFpTensor:$y 5252 ); 5253 5254 let results = (outs 5255 TF_IntOrFpTensor:$z 5256 ); 5257 5258 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5259} 5260 5261def TF_FusedBatchNormOp : TF_Op<"FusedBatchNorm", [NoSideEffect]> { 5262 let summary = "Batch normalization."; 5263 5264 let description = [{ 5265Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". 5266The size of 1D Tensors matches the dimension C of the 4D Tensors. 5267 }]; 5268 5269 let arguments = (ins 5270 Arg<TF_Float32Tensor, [{A 4D Tensor for input data.}]>:$x, 5271 Arg<TF_Float32Tensor, [{A 1D Tensor for scaling factor, to scale the normalized x.}]>:$scale, 5272 Arg<TF_Float32Tensor, [{A 1D Tensor for offset, to shift to the normalized x.}]>:$offset, 5273 Arg<TF_Float32Tensor, [{A 1D Tensor for population mean. Used for inference only; 5274must be empty for training.}]>:$mean, 5275 Arg<TF_Float32Tensor, [{A 1D Tensor for population variance. Used for inference only; 5276must be empty for training.}]>:$variance, 5277 5278 DefaultValuedAttr<F32Attr, "0.0001f">:$epsilon, 5279 DefaultValuedAttr<F32Attr, "1.0f">:$exponential_avg_factor, 5280 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 5281 DefaultValuedAttr<BoolAttr, "true">:$is_training 5282 ); 5283 5284 let results = (outs 5285 Res<TF_Float32Tensor, [{A 4D Tensor for output data.}]>:$y, 5286 Res<TF_Float32Tensor, [{A 1D Tensor for the computed batch mean, to be used by TensorFlow 5287to compute the running mean.}]>:$batch_mean, 5288 Res<TF_Float32Tensor, [{A 1D Tensor for the computed batch variance, to be used by 5289TensorFlow to compute the running variance.}]>:$batch_variance, 5290 Res<TF_Float32Tensor, [{A 1D Tensor for the computed batch mean, to be reused 5291in the gradient computation.}]>:$reserve_space_1, 5292 Res<TF_Float32Tensor, [{A 1D Tensor for the computed batch variance (inverted variance 5293in the cuDNN case), to be reused in the gradient computation.}]>:$reserve_space_2 5294 ); 5295 5296 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5297 5298 let hasCanonicalizer = 1; 5299 5300 let hasVerifier = 1; 5301} 5302 5303def TF_FusedBatchNormGradOp : TF_Op<"FusedBatchNormGrad", [NoSideEffect]> { 5304 let summary = "Gradient for batch normalization."; 5305 5306 let description = [{ 5307Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". 5308The size of 1D Tensors matches the dimension C of the 4D Tensors. 5309 }]; 5310 5311 let arguments = (ins 5312 Arg<TF_Float32Tensor, [{A 4D Tensor for the gradient with respect to y.}]>:$y_backprop, 5313 Arg<TF_Float32Tensor, [{A 4D Tensor for input data.}]>:$x, 5314 Arg<TF_Float32Tensor, [{A 1D Tensor for scaling factor, to scale the normalized x.}]>:$scale, 5315 Arg<TF_Float32Tensor, [{When is_training is True, a 1D Tensor for the computed batch 5316mean to be reused in gradient computation. When is_training is 5317False, a 1D Tensor for the population mean to be reused in both 53181st and 2nd order gradient computation.}]>:$reserve_space_1, 5319 Arg<TF_Float32Tensor, [{When is_training is True, a 1D Tensor for the computed batch 5320variance (inverted variance in the cuDNN case) to be reused in 5321gradient computation. When is_training is False, a 1D Tensor 5322for the population variance to be reused in both 1st and 2nd 5323order gradient computation.}]>:$reserve_space_2, 5324 5325 DefaultValuedAttr<F32Attr, "0.0001f">:$epsilon, 5326 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 5327 DefaultValuedAttr<BoolAttr, "true">:$is_training 5328 ); 5329 5330 let results = (outs 5331 Res<TF_Float32Tensor, [{A 4D Tensor for the gradient with respect to x.}]>:$x_backprop, 5332 Res<TF_Float32Tensor, [{A 1D Tensor for the gradient with respect to scale.}]>:$scale_backprop, 5333 Res<TF_Float32Tensor, [{A 1D Tensor for the gradient with respect to offset.}]>:$offset_backprop, 5334 Res<TF_Float32Tensor, [{Unused placeholder to match the mean input in FusedBatchNorm.}]>:$reserve_space_3, 5335 Res<TF_Float32Tensor, [{Unused placeholder to match the variance input 5336in FusedBatchNorm.}]>:$reserve_space_4 5337 ); 5338 5339 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5340} 5341 5342def TF_FusedBatchNormGradV2Op : TF_Op<"FusedBatchNormGradV2", [NoSideEffect]> { 5343 let summary = "Gradient for batch normalization."; 5344 5345 let description = [{ 5346Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". 5347The size of 1D Tensors matches the dimension C of the 4D Tensors. 5348 }]; 5349 5350 let arguments = (ins 5351 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{A 4D Tensor for the gradient with respect to y.}]>:$y_backprop, 5352 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{A 4D Tensor for input data.}]>:$x, 5353 Arg<TF_Float32Tensor, [{A 1D Tensor for scaling factor, to scale the normalized x.}]>:$scale, 5354 Arg<TF_Float32Tensor, [{When is_training is True, a 1D Tensor for the computed batch 5355mean to be reused in gradient computation. When is_training is 5356False, a 1D Tensor for the population mean to be reused in both 53571st and 2nd order gradient computation.}]>:$reserve_space_1, 5358 Arg<TF_Float32Tensor, [{When is_training is True, a 1D Tensor for the computed batch 5359variance (inverted variance in the cuDNN case) to be reused in 5360gradient computation. When is_training is False, a 1D Tensor 5361for the population variance to be reused in both 1st and 2nd 5362order gradient computation.}]>:$reserve_space_2, 5363 5364 DefaultValuedAttr<F32Attr, "0.0001f">:$epsilon, 5365 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 5366 DefaultValuedAttr<BoolAttr, "true">:$is_training 5367 ); 5368 5369 let results = (outs 5370 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{A 4D Tensor for the gradient with respect to x.}]>:$x_backprop, 5371 Res<TF_Float32Tensor, [{A 1D Tensor for the gradient with respect to scale.}]>:$scale_backprop, 5372 Res<TF_Float32Tensor, [{A 1D Tensor for the gradient with respect to offset.}]>:$offset_backprop, 5373 Res<TF_Float32Tensor, [{Unused placeholder to match the mean input in FusedBatchNorm.}]>:$reserve_space_3, 5374 Res<TF_Float32Tensor, [{Unused placeholder to match the variance input 5375in FusedBatchNorm.}]>:$reserve_space_4 5376 ); 5377 5378 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5379 TF_DerivedOperandTypeAttr U = TF_DerivedOperandTypeAttr<3>; 5380} 5381 5382def TF_FusedBatchNormGradV3Op : TF_Op<"FusedBatchNormGradV3", [NoSideEffect, TF_LayoutSensitiveInterface]> { 5383 let summary = "Gradient for batch normalization."; 5384 5385 let description = [{ 5386Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". 5387The size of 1D Tensors matches the dimension C of the 4D Tensors. 5388 }]; 5389 5390 let arguments = (ins 5391 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{A 4D Tensor for the gradient with respect to y.}]>:$y_backprop, 5392 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{A 4D Tensor for input data.}]>:$x, 5393 Arg<TF_Float32Tensor, [{A 1D Tensor for scaling factor, to scale the normalized x.}]>:$scale, 5394 Arg<TF_Float32Tensor, [{When is_training is True, a 1D Tensor for the computed batch 5395mean to be reused in gradient computation. When is_training is 5396False, a 1D Tensor for the population mean to be reused in both 53971st and 2nd order gradient computation.}]>:$reserve_space_1, 5398 Arg<TF_Float32Tensor, [{When is_training is True, a 1D Tensor for the computed batch 5399variance (inverted variance in the cuDNN case) to be reused in 5400gradient computation. When is_training is False, a 1D Tensor 5401for the population variance to be reused in both 1st and 2nd 5402order gradient computation.}]>:$reserve_space_2, 5403 Arg<TF_Float32Tensor, [{When is_training is True, a 1D Tensor for some intermediate results to be reused 5404in gradient computation. When is_training is False, a dummy empty Tensor will be 5405created.}]>:$reserve_space_3, 5406 5407 DefaultValuedAttr<F32Attr, "0.0001f">:$epsilon, 5408 DefaultValuedAttr<TF_AnyStrAttrOf<["NHWC", "NCHW", "NDHWC", "NCDHW"]>, "\"NHWC\"">:$data_format, 5409 DefaultValuedAttr<BoolAttr, "true">:$is_training 5410 ); 5411 5412 let results = (outs 5413 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{A 4D Tensor for the gradient with respect to x.}]>:$x_backprop, 5414 Res<TF_Float32Tensor, [{A 1D Tensor for the gradient with respect to scale.}]>:$scale_backprop, 5415 Res<TF_Float32Tensor, [{A 1D Tensor for the gradient with respect to offset.}]>:$offset_backprop, 5416 Res<TF_Float32Tensor, [{Unused placeholder to match the mean input in FusedBatchNorm.}]>:$reserve_space_4, 5417 Res<TF_Float32Tensor, [{Unused placeholder to match the variance input 5418in FusedBatchNorm.}]>:$reserve_space_5 5419 ); 5420 5421 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5422 TF_DerivedOperandTypeAttr U = TF_DerivedOperandTypeAttr<3>; 5423 5424 let extraClassDeclaration = [{ 5425 // TF_LayoutSensitiveInterface: 5426 SmallVector<unsigned, 4> GetLayoutDependentArgs() { return {0, 1}; } 5427 SmallVector<unsigned, 4> GetLayoutDependentResults() { return {0}; } 5428 StringRef GetOptimalLayout(const RuntimeDevices& devices); 5429 LogicalResult UpdateDataFormat(StringRef data_format); 5430 }]; 5431} 5432 5433def TF_FusedBatchNormV2Op : TF_Op<"FusedBatchNormV2", [NoSideEffect, TF_FoldOperandsTransposeInterface, TF_LayoutSensitiveInterface]> { 5434 let summary = "Batch normalization."; 5435 5436 let description = [{ 5437Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". 5438The size of 1D Tensors matches the dimension C of the 4D Tensors. 5439 }]; 5440 5441 let arguments = (ins 5442 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{A 4D Tensor for input data.}]>:$x, 5443 Arg<TF_Float32Tensor, [{A 1D Tensor for scaling factor, to scale the normalized x.}]>:$scale, 5444 Arg<TF_Float32Tensor, [{A 1D Tensor for offset, to shift to the normalized x.}]>:$offset, 5445 Arg<TF_Float32Tensor, [{A 1D Tensor for population mean. Used for inference only; 5446must be empty for training.}]>:$mean, 5447 Arg<TF_Float32Tensor, [{A 1D Tensor for population variance. Used for inference only; 5448must be empty for training.}]>:$variance, 5449 5450 DefaultValuedAttr<F32Attr, "0.0001f">:$epsilon, 5451 DefaultValuedAttr<F32Attr, "1.0f">:$exponential_avg_factor, 5452 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 5453 DefaultValuedAttr<BoolAttr, "true">:$is_training 5454 ); 5455 5456 let results = (outs 5457 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{A 4D Tensor for output data.}]>:$y, 5458 Res<TF_Float32Tensor, [{A 1D Tensor for the computed batch mean, to be used by TensorFlow 5459to compute the running mean.}]>:$batch_mean, 5460 Res<TF_Float32Tensor, [{A 1D Tensor for the computed batch variance, to be used by 5461TensorFlow to compute the running variance.}]>:$batch_variance, 5462 Res<TF_Float32Tensor, [{A 1D Tensor for the computed batch mean, to be reused 5463in the gradient computation.}]>:$reserve_space_1, 5464 Res<TF_Float32Tensor, [{A 1D Tensor for the computed batch variance (inverted variance 5465in the cuDNN case), to be reused in the gradient computation.}]>:$reserve_space_2 5466 ); 5467 5468 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5469 TF_DerivedOperandTypeAttr U = TF_DerivedOperandTypeAttr<1>; 5470 5471 let extraClassDeclaration = [{ 5472 // TF_FoldOperandsTransposeInterface: 5473 SmallVector<unsigned, 4> GetLayoutDependentArgs() { return {0}; } 5474 SmallVector<unsigned, 4> GetLayoutDependentResults() { return {0}; } 5475 LogicalResult FoldOperandsPermutation(ArrayRef<int64_t> permutation); 5476 5477 // TF_LayoutSensitiveInterface: 5478 StringRef GetOptimalLayout(const RuntimeDevices& devices); 5479 LogicalResult UpdateDataFormat(StringRef data_format); 5480 }]; 5481} 5482 5483def TF_FusedBatchNormV3Op : TF_Op<"FusedBatchNormV3", [NoSideEffect, TF_FoldOperandsTransposeInterface, TF_LayoutSensitiveInterface]> { 5484 let summary = "Batch normalization."; 5485 5486 let description = [{ 5487Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW". 5488The size of 1D Tensors matches the dimension C of the 4D Tensors. 5489 }]; 5490 5491 let arguments = (ins 5492 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{A 4D Tensor for input data.}]>:$x, 5493 Arg<TensorOf<[TF_Bfloat16, TF_Float32]>, [{A 1D Tensor for scaling factor, to scale the normalized x.}]>:$scale, 5494 Arg<TensorOf<[TF_Bfloat16, TF_Float32]>, [{A 1D Tensor for offset, to shift to the normalized x.}]>:$offset, 5495 Arg<TensorOf<[TF_Bfloat16, TF_Float32]>, [{A 1D Tensor for population mean. Used for inference only; 5496must be empty for training.}]>:$mean, 5497 Arg<TensorOf<[TF_Bfloat16, TF_Float32]>, [{A 1D Tensor for population variance. Used for inference only; 5498must be empty for training.}]>:$variance, 5499 5500 DefaultValuedAttr<F32Attr, "0.0001f">:$epsilon, 5501 DefaultValuedAttr<F32Attr, "1.0f">:$exponential_avg_factor, 5502 DefaultValuedAttr<TF_AnyStrAttrOf<["NHWC", "NCHW", "NDHWC", "NCDHW"]>, "\"NHWC\"">:$data_format, 5503 DefaultValuedAttr<BoolAttr, "true">:$is_training 5504 ); 5505 5506 let results = (outs 5507 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{A 4D Tensor for output data.}]>:$y, 5508 Res<TensorOf<[TF_Bfloat16, TF_Float32]>, [{A 1D Tensor for the computed batch mean, to be used by TensorFlow 5509to compute the running mean.}]>:$batch_mean, 5510 Res<TensorOf<[TF_Bfloat16, TF_Float32]>, [{A 1D Tensor for the computed batch variance, to be used by 5511TensorFlow to compute the running variance.}]>:$batch_variance, 5512 Res<TensorOf<[TF_Bfloat16, TF_Float32]>, [{A 1D Tensor for the computed batch mean, to be reused 5513in the gradient computation.}]>:$reserve_space_1, 5514 Res<TensorOf<[TF_Bfloat16, TF_Float32]>, [{A 1D Tensor for the computed batch variance (inverted variance 5515in the cuDNN case), to be reused in the gradient computation.}]>:$reserve_space_2, 5516 Res<TensorOf<[TF_Bfloat16, TF_Float32]>, [{A 1D Tensor for some intermediate results, to be reused in the gradient 5517computation for better efficiency.}]>:$reserve_space_3 5518 ); 5519 5520 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5521 TF_DerivedOperandTypeAttr U = TF_DerivedOperandTypeAttr<1>; 5522 5523 let extraClassDeclaration = [{ 5524 // TF_FoldOperandsTransposeInterface: 5525 SmallVector<unsigned, 4> GetLayoutDependentArgs() { return {0}; } 5526 SmallVector<unsigned, 4> GetLayoutDependentResults() { return {0}; } 5527 LogicalResult FoldOperandsPermutation(ArrayRef<int64_t> permutation); 5528 5529 // TF_LayoutSensitiveInterface: 5530 StringRef GetOptimalLayout(const RuntimeDevices& devices); 5531 LogicalResult UpdateDataFormat(StringRef data_format); 5532 }]; 5533} 5534 5535def TF_GatherOp : TF_Op<"Gather", [NoSideEffect]> { 5536 let summary = "Gather slices from `params` according to `indices`."; 5537 5538 let description = [{ 5539`indices` must be an integer tensor of any dimension (usually 0-D or 1-D). 5540Produces an output tensor with shape `indices.shape + params.shape[1:]` where: 5541 5542```python 5543 # Scalar indices 5544 output[:, ..., :] = params[indices, :, ... :] 5545 5546 # Vector indices 5547 output[i, :, ..., :] = params[indices[i], :, ... :] 5548 5549 # Higher rank indices 5550 output[i, ..., j, :, ... :] = params[indices[i, ..., j], :, ..., :] 5551``` 5552 5553If `indices` is a permutation and `len(indices) == params.shape[0]` then 5554this operation will permute `params` accordingly. 5555 5556`validate_indices`: DEPRECATED. If this operation is assigned to CPU, values in 5557`indices` are always validated to be within range. If assigned to GPU, 5558out-of-bound indices result in safe but unspecified behavior, which may include 5559raising an error. 5560 5561<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 5562<img style="width:100%" src="https://www.tensorflow.org/images/Gather.png" alt> 5563</div> 5564 }]; 5565 5566 let arguments = (ins 5567 TF_Tensor:$params, 5568 TF_I32OrI64Tensor:$indices, 5569 5570 DefaultValuedAttr<BoolAttr, "true">:$validate_indices 5571 ); 5572 5573 let results = (outs 5574 TF_Tensor:$output 5575 ); 5576 5577 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 5578 TF_DerivedOperandTypeAttr Tparams = TF_DerivedOperandTypeAttr<0>; 5579 5580 let hasCanonicalizer = 1; 5581} 5582 5583def TF_GatherNdOp : TF_Op<"GatherNd", [NoSideEffect]> { 5584 let summary = [{ 5585Gather slices from `params` into a Tensor with shape specified by `indices`. 5586 }]; 5587 5588 let description = [{ 5589`indices` is a K-dimensional integer tensor, best thought of as a 5590(K-1)-dimensional tensor of indices into `params`, where each element defines a 5591slice of `params`: 5592 5593 output[\\(i_0, ..., i_{K-2}\\)] = params[indices[\\(i_0, ..., i_{K-2}\\)]] 5594 5595Whereas in `tf.gather` `indices` defines slices into the `axis` 5596dimension of `params`, in `tf.gather_nd`, `indices` defines slices into the 5597first `N` dimensions of `params`, where `N = indices.shape[-1]`. 5598 5599The last dimension of `indices` can be at most the rank of 5600`params`: 5601 5602 indices.shape[-1] <= params.rank 5603 5604The last dimension of `indices` corresponds to elements 5605(if `indices.shape[-1] == params.rank`) or slices 5606(if `indices.shape[-1] < params.rank`) along dimension `indices.shape[-1]` 5607of `params`. The output tensor has shape 5608 5609 indices.shape[:-1] + params.shape[indices.shape[-1]:] 5610 5611Note that on CPU, if an out of bound index is found, an error is returned. 5612On GPU, if an out of bound index is found, a 0 is stored in the 5613corresponding output value. 5614 5615Some examples below. 5616 5617Simple indexing into a matrix: 5618 5619```python 5620 indices = [[0, 0], [1, 1]] 5621 params = [['a', 'b'], ['c', 'd']] 5622 output = ['a', 'd'] 5623``` 5624 5625Slice indexing into a matrix: 5626 5627```python 5628 indices = [[1], [0]] 5629 params = [['a', 'b'], ['c', 'd']] 5630 output = [['c', 'd'], ['a', 'b']] 5631``` 5632 5633Indexing into a 3-tensor: 5634 5635```python 5636 indices = [[1]] 5637 params = [[['a0', 'b0'], ['c0', 'd0']], 5638 [['a1', 'b1'], ['c1', 'd1']]] 5639 output = [[['a1', 'b1'], ['c1', 'd1']]] 5640 5641 5642 indices = [[0, 1], [1, 0]] 5643 params = [[['a0', 'b0'], ['c0', 'd0']], 5644 [['a1', 'b1'], ['c1', 'd1']]] 5645 output = [['c0', 'd0'], ['a1', 'b1']] 5646 5647 5648 indices = [[0, 0, 1], [1, 0, 1]] 5649 params = [[['a0', 'b0'], ['c0', 'd0']], 5650 [['a1', 'b1'], ['c1', 'd1']]] 5651 output = ['b0', 'b1'] 5652``` 5653 5654Batched indexing into a matrix: 5655 5656```python 5657 indices = [[[0, 0]], [[0, 1]]] 5658 params = [['a', 'b'], ['c', 'd']] 5659 output = [['a'], ['b']] 5660``` 5661 5662Batched slice indexing into a matrix: 5663 5664```python 5665 indices = [[[1]], [[0]]] 5666 params = [['a', 'b'], ['c', 'd']] 5667 output = [[['c', 'd']], [['a', 'b']]] 5668``` 5669 5670Batched indexing into a 3-tensor: 5671 5672```python 5673 indices = [[[1]], [[0]]] 5674 params = [[['a0', 'b0'], ['c0', 'd0']], 5675 [['a1', 'b1'], ['c1', 'd1']]] 5676 output = [[[['a1', 'b1'], ['c1', 'd1']]], 5677 [[['a0', 'b0'], ['c0', 'd0']]]] 5678 5679 indices = [[[0, 1], [1, 0]], [[0, 0], [1, 1]]] 5680 params = [[['a0', 'b0'], ['c0', 'd0']], 5681 [['a1', 'b1'], ['c1', 'd1']]] 5682 output = [[['c0', 'd0'], ['a1', 'b1']], 5683 [['a0', 'b0'], ['c1', 'd1']]] 5684 5685 5686 indices = [[[0, 0, 1], [1, 0, 1]], [[0, 1, 1], [1, 1, 0]]] 5687 params = [[['a0', 'b0'], ['c0', 'd0']], 5688 [['a1', 'b1'], ['c1', 'd1']]] 5689 output = [['b0', 'b1'], ['d0', 'c1']] 5690``` 5691 5692See also `tf.gather` and `tf.batch_gather`. 5693 }]; 5694 5695 let arguments = (ins 5696 Arg<TF_Tensor, [{The tensor from which to gather values.}]>:$params, 5697 Arg<TensorOf<[TF_Int16, TF_Int32, TF_Int64]>, [{Index tensor.}]>:$indices 5698 ); 5699 5700 let results = (outs 5701 Res<TF_Tensor, [{Values from `params` gathered from indices given by `indices`, with 5702shape `indices.shape[:-1] + params.shape[indices.shape[-1]:]`.}]>:$output 5703 ); 5704 5705 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 5706 TF_DerivedOperandTypeAttr Tparams = TF_DerivedOperandTypeAttr<0>; 5707} 5708 5709def TF_GatherV2Op : TF_Op<"GatherV2", [NoSideEffect]> { 5710 let summary = [{ 5711Gather slices from `params` axis `axis` according to `indices`. 5712 }]; 5713 5714 let description = [{ 5715`indices` must be an integer tensor of any dimension (usually 0-D or 1-D). 5716Produces an output tensor with shape `params.shape[:axis] + 5717indices.shape[batch_dims:] + params.shape[axis + 1:]` where: 5718 5719```python 5720 # Scalar indices (output is rank(params) - 1). 5721 output[a_0, ..., a_n, b_0, ..., b_n] = 5722 params[a_0, ..., a_n, indices, b_0, ..., b_n] 5723 5724 # Vector indices (output is rank(params)). 5725 output[a_0, ..., a_n, i, b_0, ..., b_n] = 5726 params[a_0, ..., a_n, indices[i], b_0, ..., b_n] 5727 5728 # Higher rank indices (output is rank(params) + rank(indices) - 1). 5729 output[a_0, ..., a_n, i, ..., j, b_0, ... b_n] = 5730 params[a_0, ..., a_n, indices[i, ..., j], b_0, ..., b_n] 5731``` 5732 5733<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 5734<img style="width:100%" src="https://www.tensorflow.org/images/Gather.png" alt> 5735</div> 5736 5737Note that on CPU, if an out of bound index is found, an error is returned. 5738On GPU, if an out of bound index is found, a 0 is stored in the 5739corresponding output value. 5740 5741See also `tf.batch_gather` and `tf.gather_nd`. 5742 }]; 5743 5744 let arguments = (ins 5745 Arg<TF_Tensor, [{The tensor from which to gather values. Must be at least rank 5746`axis + 1`.}]>:$params, 5747 Arg<TensorOf<[TF_Int16, TF_Int32, TF_Int64]>, [{Index tensor. Must be in range `[0, params.shape[axis])`.}]>:$indices, 5748 Arg<TF_I32OrI64Tensor, [{The axis in `params` to gather `indices` from. Defaults to the first 5749dimension. Supports negative indexes.}]>:$axis, 5750 5751 DefaultValuedAttr<I64Attr, "0">:$batch_dims 5752 ); 5753 5754 let results = (outs 5755 Res<TF_Tensor, [{Values from `params` gathered from indices given by `indices`, with 5756shape `params.shape[:axis] + indices.shape + params.shape[axis + 1:]`.}]>:$output 5757 ); 5758 5759 TF_DerivedOperandTypeAttr Taxis = TF_DerivedOperandTypeAttr<2>; 5760 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 5761 TF_DerivedOperandTypeAttr Tparams = TF_DerivedOperandTypeAttr<0>; 5762 5763 let hasVerifier = 1; 5764} 5765 5766def TF_GeneratorDatasetOp : TF_Op<"GeneratorDataset", [AttrSizedOperandSegments, TF_GeneratorOpSideEffect]> { 5767 let summary = [{ 5768Creates a dataset that invokes a function to generate elements. 5769 }]; 5770 5771 let arguments = (ins 5772 Variadic<TF_Tensor>:$init_func_other_args, 5773 Variadic<TF_Tensor>:$next_func_other_args, 5774 Variadic<TF_Tensor>:$finalize_func_other_args, 5775 5776 SymbolRefAttr:$init_func, 5777 SymbolRefAttr:$next_func, 5778 SymbolRefAttr:$finalize_func, 5779 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 5780 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 5781 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 5782 ); 5783 5784 let results = (outs 5785 TF_VariantTensor:$handle 5786 ); 5787 5788 TF_DerivedOperandTypeListAttr Tfinalize_func_args = TF_DerivedOperandTypeListAttr<2>; 5789 TF_DerivedOperandTypeListAttr Tinit_func_args = TF_DerivedOperandTypeListAttr<0>; 5790 TF_DerivedOperandTypeListAttr Tnext_func_args = TF_DerivedOperandTypeListAttr<1>; 5791} 5792 5793def TF_GreaterOp : TF_Op<"Greater", [NoSideEffect, ResultsBroadcastableShape]>, 5794 WithBroadcastableCmpOpBuilder { 5795 let summary = "Returns the truth value of (x > y) element-wise."; 5796 5797 let description = [{ 5798*NOTE*: `Greater` supports broadcasting. More about broadcasting 5799[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 5800 5801Example: 5802 5803```python 5804x = tf.constant([5, 4, 6]) 5805y = tf.constant([5, 2, 5]) 5806tf.math.greater(x, y) ==> [False, True, True] 5807 5808x = tf.constant([5, 4, 6]) 5809y = tf.constant([5]) 5810tf.math.greater(x, y) ==> [False, False, True] 5811``` 5812 }]; 5813 5814 let arguments = (ins 5815 TF_IntOrFpTensor:$x, 5816 TF_IntOrFpTensor:$y 5817 ); 5818 5819 let results = (outs 5820 TF_BoolTensor:$z 5821 ); 5822 5823 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5824} 5825 5826def TF_GreaterEqualOp : TF_Op<"GreaterEqual", [NoSideEffect, ResultsBroadcastableShape]>, 5827 WithBroadcastableCmpOpBuilder { 5828 let summary = "Returns the truth value of (x >= y) element-wise."; 5829 5830 let description = [{ 5831*NOTE*: `GreaterEqual` supports broadcasting. More about broadcasting 5832[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 5833 5834Example: 5835 5836```python 5837x = tf.constant([5, 4, 6, 7]) 5838y = tf.constant([5, 2, 5, 10]) 5839tf.math.greater_equal(x, y) ==> [True, True, True, False] 5840 5841x = tf.constant([5, 4, 6, 7]) 5842y = tf.constant([5]) 5843tf.math.greater_equal(x, y) ==> [True, False, True, True] 5844``` 5845 }]; 5846 5847 let arguments = (ins 5848 TF_IntOrFpTensor:$x, 5849 TF_IntOrFpTensor:$y 5850 ); 5851 5852 let results = (outs 5853 TF_BoolTensor:$z 5854 ); 5855 5856 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5857} 5858 5859def TF_HSVToRGBOp : TF_Op<"HSVToRGB", [NoSideEffect]> { 5860 let summary = "Convert one or more images from HSV to RGB."; 5861 5862 let description = [{ 5863Outputs a tensor of the same shape as the `images` tensor, containing the RGB 5864value of the pixels. The output is only well defined if the value in `images` 5865are in `[0,1]`. 5866 5867See `rgb_to_hsv` for a description of the HSV encoding. 5868 }]; 5869 5870 let arguments = (ins 5871 Arg<TF_FloatTensor, [{1-D or higher rank. HSV data to convert. Last dimension must be size 3.}]>:$images 5872 ); 5873 5874 let results = (outs 5875 Res<TF_FloatTensor, [{`images` converted to RGB.}]>:$output 5876 ); 5877 5878 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 5879} 5880 5881def TF_HashTableOp : TF_Op<"HashTable", []> { 5882 let summary = "Creates a non-initialized hash table."; 5883 5884 let description = [{ 5885This op creates a hash table, specifying the type of its keys and values. 5886Before using the table you will have to initialize it. After initialization the 5887table will be immutable. 5888 }]; 5889 5890 let arguments = (ins 5891 DefaultValuedAttr<StrAttr, "\"\"">:$container, 5892 DefaultValuedAttr<StrAttr, "\"\"">:$shared_name, 5893 DefaultValuedAttr<BoolAttr, "false">:$use_node_name_sharing, 5894 TypeAttr:$key_dtype, 5895 TypeAttr:$value_dtype 5896 ); 5897 5898 let results = (outs 5899 Res<TF_StrTensor, [{Handle to a table.}], [TF_LookupTableAlloc]>:$table_handle 5900 ); 5901 5902 let hasCanonicalizer = 1; 5903} 5904 5905def TF_HashTableV2Op : TF_Op<"HashTableV2", []> { 5906 let summary = "Creates a non-initialized hash table."; 5907 5908 let description = [{ 5909This op creates a hash table, specifying the type of its keys and values. 5910Before using the table you will have to initialize it. After initialization the 5911table will be immutable. 5912 }]; 5913 5914 let arguments = (ins 5915 DefaultValuedAttr<StrAttr, "\"\"">:$container, 5916 DefaultValuedAttr<StrAttr, "\"\"">:$shared_name, 5917 DefaultValuedAttr<BoolAttr, "false">:$use_node_name_sharing, 5918 TypeAttr:$key_dtype, 5919 TypeAttr:$value_dtype 5920 ); 5921 5922 let results = (outs 5923 Res<TF_ResourceTensor, [{Handle to a table.}], [TF_LookupTableAlloc]>:$table_handle 5924 ); 5925 5926 let builders = [ 5927 OpBuilder<(ins "StringAttr":$container, "StringAttr":$shared_name, 5928 "BoolAttr":$use_node_name_sharing, "TypeAttr":$key_dtype, "TypeAttr":$value_dtype), 5929 [{ 5930 build($_builder, $_state, 5931 mlir::RankedTensorType::get({}, 5932 $_builder.getType<mlir::TF::ResourceType>()), 5933 container, shared_name, use_node_name_sharing, key_dtype, value_dtype); 5934 }]>]; 5935} 5936 5937def TF_IFFTOp : TF_Op<"IFFT", [NoSideEffect]> { 5938 let summary = "Inverse fast Fourier transform."; 5939 5940 let description = [{ 5941Computes the inverse 1-dimensional discrete Fourier transform over the 5942inner-most dimension of `input`. 5943 }]; 5944 5945 let arguments = (ins 5946 Arg<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor.}]>:$input 5947 ); 5948 5949 let results = (outs 5950 Res<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor of the same shape as `input`. The inner-most 5951 dimension of `input` is replaced with its inverse 1D Fourier transform. 5952 5953@compatibility(numpy) 5954Equivalent to np.fft.ifft 5955@end_compatibility}]>:$output 5956 ); 5957 5958 TF_DerivedOperandTypeAttr Tcomplex = TF_DerivedOperandTypeAttr<0>; 5959} 5960 5961def TF_IFFT2DOp : TF_Op<"IFFT2D", [NoSideEffect]> { 5962 let summary = "Inverse 2D fast Fourier transform."; 5963 5964 let description = [{ 5965Computes the inverse 2-dimensional discrete Fourier transform over the 5966inner-most 2 dimensions of `input`. 5967 }]; 5968 5969 let arguments = (ins 5970 Arg<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor.}]>:$input 5971 ); 5972 5973 let results = (outs 5974 Res<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor of the same shape as `input`. The inner-most 2 5975 dimensions of `input` are replaced with their inverse 2D Fourier transform. 5976 5977@compatibility(numpy) 5978Equivalent to np.fft.ifft2 5979@end_compatibility}]>:$output 5980 ); 5981 5982 TF_DerivedOperandTypeAttr Tcomplex = TF_DerivedOperandTypeAttr<0>; 5983} 5984 5985def TF_IFFT3DOp : TF_Op<"IFFT3D", [NoSideEffect]> { 5986 let summary = "Inverse 3D fast Fourier transform."; 5987 5988 let description = [{ 5989Computes the inverse 3-dimensional discrete Fourier transform over the 5990inner-most 3 dimensions of `input`. 5991 }]; 5992 5993 let arguments = (ins 5994 Arg<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor.}]>:$input 5995 ); 5996 5997 let results = (outs 5998 Res<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor of the same shape as `input`. The inner-most 3 5999 dimensions of `input` are replaced with their inverse 3D Fourier transform. 6000 6001@compatibility(numpy) 6002Equivalent to np.fft.ifftn with 3 dimensions. 6003@end_compatibility}]>:$output 6004 ); 6005 6006 TF_DerivedOperandTypeAttr Tcomplex = TF_DerivedOperandTypeAttr<0>; 6007} 6008 6009def TF_IRFFTOp : TF_Op<"IRFFT", [NoSideEffect]> { 6010 let summary = "Inverse real-valued fast Fourier transform."; 6011 6012 let description = [{ 6013Computes the inverse 1-dimensional discrete Fourier transform of a real-valued 6014signal over the inner-most dimension of `input`. 6015 6016The inner-most dimension of `input` is assumed to be the result of `RFFT`: the 6017`fft_length / 2 + 1` unique components of the DFT of a real-valued signal. If 6018`fft_length` is not provided, it is computed from the size of the inner-most 6019dimension of `input` (`fft_length = 2 * (inner - 1)`). If the FFT length used to 6020compute `input` is odd, it should be provided since it cannot be inferred 6021properly. 6022 6023Along the axis `IRFFT` is computed on, if `fft_length / 2 + 1` is smaller 6024than the corresponding dimension of `input`, the dimension is cropped. If it is 6025larger, the dimension is padded with zeros. 6026 }]; 6027 6028 let arguments = (ins 6029 Arg<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor.}]>:$input, 6030 Arg<TF_Int32Tensor, [{An int32 tensor of shape [1]. The FFT length.}]>:$fft_length 6031 ); 6032 6033 let results = (outs 6034 Res<TF_F32OrF64Tensor, [{A float32 tensor of the same rank as `input`. The inner-most 6035 dimension of `input` is replaced with the `fft_length` samples of its inverse 6036 1D Fourier transform. 6037 6038@compatibility(numpy) 6039Equivalent to np.fft.irfft 6040@end_compatibility}]>:$output 6041 ); 6042 6043 TF_DerivedOperandTypeAttr Tcomplex = TF_DerivedOperandTypeAttr<0>; 6044 TF_DerivedResultTypeAttr Treal = TF_DerivedResultTypeAttr<0>; 6045} 6046 6047def TF_IRFFT2DOp : TF_Op<"IRFFT2D", [NoSideEffect]> { 6048 let summary = "Inverse 2D real-valued fast Fourier transform."; 6049 6050 let description = [{ 6051Computes the inverse 2-dimensional discrete Fourier transform of a real-valued 6052signal over the inner-most 2 dimensions of `input`. 6053 6054The inner-most 2 dimensions of `input` are assumed to be the result of `RFFT2D`: 6055The inner-most dimension contains the `fft_length / 2 + 1` unique components of 6056the DFT of a real-valued signal. If `fft_length` is not provided, it is computed 6057from the size of the inner-most 2 dimensions of `input`. If the FFT length used 6058to compute `input` is odd, it should be provided since it cannot be inferred 6059properly. 6060 6061Along each axis `IRFFT2D` is computed on, if `fft_length` (or 6062`fft_length / 2 + 1` for the inner-most dimension) is smaller than the 6063corresponding dimension of `input`, the dimension is cropped. If it is larger, 6064the dimension is padded with zeros. 6065 }]; 6066 6067 let arguments = (ins 6068 Arg<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor.}]>:$input, 6069 Arg<TF_Int32Tensor, [{An int32 tensor of shape [2]. The FFT length for each dimension.}]>:$fft_length 6070 ); 6071 6072 let results = (outs 6073 Res<TF_F32OrF64Tensor, [{A float32 tensor of the same rank as `input`. The inner-most 2 6074 dimensions of `input` are replaced with the `fft_length` samples of their 6075 inverse 2D Fourier transform. 6076 6077@compatibility(numpy) 6078Equivalent to np.fft.irfft2 6079@end_compatibility}]>:$output 6080 ); 6081 6082 TF_DerivedOperandTypeAttr Tcomplex = TF_DerivedOperandTypeAttr<0>; 6083 TF_DerivedResultTypeAttr Treal = TF_DerivedResultTypeAttr<0>; 6084} 6085 6086def TF_IRFFT3DOp : TF_Op<"IRFFT3D", [NoSideEffect]> { 6087 let summary = "Inverse 3D real-valued fast Fourier transform."; 6088 6089 let description = [{ 6090Computes the inverse 3-dimensional discrete Fourier transform of a real-valued 6091signal over the inner-most 3 dimensions of `input`. 6092 6093The inner-most 3 dimensions of `input` are assumed to be the result of `RFFT3D`: 6094The inner-most dimension contains the `fft_length / 2 + 1` unique components of 6095the DFT of a real-valued signal. If `fft_length` is not provided, it is computed 6096from the size of the inner-most 3 dimensions of `input`. If the FFT length used 6097to compute `input` is odd, it should be provided since it cannot be inferred 6098properly. 6099 6100Along each axis `IRFFT3D` is computed on, if `fft_length` (or 6101`fft_length / 2 + 1` for the inner-most dimension) is smaller than the 6102corresponding dimension of `input`, the dimension is cropped. If it is larger, 6103the dimension is padded with zeros. 6104 }]; 6105 6106 let arguments = (ins 6107 Arg<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex tensor.}]>:$input, 6108 Arg<TF_Int32Tensor, [{An int32 tensor of shape [3]. The FFT length for each dimension.}]>:$fft_length 6109 ); 6110 6111 let results = (outs 6112 Res<TF_F32OrF64Tensor, [{A float32 tensor of the same rank as `input`. The inner-most 3 6113 dimensions of `input` are replaced with the `fft_length` samples of their 6114 inverse 3D real Fourier transform. 6115 6116@compatibility(numpy) 6117Equivalent to np.irfftn with 3 dimensions. 6118@end_compatibility}]>:$output 6119 ); 6120 6121 TF_DerivedOperandTypeAttr Tcomplex = TF_DerivedOperandTypeAttr<0>; 6122 TF_DerivedResultTypeAttr Treal = TF_DerivedResultTypeAttr<0>; 6123} 6124 6125def TF_IdentityOp : TF_Op<"Identity", [NoSideEffect, TF_NoConstantFold, TF_OperandsSameAsResultsTypeOrRef]> { 6126 let summary = [{ 6127Return a tensor with the same shape and contents as the input tensor or value. 6128 }]; 6129 6130 let arguments = (ins 6131 TF_Tensor:$input 6132 ); 6133 6134 let results = (outs 6135 TF_Tensor:$output 6136 ); 6137 6138 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6139} 6140 6141def TF_IdentityNOp : TF_Op<"IdentityN", [NoSideEffect]> { 6142 let summary = [{ 6143Returns a list of tensors with the same shapes and contents as the input 6144 }]; 6145 6146 let description = [{ 6147tensors. 6148 6149This op can be used to override the gradient for complicated functions. For 6150example, suppose y = f(x) and we wish to apply a custom function g for backprop 6151such that dx = g(dy). In Python, 6152 6153```python 6154with tf.get_default_graph().gradient_override_map( 6155 {'IdentityN': 'OverrideGradientWithG'}): 6156 y, _ = identity_n([f(x), x]) 6157 6158@tf.RegisterGradient('OverrideGradientWithG') 6159def ApplyG(op, dy, _): 6160 return [None, g(dy)] # Do not backprop to f(x). 6161``` 6162 }]; 6163 6164 let arguments = (ins 6165 Variadic<TF_Tensor>:$input 6166 ); 6167 6168 let results = (outs 6169 Variadic<TF_Tensor>:$output 6170 ); 6171 6172 TF_DerivedOperandTypeListAttr T = TF_DerivedOperandTypeListAttr<0>; 6173} 6174 6175def TF_IgammaOp : TF_Op<"Igamma", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 6176 WithBroadcastableBinOpBuilder { 6177 let summary = [{ 6178Compute the lower regularized incomplete Gamma function `P(a, x)`. 6179 }]; 6180 6181 let description = [{ 6182The lower regularized incomplete Gamma function is defined as: 6183 6184 6185\\(P(a, x) = gamma(a, x) / Gamma(a) = 1 - Q(a, x)\\) 6186 6187where 6188 6189\\(gamma(a, x) = \\int_{0}^{x} t^{a-1} exp(-t) dt\\) 6190 6191is the lower incomplete Gamma function. 6192 6193Note, above `Q(a, x)` (`Igammac`) is the upper regularized complete 6194Gamma function. 6195 }]; 6196 6197 let arguments = (ins 6198 TF_FloatTensor:$a, 6199 TF_FloatTensor:$x 6200 ); 6201 6202 let results = (outs 6203 TF_FloatTensor:$z 6204 ); 6205 6206 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6207} 6208 6209def TF_IgammaGradAOp : TF_Op<"IgammaGradA", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 6210 WithBroadcastableBinOpBuilder { 6211 let summary = "Computes the gradient of `igamma(a, x)` wrt `a`."; 6212 6213 let arguments = (ins 6214 TF_F32OrF64Tensor:$a, 6215 TF_F32OrF64Tensor:$x 6216 ); 6217 6218 let results = (outs 6219 TF_F32OrF64Tensor:$z 6220 ); 6221 6222 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6223} 6224 6225def TF_IgammacOp : TF_Op<"Igammac", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 6226 WithBroadcastableBinOpBuilder { 6227 let summary = [{ 6228Compute the upper regularized incomplete Gamma function `Q(a, x)`. 6229 }]; 6230 6231 let description = [{ 6232The upper regularized incomplete Gamma function is defined as: 6233 6234\\(Q(a, x) = Gamma(a, x) / Gamma(a) = 1 - P(a, x)\\) 6235 6236where 6237 6238\\(Gamma(a, x) = \int_{x}^{\infty} t^{a-1} exp(-t) dt\\) 6239 6240is the upper incomplete Gamma function. 6241 6242Note, above `P(a, x)` (`Igamma`) is the lower regularized complete 6243Gamma function. 6244 }]; 6245 6246 let arguments = (ins 6247 TF_FloatTensor:$a, 6248 TF_FloatTensor:$x 6249 ); 6250 6251 let results = (outs 6252 TF_FloatTensor:$z 6253 ); 6254 6255 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6256} 6257 6258def TF_ImagOp : TF_Op<"Imag", [NoSideEffect, SameOperandsAndResultShape]> { 6259 let summary = "Returns the imaginary part of a complex number."; 6260 6261 let description = [{ 6262Given a tensor `input` of complex numbers, this operation returns a tensor of 6263type `float` that is the imaginary part of each element in `input`. All 6264elements in `input` must be complex numbers of the form \\(a + bj\\), where *a* 6265is the real part and *b* is the imaginary part returned by this operation. 6266 6267For example: 6268 6269``` 6270# tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] 6271tf.imag(input) ==> [4.75, 5.75] 6272``` 6273 }]; 6274 6275 let arguments = (ins 6276 TensorOf<[TF_Complex128, TF_Complex64]>:$input 6277 ); 6278 6279 let results = (outs 6280 TF_F32OrF64Tensor:$output 6281 ); 6282 6283 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6284 TF_DerivedResultTypeAttr Tout = TF_DerivedResultTypeAttr<0>; 6285} 6286 6287def TF_InTopKV2Op : TF_Op<"InTopKV2", [NoSideEffect]> { 6288 let summary = "Says whether the targets are in the top `K` predictions."; 6289 6290 let description = [{ 6291This outputs a `batch_size` bool array, an entry `out[i]` is `true` if the 6292prediction for the target class is among the top `k` predictions among 6293all predictions for example `i`. Note that the behavior of `InTopK` differs 6294from the `TopK` op in its handling of ties; if multiple classes have the 6295same prediction value and straddle the top-`k` boundary, all of those 6296classes are considered to be in the top `k`. 6297 6298More formally, let 6299 6300 \\(predictions_i\\) be the predictions for all classes for example `i`, 6301 \\(targets_i\\) be the target class for example `i`, 6302 \\(out_i\\) be the output for example `i`, 6303 6304$$out_i = predictions_{i, targets_i} \in TopKIncludingTies(predictions_i)$$ 6305 }]; 6306 6307 let arguments = (ins 6308 Arg<TF_Float32Tensor, [{A `batch_size` x `classes` tensor.}]>:$predictions, 6309 Arg<TF_I32OrI64Tensor, [{A `batch_size` vector of class ids.}]>:$targets, 6310 Arg<TF_I32OrI64Tensor, [{Number of top elements to look at for computing precision.}]>:$k 6311 ); 6312 6313 let results = (outs 6314 Res<TF_BoolTensor, [{Computed precision at `k` as a `bool Tensor`.}]>:$precision 6315 ); 6316 6317 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 6318} 6319 6320def TF_InfeedDequeueOp : TF_Op<"InfeedDequeue", []> { 6321 let summary = [{ 6322A placeholder op for a value that will be fed into the computation. 6323 }]; 6324 6325 let arguments = (ins 6326 TF_ShapeAttr:$shape 6327 ); 6328 6329 let results = (outs 6330 Res<TF_Tensor, [{A tensor that will be provided using the infeed mechanism.}]>:$output 6331 ); 6332 6333 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 6334} 6335 6336def TF_InitializeTableOp : TF_Op<"InitializeTable", []> { 6337 let summary = [{ 6338Table initializer that takes two tensors for keys and values respectively. 6339 }]; 6340 6341 let arguments = (ins 6342 Arg<TF_StrTensor, [{Handle to a table which will be initialized.}], [TF_LookupTableWrite]>:$table_handle, 6343 Arg<TF_Tensor, [{Keys of type Tkey.}]>:$keys, 6344 Arg<TF_Tensor, [{Values of type Tval.}]>:$values 6345 ); 6346 6347 let results = (outs); 6348 6349 TF_DerivedOperandTypeAttr Tkey = TF_DerivedOperandTypeAttr<1>; 6350 TF_DerivedOperandTypeAttr Tval = TF_DerivedOperandTypeAttr<2>; 6351} 6352 6353def TF_InitializeTableFromDatasetOp : TF_Op<"InitializeTableFromDataset", []> { 6354 let summary = ""; 6355 6356 let arguments = (ins 6357 Arg<TF_ResourceTensor, "", [TF_LookupTableWrite]>:$table_handle, 6358 TF_VariantTensor:$dataset 6359 ); 6360 6361 let results = (outs); 6362} 6363 6364def TF_InitializeTableFromTextFileOp : TF_Op<"InitializeTableFromTextFile", []> { 6365 let summary = "Initializes a table from a text file."; 6366 6367 let description = [{ 6368It inserts one key-value pair into the table for each line of the file. 6369The key and value is extracted from the whole line content, elements from the 6370split line based on `delimiter` or the line number (starting from zero). 6371Where to extract the key and value from a line is specified by `key_index` and 6372`value_index`. 6373 6374- A value of -1 means use the line number(starting from zero), expects `int64`. 6375- A value of -2 means use the whole line content, expects `string`. 6376- A value >= 0 means use the index (starting at zero) of the split line based 6377 on `delimiter`. 6378 }]; 6379 6380 let arguments = (ins 6381 Arg<TF_StrTensor, [{Handle to a table which will be initialized.}], [TF_LookupTableWrite]>:$table_handle, 6382 Arg<TF_StrTensor, [{Filename of a vocabulary text file.}]>:$filename, 6383 6384 ConfinedAttr<I64Attr, [IntMinValue<-2>]>:$key_index, 6385 ConfinedAttr<I64Attr, [IntMinValue<-2>]>:$value_index, 6386 ConfinedAttr<DefaultValuedAttr<I64Attr, "-1">, [IntMinValue<-1>]>:$vocab_size, 6387 DefaultValuedAttr<StrAttr, "\"\\t\"">:$delimiter, 6388 DefaultValuedAttr<I64Attr, "0">:$offset 6389 ); 6390 6391 let results = (outs); 6392} 6393 6394def TF_InitializeTableFromTextFileV2Op : TF_Op<"InitializeTableFromTextFileV2", []> { 6395 let summary = "Initializes a table from a text file."; 6396 6397 let description = [{ 6398It inserts one key-value pair into the table for each line of the file. 6399The key and value is extracted from the whole line content, elements from the 6400split line based on `delimiter` or the line number (starting from zero). 6401Where to extract the key and value from a line is specified by `key_index` and 6402`value_index`. 6403 6404- A value of -1 means use the line number(starting from zero), expects `int64`. 6405- A value of -2 means use the whole line content, expects `string`. 6406- A value >= 0 means use the index (starting at zero) of the split line based 6407 on `delimiter`. 6408 }]; 6409 6410 let arguments = (ins 6411 Arg<TF_ResourceTensor, [{Handle to a table which will be initialized.}], [TF_LookupTableWrite]>:$table_handle, 6412 Arg<TF_StrTensor, [{Filename of a vocabulary text file.}]>:$filename, 6413 6414 ConfinedAttr<I64Attr, [IntMinValue<-2>]>:$key_index, 6415 ConfinedAttr<I64Attr, [IntMinValue<-2>]>:$value_index, 6416 ConfinedAttr<DefaultValuedAttr<I64Attr, "-1">, [IntMinValue<-1>]>:$vocab_size, 6417 DefaultValuedAttr<StrAttr, "\"\\t\"">:$delimiter, 6418 DefaultValuedAttr<I64Attr, "0">:$offset 6419 ); 6420 6421 let results = (outs); 6422} 6423 6424def TF_InitializeTableV2Op : TF_Op<"InitializeTableV2", []> { 6425 let summary = [{ 6426Table initializer that takes two tensors for keys and values respectively. 6427 }]; 6428 6429 let arguments = (ins 6430 Arg<TF_ResourceTensor, [{Handle to a table which will be initialized.}], [TF_LookupTableWrite]>:$table_handle, 6431 Arg<TF_Tensor, [{Keys of type Tkey.}]>:$keys, 6432 Arg<TF_Tensor, [{Values of type Tval.}]>:$values 6433 ); 6434 6435 let results = (outs); 6436 6437 TF_DerivedOperandTypeAttr Tkey = TF_DerivedOperandTypeAttr<1>; 6438 TF_DerivedOperandTypeAttr Tval = TF_DerivedOperandTypeAttr<2>; 6439} 6440 6441def TF_InplaceAddOp : TF_Op<"InplaceAdd", [NoSideEffect, TF_AllTypesMatch<["x", "y"]>]> { 6442 let summary = "Adds v into specified rows of x."; 6443 6444 let description = [{ 6445Computes y = x; y[i, :] += v; return y. 6446 }]; 6447 6448 let arguments = (ins 6449 Arg<TF_Tensor, [{A `Tensor` of type T.}]>:$x, 6450 Arg<TF_Int32Tensor, [{A vector. Indices into the left-most dimension of `x`.}]>:$i, 6451 Arg<TF_Tensor, [{A `Tensor` of type T. Same dimension sizes as x except the first dimension, which must be the same as i's size.}]>:$v 6452 ); 6453 6454 let results = (outs 6455 Res<TF_Tensor, [{A `Tensor` of type T. An alias of `x`. The content of `y` is undefined if there are duplicates in `i`.}]>:$y 6456 ); 6457 6458 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6459} 6460 6461def TF_InplaceUpdateOp : TF_Op<"InplaceUpdate", [NoSideEffect]> { 6462 let summary = "Updates specified rows 'i' with values 'v'."; 6463 6464 let description = [{ 6465Computes `x[i, :] = v; return x`. 6466 6467Originally this function is mutative however for compilation we make this 6468operation create / operate on a copy of `x`. 6469 }]; 6470 6471 let arguments = (ins 6472 Arg<TF_Tensor, [{A tensor of type `T`.}]>:$x, 6473 Arg<TF_Int32Tensor, [{A vector. Indices into the left-most dimension of `x`.}]>:$i, 6474 Arg<TF_Tensor, [{A `Tensor` of type T. Same dimension sizes as x except the first dimension, which must be the same as i's size.}]>:$v 6475 ); 6476 6477 let results = (outs 6478 Res<TF_Tensor, [{A `Tensor` of type T. An alias of `x`. The content of `y` is undefined if there are duplicates in `i`.}]>:$y 6479 ); 6480 6481 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6482} 6483 6484def TF_InvOp : TF_Op<"Inv", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 6485 let summary = "Computes the reciprocal of x element-wise."; 6486 6487 let description = [{ 6488I.e., \\(y = 1 / x\\). 6489 }]; 6490 6491 let arguments = (ins 6492 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x 6493 ); 6494 6495 let results = (outs 6496 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 6497 ); 6498 6499 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6500} 6501 6502def TF_InvertOp : TF_Op<"Invert", [Involution, NoSideEffect, SameOperandsAndResultType]> { 6503 let summary = [{ 6504Invert (flip) each bit of supported types; for example, type `uint8` value 01010101 becomes 10101010. 6505 }]; 6506 6507 let description = [{ 6508Flip each bit of supported types. For example, type `int8` (decimal 2) binary 00000010 becomes (decimal -3) binary 11111101. 6509This operation is performed on each element of the tensor argument `x`. 6510 6511Example: 6512```python 6513import tensorflow as tf 6514from tensorflow.python.ops import bitwise_ops 6515 6516# flip 2 (00000010) to -3 (11111101) 6517tf.assert_equal(-3, bitwise_ops.invert(2)) 6518 6519dtype_list = [dtypes.int8, dtypes.int16, dtypes.int32, dtypes.int64, 6520 dtypes.uint8, dtypes.uint16, dtypes.uint32, dtypes.uint64] 6521 6522inputs = [0, 5, 3, 14] 6523for dtype in dtype_list: 6524 # Because of issues with negative numbers, let's test this indirectly. 6525 # 1. invert(a) and a = 0 6526 # 2. invert(a) or a = invert(0) 6527 input_tensor = tf.constant([0, 5, 3, 14], dtype=dtype) 6528 not_a_and_a, not_a_or_a, not_0 = [bitwise_ops.bitwise_and( 6529 input_tensor, bitwise_ops.invert(input_tensor)), 6530 bitwise_ops.bitwise_or( 6531 input_tensor, bitwise_ops.invert(input_tensor)), 6532 bitwise_ops.invert( 6533 tf.constant(0, dtype=dtype))] 6534 6535 expected = tf.constant([0, 0, 0, 0], dtype=tf.float32) 6536 tf.assert_equal(tf.cast(not_a_and_a, tf.float32), expected) 6537 6538 expected = tf.cast([not_0] * 4, tf.float32) 6539 tf.assert_equal(tf.cast(not_a_or_a, tf.float32), expected) 6540 6541 # For unsigned dtypes let's also check the result directly. 6542 if dtype.is_unsigned: 6543 inverted = bitwise_ops.invert(input_tensor) 6544 expected = tf.constant([dtype.max - x for x in inputs], dtype=tf.float32) 6545 tf.assert_equal(tf.cast(inverted, tf.float32), tf.cast(expected, tf.float32)) 6546``` 6547 }]; 6548 6549 let arguments = (ins 6550 TF_IntTensor:$x 6551 ); 6552 6553 let results = (outs 6554 TF_IntTensor:$y 6555 ); 6556 6557 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6558} 6559 6560def TF_InvertPermutationOp : TF_Op<"InvertPermutation", [NoSideEffect]> { 6561 let summary = "Computes the inverse permutation of a tensor."; 6562 6563 let description = [{ 6564This operation computes the inverse of an index permutation. It takes a 1-D 6565integer tensor `x`, which represents the indices of a zero-based array, and 6566swaps each value with its index position. In other words, for an output tensor 6567`y` and an input tensor `x`, this operation computes the following: 6568 6569`y[x[i]] = i for i in [0, 1, ..., len(x) - 1]` 6570 6571The values must include 0. There can be no duplicate values or negative values. 6572 6573For example: 6574 6575``` 6576# tensor `x` is [3, 4, 0, 2, 1] 6577invert_permutation(x) ==> [2, 4, 3, 0, 1] 6578``` 6579 }]; 6580 6581 let arguments = (ins 6582 Arg<TF_I32OrI64Tensor, [{1-D.}]>:$x 6583 ); 6584 6585 let results = (outs 6586 Res<TF_I32OrI64Tensor, [{1-D.}]>:$y 6587 ); 6588 6589 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6590 6591 let hasVerifier = 1; 6592} 6593 6594def TF_IsFiniteOp : TF_Op<"IsFinite", [NoSideEffect, SameOperandsAndResultShape]> { 6595 let summary = "Returns which elements of x are finite."; 6596 6597 let description = [{ 6598@compatibility(numpy) 6599Equivalent to np.isfinite 6600@end_compatibility 6601 6602Example: 6603 6604```python 6605x = tf.constant([5.0, 4.8, 6.8, np.inf, np.nan]) 6606tf.math.is_finite(x) ==> [True, True, True, False, False] 6607``` 6608 }]; 6609 6610 let arguments = (ins 6611 TF_FloatTensor:$x 6612 ); 6613 6614 let results = (outs 6615 TF_BoolTensor:$y 6616 ); 6617 6618 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6619} 6620 6621def TF_IsInfOp : TF_Op<"IsInf", [NoSideEffect, SameOperandsAndResultShape]> { 6622 let summary = "Returns which elements of x are Inf."; 6623 6624 let description = [{ 6625@compatibility(numpy) 6626Equivalent to np.isinf 6627@end_compatibility 6628 6629Example: 6630 6631```python 6632x = tf.constant([5.0, np.inf, 6.8, np.inf]) 6633tf.math.is_inf(x) ==> [False, True, False, True] 6634``` 6635 }]; 6636 6637 let arguments = (ins 6638 TF_FloatTensor:$x 6639 ); 6640 6641 let results = (outs 6642 TF_BoolTensor:$y 6643 ); 6644 6645 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6646} 6647 6648def TF_IsNanOp : TF_Op<"IsNan", [NoSideEffect, SameOperandsAndResultShape]> { 6649 let summary = "Returns which elements of x are NaN."; 6650 6651 let description = [{ 6652@compatibility(numpy) 6653Equivalent to np.isnan 6654@end_compatibility 6655 6656Example: 6657 6658```python 6659x = tf.constant([5.0, np.nan, 6.8, np.nan, np.inf]) 6660tf.math.is_nan(x) ==> [False, True, False, True, False] 6661``` 6662 }]; 6663 6664 let arguments = (ins 6665 TF_FloatTensor:$x 6666 ); 6667 6668 let results = (outs 6669 TF_BoolTensor:$y 6670 ); 6671 6672 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6673} 6674 6675def TF_IteratorOp : TF_Op<"Iterator", []> { 6676 let summary = "A container for an iterator resource."; 6677 6678 let arguments = (ins 6679 StrAttr:$shared_name, 6680 StrAttr:$container, 6681 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 6682 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 6683 ); 6684 6685 let results = (outs 6686 Res<TF_ResourceTensor, [{A handle to the iterator that can be passed to a "MakeIterator" 6687or "IteratorGetNext" op.}], [TF_DatasetIteratorAlloc]>:$handle 6688 ); 6689} 6690 6691def TF_IteratorFromStringHandleOp : TF_Op<"IteratorFromStringHandle", []> { 6692 let summary = [{ 6693Converts the given string representing a handle to an iterator to a resource. 6694 }]; 6695 6696 let arguments = (ins 6697 Arg<TF_StrTensor, [{A string representation of the given handle.}]>:$string_handle, 6698 6699 DefaultValuedAttr<TypeArrayAttr, "{}">:$output_types, 6700 DefaultValuedAttr<TF_ShapeAttrArray, "{}">:$output_shapes 6701 ); 6702 6703 let results = (outs 6704 Res<TF_ResourceTensor, [{A handle to an iterator resource.}], [TF_DatasetIteratorAlloc]>:$resource_handle 6705 ); 6706} 6707 6708def TF_IteratorFromStringHandleV2Op : TF_Op<"IteratorFromStringHandleV2", []> { 6709 let summary = ""; 6710 6711 let arguments = (ins 6712 TF_StrTensor:$string_handle, 6713 6714 DefaultValuedAttr<TypeArrayAttr, "{}">:$output_types, 6715 DefaultValuedAttr<TF_ShapeAttrArray, "{}">:$output_shapes 6716 ); 6717 6718 let results = (outs 6719 Res<TF_ResourceTensor, "", [TF_DatasetIteratorAlloc]>:$resource_handle 6720 ); 6721} 6722 6723def TF_IteratorGetNextOp : TF_Op<"IteratorGetNext", []> { 6724 let summary = "Gets the next output from the given iterator ."; 6725 6726 let arguments = (ins 6727 Arg<TF_ResourceTensor, "", [TF_DatasetIteratorRead, TF_DatasetIteratorWrite]>:$iterator 6728 ); 6729 6730 let results = (outs 6731 Variadic<TF_Tensor>:$components 6732 ); 6733 6734 TF_DerivedResultShapeListAttr output_shapes = TF_DerivedResultShapeListAttr<0>; 6735 TF_DerivedResultTypeListAttr output_types = TF_DerivedResultTypeListAttr<0>; 6736} 6737 6738def TF_IteratorGetNextAsOptionalOp : TF_Op<"IteratorGetNextAsOptional", []> { 6739 let summary = [{ 6740Gets the next output from the given iterator as an Optional variant. 6741 }]; 6742 6743 let arguments = (ins 6744 Arg<TF_ResourceTensor, "", [TF_DatasetIteratorRead, TF_DatasetIteratorWrite]>:$iterator, 6745 6746 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 6747 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 6748 ); 6749 6750 let results = (outs 6751 TF_VariantTensor:$optional 6752 ); 6753} 6754 6755def TF_IteratorGetNextSyncOp : TF_Op<"IteratorGetNextSync", []> { 6756 let summary = "Gets the next output from the given iterator."; 6757 6758 let description = [{ 6759This operation is a synchronous version IteratorGetNext. It should only be used 6760in situations where the iterator does not block the calling thread, or where 6761the calling thread is not a member of the thread pool used to execute parallel 6762operations (e.g. in eager mode). 6763 }]; 6764 6765 let arguments = (ins 6766 Arg<TF_ResourceTensor, "", [TF_DatasetIteratorRead, TF_DatasetIteratorWrite]>:$iterator 6767 ); 6768 6769 let results = (outs 6770 Variadic<TF_Tensor>:$components 6771 ); 6772 6773 TF_DerivedResultShapeListAttr output_shapes = TF_DerivedResultShapeListAttr<0>; 6774 TF_DerivedResultTypeListAttr output_types = TF_DerivedResultTypeListAttr<0>; 6775} 6776 6777def TF_IteratorToStringHandleOp : TF_Op<"IteratorToStringHandle", []> { 6778 let summary = [{ 6779Converts the given `resource_handle` representing an iterator to a string. 6780 }]; 6781 6782 let arguments = (ins 6783 Arg<TF_ResourceTensor, [{A handle to an iterator resource.}], [TF_DatasetIteratorRead]>:$resource_handle 6784 ); 6785 6786 let results = (outs 6787 Res<TF_StrTensor, [{A string representation of the given handle.}]>:$string_handle 6788 ); 6789} 6790 6791def TF_IteratorV2Op : TF_Op<"IteratorV2", []> { 6792 let summary = ""; 6793 6794 let arguments = (ins 6795 StrAttr:$shared_name, 6796 StrAttr:$container, 6797 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 6798 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 6799 ); 6800 6801 let results = (outs 6802 Res<TF_ResourceTensor, "", [TF_DatasetIteratorAlloc]>:$handle 6803 ); 6804} 6805 6806def TF_KthOrderStatisticOp : TF_Op<"KthOrderStatistic", [NoSideEffect]> { 6807 let summary = "Computes the Kth order statistic of a data set. The current"; 6808 6809 let description = [{ 6810implementation uses a binary search requiring exactly 32 passes over 6811the input data. The running time is linear with respect to input 6812size. The median-of-medians algorithm is probably faster, but is 6813difficult to implement efficiently in XLA. The implementation imposes 6814a total ordering on floats. The ordering is consistent with the usual 6815partial order. Positive NaNs are greater than positive 6816infinity. Negative NaNs are less than negative infinity. NaNs with 6817distinct payloads are treated as distinct. Subnormal numbers are 6818preserved (not flushed to zero). Positive infinity is greater than all 6819numbers. Negative infinity is less than all numbers. Positive is 6820greater than negative zero. There are less than k values greater than 6821the kth order statistic. There are at least k values greater than or 6822equal to the Kth order statistic. The semantics are not the same as 6823top_k_unique. 6824 }]; 6825 6826 let arguments = (ins 6827 TF_Float32Tensor:$input, 6828 6829 I64Attr:$k 6830 ); 6831 6832 let results = (outs 6833 TF_Float32Tensor:$output 6834 ); 6835} 6836 6837def TF_L2LossOp : TF_Op<"L2Loss", [NoSideEffect]> { 6838 let summary = "L2 Loss."; 6839 6840 let description = [{ 6841Computes half the L2 norm of a tensor without the `sqrt`: 6842 6843 output = sum(t ** 2) / 2 6844 }]; 6845 6846 let arguments = (ins 6847 Arg<TF_FloatTensor, [{Typically 2-D, but may have any dimensions.}]>:$t 6848 ); 6849 6850 let results = (outs 6851 Res<TF_FloatTensor, [{0-D.}]>:$output 6852 ); 6853 6854 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6855} 6856 6857def TF_LRNOp : TF_Op<"LRN", [NoSideEffect]> { 6858 let summary = "Local Response Normalization."; 6859 6860 let description = [{ 6861The 4-D `input` tensor is treated as a 3-D array of 1-D vectors (along the last 6862dimension), and each vector is normalized independently. Within a given vector, 6863each component is divided by the weighted, squared sum of inputs within 6864`depth_radius`. In detail, 6865 6866 sqr_sum[a, b, c, d] = 6867 sum(input[a, b, c, d - depth_radius : d + depth_radius + 1] ** 2) 6868 output = input / (bias + alpha * sqr_sum) ** beta 6869 6870For details, see [Krizhevsky et al., ImageNet classification with deep 6871convolutional neural networks (NIPS 2012)](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks). 6872 }]; 6873 6874 let arguments = (ins 6875 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{4-D.}]>:$input, 6876 6877 DefaultValuedAttr<I64Attr, "5">:$depth_radius, 6878 DefaultValuedAttr<F32Attr, "1.0f">:$bias, 6879 DefaultValuedAttr<F32Attr, "1.0f">:$alpha, 6880 DefaultValuedAttr<F32Attr, "0.5f">:$beta 6881 ); 6882 6883 let results = (outs 6884 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>:$output 6885 ); 6886 6887 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6888} 6889 6890def TF_LRNGradOp : TF_Op<"LRNGrad", [NoSideEffect]> { 6891 let summary = "Gradients for Local Response Normalization."; 6892 6893 let arguments = (ins 6894 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{4-D with shape `[batch, height, width, channels]`.}]>:$input_grads, 6895 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{4-D with shape `[batch, height, width, channels]`.}]>:$input_image, 6896 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{4-D with shape `[batch, height, width, channels]`.}]>:$output_image, 6897 6898 DefaultValuedAttr<I64Attr, "5">:$depth_radius, 6899 DefaultValuedAttr<F32Attr, "1.0f">:$bias, 6900 DefaultValuedAttr<F32Attr, "1.0f">:$alpha, 6901 DefaultValuedAttr<F32Attr, "0.5f">:$beta 6902 ); 6903 6904 let results = (outs 6905 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{The gradients for LRN.}]>:$output 6906 ); 6907 6908 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6909} 6910 6911def TF_LeakyReluOp : TF_Op<"LeakyRelu", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 6912 let summary = "Computes rectified linear: `max(features, features * alpha)`."; 6913 6914 let arguments = (ins 6915 TF_FloatTensor:$features, 6916 6917 DefaultValuedAttr<F32Attr, "0.2f">:$alpha 6918 ); 6919 6920 let results = (outs 6921 TF_FloatTensor:$activations 6922 ); 6923 6924 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6925 6926 let hasFolder = 1; 6927} 6928 6929def TF_LeakyReluGradOp : TF_Op<"LeakyReluGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 6930 let summary = [{ 6931Computes rectified linear gradients for a LeakyRelu operation. 6932 }]; 6933 6934 let arguments = (ins 6935 Arg<TF_FloatTensor, [{The backpropagated gradients to the corresponding LeakyRelu operation.}]>:$gradients, 6936 Arg<TF_FloatTensor, [{The features passed as input to the corresponding LeakyRelu operation, 6937OR the outputs of that operation (both work equivalently).}]>:$features, 6938 6939 DefaultValuedAttr<F32Attr, "0.2f">:$alpha 6940 ); 6941 6942 let results = (outs 6943 Res<TF_FloatTensor, [{`gradients * (features > 0) + alpha * gradients * (features <= 0)`.}]>:$backprops 6944 ); 6945 6946 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6947} 6948 6949def TF_LeftShiftOp : TF_Op<"LeftShift", [NoSideEffect, ResultsBroadcastableShape]>, 6950 WithBroadcastableBinOpBuilder { 6951 let summary = "Elementwise computes the bitwise left-shift of `x` and `y`."; 6952 6953 let description = [{ 6954If `y` is negative, or greater than or equal to the width of `x` in bits the 6955result is implementation defined. 6956 6957Example: 6958 6959```python 6960import tensorflow as tf 6961from tensorflow.python.ops import bitwise_ops 6962import numpy as np 6963dtype_list = [tf.int8, tf.int16, tf.int32, tf.int64] 6964 6965for dtype in dtype_list: 6966 lhs = tf.constant([-1, -5, -3, -14], dtype=dtype) 6967 rhs = tf.constant([5, 0, 7, 11], dtype=dtype) 6968 6969 left_shift_result = bitwise_ops.left_shift(lhs, rhs) 6970 6971 print(left_shift_result) 6972 6973# This will print: 6974# tf.Tensor([ -32 -5 -128 0], shape=(4,), dtype=int8) 6975# tf.Tensor([ -32 -5 -384 -28672], shape=(4,), dtype=int16) 6976# tf.Tensor([ -32 -5 -384 -28672], shape=(4,), dtype=int32) 6977# tf.Tensor([ -32 -5 -384 -28672], shape=(4,), dtype=int64) 6978 6979lhs = np.array([-2, 64, 101, 32], dtype=np.int8) 6980rhs = np.array([-1, -5, -3, -14], dtype=np.int8) 6981bitwise_ops.left_shift(lhs, rhs) 6982# <tf.Tensor: shape=(4,), dtype=int8, numpy=array([ -2, 64, 101, 32], dtype=int8)> 6983``` 6984 }]; 6985 6986 let arguments = (ins 6987 TF_IntTensor:$x, 6988 TF_IntTensor:$y 6989 ); 6990 6991 let results = (outs 6992 TF_IntTensor:$z 6993 ); 6994 6995 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 6996} 6997 6998def TF_LessOp : TF_Op<"Less", [NoSideEffect, ResultsBroadcastableShape]>, 6999 WithBroadcastableCmpOpBuilder { 7000 let summary = "Returns the truth value of (x < y) element-wise."; 7001 7002 let description = [{ 7003*NOTE*: `Less` supports broadcasting. More about broadcasting 7004[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 7005 7006Example: 7007 7008```python 7009x = tf.constant([5, 4, 6]) 7010y = tf.constant([5]) 7011tf.math.less(x, y) ==> [False, True, False] 7012 7013x = tf.constant([5, 4, 6]) 7014y = tf.constant([5, 6, 7]) 7015tf.math.less(x, y) ==> [False, True, True] 7016``` 7017 }]; 7018 7019 let arguments = (ins 7020 TF_IntOrFpTensor:$x, 7021 TF_IntOrFpTensor:$y 7022 ); 7023 7024 let results = (outs 7025 TF_BoolTensor:$z 7026 ); 7027 7028 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 7029} 7030 7031def TF_LessEqualOp : TF_Op<"LessEqual", [NoSideEffect, ResultsBroadcastableShape]>, 7032 WithBroadcastableCmpOpBuilder { 7033 let summary = "Returns the truth value of (x <= y) element-wise."; 7034 7035 let description = [{ 7036*NOTE*: `LessEqual` supports broadcasting. More about broadcasting 7037[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 7038 7039Example: 7040 7041```python 7042x = tf.constant([5, 4, 6]) 7043y = tf.constant([5]) 7044tf.math.less_equal(x, y) ==> [True, True, False] 7045 7046x = tf.constant([5, 4, 6]) 7047y = tf.constant([5, 6, 6]) 7048tf.math.less_equal(x, y) ==> [True, True, True] 7049``` 7050 }]; 7051 7052 let arguments = (ins 7053 TF_IntOrFpTensor:$x, 7054 TF_IntOrFpTensor:$y 7055 ); 7056 7057 let results = (outs 7058 TF_BoolTensor:$z 7059 ); 7060 7061 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 7062} 7063 7064def TF_LgammaOp : TF_Op<"Lgamma", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 7065 let summary = [{ 7066Computes the log of the absolute value of `Gamma(x)` element-wise. 7067 }]; 7068 7069 let description = [{ 7070For positive numbers, this function computes log((input - 1)!) for every element in the tensor. 7071 `lgamma(5) = log((5-1)!) = log(4!) = log(24) = 3.1780539` 7072 7073Example: 7074 7075```python 7076x = tf.constant([0, 0.5, 1, 4.5, -4, -5.6]) 7077tf.math.lgamma(x) ==> [inf, 0.5723649, 0., 2.4537368, inf, -4.6477685] 7078``` 7079 }]; 7080 7081 let arguments = (ins 7082 TF_FloatTensor:$x 7083 ); 7084 7085 let results = (outs 7086 TF_FloatTensor:$y 7087 ); 7088 7089 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 7090} 7091 7092def TF_LinSpaceOp : TF_Op<"LinSpace", [NoSideEffect]> { 7093 let summary = "Generates values in an interval."; 7094 7095 let description = [{ 7096A sequence of `num` evenly-spaced values are generated beginning at `start`. 7097If `num > 1`, the values in the sequence increase by `stop - start / num - 1`, 7098so that the last one is exactly `stop`. 7099 7100For example: 7101 7102``` 7103tf.linspace(10.0, 12.0, 3, name="linspace") => [ 10.0 11.0 12.0] 7104``` 7105 }]; 7106 7107 let arguments = (ins 7108 Arg<TF_FloatTensor, [{0-D tensor. First entry in the range.}]>:$start, 7109 Arg<TF_FloatTensor, [{0-D tensor. Last entry in the range.}]>:$stop, 7110 Arg<TF_I32OrI64Tensor, [{0-D tensor. Number of values to generate.}]>:$num 7111 ); 7112 7113 let results = (outs 7114 Res<TF_FloatTensor, [{1-D. The generated values.}]>:$output 7115 ); 7116 7117 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 7118 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<2>; 7119} 7120 7121def TF_ListDiffOp : TF_Op<"ListDiff", [NoSideEffect]> { 7122 let summary = [{ 7123Computes the difference between two lists of numbers or strings. 7124 }]; 7125 7126 let description = [{ 7127Given a list `x` and a list `y`, this operation returns a list `out` that 7128represents all values that are in `x` but not in `y`. The returned list `out` 7129is sorted in the same order that the numbers appear in `x` (duplicates are 7130preserved). This operation also returns a list `idx` that represents the 7131position of each `out` element in `x`. In other words: 7132 7133`out[i] = x[idx[i]] for i in [0, 1, ..., len(out) - 1]` 7134 7135For example, given this input: 7136 7137``` 7138x = [1, 2, 3, 4, 5, 6] 7139y = [1, 3, 5] 7140``` 7141 7142This operation would return: 7143 7144``` 7145out ==> [2, 4, 6] 7146idx ==> [1, 3, 5] 7147``` 7148 }]; 7149 7150 let arguments = (ins 7151 Arg<TF_Tensor, [{1-D. Values to keep.}]>:$x, 7152 Arg<TF_Tensor, [{1-D. Values to remove.}]>:$y 7153 ); 7154 7155 let results = (outs 7156 Res<TF_Tensor, [{1-D. Values present in `x` but not in `y`.}]>:$out, 7157 Res<TF_I32OrI64Tensor, [{1-D. Positions of `x` values preserved in `out`.}]>:$idx 7158 ); 7159 7160 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 7161 TF_DerivedResultTypeAttr out_idx = TF_DerivedResultTypeAttr<1>; 7162} 7163 7164def TF_LoadTPUEmbeddingADAMParametersOp : TF_Op<"LoadTPUEmbeddingADAMParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7165 let summary = "Load ADAM embedding parameters."; 7166 7167 let description = [{ 7168An op that loads optimization parameters into HBM for embedding. Must be 7169preceded by a ConfigureTPUEmbeddingHost op that sets up the correct 7170embedding table configuration. For example, this op is used to install 7171parameters that are loaded from a checkpoint before a training loop is 7172executed. 7173 }]; 7174 7175 let arguments = (ins 7176 Arg<TF_Float32Tensor, [{Value of parameters used in the ADAM optimization algorithm.}]>:$parameters, 7177 Arg<TF_Float32Tensor, [{Value of momenta used in the ADAM optimization algorithm.}]>:$momenta, 7178 Arg<TF_Float32Tensor, [{Value of velocities used in the ADAM optimization algorithm.}]>:$velocities, 7179 7180 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7181 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7182 I64Attr:$num_shards, 7183 I64Attr:$shard_id, 7184 DefaultValuedAttr<StrAttr, "\"\"">:$config 7185 ); 7186 7187 let results = (outs); 7188} 7189 7190def TF_LoadTPUEmbeddingADAMParametersGradAccumDebugOp : TF_Op<"LoadTPUEmbeddingADAMParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7191 let summary = ""; 7192 7193 let arguments = (ins 7194 TF_Float32Tensor:$parameters, 7195 TF_Float32Tensor:$momenta, 7196 TF_Float32Tensor:$velocities, 7197 TF_Float32Tensor:$gradient_accumulators, 7198 7199 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7200 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7201 I64Attr:$num_shards, 7202 I64Attr:$shard_id, 7203 DefaultValuedAttr<StrAttr, "\"\"">:$config 7204 ); 7205 7206 let results = (outs); 7207} 7208 7209def TF_LoadTPUEmbeddingAdadeltaParametersOp : TF_Op<"LoadTPUEmbeddingAdadeltaParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7210 let summary = "Load Adadelta embedding parameters."; 7211 7212 let description = [{ 7213An op that loads optimization parameters into HBM for embedding. Must be 7214preceded by a ConfigureTPUEmbeddingHost op that sets up the correct 7215embedding table configuration. For example, this op is used to install 7216parameters that are loaded from a checkpoint before a training loop is 7217executed. 7218 }]; 7219 7220 let arguments = (ins 7221 Arg<TF_Float32Tensor, [{Value of parameters used in the Adadelta optimization algorithm.}]>:$parameters, 7222 Arg<TF_Float32Tensor, [{Value of accumulators used in the Adadelta optimization algorithm.}]>:$accumulators, 7223 Arg<TF_Float32Tensor, [{Value of updates used in the Adadelta optimization algorithm.}]>:$updates, 7224 7225 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7226 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7227 I64Attr:$num_shards, 7228 I64Attr:$shard_id, 7229 DefaultValuedAttr<StrAttr, "\"\"">:$config 7230 ); 7231 7232 let results = (outs); 7233} 7234 7235def TF_LoadTPUEmbeddingAdadeltaParametersGradAccumDebugOp : TF_Op<"LoadTPUEmbeddingAdadeltaParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7236 let summary = ""; 7237 7238 let arguments = (ins 7239 TF_Float32Tensor:$parameters, 7240 TF_Float32Tensor:$accumulators, 7241 TF_Float32Tensor:$updates, 7242 TF_Float32Tensor:$gradient_accumulators, 7243 7244 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7245 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7246 I64Attr:$num_shards, 7247 I64Attr:$shard_id, 7248 DefaultValuedAttr<StrAttr, "\"\"">:$config 7249 ); 7250 7251 let results = (outs); 7252} 7253 7254def TF_LoadTPUEmbeddingAdagradParametersOp : TF_Op<"LoadTPUEmbeddingAdagradParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7255 let summary = "Load Adagrad embedding parameters."; 7256 7257 let description = [{ 7258An op that loads optimization parameters into HBM for embedding. Must be 7259preceded by a ConfigureTPUEmbeddingHost op that sets up the correct 7260embedding table configuration. For example, this op is used to install 7261parameters that are loaded from a checkpoint before a training loop is 7262executed. 7263 }]; 7264 7265 let arguments = (ins 7266 Arg<TF_Float32Tensor, [{Value of parameters used in the Adagrad optimization algorithm.}]>:$parameters, 7267 Arg<TF_Float32Tensor, [{Value of accumulators used in the Adagrad optimization algorithm.}]>:$accumulators, 7268 7269 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7270 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7271 I64Attr:$num_shards, 7272 I64Attr:$shard_id, 7273 DefaultValuedAttr<StrAttr, "\"\"">:$config 7274 ); 7275 7276 let results = (outs); 7277} 7278 7279def TF_LoadTPUEmbeddingAdagradParametersGradAccumDebugOp : TF_Op<"LoadTPUEmbeddingAdagradParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7280 let summary = ""; 7281 7282 let arguments = (ins 7283 TF_Float32Tensor:$parameters, 7284 TF_Float32Tensor:$accumulators, 7285 TF_Float32Tensor:$gradient_accumulators, 7286 7287 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7288 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7289 I64Attr:$num_shards, 7290 I64Attr:$shard_id, 7291 DefaultValuedAttr<StrAttr, "\"\"">:$config 7292 ); 7293 7294 let results = (outs); 7295} 7296 7297def TF_LoadTPUEmbeddingCenteredRMSPropParametersOp : TF_Op<"LoadTPUEmbeddingCenteredRMSPropParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7298 let summary = "Load centered RMSProp embedding parameters."; 7299 7300 let description = [{ 7301An op that loads optimization parameters into HBM for embedding. Must be 7302preceded by a ConfigureTPUEmbeddingHost op that sets up the correct 7303embedding table configuration. For example, this op is used to install 7304parameters that are loaded from a checkpoint before a training loop is 7305executed. 7306 }]; 7307 7308 let arguments = (ins 7309 Arg<TF_Float32Tensor, [{Value of parameters used in the centered RMSProp optimization algorithm.}]>:$parameters, 7310 Arg<TF_Float32Tensor, [{Value of ms used in the centered RMSProp optimization algorithm.}]>:$ms, 7311 Arg<TF_Float32Tensor, [{Value of mom used in the centered RMSProp optimization algorithm.}]>:$mom, 7312 Arg<TF_Float32Tensor, [{Value of mg used in the centered RMSProp optimization algorithm.}]>:$mg, 7313 7314 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7315 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7316 I64Attr:$num_shards, 7317 I64Attr:$shard_id, 7318 DefaultValuedAttr<StrAttr, "\"\"">:$config 7319 ); 7320 7321 let results = (outs); 7322} 7323 7324def TF_LoadTPUEmbeddingFTRLParametersOp : TF_Op<"LoadTPUEmbeddingFTRLParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7325 let summary = "Load FTRL embedding parameters."; 7326 7327 let description = [{ 7328An op that loads optimization parameters into HBM for embedding. Must be 7329preceded by a ConfigureTPUEmbeddingHost op that sets up the correct 7330embedding table configuration. For example, this op is used to install 7331parameters that are loaded from a checkpoint before a training loop is 7332executed. 7333 }]; 7334 7335 let arguments = (ins 7336 Arg<TF_Float32Tensor, [{Value of parameters used in the FTRL optimization algorithm.}]>:$parameters, 7337 Arg<TF_Float32Tensor, [{Value of accumulators used in the FTRL optimization algorithm.}]>:$accumulators, 7338 Arg<TF_Float32Tensor, [{Value of linears used in the FTRL optimization algorithm.}]>:$linears, 7339 7340 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7341 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7342 I64Attr:$num_shards, 7343 I64Attr:$shard_id, 7344 DefaultValuedAttr<StrAttr, "\"\"">:$config 7345 ); 7346 7347 let results = (outs); 7348} 7349 7350def TF_LoadTPUEmbeddingFTRLParametersGradAccumDebugOp : TF_Op<"LoadTPUEmbeddingFTRLParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7351 let summary = ""; 7352 7353 let arguments = (ins 7354 TF_Float32Tensor:$parameters, 7355 TF_Float32Tensor:$accumulators, 7356 TF_Float32Tensor:$linears, 7357 TF_Float32Tensor:$gradient_accumulators, 7358 7359 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7360 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7361 I64Attr:$num_shards, 7362 I64Attr:$shard_id, 7363 DefaultValuedAttr<StrAttr, "\"\"">:$config 7364 ); 7365 7366 let results = (outs); 7367} 7368 7369def TF_LoadTPUEmbeddingMDLAdagradLightParametersOp : TF_Op<"LoadTPUEmbeddingMDLAdagradLightParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7370 let summary = "Load MDL Adagrad Light embedding parameters."; 7371 7372 let description = [{ 7373An op that loads optimization parameters into HBM for embedding. Must be 7374preceded by a ConfigureTPUEmbeddingHost op that sets up the correct 7375embedding table configuration. For example, this op is used to install 7376parameters that are loaded from a checkpoint before a training loop is 7377executed. 7378 }]; 7379 7380 let arguments = (ins 7381 Arg<TF_Float32Tensor, [{Value of parameters used in the MDL Adagrad Light optimization algorithm.}]>:$parameters, 7382 Arg<TF_Float32Tensor, [{Value of accumulators used in the MDL Adagrad Light optimization algorithm.}]>:$accumulators, 7383 Arg<TF_Float32Tensor, [{Value of weights used in the MDL Adagrad Light optimization algorithm.}]>:$weights, 7384 Arg<TF_Float32Tensor, [{Value of benefits used in the MDL Adagrad Light optimization algorithm.}]>:$benefits, 7385 7386 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7387 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7388 I64Attr:$num_shards, 7389 I64Attr:$shard_id, 7390 DefaultValuedAttr<StrAttr, "\"\"">:$config 7391 ); 7392 7393 let results = (outs); 7394} 7395 7396def TF_LoadTPUEmbeddingMomentumParametersOp : TF_Op<"LoadTPUEmbeddingMomentumParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7397 let summary = "Load Momentum embedding parameters."; 7398 7399 let description = [{ 7400An op that loads optimization parameters into HBM for embedding. Must be 7401preceded by a ConfigureTPUEmbeddingHost op that sets up the correct 7402embedding table configuration. For example, this op is used to install 7403parameters that are loaded from a checkpoint before a training loop is 7404executed. 7405 }]; 7406 7407 let arguments = (ins 7408 Arg<TF_Float32Tensor, [{Value of parameters used in the Momentum optimization algorithm.}]>:$parameters, 7409 Arg<TF_Float32Tensor, [{Value of momenta used in the Momentum optimization algorithm.}]>:$momenta, 7410 7411 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7412 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7413 I64Attr:$num_shards, 7414 I64Attr:$shard_id, 7415 DefaultValuedAttr<StrAttr, "\"\"">:$config 7416 ); 7417 7418 let results = (outs); 7419} 7420 7421def TF_LoadTPUEmbeddingMomentumParametersGradAccumDebugOp : TF_Op<"LoadTPUEmbeddingMomentumParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7422 let summary = ""; 7423 7424 let arguments = (ins 7425 TF_Float32Tensor:$parameters, 7426 TF_Float32Tensor:$momenta, 7427 TF_Float32Tensor:$gradient_accumulators, 7428 7429 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7430 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7431 I64Attr:$num_shards, 7432 I64Attr:$shard_id, 7433 DefaultValuedAttr<StrAttr, "\"\"">:$config 7434 ); 7435 7436 let results = (outs); 7437} 7438 7439def TF_LoadTPUEmbeddingProximalAdagradParametersOp : TF_Op<"LoadTPUEmbeddingProximalAdagradParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7440 let summary = "Load proximal Adagrad embedding parameters."; 7441 7442 let description = [{ 7443An op that loads optimization parameters into HBM for embedding. Must be 7444preceded by a ConfigureTPUEmbeddingHost op that sets up the correct 7445embedding table configuration. For example, this op is used to install 7446parameters that are loaded from a checkpoint before a training loop is 7447executed. 7448 }]; 7449 7450 let arguments = (ins 7451 Arg<TF_Float32Tensor, [{Value of parameters used in the proximal Adagrad optimization algorithm.}]>:$parameters, 7452 Arg<TF_Float32Tensor, [{Value of accumulators used in the proximal Adagrad optimization algorithm.}]>:$accumulators, 7453 7454 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7455 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7456 I64Attr:$num_shards, 7457 I64Attr:$shard_id, 7458 DefaultValuedAttr<StrAttr, "\"\"">:$config 7459 ); 7460 7461 let results = (outs); 7462} 7463 7464def TF_LoadTPUEmbeddingProximalAdagradParametersGradAccumDebugOp : TF_Op<"LoadTPUEmbeddingProximalAdagradParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7465 let summary = ""; 7466 7467 let arguments = (ins 7468 TF_Float32Tensor:$parameters, 7469 TF_Float32Tensor:$accumulators, 7470 TF_Float32Tensor:$gradient_accumulators, 7471 7472 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7473 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7474 I64Attr:$num_shards, 7475 I64Attr:$shard_id, 7476 DefaultValuedAttr<StrAttr, "\"\"">:$config 7477 ); 7478 7479 let results = (outs); 7480} 7481 7482def TF_LoadTPUEmbeddingProximalYogiParametersOp : TF_Op<"LoadTPUEmbeddingProximalYogiParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7483 let summary = ""; 7484 7485 let arguments = (ins 7486 TF_Float32Tensor:$parameters, 7487 TF_Float32Tensor:$v, 7488 TF_Float32Tensor:$m, 7489 7490 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7491 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7492 I64Attr:$num_shards, 7493 I64Attr:$shard_id, 7494 DefaultValuedAttr<StrAttr, "\"\"">:$config 7495 ); 7496 7497 let results = (outs); 7498} 7499 7500def TF_LoadTPUEmbeddingProximalYogiParametersGradAccumDebugOp : TF_Op<"LoadTPUEmbeddingProximalYogiParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7501 let summary = ""; 7502 7503 let arguments = (ins 7504 TF_Float32Tensor:$parameters, 7505 TF_Float32Tensor:$v, 7506 TF_Float32Tensor:$m, 7507 TF_Float32Tensor:$gradient_accumulators, 7508 7509 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7510 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7511 I64Attr:$num_shards, 7512 I64Attr:$shard_id, 7513 DefaultValuedAttr<StrAttr, "\"\"">:$config 7514 ); 7515 7516 let results = (outs); 7517} 7518 7519def TF_LoadTPUEmbeddingRMSPropParametersOp : TF_Op<"LoadTPUEmbeddingRMSPropParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7520 let summary = "Load RMSProp embedding parameters."; 7521 7522 let description = [{ 7523An op that loads optimization parameters into HBM for embedding. Must be 7524preceded by a ConfigureTPUEmbeddingHost op that sets up the correct 7525embedding table configuration. For example, this op is used to install 7526parameters that are loaded from a checkpoint before a training loop is 7527executed. 7528 }]; 7529 7530 let arguments = (ins 7531 Arg<TF_Float32Tensor, [{Value of parameters used in the RMSProp optimization algorithm.}]>:$parameters, 7532 Arg<TF_Float32Tensor, [{Value of ms used in the RMSProp optimization algorithm.}]>:$ms, 7533 Arg<TF_Float32Tensor, [{Value of mom used in the RMSProp optimization algorithm.}]>:$mom, 7534 7535 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7536 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7537 I64Attr:$num_shards, 7538 I64Attr:$shard_id, 7539 DefaultValuedAttr<StrAttr, "\"\"">:$config 7540 ); 7541 7542 let results = (outs); 7543} 7544 7545def TF_LoadTPUEmbeddingRMSPropParametersGradAccumDebugOp : TF_Op<"LoadTPUEmbeddingRMSPropParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7546 let summary = ""; 7547 7548 let arguments = (ins 7549 TF_Float32Tensor:$parameters, 7550 TF_Float32Tensor:$ms, 7551 TF_Float32Tensor:$mom, 7552 TF_Float32Tensor:$gradient_accumulators, 7553 7554 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7555 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7556 I64Attr:$num_shards, 7557 I64Attr:$shard_id, 7558 DefaultValuedAttr<StrAttr, "\"\"">:$config 7559 ); 7560 7561 let results = (outs); 7562} 7563 7564def TF_LoadTPUEmbeddingStochasticGradientDescentParametersOp : TF_Op<"LoadTPUEmbeddingStochasticGradientDescentParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7565 let summary = "Load SGD embedding parameters."; 7566 7567 let description = [{ 7568An op that loads optimization parameters into HBM for embedding. Must be 7569preceded by a ConfigureTPUEmbeddingHost op that sets up the correct 7570embedding table configuration. For example, this op is used to install 7571parameters that are loaded from a checkpoint before a training loop is 7572executed. 7573 }]; 7574 7575 let arguments = (ins 7576 Arg<TF_Float32Tensor, [{Value of parameters used in the stochastic gradient descent optimization algorithm.}]>:$parameters, 7577 7578 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7579 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7580 I64Attr:$num_shards, 7581 I64Attr:$shard_id, 7582 DefaultValuedAttr<StrAttr, "\"\"">:$config 7583 ); 7584 7585 let results = (outs); 7586} 7587 7588def TF_LoadTPUEmbeddingStochasticGradientDescentParametersGradAccumDebugOp : TF_Op<"LoadTPUEmbeddingStochasticGradientDescentParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 7589 let summary = ""; 7590 7591 let arguments = (ins 7592 TF_Float32Tensor:$parameters, 7593 TF_Float32Tensor:$gradient_accumulators, 7594 7595 DefaultValuedAttr<I64Attr, "-1">:$table_id, 7596 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 7597 I64Attr:$num_shards, 7598 I64Attr:$shard_id, 7599 DefaultValuedAttr<StrAttr, "\"\"">:$config 7600 ); 7601 7602 let results = (outs); 7603} 7604 7605def TF_LogOp : TF_Op<"Log", [NoSideEffect, SameOperandsAndResultType]> { 7606 let summary = "Computes natural logarithm of x element-wise."; 7607 7608 let description = [{ 7609I.e., \\(y = \log_e x\\). 7610 7611Example: 7612 7613```python 7614x = tf.constant([0, 0.5, 1, 5]) 7615tf.math.log(x) ==> [-inf, -0.6931472, 0. , 1.609438] 7616``` 7617 }]; 7618 7619 let arguments = (ins 7620 TF_FpOrComplexTensor:$x 7621 ); 7622 7623 let results = (outs 7624 TF_FpOrComplexTensor:$y 7625 ); 7626 7627 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 7628 7629 let hasCanonicalizer = 1; 7630 let extraClassDeclaration = [{ 7631 static bool isCompatibleReturnTypes(TypeRange inferred, TypeRange actual) { 7632 return ArraysAreCastCompatible(inferred, actual); 7633 } 7634 }]; 7635} 7636 7637def TF_Log1pOp : TF_Op<"Log1p", [NoSideEffect, SameOperandsAndResultType, TF_CwiseUnary]> { 7638 let summary = "Computes natural logarithm of (1 + x) element-wise."; 7639 7640 let description = [{ 7641I.e., \\(y = \log_e (1 + x)\\). 7642 7643Example: 7644 7645```python 7646x = tf.constant([0, 0.5, 1, 5]) 7647tf.math.log1p(x) ==> [0., 0.4054651, 0.6931472, 1.7917595] 7648``` 7649 }]; 7650 7651 let arguments = (ins 7652 TF_FpOrComplexTensor:$x 7653 ); 7654 7655 let results = (outs 7656 TF_FpOrComplexTensor:$y 7657 ); 7658 7659 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 7660} 7661 7662def TF_LogSoftmaxOp : TF_Op<"LogSoftmax", [NoSideEffect, SameOperandsAndResultType]> { 7663 let summary = "Computes log softmax activations."; 7664 7665 let description = [{ 7666For each batch `i` and class `j` we have 7667 7668 logsoftmax[i, j] = logits[i, j] - log(sum(exp(logits[i]))) 7669 }]; 7670 7671 let arguments = (ins 7672 Arg<TF_FloatTensor, [{2-D with shape `[batch_size, num_classes]`.}]>:$logits 7673 ); 7674 7675 let results = (outs 7676 Res<TF_FloatTensor, [{Same shape as `logits`.}]>:$logsoftmax 7677 ); 7678 7679 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 7680} 7681 7682def TF_LogicalAndOp : TF_Op<"LogicalAnd", [Commutative, NoSideEffect, ResultsBroadcastableShape]>, 7683 WithBroadcastableBinOpBuilder { 7684 let summary = "Returns the truth value of x AND y element-wise."; 7685 7686 let description = [{ 7687*NOTE*: `LogicalAnd` supports broadcasting. More about broadcasting 7688[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 7689 }]; 7690 7691 let arguments = (ins 7692 TF_BoolTensor:$x, 7693 TF_BoolTensor:$y 7694 ); 7695 7696 let results = (outs 7697 TF_BoolTensor:$z 7698 ); 7699} 7700 7701def TF_LogicalNotOp : TF_Op<"LogicalNot", [Involution, NoSideEffect, SameOperandsAndResultType]> { 7702 let summary = "Returns the truth value of `NOT x` element-wise."; 7703 7704 let arguments = (ins 7705 Arg<TF_BoolTensor, [{A `Tensor` of type `bool`.}]>:$x 7706 ); 7707 7708 let results = (outs 7709 Res<TF_BoolTensor, [{A `Tensor` of type `bool` with the same shape as `x`. The logical negation of `x`.}]>:$y 7710 ); 7711 7712 let hasCanonicalizer = 1; 7713 let extraClassDeclaration = [{ 7714 static bool isCompatibleReturnTypes(TypeRange inferred, TypeRange actual) { 7715 return ArraysAreCastCompatible(inferred, actual); 7716 } 7717 }]; 7718} 7719 7720def TF_LogicalOrOp : TF_Op<"LogicalOr", [Commutative, NoSideEffect, ResultsBroadcastableShape]>, 7721 WithBroadcastableBinOpBuilder { 7722 let summary = "Returns the truth value of x OR y element-wise."; 7723 7724 let description = [{ 7725*NOTE*: `LogicalOr` supports broadcasting. More about broadcasting 7726[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 7727 }]; 7728 7729 let arguments = (ins 7730 TF_BoolTensor:$x, 7731 TF_BoolTensor:$y 7732 ); 7733 7734 let results = (outs 7735 TF_BoolTensor:$z 7736 ); 7737} 7738 7739def TF_LookupTableExportV2Op : TF_Op<"LookupTableExportV2", []> { 7740 let summary = "Outputs all keys and values in the table."; 7741 7742 let arguments = (ins 7743 Arg<TF_ResourceTensor, [{Handle to the table.}], [TF_LookupTableRead]>:$table_handle 7744 ); 7745 7746 let results = (outs 7747 Res<TF_Tensor, [{Vector of all keys present in the table.}]>:$keys, 7748 Res<TF_Tensor, [{Tensor of all values in the table. Indexed in parallel with `keys`.}]>:$values 7749 ); 7750 7751 TF_DerivedResultTypeAttr Tkeys = TF_DerivedResultTypeAttr<0>; 7752 TF_DerivedResultTypeAttr Tvalues = TF_DerivedResultTypeAttr<1>; 7753} 7754 7755def TF_LookupTableFindOp : TF_Op<"LookupTableFind", []> { 7756 let summary = "Looks up keys in a table, outputs the corresponding values."; 7757 7758 let description = [{ 7759The tensor `keys` must of the same type as the keys of the table. 7760The output `values` is of the type of the table values. 7761 7762The scalar `default_value` is the value output for keys not present in the 7763table. It must also be of the same type as the table values. 7764 }]; 7765 7766 let arguments = (ins 7767 Arg<TF_StrTensor, [{Handle to the table.}], [TF_LookupTableRead]>:$table_handle, 7768 Arg<TF_Tensor, [{Any shape. Keys to look up.}]>:$keys, 7769 TF_Tensor:$default_value 7770 ); 7771 7772 let results = (outs 7773 Res<TF_Tensor, [{Same shape as `keys`. Values found in the table, or `default_values` 7774for missing keys.}]>:$values 7775 ); 7776 7777 TF_DerivedOperandTypeAttr Tin = TF_DerivedOperandTypeAttr<1>; 7778 TF_DerivedOperandTypeAttr Tout = TF_DerivedOperandTypeAttr<2>; 7779} 7780 7781def TF_LookupTableFindV2Op : TF_Op<"LookupTableFindV2", []> { 7782 let summary = "Looks up keys in a table, outputs the corresponding values."; 7783 7784 let description = [{ 7785The tensor `keys` must of the same type as the keys of the table. 7786The output `values` is of the type of the table values. 7787 7788The scalar `default_value` is the value output for keys not present in the 7789table. It must also be of the same type as the table values. 7790 }]; 7791 7792 let arguments = (ins 7793 Arg<TF_ResourceTensor, [{Handle to the table.}], [TF_LookupTableRead]>:$table_handle, 7794 Arg<TF_Tensor, [{Any shape. Keys to look up.}]>:$keys, 7795 TF_Tensor:$default_value 7796 ); 7797 7798 let results = (outs 7799 Res<TF_Tensor, [{Same shape as `keys`. Values found in the table, or `default_values` 7800for missing keys.}]>:$values 7801 ); 7802 7803 TF_DerivedOperandTypeAttr Tin = TF_DerivedOperandTypeAttr<1>; 7804 TF_DerivedOperandTypeAttr Tout = TF_DerivedOperandTypeAttr<2>; 7805} 7806 7807def TF_LookupTableImportV2Op : TF_Op<"LookupTableImportV2", []> { 7808 let summary = [{ 7809Replaces the contents of the table with the specified keys and values. 7810 }]; 7811 7812 let description = [{ 7813The tensor `keys` must be of the same type as the keys of the table. 7814The tensor `values` must be of the type of the table values. 7815 }]; 7816 7817 let arguments = (ins 7818 Arg<TF_ResourceTensor, [{Handle to the table.}], [TF_LookupTableWrite]>:$table_handle, 7819 Arg<TF_Tensor, [{Any shape. Keys to look up.}]>:$keys, 7820 Arg<TF_Tensor, [{Values to associate with keys.}]>:$values 7821 ); 7822 7823 let results = (outs); 7824 7825 TF_DerivedOperandTypeAttr Tin = TF_DerivedOperandTypeAttr<1>; 7826 TF_DerivedOperandTypeAttr Tout = TF_DerivedOperandTypeAttr<2>; 7827} 7828 7829def TF_LookupTableInsertV2Op : TF_Op<"LookupTableInsertV2", []> { 7830 let summary = "Updates the table to associates keys with values."; 7831 7832 let description = [{ 7833The tensor `keys` must be of the same type as the keys of the table. 7834The tensor `values` must be of the type of the table values. 7835 }]; 7836 7837 let arguments = (ins 7838 Arg<TF_ResourceTensor, [{Handle to the table.}], [TF_LookupTableWrite]>:$table_handle, 7839 Arg<TF_Tensor, [{Any shape. Keys to look up.}]>:$keys, 7840 Arg<TF_Tensor, [{Values to associate with keys.}]>:$values 7841 ); 7842 7843 let results = (outs); 7844 7845 TF_DerivedOperandTypeAttr Tin = TF_DerivedOperandTypeAttr<1>; 7846 TF_DerivedOperandTypeAttr Tout = TF_DerivedOperandTypeAttr<2>; 7847} 7848 7849def TF_LookupTableRemoveV2Op : TF_Op<"LookupTableRemoveV2", []> { 7850 let summary = "Removes keys and its associated values from a table."; 7851 7852 let description = [{ 7853The tensor `keys` must of the same type as the keys of the table. Keys not 7854already in the table are silently ignored. 7855 }]; 7856 7857 let arguments = (ins 7858 Arg<TF_ResourceTensor, [{Handle to the table.}], [TF_LookupTableWrite]>:$table_handle, 7859 Arg<TF_Tensor, [{Any shape. Keys of the elements to remove.}]>:$keys 7860 ); 7861 7862 let results = (outs); 7863 7864 TF_DerivedOperandTypeAttr Tin = TF_DerivedOperandTypeAttr<1>; 7865} 7866 7867def TF_LookupTableSizeOp : TF_Op<"LookupTableSize", []> { 7868 let summary = "Computes the number of elements in the given table."; 7869 7870 let arguments = (ins 7871 Arg<TF_StrTensor, [{Handle to the table.}], [TF_LookupTableRead]>:$table_handle 7872 ); 7873 7874 let results = (outs 7875 Res<TF_Int64Tensor, [{Scalar that contains number of elements in the table.}]>:$size 7876 ); 7877} 7878 7879def TF_LookupTableSizeV2Op : TF_Op<"LookupTableSizeV2", []> { 7880 let summary = "Computes the number of elements in the given table."; 7881 7882 let arguments = (ins 7883 Arg<TF_ResourceTensor, [{Handle to the table.}], [TF_LookupTableRead]>:$table_handle 7884 ); 7885 7886 let results = (outs 7887 Res<TF_Int64Tensor, [{Scalar that contains number of elements in the table.}]>:$size 7888 ); 7889} 7890 7891def TF_LowerBoundOp : TF_Op<"LowerBound", [NoSideEffect]> { 7892 let summary = [{ 7893Applies lower_bound(sorted_search_values, values) along each row. 7894 }]; 7895 7896 let description = [{ 7897Each set of rows with the same index in (sorted_inputs, values) is treated 7898independently. The resulting row is the equivalent of calling 7899`np.searchsorted(sorted_inputs, values, side='left')`. 7900 7901The result is not a global index to the entire 7902`Tensor`, but rather just the index in the last dimension. 7903 7904A 2-D example: 7905 sorted_sequence = [[0, 3, 9, 9, 10], 7906 [1, 2, 3, 4, 5]] 7907 values = [[2, 4, 9], 7908 [0, 2, 6]] 7909 7910 result = LowerBound(sorted_sequence, values) 7911 7912 result == [[1, 2, 2], 7913 [0, 1, 5]] 7914 }]; 7915 7916 let arguments = (ins 7917 Arg<TF_Tensor, [{2-D Tensor where each row is ordered.}]>:$sorted_inputs, 7918 Arg<TF_Tensor, [{2-D Tensor with the same numbers of rows as `sorted_search_values`. Contains 7919the values that will be searched for in `sorted_search_values`.}]>:$values 7920 ); 7921 7922 let results = (outs 7923 Res<TF_I32OrI64Tensor, [{A `Tensor` with the same shape as `values`. It contains the first scalar index 7924into the last dimension where values can be inserted without changing the 7925ordered property.}]>:$output 7926 ); 7927 7928 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 7929 TF_DerivedResultTypeAttr out_type = TF_DerivedResultTypeAttr<0>; 7930} 7931 7932def TF_MakeIteratorOp : TF_Op<"MakeIterator", []> { 7933 let summary = [{ 7934Makes a new iterator from the given `dataset` and stores it in `iterator`. 7935 }]; 7936 7937 let description = [{ 7938This operation may be executed multiple times. Each execution will reset the 7939iterator in `iterator` to the first element of `dataset`. 7940 }]; 7941 7942 let arguments = (ins 7943 TF_VariantTensor:$dataset, 7944 Arg<TF_ResourceTensor, "", [TF_DatasetIteratorWrite]>:$iterator 7945 ); 7946 7947 let results = (outs); 7948} 7949 7950def TF_MakeUniqueOp : TF_Op<"MakeUnique", [NoSideEffect]> { 7951 let summary = [{ 7952Make all elements in the non-Batch dimension unique, but \"close\" to 7953 }]; 7954 7955 let description = [{ 7956their initial value. Never returns a sub-normal number. Never returns 7957zero. The sign of each input element is always identical to the sign 7958of the corresponding output element. Behavior for infinite elements is 7959undefined. Behavior for subnormal elements is undefined. 7960 }]; 7961 7962 let arguments = (ins 7963 TF_Float32Tensor:$input 7964 ); 7965 7966 let results = (outs 7967 TF_Float32Tensor:$output 7968 ); 7969} 7970 7971def TF_MapAndBatchDatasetOp : TF_Op<"MapAndBatchDataset", [NoSideEffect]> { 7972 let summary = "Creates a dataset that fuses mapping with batching."; 7973 7974 let description = [{ 7975Creates a dataset that applies `f` to the outputs of `input_dataset` and then 7976batches `batch_size` of them. 7977 7978Unlike a "MapDataset", which applies `f` sequentially, this dataset invokes up 7979to `batch_size * num_parallel_batches` copies of `f` in parallel. 7980 }]; 7981 7982 let arguments = (ins 7983 Arg<TF_VariantTensor, [{A variant tensor representing the input dataset.}]>:$input_dataset, 7984 Arg<Variadic<TF_Tensor>, [{A list of tensors, typically values that were captured when building a closure 7985for `f`.}]>:$other_arguments, 7986 Arg<TF_Int64Tensor, [{A scalar representing the number of elements to accumulate in a 7987batch. It determines the number of concurrent invocations of `f` that process 7988elements from `input_dataset` in parallel.}]>:$batch_size, 7989 Arg<TF_Int64Tensor, [{A scalar representing the maximum number of parallel invocations of the `map_fn` 7990function. Applying the `map_fn` on consecutive input elements in parallel has 7991the potential to improve input pipeline throughput.}]>:$num_parallel_calls, 7992 Arg<TF_BoolTensor, [{A scalar representing whether the last batch should be dropped in case its size 7993is smaller than desired.}]>:$drop_remainder, 7994 7995 SymbolRefAttr:$f, 7996 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 7997 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 7998 DefaultValuedAttr<BoolAttr, "false">:$preserve_cardinality, 7999 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 8000 ); 8001 8002 let results = (outs 8003 TF_VariantTensor:$handle 8004 ); 8005 8006 TF_DerivedOperandTypeListAttr Targuments = TF_DerivedOperandTypeListAttr<1>; 8007} 8008 8009def TF_MapDatasetOp : TF_Op<"MapDataset", [NoSideEffect]> { 8010 let summary = [{ 8011Creates a dataset that applies `f` to the outputs of `input_dataset`. 8012 }]; 8013 8014 let arguments = (ins 8015 TF_VariantTensor:$input_dataset, 8016 Variadic<TF_Tensor>:$other_arguments, 8017 8018 SymbolRefAttr:$f, 8019 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 8020 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 8021 DefaultValuedAttr<BoolAttr, "true">:$use_inter_op_parallelism, 8022 DefaultValuedAttr<BoolAttr, "false">:$preserve_cardinality, 8023 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 8024 ); 8025 8026 let results = (outs 8027 TF_VariantTensor:$handle 8028 ); 8029 8030 TF_DerivedOperandTypeListAttr Targuments = TF_DerivedOperandTypeListAttr<1>; 8031} 8032 8033def TF_MatMulOp : TF_Op<"MatMul", [NoSideEffect, TF_SameOperandsAndResultElementTypeResolveRef]> { 8034 let summary = [{ 8035Multiply the matrix "a" by the matrix "b". 8036 }]; 8037 8038 let description = [{ 8039The inputs must be two-dimensional matrices and the inner dimension of 8040"a" (after being transposed if transpose_a is true) must match the 8041outer dimension of "b" (after being transposed if transposed_b is 8042true). 8043 8044*Note*: The default kernel implementation for MatMul on GPUs uses 8045cublas. 8046 }]; 8047 8048 let arguments = (ins 8049 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$a, 8050 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$b, 8051 8052 DefaultValuedAttr<BoolAttr, "false">:$transpose_a, 8053 DefaultValuedAttr<BoolAttr, "false">:$transpose_b 8054 ); 8055 8056 let results = (outs 8057 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$product 8058 ); 8059 8060 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8061} 8062 8063def TF_MatrixBandPartOp : TF_Op<"MatrixBandPart", [NoSideEffect, TF_AllTypesMatch<["input", "band"]>]> { 8064 let summary = [{ 8065Copy a tensor setting everything outside a central band in each innermost matrix to zero. 8066 }]; 8067 8068 let description = [{ 8069The `band` part is computed as follows: 8070Assume `input` has `k` dimensions `[I, J, K, ..., M, N]`, then the output is a 8071tensor with the same shape where 8072 8073`band[i, j, k, ..., m, n] = in_band(m, n) * input[i, j, k, ..., m, n]`. 8074 8075The indicator function 8076 8077`in_band(m, n) = (num_lower < 0 || (m-n) <= num_lower)) && 8078 (num_upper < 0 || (n-m) <= num_upper)`. 8079 8080For example: 8081 8082``` 8083# if 'input' is [[ 0, 1, 2, 3] 8084# [-1, 0, 1, 2] 8085# [-2, -1, 0, 1] 8086# [-3, -2, -1, 0]], 8087 8088tf.linalg.band_part(input, 1, -1) ==> [[ 0, 1, 2, 3] 8089 [-1, 0, 1, 2] 8090 [ 0, -1, 0, 1] 8091 [ 0, 0, -1, 0]], 8092 8093tf.linalg.band_part(input, 2, 1) ==> [[ 0, 1, 0, 0] 8094 [-1, 0, 1, 0] 8095 [-2, -1, 0, 1] 8096 [ 0, -2, -1, 0]] 8097``` 8098 8099Useful special cases: 8100 8101``` 8102 tf.linalg.band_part(input, 0, -1) ==> Upper triangular part. 8103 tf.linalg.band_part(input, -1, 0) ==> Lower triangular part. 8104 tf.linalg.band_part(input, 0, 0) ==> Diagonal. 8105``` 8106 }]; 8107 8108 let arguments = (ins 8109 Arg<TF_Tensor, [{Rank `k` tensor.}]>:$input, 8110 Arg<TF_I32OrI64Tensor, [{0-D tensor. Number of subdiagonals to keep. If negative, keep entire 8111lower triangle.}]>:$num_lower, 8112 Arg<TF_I32OrI64Tensor, [{0-D tensor. Number of superdiagonals to keep. If negative, keep 8113entire upper triangle.}]>:$num_upper 8114 ); 8115 8116 let results = (outs 8117 Res<TF_Tensor, [{Rank `k` tensor of the same shape as input. The extracted banded tensor.}]>:$band 8118 ); 8119 8120 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8121 TF_DerivedOperandTypeAttr Tindex = TF_DerivedOperandTypeAttr<1>; 8122 8123 let hasVerifier = 1; 8124} 8125 8126def TF_MatrixDiagOp : TF_Op<"MatrixDiag", [NoSideEffect]> { 8127 let summary = [{ 8128Returns a batched diagonal tensor with a given batched diagonal values. 8129 }]; 8130 8131 let description = [{ 8132Given a `diagonal`, this operation returns a tensor with the `diagonal` and 8133everything else padded with zeros. The diagonal is computed as follows: 8134 8135Assume `diagonal` has `k` dimensions `[I, J, K, ..., N]`, then the output is a 8136tensor of rank `k+1` with dimensions [I, J, K, ..., N, N]` where: 8137 8138`output[i, j, k, ..., m, n] = 1{m=n} * diagonal[i, j, k, ..., n]`. 8139 8140For example: 8141 8142``` 8143# 'diagonal' is [[1, 2, 3, 4], [5, 6, 7, 8]] 8144 8145and diagonal.shape = (2, 4) 8146 8147tf.matrix_diag(diagonal) ==> [[[1, 0, 0, 0] 8148 [0, 2, 0, 0] 8149 [0, 0, 3, 0] 8150 [0, 0, 0, 4]], 8151 [[5, 0, 0, 0] 8152 [0, 6, 0, 0] 8153 [0, 0, 7, 0] 8154 [0, 0, 0, 8]]] 8155 8156which has shape (2, 4, 4) 8157``` 8158 }]; 8159 8160 let arguments = (ins 8161 Arg<TF_Tensor, [{Rank `k`, where `k >= 1`.}]>:$diagonal 8162 ); 8163 8164 let results = (outs 8165 Res<TF_Tensor, [{Rank `k+1`, with `output.shape = diagonal.shape + [diagonal.shape[-1]]`.}]>:$output 8166 ); 8167 8168 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8169 8170 let hasCanonicalizer = 1; 8171} 8172 8173def TF_MatrixDiagPartV3Op : TF_Op<"MatrixDiagPartV3", [NoSideEffect]> { 8174 let summary = "Returns the batched diagonal part of a batched tensor."; 8175 8176 let description = [{ 8177Returns a tensor with the `k[0]`-th to `k[1]`-th diagonals of the batched 8178`input`. 8179 8180Assume `input` has `r` dimensions `[I, J, ..., L, M, N]`. 8181Let `max_diag_len` be the maximum length among all diagonals to be extracted, 8182`max_diag_len = min(M + min(k[1], 0), N + min(-k[0], 0))` 8183Let `num_diags` be the number of diagonals to extract, 8184`num_diags = k[1] - k[0] + 1`. 8185 8186If `num_diags == 1`, the output tensor is of rank `r - 1` with shape 8187`[I, J, ..., L, max_diag_len]` and values: 8188 8189``` 8190diagonal[i, j, ..., l, n] 8191 = input[i, j, ..., l, n+y, n+x] ; if 0 <= n+y < M and 0 <= n+x < N, 8192 padding_value ; otherwise. 8193``` 8194where `y = max(-k[1], 0)`, `x = max(k[1], 0)`. 8195 8196Otherwise, the output tensor has rank `r` with dimensions 8197`[I, J, ..., L, num_diags, max_diag_len]` with values: 8198 8199``` 8200diagonal[i, j, ..., l, m, n] 8201 = input[i, j, ..., l, n+y, n+x] ; if 0 <= n+y < M and 0 <= n+x < N, 8202 padding_value ; otherwise. 8203``` 8204where `d = k[1] - m`, `y = max(-d, 0) - offset`, and `x = max(d, 0) - offset`. 8205 8206`offset` is zero except when the alignment of the diagonal is to the right. 8207``` 8208offset = max_diag_len - diag_len(d) ; if (`align` in {RIGHT_LEFT, RIGHT_RIGHT} 8209 and `d >= 0`) or 8210 (`align` in {LEFT_RIGHT, RIGHT_RIGHT} 8211 and `d <= 0`) 8212 0 ; otherwise 8213``` 8214where `diag_len(d) = min(cols - max(d, 0), rows + min(d, 0))`. 8215 8216The input must be at least a matrix. 8217 8218For example: 8219 8220``` 8221input = np.array([[[1, 2, 3, 4], # Input shape: (2, 3, 4) 8222 [5, 6, 7, 8], 8223 [9, 8, 7, 6]], 8224 [[5, 4, 3, 2], 8225 [1, 2, 3, 4], 8226 [5, 6, 7, 8]]]) 8227 8228# A main diagonal from each batch. 8229tf.matrix_diag_part(input) ==> [[1, 6, 7], # Output shape: (2, 3) 8230 [5, 2, 7]] 8231 8232# A superdiagonal from each batch. 8233tf.matrix_diag_part(input, k = 1) 8234 ==> [[2, 7, 6], # Output shape: (2, 3) 8235 [4, 3, 8]] 8236 8237# A band from each batch. 8238tf.matrix_diag_part(input, k = (-1, 2)) 8239 ==> [[[0, 3, 8], # Output shape: (2, 4, 3) 8240 [2, 7, 6], 8241 [1, 6, 7], 8242 [5, 8, 0]], 8243 [[0, 3, 4], 8244 [4, 3, 8], 8245 [5, 2, 7], 8246 [1, 6, 0]]] 8247 8248# LEFT_RIGHT alignment. 8249tf.matrix_diag_part(input, k = (-1, 2), align="LEFT_RIGHT") 8250 ==> [[[3, 8, 0], # Output shape: (2, 4, 3) 8251 [2, 7, 6], 8252 [1, 6, 7], 8253 [0, 5, 8]], 8254 [[3, 4, 0], 8255 [4, 3, 8], 8256 [5, 2, 7], 8257 [0, 1, 6]]] 8258 8259# max_diag_len can be shorter than the main diagonal. 8260tf.matrix_diag_part(input, k = (-2, -1)) 8261 ==> [[[5, 8], 8262 [9, 0]], 8263 [[1, 6], 8264 [5, 0]]] 8265 8266# padding_value = 9 8267tf.matrix_diag_part(input, k = (1, 3), padding_value = 9) 8268 ==> [[[9, 9, 4], # Output shape: (2, 3, 3) 8269 [9, 3, 8], 8270 [2, 7, 6]], 8271 [[9, 9, 2], 8272 [9, 3, 4], 8273 [4, 3, 8]]] 8274 8275``` 8276 }]; 8277 8278 let arguments = (ins 8279 Arg<TF_Tensor, [{Rank `r` tensor where `r >= 2`.}]>:$input, 8280 Arg<TF_Int32Tensor, [{Diagonal offset(s). Positive value means superdiagonal, 0 refers to the main 8281diagonal, and negative value means subdiagonals. `k` can be a single integer 8282(for a single diagonal) or a pair of integers specifying the low and high ends 8283of a matrix band. `k[0]` must not be larger than `k[1]`.}]>:$k, 8284 Arg<TF_Tensor, [{The value to fill the area outside the specified diagonal band with. 8285Default is 0.}]>:$padding_value, 8286 8287 DefaultValuedAttr<TF_AnyStrAttrOf<["LEFT_RIGHT", "RIGHT_LEFT", "LEFT_LEFT", "RIGHT_RIGHT"]>, "\"RIGHT_LEFT\"">:$align 8288 ); 8289 8290 let results = (outs 8291 Res<TF_Tensor, [{The extracted diagonal(s).}]>:$diagonal 8292 ); 8293 8294 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8295} 8296 8297def TF_MatrixDiagV2Op : TF_Op<"MatrixDiagV2", [NoSideEffect]> { 8298 let summary = [{ 8299Returns a batched diagonal tensor with given batched diagonal values. 8300 }]; 8301 8302 let description = [{ 8303Returns a tensor with the contents in `diagonal` as `k[0]`-th to `k[1]`-th 8304diagonals of a matrix, with everything else padded with `padding`. `num_rows` 8305and `num_cols` specify the dimension of the innermost matrix of the output. If 8306both are not specified, the op assumes the innermost matrix is square and infers 8307its size from `k` and the innermost dimension of `diagonal`. If only one of them 8308is specified, the op assumes the unspecified value is the smallest possible 8309based on other criteria. 8310 8311Let `diagonal` have `r` dimensions `[I, J, ..., L, M, N]`. The output tensor has 8312rank `r+1` with shape `[I, J, ..., L, M, num_rows, num_cols]` when only one 8313diagonal is given (`k` is an integer or `k[0] == k[1]`). Otherwise, it has rank 8314`r` with shape `[I, J, ..., L, num_rows, num_cols]`. 8315 8316The second innermost dimension of `diagonal` has double meaning. 8317When `k` is scalar or `k[0] == k[1]`, `M` is part of the batch size 8318[I, J, ..., M], and the output tensor is: 8319 8320``` 8321output[i, j, ..., l, m, n] 8322 = diagonal[i, j, ..., l, n-max(d_upper, 0)] ; if n - m == d_upper 8323 padding_value ; otherwise 8324``` 8325 8326Otherwise, `M` is treated as the number of diagonals for the matrix in the 8327same batch (`M = k[1]-k[0]+1`), and the output tensor is: 8328 8329``` 8330output[i, j, ..., l, m, n] 8331 = diagonal[i, j, ..., l, diag_index, index_in_diag] ; if k[0] <= d <= k[1] 8332 padding_value ; otherwise 8333``` 8334where `d = n - m`, `diag_index = k[1] - d`, and `index_in_diag = n - max(d, 0)`. 8335 8336For example: 8337 8338``` 8339# The main diagonal. 8340diagonal = np.array([[1, 2, 3, 4], # Input shape: (2, 4) 8341 [5, 6, 7, 8]]) 8342tf.matrix_diag(diagonal) ==> [[[1, 0, 0, 0], # Output shape: (2, 4, 4) 8343 [0, 2, 0, 0], 8344 [0, 0, 3, 0], 8345 [0, 0, 0, 4]], 8346 [[5, 0, 0, 0], 8347 [0, 6, 0, 0], 8348 [0, 0, 7, 0], 8349 [0, 0, 0, 8]]] 8350 8351# A superdiagonal (per batch). 8352diagonal = np.array([[1, 2, 3], # Input shape: (2, 3) 8353 [4, 5, 6]]) 8354tf.matrix_diag(diagonal, k = 1) 8355 ==> [[[0, 1, 0, 0], # Output shape: (2, 4, 4) 8356 [0, 0, 2, 0], 8357 [0, 0, 0, 3], 8358 [0, 0, 0, 0]], 8359 [[0, 4, 0, 0], 8360 [0, 0, 5, 0], 8361 [0, 0, 0, 6], 8362 [0, 0, 0, 0]]] 8363 8364# A band of diagonals. 8365diagonals = np.array([[[1, 2, 3], # Input shape: (2, 2, 3) 8366 [4, 5, 0]], 8367 [[6, 7, 9], 8368 [9, 1, 0]]]) 8369tf.matrix_diag(diagonals, k = (-1, 0)) 8370 ==> [[[1, 0, 0], # Output shape: (2, 3, 3) 8371 [4, 2, 0], 8372 [0, 5, 3]], 8373 [[6, 0, 0], 8374 [9, 7, 0], 8375 [0, 1, 9]]] 8376 8377# Rectangular matrix. 8378diagonal = np.array([1, 2]) # Input shape: (2) 8379tf.matrix_diag(diagonal, k = -1, num_rows = 3, num_cols = 4) 8380 ==> [[0, 0, 0, 0], # Output shape: (3, 4) 8381 [1, 0, 0, 0], 8382 [0, 2, 0, 0]] 8383 8384# Rectangular matrix with inferred num_cols and padding_value = 9. 8385tf.matrix_diag(diagonal, k = -1, num_rows = 3, padding_value = 9) 8386 ==> [[9, 9], # Output shape: (3, 2) 8387 [1, 9], 8388 [9, 2]] 8389``` 8390 }]; 8391 8392 let arguments = (ins 8393 Arg<TF_Tensor, [{Rank `r`, where `r >= 1`}]>:$diagonal, 8394 Arg<TF_Int32Tensor, [{Diagonal offset(s). Positive value means superdiagonal, 0 refers to the main 8395diagonal, and negative value means subdiagonals. `k` can be a single integer 8396(for a single diagonal) or a pair of integers specifying the low and high ends 8397of a matrix band. `k[0]` must not be larger than `k[1]`.}]>:$k, 8398 Arg<TF_Int32Tensor, [{The number of rows of the output matrix. If it is not provided, the op assumes 8399the output matrix is a square matrix and infers the matrix size from k and the 8400innermost dimension of `diagonal`.}]>:$num_rows, 8401 Arg<TF_Int32Tensor, [{The number of columns of the output matrix. If it is not provided, the op 8402assumes the output matrix is a square matrix and infers the matrix size from 8403k and the innermost dimension of `diagonal`.}]>:$num_cols, 8404 Arg<TF_Tensor, [{The number to fill the area outside the specified diagonal band with. 8405Default is 0.}]>:$padding_value 8406 ); 8407 8408 let results = (outs 8409 Res<TF_Tensor, [{Has rank `r+1` when `k` is an integer or `k[0] == k[1]`, rank `r` otherwise.}]>:$output 8410 ); 8411 8412 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8413} 8414 8415def TF_MatrixDiagV3Op : TF_Op<"MatrixDiagV3", [NoSideEffect]> { 8416 let summary = [{ 8417Returns a batched diagonal tensor with given batched diagonal values. 8418 }]; 8419 8420 let description = [{ 8421Returns a tensor with the contents in `diagonal` as `k[0]`-th to `k[1]`-th 8422diagonals of a matrix, with everything else padded with `padding`. `num_rows` 8423and `num_cols` specify the dimension of the innermost matrix of the output. If 8424both are not specified, the op assumes the innermost matrix is square and infers 8425its size from `k` and the innermost dimension of `diagonal`. If only one of them 8426is specified, the op assumes the unspecified value is the smallest possible 8427based on other criteria. 8428 8429Let `diagonal` have `r` dimensions `[I, J, ..., L, M, N]`. The output tensor has 8430rank `r+1` with shape `[I, J, ..., L, M, num_rows, num_cols]` when only one 8431diagonal is given (`k` is an integer or `k[0] == k[1]`). Otherwise, it has rank 8432`r` with shape `[I, J, ..., L, num_rows, num_cols]`. 8433 8434The second innermost dimension of `diagonal` has double meaning. 8435When `k` is scalar or `k[0] == k[1]`, `M` is part of the batch size 8436[I, J, ..., M], and the output tensor is: 8437 8438``` 8439output[i, j, ..., l, m, n] 8440 = diagonal[i, j, ..., l, n-max(d_upper, 0)] ; if n - m == d_upper 8441 padding_value ; otherwise 8442``` 8443 8444Otherwise, `M` is treated as the number of diagonals for the matrix in the 8445same batch (`M = k[1]-k[0]+1`), and the output tensor is: 8446 8447``` 8448output[i, j, ..., l, m, n] 8449 = diagonal[i, j, ..., l, diag_index, index_in_diag] ; if k[0] <= d <= k[1] 8450 padding_value ; otherwise 8451``` 8452where `d = n - m`, `diag_index = [k] - d`, and 8453`index_in_diag = n - max(d, 0) + offset`. 8454 8455`offset` is zero except when the alignment of the diagonal is to the right. 8456``` 8457offset = max_diag_len - diag_len(d) ; if (`align` in {RIGHT_LEFT, RIGHT_RIGHT} 8458 and `d >= 0`) or 8459 (`align` in {LEFT_RIGHT, RIGHT_RIGHT} 8460 and `d <= 0`) 8461 0 ; otherwise 8462``` 8463where `diag_len(d) = min(cols - max(d, 0), rows + min(d, 0))`. 8464 8465For example: 8466 8467``` 8468# The main diagonal. 8469diagonal = np.array([[1, 2, 3, 4], # Input shape: (2, 4) 8470 [5, 6, 7, 8]]) 8471tf.matrix_diag(diagonal) ==> [[[1, 0, 0, 0], # Output shape: (2, 4, 4) 8472 [0, 2, 0, 0], 8473 [0, 0, 3, 0], 8474 [0, 0, 0, 4]], 8475 [[5, 0, 0, 0], 8476 [0, 6, 0, 0], 8477 [0, 0, 7, 0], 8478 [0, 0, 0, 8]]] 8479 8480# A superdiagonal (per batch). 8481diagonal = np.array([[1, 2, 3], # Input shape: (2, 3) 8482 [4, 5, 6]]) 8483tf.matrix_diag(diagonal, k = 1) 8484 ==> [[[0, 1, 0, 0], # Output shape: (2, 4, 4) 8485 [0, 0, 2, 0], 8486 [0, 0, 0, 3], 8487 [0, 0, 0, 0]], 8488 [[0, 4, 0, 0], 8489 [0, 0, 5, 0], 8490 [0, 0, 0, 6], 8491 [0, 0, 0, 0]]] 8492 8493# A tridiagonal band (per batch). 8494diagonals = np.array([[[0, 8, 9], # Input shape: (2, 2, 3) 8495 [1, 2, 3], 8496 [4, 5, 0]], 8497 [[0, 2, 3], 8498 [6, 7, 9], 8499 [9, 1, 0]]]) 8500tf.matrix_diag(diagonals, k = (-1, 1)) 8501 ==> [[[1, 8, 0], # Output shape: (2, 3, 3) 8502 [4, 2, 9], 8503 [0, 5, 3]], 8504 [[6, 2, 0], 8505 [9, 7, 3], 8506 [0, 1, 9]]] 8507 8508# LEFT_RIGHT alignment. 8509diagonals = np.array([[[8, 9, 0], # Input shape: (2, 2, 3) 8510 [1, 2, 3], 8511 [0, 4, 5]], 8512 [[2, 3, 0], 8513 [6, 7, 9], 8514 [0, 9, 1]]]) 8515tf.matrix_diag(diagonals, k = (-1, 1), align="LEFT_RIGHT") 8516 ==> [[[1, 8, 0], # Output shape: (2, 3, 3) 8517 [4, 2, 9], 8518 [0, 5, 3]], 8519 [[6, 2, 0], 8520 [9, 7, 3], 8521 [0, 1, 9]]] 8522 8523# Rectangular matrix. 8524diagonal = np.array([1, 2]) # Input shape: (2) 8525tf.matrix_diag(diagonal, k = -1, num_rows = 3, num_cols = 4) 8526 ==> [[0, 0, 0, 0], # Output shape: (3, 4) 8527 [1, 0, 0, 0], 8528 [0, 2, 0, 0]] 8529 8530# Rectangular matrix with inferred num_cols and padding_value = 9. 8531tf.matrix_diag(diagonal, k = -1, num_rows = 3, padding_value = 9) 8532 ==> [[9, 9], # Output shape: (3, 2) 8533 [1, 9], 8534 [9, 2]] 8535 8536``` 8537 }]; 8538 8539 let arguments = (ins 8540 Arg<TF_Tensor, [{Rank `r`, where `r >= 1`}]>:$diagonal, 8541 Arg<TF_Int32Tensor, [{Diagonal offset(s). Positive value means superdiagonal, 0 refers to the main 8542diagonal, and negative value means subdiagonals. `k` can be a single integer 8543(for a single diagonal) or a pair of integers specifying the low and high ends 8544of a matrix band. `k[0]` must not be larger than `k[1]`.}]>:$k, 8545 Arg<TF_Int32Tensor, [{The number of rows of the output matrix. If it is not provided, the op assumes 8546the output matrix is a square matrix and infers the matrix size from k and the 8547innermost dimension of `diagonal`.}]>:$num_rows, 8548 Arg<TF_Int32Tensor, [{The number of columns of the output matrix. If it is not provided, the op 8549assumes the output matrix is a square matrix and infers the matrix size from 8550k and the innermost dimension of `diagonal`.}]>:$num_cols, 8551 Arg<TF_Tensor, [{The number to fill the area outside the specified diagonal band with. 8552Default is 0.}]>:$padding_value, 8553 8554 DefaultValuedAttr<TF_AnyStrAttrOf<["LEFT_RIGHT", "RIGHT_LEFT", "LEFT_LEFT", "RIGHT_RIGHT"]>, "\"RIGHT_LEFT\"">:$align 8555 ); 8556 8557 let results = (outs 8558 Res<TF_Tensor, [{Has rank `r+1` when `k` is an integer or `k[0] == k[1]`, rank `r` otherwise.}]>:$output 8559 ); 8560 8561 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8562} 8563 8564def TF_MatrixInverseOp : TF_Op<"MatrixInverse", [NoSideEffect]> { 8565 let summary = [{ 8566Computes the inverse of one or more square invertible matrices or their adjoints (conjugate transposes). 8567 }]; 8568 8569 let description = [{ 8570The input is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions 8571form square matrices. The output is a tensor of the same shape as the input 8572containing the inverse for all input submatrices `[..., :, :]`. 8573 8574The op uses LU decomposition with partial pivoting to compute the inverses. 8575 8576If a matrix is not invertible there is no guarantee what the op does. It 8577may detect the condition and raise an exception or it may simply return a 8578garbage result. 8579 }]; 8580 8581 let arguments = (ins 8582 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Shape is `[..., M, M]`.}]>:$input, 8583 8584 DefaultValuedAttr<BoolAttr, "false">:$adjoint 8585 ); 8586 8587 let results = (outs 8588 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Shape is `[..., M, M]`. 8589 8590@compatibility(numpy) 8591Equivalent to np.linalg.inv 8592@end_compatibility}]>:$output 8593 ); 8594 8595 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8596} 8597 8598def TF_MatrixSetDiagOp : TF_Op<"MatrixSetDiag", [NoSideEffect]> { 8599 let summary = [{ 8600Returns a batched matrix tensor with new batched diagonal values. 8601 }]; 8602 8603 let description = [{ 8604Given `input` and `diagonal`, this operation returns a tensor with the 8605same shape and values as `input`, except for the main diagonal of the 8606innermost matrices. These will be overwritten by the values in `diagonal`. 8607 8608The output is computed as follows: 8609 8610Assume `input` has `k+1` dimensions `[I, J, K, ..., M, N]` and `diagonal` has 8611`k` dimensions `[I, J, K, ..., min(M, N)]`. Then the output is a 8612tensor of rank `k+1` with dimensions `[I, J, K, ..., M, N]` where: 8613 8614 * `output[i, j, k, ..., m, n] = diagonal[i, j, k, ..., n]` for `m == n`. 8615 * `output[i, j, k, ..., m, n] = input[i, j, k, ..., m, n]` for `m != n`. 8616 }]; 8617 8618 let arguments = (ins 8619 Arg<TF_Tensor, [{Rank `k+1`, where `k >= 1`.}]>:$input, 8620 Arg<TF_Tensor, [{Rank `k`, where `k >= 1`.}]>:$diagonal 8621 ); 8622 8623 let results = (outs 8624 Res<TF_Tensor, [{Rank `k+1`, with `output.shape = input.shape`.}]>:$output 8625 ); 8626 8627 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8628 8629 let hasCanonicalizer = 1; 8630} 8631 8632def TF_MatrixSetDiagV2Op : TF_Op<"MatrixSetDiagV2", [NoSideEffect]> { 8633 let summary = [{ 8634Returns a batched matrix tensor with new batched diagonal values. 8635 }]; 8636 8637 let description = [{ 8638Given `input` and `diagonal`, this operation returns a tensor with the 8639same shape and values as `input`, except for the specified diagonals of the 8640innermost matrices. These will be overwritten by the values in `diagonal`. 8641 8642`input` has `r+1` dimensions `[I, J, ..., L, M, N]`. When `k` is scalar or 8643`k[0] == k[1]`, `diagonal` has `r` dimensions `[I, J, ..., L, max_diag_len]`. 8644Otherwise, it has `r+1` dimensions `[I, J, ..., L, num_diags, max_diag_len]`. 8645`num_diags` is the number of diagonals, `num_diags = k[1] - k[0] + 1`. 8646`max_diag_len` is the longest diagonal in the range `[k[0], k[1]]`, 8647`max_diag_len = min(M + min(k[1], 0), N + min(-k[0], 0))` 8648 8649The output is a tensor of rank `k+1` with dimensions `[I, J, ..., L, M, N]`. 8650If `k` is scalar or `k[0] == k[1]`: 8651 8652``` 8653output[i, j, ..., l, m, n] 8654 = diagonal[i, j, ..., l, n-max(k[1], 0)] ; if n - m == k[1] 8655 input[i, j, ..., l, m, n] ; otherwise 8656``` 8657 8658Otherwise, 8659 8660``` 8661output[i, j, ..., l, m, n] 8662 = diagonal[i, j, ..., l, diag_index, index_in_diag] ; if k[0] <= d <= k[1] 8663 input[i, j, ..., l, m, n] ; otherwise 8664``` 8665where `d = n - m`, `diag_index = k[1] - d`, and `index_in_diag = n - max(d, 0)`. 8666 8667For example: 8668 8669``` 8670# The main diagonal. 8671input = np.array([[[7, 7, 7, 7], # Input shape: (2, 3, 4) 8672 [7, 7, 7, 7], 8673 [7, 7, 7, 7]], 8674 [[7, 7, 7, 7], 8675 [7, 7, 7, 7], 8676 [7, 7, 7, 7]]]) 8677diagonal = np.array([[1, 2, 3], # Diagonal shape: (2, 3) 8678 [4, 5, 6]]) 8679tf.matrix_set_diag(diagonal) ==> [[[1, 7, 7, 7], # Output shape: (2, 3, 4) 8680 [7, 2, 7, 7], 8681 [7, 7, 3, 7]], 8682 [[4, 7, 7, 7], 8683 [7, 5, 7, 7], 8684 [7, 7, 6, 7]]] 8685 8686# A superdiagonal (per batch). 8687tf.matrix_set_diag(diagonal, k = 1) 8688 ==> [[[7, 1, 7, 7], # Output shape: (2, 3, 4) 8689 [7, 7, 2, 7], 8690 [7, 7, 7, 3]], 8691 [[7, 4, 7, 7], 8692 [7, 7, 5, 7], 8693 [7, 7, 7, 6]]] 8694 8695# A band of diagonals. 8696diagonals = np.array([[[1, 2, 3], # Diagonal shape: (2, 2, 3) 8697 [4, 5, 0]], 8698 [[6, 1, 2], 8699 [3, 4, 0]]]) 8700tf.matrix_set_diag(diagonals, k = (-1, 0)) 8701 ==> [[[1, 7, 7, 7], # Output shape: (2, 3, 4) 8702 [4, 2, 7, 7], 8703 [0, 5, 3, 7]], 8704 [[6, 7, 7, 7], 8705 [3, 1, 7, 7], 8706 [7, 4, 2, 7]]] 8707 8708``` 8709 }]; 8710 8711 let arguments = (ins 8712 Arg<TF_Tensor, [{Rank `r+1`, where `r >= 1`.}]>:$input, 8713 Arg<TF_Tensor, [{Rank `r` when `k` is an integer or `k[0] == k[1]`. Otherwise, it has rank `r+1`. 8714`k >= 1`.}]>:$diagonal, 8715 Arg<TF_Int32Tensor, [{Diagonal offset(s). Positive value means superdiagonal, 0 refers to the main 8716diagonal, and negative value means subdiagonals. `k` can be a single integer 8717(for a single diagonal) or a pair of integers specifying the low and high ends 8718of a matrix band. `k[0]` must not be larger than `k[1]`.}]>:$k 8719 ); 8720 8721 let results = (outs 8722 Res<TF_Tensor, [{Rank `r+1`, with `output.shape = input.shape`.}]>:$output 8723 ); 8724 8725 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8726 8727 let hasCanonicalizer = 1; 8728} 8729 8730def TF_MatrixSetDiagV3Op : TF_Op<"MatrixSetDiagV3", [NoSideEffect]> { 8731 let summary = [{ 8732Returns a batched matrix tensor with new batched diagonal values. 8733 }]; 8734 8735 let description = [{ 8736Given `input` and `diagonal`, this operation returns a tensor with the 8737same shape and values as `input`, except for the specified diagonals of the 8738innermost matrices. These will be overwritten by the values in `diagonal`. 8739 8740`input` has `r+1` dimensions `[I, J, ..., L, M, N]`. When `k` is scalar or 8741`k[0] == k[1]`, `diagonal` has `r` dimensions `[I, J, ..., L, max_diag_len]`. 8742Otherwise, it has `r+1` dimensions `[I, J, ..., L, num_diags, max_diag_len]`. 8743`num_diags` is the number of diagonals, `num_diags = k[1] - k[0] + 1`. 8744`max_diag_len` is the longest diagonal in the range `[k[0], k[1]]`, 8745`max_diag_len = min(M + min(k[1], 0), N + min(-k[0], 0))` 8746 8747The output is a tensor of rank `k+1` with dimensions `[I, J, ..., L, M, N]`. 8748If `k` is scalar or `k[0] == k[1]`: 8749 8750``` 8751output[i, j, ..., l, m, n] 8752 = diagonal[i, j, ..., l, n-max(k[1], 0)] ; if n - m == k[1] 8753 input[i, j, ..., l, m, n] ; otherwise 8754``` 8755 8756Otherwise, 8757 8758``` 8759output[i, j, ..., l, m, n] 8760 = diagonal[i, j, ..., l, diag_index, index_in_diag] ; if k[0] <= d <= k[1] 8761 input[i, j, ..., l, m, n] ; otherwise 8762``` 8763where `d = n - m`, `diag_index = k[1] - d`, and 8764`index_in_diag = n - max(d, 0) + offset`. 8765 8766`offset` is zero except when the alignment of the diagonal is to the right. 8767``` 8768offset = max_diag_len - diag_len(d) ; if (`align` in {RIGHT_LEFT, RIGHT_RIGHT} 8769 and `d >= 0`) or 8770 (`align` in {LEFT_RIGHT, RIGHT_RIGHT} 8771 and `d <= 0`) 8772 0 ; otherwise 8773``` 8774where `diag_len(d) = min(cols - max(d, 0), rows + min(d, 0))`. 8775 8776For example: 8777 8778``` 8779# The main diagonal. 8780input = np.array([[[7, 7, 7, 7], # Input shape: (2, 3, 4) 8781 [7, 7, 7, 7], 8782 [7, 7, 7, 7]], 8783 [[7, 7, 7, 7], 8784 [7, 7, 7, 7], 8785 [7, 7, 7, 7]]]) 8786diagonal = np.array([[1, 2, 3], # Diagonal shape: (2, 3) 8787 [4, 5, 6]]) 8788tf.matrix_set_diag(input, diagonal) 8789 ==> [[[1, 7, 7, 7], # Output shape: (2, 3, 4) 8790 [7, 2, 7, 7], 8791 [7, 7, 3, 7]], 8792 [[4, 7, 7, 7], 8793 [7, 5, 7, 7], 8794 [7, 7, 6, 7]]] 8795 8796# A superdiagonal (per batch). 8797tf.matrix_set_diag(input, diagonal, k = 1) 8798 ==> [[[7, 1, 7, 7], # Output shape: (2, 3, 4) 8799 [7, 7, 2, 7], 8800 [7, 7, 7, 3]], 8801 [[7, 4, 7, 7], 8802 [7, 7, 5, 7], 8803 [7, 7, 7, 6]]] 8804 8805# A band of diagonals. 8806diagonals = np.array([[[0, 9, 1], # Diagonal shape: (2, 4, 3) 8807 [6, 5, 8], 8808 [1, 2, 3], 8809 [4, 5, 0]], 8810 [[0, 1, 2], 8811 [5, 6, 4], 8812 [6, 1, 2], 8813 [3, 4, 0]]]) 8814tf.matrix_set_diag(input, diagonals, k = (-1, 2)) 8815 ==> [[[1, 6, 9, 7], # Output shape: (2, 3, 4) 8816 [4, 2, 5, 1], 8817 [7, 5, 3, 8]], 8818 [[6, 5, 1, 7], 8819 [3, 1, 6, 2], 8820 [7, 4, 2, 4]]] 8821 8822# LEFT_RIGHT alignment. 8823diagonals = np.array([[[9, 1, 0], # Diagonal shape: (2, 4, 3) 8824 [6, 5, 8], 8825 [1, 2, 3], 8826 [0, 4, 5]], 8827 [[1, 2, 0], 8828 [5, 6, 4], 8829 [6, 1, 2], 8830 [0, 3, 4]]]) 8831tf.matrix_set_diag(input, diagonals, k = (-1, 2), align="LEFT_RIGHT") 8832 ==> [[[1, 6, 9, 7], # Output shape: (2, 3, 4) 8833 [4, 2, 5, 1], 8834 [7, 5, 3, 8]], 8835 [[6, 5, 1, 7], 8836 [3, 1, 6, 2], 8837 [7, 4, 2, 4]]] 8838 8839``` 8840 }]; 8841 8842 let arguments = (ins 8843 Arg<TF_Tensor, [{Rank `r+1`, where `r >= 1`.}]>:$input, 8844 Arg<TF_Tensor, [{Rank `r` when `k` is an integer or `k[0] == k[1]`. Otherwise, it has rank `r+1`. 8845`k >= 1`.}]>:$diagonal, 8846 Arg<TF_Int32Tensor, [{Diagonal offset(s). Positive value means superdiagonal, 0 refers to the main 8847diagonal, and negative value means subdiagonals. `k` can be a single integer 8848(for a single diagonal) or a pair of integers specifying the low and high ends 8849of a matrix band. `k[0]` must not be larger than `k[1]`.}]>:$k, 8850 8851 DefaultValuedAttr<TF_AnyStrAttrOf<["LEFT_RIGHT", "RIGHT_LEFT", "LEFT_LEFT", "RIGHT_RIGHT"]>, "\"RIGHT_LEFT\"">:$align 8852 ); 8853 8854 let results = (outs 8855 Res<TF_Tensor, [{Rank `r+1`, with `output.shape = input.shape`.}]>:$output 8856 ); 8857 8858 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8859} 8860 8861def TF_MatrixSolveOp : TF_Op<"MatrixSolve", [NoSideEffect]> { 8862 let summary = "Solves systems of linear equations."; 8863 8864 let description = [{ 8865`Matrix` is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions 8866form square matrices. `Rhs` is a tensor of shape `[..., M, K]`. The `output` is 8867a tensor shape `[..., M, K]`. If `adjoint` is `False` then each output matrix 8868satisfies `matrix[..., :, :] * output[..., :, :] = rhs[..., :, :]`. 8869If `adjoint` is `True` then each output matrix satisfies 8870`adjoint(matrix[..., :, :]) * output[..., :, :] = rhs[..., :, :]`. 8871 }]; 8872 8873 let arguments = (ins 8874 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Shape is `[..., M, M]`.}]>:$matrix, 8875 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Shape is `[..., M, K]`.}]>:$rhs, 8876 8877 DefaultValuedAttr<BoolAttr, "false">:$adjoint 8878 ); 8879 8880 let results = (outs 8881 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Shape is `[..., M, K]`.}]>:$output 8882 ); 8883 8884 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8885} 8886 8887def TF_MatrixTriangularSolveOp : TF_Op<"MatrixTriangularSolve", [NoSideEffect]> { 8888 let summary = [{ 8889Solves systems of linear equations with upper or lower triangular matrices by backsubstitution. 8890 }]; 8891 8892 let description = [{ 8893`matrix` is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions form 8894square matrices. If `lower` is `True` then the strictly upper triangular part 8895of each inner-most matrix is assumed to be zero and not accessed. 8896If `lower` is False then the strictly lower triangular part of each inner-most 8897matrix is assumed to be zero and not accessed. 8898`rhs` is a tensor of shape `[..., M, N]`. 8899 8900The output is a tensor of shape `[..., M, N]`. If `adjoint` is 8901`True` then the innermost matrices in `output` satisfy matrix equations 8902`matrix[..., :, :] * output[..., :, :] = rhs[..., :, :]`. 8903If `adjoint` is `False` then the strictly then the innermost matrices in 8904`output` satisfy matrix equations 8905`adjoint(matrix[..., i, k]) * output[..., k, j] = rhs[..., i, j]`. 8906 8907Note, the batch shapes for the inputs only need to broadcast. 8908 8909Example: 8910```python 8911 8912a = tf.constant([[3, 0, 0, 0], 8913 [2, 1, 0, 0], 8914 [1, 0, 1, 0], 8915 [1, 1, 1, 1]], dtype=tf.float32) 8916 8917b = tf.constant([[4], 8918 [2], 8919 [4], 8920 [2]], dtype=tf.float32) 8921 8922x = tf.linalg.triangular_solve(a, b, lower=True) 8923x 8924# <tf.Tensor: shape=(4, 1), dtype=float32, numpy= 8925# array([[ 1.3333334 ], 8926# [-0.66666675], 8927# [ 2.6666665 ], 8928# [-1.3333331 ]], dtype=float32)> 8929 8930# in python3 one can use `a@x` 8931tf.matmul(a, x) 8932# <tf.Tensor: shape=(4, 1), dtype=float32, numpy= 8933# array([[4. ], 8934# [2. ], 8935# [4. ], 8936# [1.9999999]], dtype=float32)> 8937``` 8938 }]; 8939 8940 let arguments = (ins 8941 Arg<TF_FpOrComplexTensor, [{Shape is `[..., M, M]`.}]>:$matrix, 8942 Arg<TF_FpOrComplexTensor, [{Shape is `[..., M, K]`.}]>:$rhs, 8943 8944 DefaultValuedAttr<BoolAttr, "true">:$lower, 8945 DefaultValuedAttr<BoolAttr, "false">:$adjoint 8946 ); 8947 8948 let results = (outs 8949 Res<TF_FpOrComplexTensor, [{Shape is `[..., M, K]`.}]>:$output 8950 ); 8951 8952 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8953} 8954 8955def TF_MaxOp : TF_Op<"Max", [NoSideEffect]> { 8956 let summary = [{ 8957Computes the maximum of elements across dimensions of a tensor. 8958 }]; 8959 8960 let description = [{ 8961Reduces `input` along the dimensions given in `axis`. Unless 8962`keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in 8963`axis`. If `keep_dims` is true, the reduced dimensions are 8964retained with length 1. 8965 }]; 8966 8967 let arguments = (ins 8968 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint16, TF_Qint32, TF_Qint8, TF_Quint16, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The tensor to reduce.}]>:$input, 8969 Arg<TF_I32OrI64Tensor, [{The dimensions to reduce. Must be in the range 8970`[-rank(input), rank(input))`.}]>:$reduction_indices, 8971 8972 DefaultValuedAttr<BoolAttr, "false">:$keep_dims 8973 ); 8974 8975 let results = (outs 8976 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint16, TF_Qint32, TF_Qint8, TF_Quint16, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The reduced tensor.}]>:$output 8977 ); 8978 8979 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 8980 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 8981 8982 let builders = [ 8983 OpBuilder<(ins "Value":$input, "Value":$reduction_indices, 8984 "BoolAttr":$keep_dims)> 8985 ]; 8986} 8987 8988def TF_MaxPoolOp : TF_Op<"MaxPool", [NoSideEffect, TF_FoldOperandsTransposeInterface, TF_LayoutSensitiveInterface]> { 8989 let summary = "Performs max pooling on the input."; 8990 8991 let arguments = (ins 8992 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint8, TF_Uint16, TF_Uint8]>, [{4-D input to pool over.}]>:$input, 8993 8994 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$ksize, 8995 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$strides, 8996 TF_AnyStrAttrOf<["SAME", "VALID", "EXPLICIT"]>:$padding, 8997 DefaultValuedAttr<I64ArrayAttr, "{}">:$explicit_paddings, 8998 DefaultValuedAttr<TF_AnyStrAttrOf<["NHWC", "NCHW", "NCHW_VECT_C"]>, "\"NHWC\"">:$data_format 8999 ); 9000 9001 let results = (outs 9002 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint8, TF_Uint16, TF_Uint8]>, [{The max pooled output tensor.}]>:$output 9003 ); 9004 9005 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9006 9007 let extraClassDeclaration = [{ 9008 // TF_FoldOperandsTransposeInterface: 9009 SmallVector<unsigned, 4> GetLayoutDependentArgs() { return {0}; } 9010 SmallVector<unsigned, 4> GetLayoutDependentResults() { return {0}; } 9011 LogicalResult FoldOperandsPermutation(ArrayRef<int64_t> permutation); 9012 // TF_LayoutSensitiveInterface: 9013 StringRef GetOptimalLayout(const RuntimeDevices& devices); 9014 LogicalResult UpdateDataFormat(StringRef data_format); 9015 }]; 9016} 9017 9018def TF_MaxPool3DOp : TF_Op<"MaxPool3D", [NoSideEffect]> { 9019 let summary = "Performs 3D max pooling on the input."; 9020 9021 let arguments = (ins 9022 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{Shape `[batch, depth, rows, cols, channels]` tensor to pool over.}]>:$input, 9023 9024 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$ksize, 9025 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$strides, 9026 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 9027 DefaultValuedAttr<TF_AnyStrAttrOf<["NDHWC", "NCDHW"]>, "\"NDHWC\"">:$data_format 9028 ); 9029 9030 let results = (outs 9031 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{The max pooled output tensor.}]>:$output 9032 ); 9033 9034 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9035} 9036 9037def TF_MaxPool3DGradOp : TF_Op<"MaxPool3DGrad", [NoSideEffect]> { 9038 let summary = "Computes gradients of 3D max pooling function."; 9039 9040 let arguments = (ins 9041 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{The original input tensor.}]>:$orig_input, 9042 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{The original output tensor.}]>:$orig_output, 9043 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>, [{Output backprop of shape `[batch, depth, rows, cols, channels]`.}]>:$grad, 9044 9045 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$ksize, 9046 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$strides, 9047 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 9048 DefaultValuedAttr<TF_AnyStrAttrOf<["NDHWC", "NCDHW"]>, "\"NDHWC\"">:$data_format 9049 ); 9050 9051 let results = (outs 9052 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>:$output 9053 ); 9054 9055 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 9056 TF_DerivedOperandTypeAttr TInput = TF_DerivedOperandTypeAttr<0>; 9057} 9058 9059def TF_MaxPool3DGradGradOp : TF_Op<"MaxPool3DGradGrad", [NoSideEffect]> { 9060 let summary = "Computes second-order gradients of the maxpooling function."; 9061 9062 let arguments = (ins 9063 Arg<TF_IntOrFpTensor, [{The original input tensor.}]>:$orig_input, 9064 Arg<TF_IntOrFpTensor, [{The original output tensor.}]>:$orig_output, 9065 Arg<TF_IntOrFpTensor, [{Output backprop of shape `[batch, depth, rows, cols, channels]`.}]>:$grad, 9066 9067 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$ksize, 9068 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<5>]>:$strides, 9069 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 9070 DefaultValuedAttr<TF_AnyStrAttrOf<["NDHWC", "NCDHW"]>, "\"NDHWC\"">:$data_format 9071 ); 9072 9073 let results = (outs 9074 Res<TF_IntOrFpTensor, [{Gradients of gradients w.r.t. the input to `max_pool`.}]>:$output 9075 ); 9076 9077 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9078} 9079 9080def TF_MaxPoolGradOp : TF_Op<"MaxPoolGrad", [NoSideEffect]> { 9081 let summary = "Computes gradients of the maxpooling function."; 9082 9083 let arguments = (ins 9084 Arg<TF_IntOrFpTensor, [{The original input tensor.}]>:$orig_input, 9085 Arg<TF_IntOrFpTensor, [{The original output tensor.}]>:$orig_output, 9086 Arg<TF_IntOrFpTensor, [{4-D. Gradients w.r.t. the output of `max_pool`.}]>:$grad, 9087 9088 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$ksize, 9089 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$strides, 9090 TF_AnyStrAttrOf<["SAME", "VALID", "EXPLICIT"]>:$padding, 9091 DefaultValuedAttr<I64ArrayAttr, "{}">:$explicit_paddings, 9092 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format 9093 ); 9094 9095 let results = (outs 9096 Res<TF_IntOrFpTensor, [{Gradients w.r.t. the input to `max_pool`.}]>:$output 9097 ); 9098 9099 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9100 9101 let hasVerifier = 1; 9102} 9103 9104def TF_MaxPoolGradGradOp : TF_Op<"MaxPoolGradGrad", [NoSideEffect]> { 9105 let summary = "Computes second-order gradients of the maxpooling function."; 9106 9107 let arguments = (ins 9108 Arg<TF_IntOrFpTensor, [{The original input tensor.}]>:$orig_input, 9109 Arg<TF_IntOrFpTensor, [{The original output tensor.}]>:$orig_output, 9110 Arg<TF_IntOrFpTensor, [{4-D. Gradients of gradients w.r.t. the input of `max_pool`.}]>:$grad, 9111 9112 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$ksize, 9113 ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$strides, 9114 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 9115 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format 9116 ); 9117 9118 let results = (outs 9119 Res<TF_IntOrFpTensor, [{Gradients of gradients w.r.t. the input to `max_pool`.}]>:$output 9120 ); 9121 9122 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9123} 9124 9125def TF_MaxPoolGradGradV2Op : TF_Op<"MaxPoolGradGradV2", [NoSideEffect]> { 9126 let summary = "Computes second-order gradients of the maxpooling function."; 9127 9128 let arguments = (ins 9129 Arg<TF_IntOrFpTensor, [{The original input tensor.}]>:$orig_input, 9130 Arg<TF_IntOrFpTensor, [{The original output tensor.}]>:$orig_output, 9131 Arg<TF_IntOrFpTensor, [{4-D. Gradients of gradients w.r.t. the input of `max_pool`.}]>:$grad, 9132 Arg<TF_Int32Tensor, [{The size of the window for each dimension of the input tensor.}]>:$ksize, 9133 Arg<TF_Int32Tensor, [{The stride of the sliding window for each dimension of the 9134input tensor.}]>:$strides, 9135 9136 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 9137 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format 9138 ); 9139 9140 let results = (outs 9141 Res<TF_IntOrFpTensor, [{Gradients of gradients w.r.t. the input to `max_pool`.}]>:$output 9142 ); 9143 9144 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9145} 9146 9147def TF_MaxPoolGradV2Op : TF_Op<"MaxPoolGradV2", [NoSideEffect]> { 9148 let summary = "Computes gradients of the maxpooling function."; 9149 9150 let arguments = (ins 9151 Arg<TF_IntOrFpTensor, [{The original input tensor.}]>:$orig_input, 9152 Arg<TF_IntOrFpTensor, [{The original output tensor.}]>:$orig_output, 9153 Arg<TF_IntOrFpTensor, [{4-D. Gradients w.r.t. the output of `max_pool`.}]>:$grad, 9154 Arg<TF_Int32Tensor, [{The size of the window for each dimension of the input tensor.}]>:$ksize, 9155 Arg<TF_Int32Tensor, [{The stride of the sliding window for each dimension of the 9156input tensor.}]>:$strides, 9157 9158 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 9159 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format 9160 ); 9161 9162 let results = (outs 9163 Res<TF_IntOrFpTensor, [{Gradients w.r.t. the input to `max_pool`.}]>:$output 9164 ); 9165 9166 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9167} 9168 9169def TF_MaxPoolV2Op : TF_Op<"MaxPoolV2", [NoSideEffect]> { 9170 let summary = "Performs max pooling on the input."; 9171 9172 let arguments = (ins 9173 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint8, TF_Uint16, TF_Uint8]>, [{4-D input to pool over.}]>:$input, 9174 Arg<TF_Int32Tensor, [{The size of the window for each dimension of the input tensor.}]>:$ksize, 9175 Arg<TF_Int32Tensor, [{The stride of the sliding window for each dimension of the 9176input tensor.}]>:$strides, 9177 9178 TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding, 9179 DefaultValuedAttr<TF_AnyStrAttrOf<["NHWC", "NCHW", "NCHW_VECT_C"]>, "\"NHWC\"">:$data_format 9180 ); 9181 9182 let results = (outs 9183 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint8, TF_Uint16, TF_Uint8]>, [{The max pooled output tensor.}]>:$output 9184 ); 9185 9186 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9187} 9188 9189def TF_MaximumOp : TF_Op<"Maximum", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 9190 WithBroadcastableBinOpBuilder { 9191 let summary = "Returns the max of x and y (i.e. x > y ? x : y) element-wise."; 9192 9193 let description = [{ 9194*NOTE*: `Maximum` supports broadcasting. More about broadcasting 9195[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 9196 }]; 9197 9198 let arguments = (ins 9199 TF_IntOrFpTensor:$x, 9200 TF_IntOrFpTensor:$y 9201 ); 9202 9203 let results = (outs 9204 TF_IntOrFpTensor:$z 9205 ); 9206 9207 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9208 9209 let hasCanonicalizer = 1; 9210} 9211 9212def TF_MeanOp : TF_Op<"Mean", [NoSideEffect, TF_FoldOperandsTransposeInterface]> { 9213 let summary = "Computes the mean of elements across dimensions of a tensor."; 9214 9215 let description = [{ 9216Reduces `input` along the dimensions given in `axis`. Unless 9217`keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in 9218`axis`. If `keep_dims` is true, the reduced dimensions are 9219retained with length 1. 9220 }]; 9221 9222 let arguments = (ins 9223 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The tensor to reduce.}]>:$input, 9224 Arg<TF_I32OrI64Tensor, [{The dimensions to reduce. Must be in the range 9225`[-rank(input), rank(input))`.}]>:$reduction_indices, 9226 9227 DefaultValuedAttr<BoolAttr, "false">:$keep_dims 9228 ); 9229 9230 let results = (outs 9231 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The reduced tensor.}]>:$output 9232 ); 9233 9234 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9235 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 9236 9237 let extraClassDeclaration = [{ 9238 // TF_FoldOperandsTransposeInterface: 9239 SmallVector<unsigned, 4> GetLayoutDependentArgs() { return {0}; } 9240 SmallVector<unsigned, 4> GetLayoutDependentResults() { return {}; } 9241 LogicalResult FoldOperandsPermutation(ArrayRef<int64_t> permutation); 9242 }]; 9243} 9244 9245def TF_MergeSummaryOp : TF_Op<"MergeSummary", [NoSideEffect, SameOperandsAndResultType]> { 9246 let summary = "Merges summaries."; 9247 9248 let description = [{ 9249This op creates a 9250[`Summary`](https://www.tensorflow.org/code/tensorflow/core/framework/summary.proto) 9251protocol buffer that contains the union of all the values in the input 9252summaries. 9253 9254When the Op is run, it reports an `InvalidArgument` error if multiple values 9255in the summaries to merge use the same tag. 9256 }]; 9257 9258 let arguments = (ins 9259 Arg<Variadic<TF_StrTensor>, [{Can be of any shape. Each must contain serialized `Summary` protocol 9260buffers.}]>:$inputs 9261 ); 9262 9263 let results = (outs 9264 Res<TF_StrTensor, [{Scalar. Serialized `Summary` protocol buffer.}]>:$summary 9265 ); 9266 9267 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 9268} 9269 9270def TF_MergeV2CheckpointsOp : TF_Op<"MergeV2Checkpoints", []> { 9271 let summary = [{ 9272V2 format specific: merges the metadata files of sharded checkpoints. The 9273 }]; 9274 9275 let description = [{ 9276result is one logical checkpoint, with one physical metadata file and renamed 9277data files. 9278 9279Intended for "grouping" multiple checkpoints in a sharded checkpoint setup. 9280 9281If delete_old_dirs is true, attempts to delete recursively the dirname of each 9282path in the input checkpoint_prefixes. This is useful when those paths are non 9283user-facing temporary locations. 9284 9285If allow_missing_files is true, merges the checkpoint prefixes as long as 9286at least one file exists. Otherwise, if no files exist, an error will be thrown. 9287The default value for allow_missing_files is false. 9288 }]; 9289 9290 let arguments = (ins 9291 Arg<TF_StrTensor, [{prefixes of V2 checkpoints to merge.}]>:$checkpoint_prefixes, 9292 Arg<TF_StrTensor, [{scalar. The desired final prefix. Allowed to be the same 9293as one of the checkpoint_prefixes.}]>:$destination_prefix, 9294 9295 DefaultValuedAttr<BoolAttr, "true">:$delete_old_dirs, 9296 DefaultValuedAttr<BoolAttr, "false">:$allow_missing_files 9297 ); 9298 9299 let results = (outs); 9300} 9301 9302def TF_MinOp : TF_Op<"Min", [NoSideEffect]> { 9303 let summary = [{ 9304Computes the minimum of elements across dimensions of a tensor. 9305 }]; 9306 9307 let description = [{ 9308Reduces `input` along the dimensions given in `axis`. Unless 9309`keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in 9310`axis`. If `keep_dims` is true, the reduced dimensions are 9311retained with length 1. 9312 }]; 9313 9314 let arguments = (ins 9315 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint16, TF_Qint32, TF_Qint8, TF_Quint16, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The tensor to reduce.}]>:$input, 9316 Arg<TF_I32OrI64Tensor, [{The dimensions to reduce. Must be in the range 9317`[-rank(input), rank(input))`.}]>:$reduction_indices, 9318 9319 DefaultValuedAttr<BoolAttr, "false">:$keep_dims 9320 ); 9321 9322 let results = (outs 9323 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint16, TF_Qint32, TF_Qint8, TF_Quint16, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The reduced tensor.}]>:$output 9324 ); 9325 9326 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9327 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 9328} 9329 9330def TF_MinimumOp : TF_Op<"Minimum", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 9331 WithBroadcastableBinOpBuilder { 9332 let summary = "Returns the min of x and y (i.e. x < y ? x : y) element-wise."; 9333 9334 let description = [{ 9335*NOTE*: `Minimum` supports broadcasting. More about broadcasting 9336[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 9337 }]; 9338 9339 let arguments = (ins 9340 TF_IntOrFpTensor:$x, 9341 TF_IntOrFpTensor:$y 9342 ); 9343 9344 let results = (outs 9345 TF_IntOrFpTensor:$z 9346 ); 9347 9348 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9349} 9350 9351def TF_MirrorPadOp : TF_Op<"MirrorPad", [NoSideEffect, TF_OperandHasRank<1, 2>]> { 9352 let summary = "Pads a tensor with mirrored values."; 9353 9354 let description = [{ 9355This operation pads a `input` with mirrored values according to the `paddings` 9356you specify. `paddings` is an integer tensor with shape `[n, 2]`, where n is 9357the rank of `input`. For each dimension D of `input`, `paddings[D, 0]` indicates 9358how many values to add before the contents of `input` in that dimension, and 9359`paddings[D, 1]` indicates how many values to add after the contents of `input` 9360in that dimension. Both `paddings[D, 0]` and `paddings[D, 1]` must be no greater 9361than `input.dim_size(D)` (or `input.dim_size(D) - 1`) if `copy_border` is true 9362(if false, respectively). 9363 9364The padded size of each dimension D of the output is: 9365 9366`paddings(D, 0) + input.dim_size(D) + paddings(D, 1)` 9367 9368For example: 9369 9370``` 9371# 't' is [[1, 2, 3], [4, 5, 6]]. 9372# 'paddings' is [[1, 1]], [2, 2]]. 9373# 'mode' is SYMMETRIC. 9374# rank of 't' is 2. 9375pad(t, paddings) ==> [[2, 1, 1, 2, 3, 3, 2] 9376 [2, 1, 1, 2, 3, 3, 2] 9377 [5, 4, 4, 5, 6, 6, 5] 9378 [5, 4, 4, 5, 6, 6, 5]] 9379``` 9380 }]; 9381 9382 let arguments = (ins 9383 Arg<TF_Tensor, [{The input tensor to be padded.}]>:$input, 9384 Arg<TF_I32OrI64Tensor, [{A two-column matrix specifying the padding sizes. The number of 9385rows must be the same as the rank of `input`.}]>:$paddings, 9386 9387 TF_AnyStrAttrOf<["REFLECT", "SYMMETRIC"]>:$mode 9388 ); 9389 9390 let results = (outs 9391 Res<TF_Tensor, [{The padded tensor.}]>:$output 9392 ); 9393 9394 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9395 TF_DerivedOperandTypeAttr Tpaddings = TF_DerivedOperandTypeAttr<1>; 9396} 9397 9398def TF_MirrorPadGradOp : TF_Op<"MirrorPadGrad", [NoSideEffect, TF_OperandHasRank<1, 2>]> { 9399 let summary = [{ 9400Gradient op for `MirrorPad` op. This op folds a mirror-padded tensor. 9401 }]; 9402 9403 let description = [{ 9404This operation folds the padded areas of `input` by `MirrorPad` according to the 9405`paddings` you specify. `paddings` must be the same as `paddings` argument 9406given to the corresponding `MirrorPad` op. 9407 9408The folded size of each dimension D of the output is: 9409 9410`input.dim_size(D) - paddings(D, 0) - paddings(D, 1)` 9411 9412For example: 9413 9414``` 9415# 't' is [[1, 2, 3], [4, 5, 6], [7, 8, 9]]. 9416# 'paddings' is [[0, 1]], [0, 1]]. 9417# 'mode' is SYMMETRIC. 9418# rank of 't' is 2. 9419pad(t, paddings) ==> [[ 1, 5] 9420 [11, 28]] 9421``` 9422 }]; 9423 9424 let arguments = (ins 9425 Arg<TF_Tensor, [{The input tensor to be folded.}]>:$input, 9426 Arg<TF_I32OrI64Tensor, [{A two-column matrix specifying the padding sizes. The number of 9427rows must be the same as the rank of `input`.}]>:$paddings, 9428 9429 TF_AnyStrAttrOf<["REFLECT", "SYMMETRIC"]>:$mode 9430 ); 9431 9432 let results = (outs 9433 Res<TF_Tensor, [{The folded tensor.}]>:$output 9434 ); 9435 9436 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9437 TF_DerivedOperandTypeAttr Tpaddings = TF_DerivedOperandTypeAttr<1>; 9438} 9439 9440def TF_MlirLocalVarOp : TF_Op<"MlirLocalVarOp", []> { 9441 let summary = "Creates a handle to an in-scope variable."; 9442 9443 let description = [{ 9444Used by internal passes for temporary representation of local state, which will 9445be eventually removed. 9446 }]; 9447 9448 let arguments = (ins); 9449 9450 let results = (outs 9451 Res<TF_ResourceTensor, "", [TF_VariableAlloc]>:$resource 9452 ); 9453} 9454 9455def TF_MlirPassthroughOp : TF_Op<"MlirPassthroughOp", [NoSideEffect]> { 9456 let summary = [{ 9457Wraps an arbitrary MLIR computation expressed as a module with a main() function. 9458 }]; 9459 9460 let description = [{ 9461This operation does not have an associated kernel and is not intended to be 9462executed in a regular TensorFlow session. Instead it is intended to be used for 9463testing or for special case where a user intends to pass custom MLIR computation 9464through a TensorFlow graph with the intent of having custom tooling processing 9465it downstream (when targeting a different environment, like TensorFlow lite for 9466example). 9467The MLIR module is expected to have a main() function that will be used as an 9468entry point. The inputs to the operations will be passed as argument to the 9469main() function and the returned values of the main function mapped to the 9470outputs. 9471Example usage: 9472 9473``` 9474import tensorflow as tf 9475from tensorflow.compiler.mlir.tensorflow.gen_mlir_passthrough_op import mlir_passthrough_op 9476 9477mlir_module = '''python 9478func @main(%arg0 : tensor<10xf32>, %arg1 : tensor<10xf32>) -> tensor<10x10xf32> { 9479 %add = "magic.op"(%arg0, %arg1) : (tensor<10xf32>, tensor<10xf32>) -> tensor<10x10xf32> 9480 return %ret : tensor<10x10xf32> 9481} 9482''' 9483 9484@tf.function 9485def foo(x, y): 9486 return mlir_passthrough_op([x, y], mlir_module, Toutputs=[tf.float32]) 9487 9488graph_def = foo.get_concrete_function(tf.TensorSpec([10], tf.float32), tf.TensorSpec([10], tf.float32)).graph.as_graph_def() 9489``` 9490 }]; 9491 9492 let arguments = (ins 9493 Variadic<TF_Tensor>:$inputs, 9494 9495 StrAttr:$mlir_module 9496 ); 9497 9498 let results = (outs 9499 Variadic<TF_Tensor>:$outputs 9500 ); 9501 9502 TF_DerivedOperandTypeListAttr Tinputs = TF_DerivedOperandTypeListAttr<0>; 9503 TF_DerivedResultTypeListAttr Toutputs = TF_DerivedResultTypeListAttr<0>; 9504} 9505 9506def TF_ModOp : TF_Op<"Mod", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 9507 WithBroadcastableBinOpBuilder { 9508 let summary = [{ 9509Returns element-wise remainder of division. This emulates C semantics in that 9510 }]; 9511 9512 let description = [{ 9513the result here is consistent with a truncating divide. E.g. 9514`tf.truncatediv(x, y) * y + truncate_mod(x, y) = x`. 9515 9516*NOTE*: `Mod` supports broadcasting. More about broadcasting 9517[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 9518 }]; 9519 9520 let arguments = (ins 9521 TF_FpOrI32OrI64Tensor:$x, 9522 TF_FpOrI32OrI64Tensor:$y 9523 ); 9524 9525 let results = (outs 9526 TF_FpOrI32OrI64Tensor:$z 9527 ); 9528 9529 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9530} 9531 9532def TF_ModelDatasetOp : TF_Op<"ModelDataset", [NoSideEffect]> { 9533 let summary = "Identity transformation that models performance."; 9534 9535 let description = [{ 9536Identity transformation that models performance. 9537 }]; 9538 9539 let arguments = (ins 9540 Arg<TF_VariantTensor, [{A variant tensor representing the input dataset.}]>:$input_dataset, 9541 9542 DefaultValuedAttr<I64Attr, "0">:$algorithm, 9543 DefaultValuedAttr<I64Attr, "0">:$cpu_budget, 9544 DefaultValuedAttr<I64Attr, "0">:$ram_budget, 9545 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 9546 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 9547 ); 9548 9549 let results = (outs 9550 TF_VariantTensor:$handle 9551 ); 9552} 9553 9554def TF_MulOp : TF_Op<"Mul", [Commutative, NoSideEffect, ResultsBroadcastableShape, TF_CwiseBinary, TF_SameOperandsAndResultElementTypeResolveRef]>, 9555 WithBroadcastableBinOpBuilder { 9556 let summary = "Returns x * y element-wise."; 9557 9558 let description = [{ 9559*NOTE*: `Multiply` supports broadcasting. More about broadcasting 9560[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 9561 }]; 9562 9563 let arguments = (ins 9564 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$x, 9565 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$y 9566 ); 9567 9568 let results = (outs 9569 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$z 9570 ); 9571 9572 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9573 9574 let hasFolder = 1; 9575} 9576 9577def TF_MulNoNanOp : TF_Op<"MulNoNan", [NoSideEffect, ResultsBroadcastableShape]>, 9578 WithBroadcastableBinOpBuilder { 9579 let summary = [{ 9580Returns x * y element-wise. Returns zero if y is zero, even if x if infinite or NaN. 9581 }]; 9582 9583 let description = [{ 9584*NOTE*: `MulNoNan` supports broadcasting. More about broadcasting 9585[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 9586 }]; 9587 9588 let arguments = (ins 9589 TF_FpOrComplexTensor:$x, 9590 TF_FpOrComplexTensor:$y 9591 ); 9592 9593 let results = (outs 9594 TF_FpOrComplexTensor:$z 9595 ); 9596 9597 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9598 9599 let hasCanonicalizer = 1; 9600} 9601 9602def TF_MultiDeviceIteratorOp : TF_Op<"MultiDeviceIterator", []> { 9603 let summary = "Creates a MultiDeviceIterator resource."; 9604 9605 let arguments = (ins 9606 ConfinedAttr<StrArrayAttr, [ArrayMinCount<1>]>:$devices, 9607 StrAttr:$shared_name, 9608 StrAttr:$container, 9609 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 9610 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes 9611 ); 9612 9613 let results = (outs 9614 Res<TF_ResourceTensor, [{Handle to the resource created.}], [TF_DatasetIteratorAlloc]>:$handle 9615 ); 9616} 9617 9618def TF_MultiDeviceIteratorFromStringHandleOp : TF_Op<"MultiDeviceIteratorFromStringHandle", []> { 9619 let summary = [{ 9620Generates a MultiDeviceIterator resource from its provided string handle. 9621 }]; 9622 9623 let arguments = (ins 9624 Arg<TF_StrTensor, [{String representing the resource.}]>:$string_handle, 9625 9626 DefaultValuedAttr<TypeArrayAttr, "{}">:$output_types, 9627 DefaultValuedAttr<TF_ShapeAttrArray, "{}">:$output_shapes 9628 ); 9629 9630 let results = (outs 9631 Res<TF_ResourceTensor, [{A MultiDeviceIterator resource.}], [TF_DatasetIteratorAlloc]>:$multi_device_iterator 9632 ); 9633} 9634 9635def TF_MultiDeviceIteratorGetNextFromShardOp : TF_Op<"MultiDeviceIteratorGetNextFromShard", []> { 9636 let summary = "Gets next element for the provided shard number."; 9637 9638 let arguments = (ins 9639 Arg<TF_ResourceTensor, [{A MultiDeviceIterator resource.}], [TF_DatasetIteratorRead, TF_DatasetIteratorWrite]>:$multi_device_iterator, 9640 Arg<TF_Int32Tensor, [{Integer representing which shard to fetch data for.}]>:$shard_num, 9641 Arg<TF_Int64Tensor, [{Which incarnation of the MultiDeviceIterator is running.}]>:$incarnation_id 9642 ); 9643 9644 let results = (outs 9645 Res<Variadic<TF_Tensor>, [{Result of the get_next on the dataset.}]>:$components 9646 ); 9647 9648 TF_DerivedResultShapeListAttr output_shapes = TF_DerivedResultShapeListAttr<0>; 9649 TF_DerivedResultTypeListAttr output_types = TF_DerivedResultTypeListAttr<0>; 9650} 9651 9652def TF_MultiDeviceIteratorInitOp : TF_Op<"MultiDeviceIteratorInit", []> { 9653 let summary = "Initializes the multi device iterator with the given dataset."; 9654 9655 let arguments = (ins 9656 Arg<TF_VariantTensor, [{Dataset to be iterated upon.}]>:$dataset, 9657 Arg<TF_ResourceTensor, [{A MultiDeviceIteratorResource.}], [TF_DatasetIteratorWrite]>:$multi_device_iterator, 9658 Arg<TF_Int64Tensor, [{The maximum size of the host side per device buffer to keep.}]>:$max_buffer_size 9659 ); 9660 9661 let results = (outs 9662 Res<TF_Int64Tensor, [{An int64 indicating which incarnation of the MultiDeviceIterator 9663is running.}]>:$incarnation_id 9664 ); 9665} 9666 9667def TF_MultiDeviceIteratorToStringHandleOp : TF_Op<"MultiDeviceIteratorToStringHandle", []> { 9668 let summary = "Produces a string handle for the given MultiDeviceIterator."; 9669 9670 let arguments = (ins 9671 Arg<TF_ResourceTensor, [{A MultiDeviceIterator resource.}], [TF_DatasetIteratorRead]>:$multi_device_iterator 9672 ); 9673 9674 let results = (outs 9675 Res<TF_StrTensor, [{A string representing the resource.}]>:$string_handle 9676 ); 9677} 9678 9679def TF_MultinomialOp : TF_Op<"Multinomial", [TF_CannotDuplicate]> { 9680 let summary = "Draws samples from a multinomial distribution."; 9681 9682 let arguments = (ins 9683 Arg<TF_IntOrFpTensor, [{2-D Tensor with shape `[batch_size, num_classes]`. Each slice `[i, :]` 9684represents the unnormalized log probabilities for all classes.}]>:$logits, 9685 Arg<TF_Int32Tensor, [{0-D. Number of independent samples to draw for each row slice.}]>:$num_samples, 9686 9687 DefaultValuedAttr<I64Attr, "0">:$seed, 9688 DefaultValuedAttr<I64Attr, "0">:$seed2 9689 ); 9690 9691 let results = (outs 9692 Res<TF_I32OrI64Tensor, [{2-D Tensor with shape `[batch_size, num_samples]`. Each slice `[i, :]` 9693contains the drawn class labels with range `[0, num_classes)`.}]>:$output 9694 ); 9695 9696 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9697 TF_DerivedResultTypeAttr output_dtype = TF_DerivedResultTypeAttr<0>; 9698} 9699 9700def TF_MutableDenseHashTableV2Op : TF_Op<"MutableDenseHashTableV2", []> { 9701 let summary = [{ 9702Creates an empty hash table that uses tensors as the backing store. 9703 }]; 9704 9705 let description = [{ 9706It uses "open addressing" with quadratic reprobing to resolve 9707collisions. 9708 9709This op creates a mutable hash table, specifying the type of its keys and 9710values. Each value must be a scalar. Data can be inserted into the table using 9711the insert operations. It does not support the initialization operation. 9712 }]; 9713 9714 let arguments = (ins 9715 Arg<TF_Tensor, [{The key used to represent empty key buckets internally. Must not 9716be used in insert or lookup operations.}]>:$empty_key, 9717 TF_Tensor:$deleted_key, 9718 9719 DefaultValuedAttr<StrAttr, "\"\"">:$container, 9720 DefaultValuedAttr<StrAttr, "\"\"">:$shared_name, 9721 DefaultValuedAttr<BoolAttr, "false">:$use_node_name_sharing, 9722 TypeAttr:$value_dtype, 9723 DefaultValuedAttr<TF_ShapeAttr, "llvm::ArrayRef<int64_t>({})">:$value_shape, 9724 DefaultValuedAttr<I64Attr, "131072">:$initial_num_buckets, 9725 DefaultValuedAttr<F32Attr, "0.8f">:$max_load_factor 9726 ); 9727 9728 let results = (outs 9729 Res<TF_ResourceTensor, [{Handle to a table.}], [TF_LookupTableAlloc]>:$table_handle 9730 ); 9731 9732 TF_DerivedOperandTypeAttr key_dtype = TF_DerivedOperandTypeAttr<0>; 9733} 9734 9735def TF_MutableHashTableOfTensorsV2Op : TF_Op<"MutableHashTableOfTensorsV2", []> { 9736 let summary = "Creates an empty hash table."; 9737 9738 let description = [{ 9739This op creates a mutable hash table, specifying the type of its keys and 9740values. Each value must be a vector. Data can be inserted into the table using 9741the insert operations. It does not support the initialization operation. 9742 }]; 9743 9744 let arguments = (ins 9745 DefaultValuedAttr<StrAttr, "\"\"">:$container, 9746 DefaultValuedAttr<StrAttr, "\"\"">:$shared_name, 9747 DefaultValuedAttr<BoolAttr, "false">:$use_node_name_sharing, 9748 TypeAttr:$key_dtype, 9749 TypeAttr:$value_dtype, 9750 DefaultValuedAttr<TF_ShapeAttr, "llvm::ArrayRef<int64_t>({})">:$value_shape 9751 ); 9752 9753 let results = (outs 9754 Res<TF_ResourceTensor, [{Handle to a table.}], [TF_LookupTableAlloc]>:$table_handle 9755 ); 9756} 9757 9758def TF_MutableHashTableV2Op : TF_Op<"MutableHashTableV2", []> { 9759 let summary = "Creates an empty hash table."; 9760 9761 let description = [{ 9762This op creates a mutable hash table, specifying the type of its keys and 9763values. Each value must be a scalar. Data can be inserted into the table using 9764the insert operations. It does not support the initialization operation. 9765 }]; 9766 9767 let arguments = (ins 9768 DefaultValuedAttr<StrAttr, "\"\"">:$container, 9769 DefaultValuedAttr<StrAttr, "\"\"">:$shared_name, 9770 DefaultValuedAttr<BoolAttr, "false">:$use_node_name_sharing, 9771 TypeAttr:$key_dtype, 9772 TypeAttr:$value_dtype 9773 ); 9774 9775 let results = (outs 9776 Res<TF_ResourceTensor, [{Handle to a table.}], [TF_LookupTableAlloc]>:$table_handle 9777 ); 9778} 9779 9780def TF_NdtriOp : TF_Op<"Ndtri", [NoSideEffect]> { 9781 let summary = ""; 9782 9783 let arguments = (ins 9784 TF_FloatTensor:$x 9785 ); 9786 9787 let results = (outs 9788 TF_FloatTensor:$y 9789 ); 9790 9791 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9792} 9793 9794def TF_NegOp : TF_Op<"Neg", [Involution, NoSideEffect, SameOperandsAndResultType, TF_CwiseUnary]> { 9795 let summary = "Computes numerical negative value element-wise."; 9796 9797 let description = [{ 9798I.e., \\(y = -x\\). 9799 }]; 9800 9801 let arguments = (ins 9802 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x 9803 ); 9804 9805 let results = (outs 9806 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 9807 ); 9808 9809 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9810 9811 let extraClassDeclaration = [{ 9812 static bool isCompatibleReturnTypes(TypeRange inferred, TypeRange actual) { 9813 return ArraysAreCastCompatible(inferred, actual); 9814 } 9815 }]; 9816} 9817 9818def TF_NextAfterOp : TF_Op<"NextAfter", [NoSideEffect, ResultsBroadcastableShape]>, 9819 WithBroadcastableBinOpBuilder { 9820 let summary = [{ 9821Returns the next representable value of `x1` in the direction of `x2`, element-wise. 9822 }]; 9823 9824 let description = [{ 9825This operation returns the same result as the C++ std::nextafter function. 9826 9827It can also return a subnormal number. 9828 9829@compatibility(cpp) 9830Equivalent to C++ std::nextafter function. 9831@end_compatibility 9832 }]; 9833 9834 let arguments = (ins 9835 TF_F32OrF64Tensor:$x1, 9836 TF_F32OrF64Tensor:$x2 9837 ); 9838 9839 let results = (outs 9840 TF_F32OrF64Tensor:$output 9841 ); 9842 9843 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9844} 9845 9846def TF_NoOp : TF_Op<"NoOp", [NoSideEffect]> { 9847 let summary = "Does nothing. Only useful as a placeholder for control edges."; 9848 9849 let arguments = (ins); 9850 9851 let results = (outs); 9852} 9853 9854def TF_NonMaxSuppressionV3Op : TF_Op<"NonMaxSuppressionV3", [NoSideEffect]> { 9855 let summary = [{ 9856Greedily selects a subset of bounding boxes in descending order of score, 9857 }]; 9858 9859 let description = [{ 9860pruning away boxes that have high intersection-over-union (IOU) overlap 9861with previously selected boxes. Bounding boxes with score less than 9862`score_threshold` are removed. Bounding boxes are supplied as 9863[y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any 9864diagonal pair of box corners and the coordinates can be provided as normalized 9865(i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm 9866is agnostic to where the origin is in the coordinate system and more 9867generally is invariant to orthogonal transformations and translations 9868of the coordinate system; thus translating or reflections of the coordinate 9869system result in the same boxes being selected by the algorithm. 9870The output of this operation is a set of integers indexing into the input 9871collection of bounding boxes representing the selected boxes. The bounding 9872box coordinates corresponding to the selected indices can then be obtained 9873using the `tf.gather operation`. For example: 9874 selected_indices = tf.image.non_max_suppression_v2( 9875 boxes, scores, max_output_size, iou_threshold, score_threshold) 9876 selected_boxes = tf.gather(boxes, selected_indices) 9877 }]; 9878 9879 let arguments = (ins 9880 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 2-D float tensor of shape `[num_boxes, 4]`.}]>:$boxes, 9881 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 1-D float tensor of shape `[num_boxes]` representing a single 9882score corresponding to each box (each row of boxes).}]>:$scores, 9883 Arg<TF_Int32Tensor, [{A scalar integer tensor representing the maximum number of 9884boxes to be selected by non max suppression.}]>:$max_output_size, 9885 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 0-D float tensor representing the threshold for deciding whether 9886boxes overlap too much with respect to IOU.}]>:$iou_threshold, 9887 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 0-D float tensor representing the threshold for deciding when to remove 9888boxes based on score.}]>:$score_threshold 9889 ); 9890 9891 let results = (outs 9892 Res<TF_Int32Tensor, [{A 1-D integer tensor of shape `[M]` representing the selected 9893indices from the boxes tensor, where `M <= max_output_size`.}]>:$selected_indices 9894 ); 9895 9896 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9897 TF_DerivedOperandTypeAttr T_threshold = TF_DerivedOperandTypeAttr<3>; 9898 9899 let hasCanonicalizer = 1; 9900} 9901 9902def TF_NonMaxSuppressionV4Op : TF_Op<"NonMaxSuppressionV4", [NoSideEffect]> { 9903 let summary = [{ 9904Greedily selects a subset of bounding boxes in descending order of score, 9905 }]; 9906 9907 let description = [{ 9908pruning away boxes that have high intersection-over-union (IOU) overlap 9909with previously selected boxes. Bounding boxes with score less than 9910`score_threshold` are removed. Bounding boxes are supplied as 9911[y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any 9912diagonal pair of box corners and the coordinates can be provided as normalized 9913(i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm 9914is agnostic to where the origin is in the coordinate system and more 9915generally is invariant to orthogonal transformations and translations 9916of the coordinate system; thus translating or reflections of the coordinate 9917system result in the same boxes being selected by the algorithm. 9918The output of this operation is a set of integers indexing into the input 9919collection of bounding boxes representing the selected boxes. The bounding 9920box coordinates corresponding to the selected indices can then be obtained 9921using the `tf.gather operation`. For example: 9922 selected_indices = tf.image.non_max_suppression_v2( 9923 boxes, scores, max_output_size, iou_threshold, score_threshold) 9924 selected_boxes = tf.gather(boxes, selected_indices) 9925 }]; 9926 9927 let arguments = (ins 9928 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 2-D float tensor of shape `[num_boxes, 4]`.}]>:$boxes, 9929 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 1-D float tensor of shape `[num_boxes]` representing a single 9930score corresponding to each box (each row of boxes).}]>:$scores, 9931 Arg<TF_Int32Tensor, [{A scalar integer tensor representing the maximum number of 9932boxes to be selected by non max suppression.}]>:$max_output_size, 9933 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 0-D float tensor representing the threshold for deciding whether 9934boxes overlap too much with respect to IOU.}]>:$iou_threshold, 9935 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 0-D float tensor representing the threshold for deciding when to remove 9936boxes based on score.}]>:$score_threshold, 9937 9938 DefaultValuedAttr<BoolAttr, "false">:$pad_to_max_output_size 9939 ); 9940 9941 let results = (outs 9942 Res<TF_Int32Tensor, [{A 1-D integer tensor of shape `[M]` representing the selected 9943indices from the boxes tensor, where `M <= max_output_size`.}]>:$selected_indices, 9944 Res<TF_Int32Tensor, [{A 0-D integer tensor representing the number of valid elements in 9945`selected_indices`, with the valid elements appearing first.}]>:$valid_outputs 9946 ); 9947 9948 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 9949 TF_DerivedOperandTypeAttr T_threshold = TF_DerivedOperandTypeAttr<3>; 9950} 9951 9952def TF_NonMaxSuppressionV5Op : TF_Op<"NonMaxSuppressionV5", [NoSideEffect]> { 9953 let summary = [{ 9954Greedily selects a subset of bounding boxes in descending order of score, 9955 }]; 9956 9957 let description = [{ 9958pruning away boxes that have high intersection-over-union (IOU) overlap 9959with previously selected boxes. Bounding boxes with score less than 9960`score_threshold` are removed. Bounding boxes are supplied as 9961[y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any 9962diagonal pair of box corners and the coordinates can be provided as normalized 9963(i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm 9964is agnostic to where the origin is in the coordinate system and more 9965generally is invariant to orthogonal transformations and translations 9966of the coordinate system; thus translating or reflections of the coordinate 9967system result in the same boxes being selected by the algorithm. 9968The output of this operation is a set of integers indexing into the input 9969collection of bounding boxes representing the selected boxes. The bounding 9970box coordinates corresponding to the selected indices can then be obtained 9971using the `tf.gather operation`. For example: 9972 selected_indices = tf.image.non_max_suppression_v2( 9973 boxes, scores, max_output_size, iou_threshold, score_threshold) 9974 selected_boxes = tf.gather(boxes, selected_indices) 9975This op also supports a Soft-NMS (with Gaussian weighting) mode (c.f. 9976Bodla et al, https://arxiv.org/abs/1704.04503) where boxes reduce the score 9977of other overlapping boxes instead of directly causing them to be pruned. 9978To enable this Soft-NMS mode, set the `soft_nms_sigma` parameter to be 9979larger than 0. 9980 }]; 9981 9982 let arguments = (ins 9983 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 2-D float tensor of shape `[num_boxes, 4]`.}]>:$boxes, 9984 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 1-D float tensor of shape `[num_boxes]` representing a single 9985score corresponding to each box (each row of boxes).}]>:$scores, 9986 Arg<TF_Int32Tensor, [{A scalar integer tensor representing the maximum number of 9987boxes to be selected by non max suppression.}]>:$max_output_size, 9988 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 0-D float tensor representing the threshold for deciding whether 9989boxes overlap too much with respect to IOU.}]>:$iou_threshold, 9990 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 0-D float tensor representing the threshold for deciding when to remove 9991boxes based on score.}]>:$score_threshold, 9992 Arg<TensorOf<[TF_Float16, TF_Float32]>, [{A 0-D float tensor representing the sigma parameter for Soft NMS; see Bodla et 9993al (c.f. https://arxiv.org/abs/1704.04503). When `soft_nms_sigma=0.0` (which 9994is default), we fall back to standard (hard) NMS.}]>:$soft_nms_sigma, 9995 9996 DefaultValuedAttr<BoolAttr, "false">:$pad_to_max_output_size 9997 ); 9998 9999 let results = (outs 10000 Res<TF_Int32Tensor, [{A 1-D integer tensor of shape `[M]` representing the selected 10001indices from the boxes tensor, where `M <= max_output_size`.}]>:$selected_indices, 10002 Res<TensorOf<[TF_Float16, TF_Float32]>, [{A 1-D float tensor of shape `[M]` representing the corresponding 10003scores for each selected box, where `M <= max_output_size`. Scores only differ 10004from corresponding input scores when using Soft NMS (i.e. when 10005`soft_nms_sigma>0`)}]>:$selected_scores, 10006 Res<TF_Int32Tensor, [{A 0-D integer tensor representing the number of valid elements in 10007`selected_indices`, with the valid elements appearing first.}]>:$valid_outputs 10008 ); 10009 10010 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10011} 10012 10013def TF_NotEqualOp : TF_Op<"NotEqual", [Commutative, NoSideEffect]> { 10014 let summary = "Returns the truth value of (x != y) element-wise."; 10015 10016 let description = [{ 10017*NOTE*: `NotEqual` supports broadcasting. More about broadcasting 10018[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 10019 }]; 10020 10021 let arguments = (ins 10022 TF_Tensor:$x, 10023 TF_Tensor:$y, 10024 10025 DefaultValuedAttr<BoolAttr, "true">:$incompatible_shape_error 10026 ); 10027 10028 let results = (outs 10029 TF_BoolTensor:$z 10030 ); 10031 10032 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10033 10034 let builders = [ 10035 OpBuilder<(ins "Value":$x, "Value":$y, 10036 "BoolAttr":$incompatible_shape_error)> 10037 ]; 10038 10039 let hasVerifier = 1; 10040 10041 let hasCanonicalizer = 1; 10042} 10043 10044def TF_OneHotOp : TF_Op<"OneHot", [NoSideEffect]> { 10045 let summary = "Returns a one-hot tensor."; 10046 10047 let description = [{ 10048The locations represented by indices in `indices` take value `on_value`, 10049while all other locations take value `off_value`. 10050 10051If the input `indices` is rank `N`, the output will have rank `N+1`, 10052The new axis is created at dimension `axis` (default: the new axis is 10053appended at the end). 10054 10055If `indices` is a scalar the output shape will be a vector of length `depth`. 10056 10057If `indices` is a vector of length `features`, the output shape will be: 10058``` 10059 features x depth if axis == -1 10060 depth x features if axis == 0 10061``` 10062 10063If `indices` is a matrix (batch) with shape `[batch, features]`, 10064the output shape will be: 10065``` 10066 batch x features x depth if axis == -1 10067 batch x depth x features if axis == 1 10068 depth x batch x features if axis == 0 10069``` 10070 10071 10072Examples 10073========= 10074 10075Suppose that 10076``` 10077 indices = [0, 2, -1, 1] 10078 depth = 3 10079 on_value = 5.0 10080 off_value = 0.0 10081 axis = -1 10082``` 10083 10084Then output is `[4 x 3]`: 10085``` 10086output = 10087 [5.0 0.0 0.0] // one_hot(0) 10088 [0.0 0.0 5.0] // one_hot(2) 10089 [0.0 0.0 0.0] // one_hot(-1) 10090 [0.0 5.0 0.0] // one_hot(1) 10091``` 10092 10093Suppose that 10094``` 10095 indices = [0, 2, -1, 1] 10096 depth = 3 10097 on_value = 0.0 10098 off_value = 3.0 10099 axis = 0 10100``` 10101 10102Then output is `[3 x 4]`: 10103``` 10104output = 10105 [0.0 3.0 3.0 3.0] 10106 [3.0 3.0 3.0 0.0] 10107 [3.0 3.0 3.0 3.0] 10108 [3.0 0.0 3.0 3.0] 10109// ^ one_hot(0) 10110// ^ one_hot(2) 10111// ^ one_hot(-1) 10112// ^ one_hot(1) 10113``` 10114 10115Suppose that 10116``` 10117 indices = [[0, 2], [1, -1]] 10118 depth = 3 10119 on_value = 1.0 10120 off_value = 0.0 10121 axis = -1 10122``` 10123 10124Then output is `[2 x 2 x 3]`: 10125``` 10126output = 10127 [ 10128 [1.0, 0.0, 0.0] // one_hot(0) 10129 [0.0, 0.0, 1.0] // one_hot(2) 10130 ][ 10131 [0.0, 1.0, 0.0] // one_hot(1) 10132 [0.0, 0.0, 0.0] // one_hot(-1) 10133 ] 10134``` 10135 }]; 10136 10137 let arguments = (ins 10138 Arg<TensorOf<[TF_Int32, TF_Int64, TF_Uint8]>, [{A tensor of indices.}]>:$indices, 10139 Arg<TF_Int32Tensor, [{A scalar defining the depth of the one hot dimension.}]>:$depth, 10140 Arg<TF_Tensor, [{A scalar defining the value to fill in output when `indices[j] = i`.}]>:$on_value, 10141 Arg<TF_Tensor, [{A scalar defining the value to fill in output when `indices[j] != i`.}]>:$off_value, 10142 10143 DefaultValuedAttr<I64Attr, "-1">:$axis 10144 ); 10145 10146 let results = (outs 10147 Res<TF_Tensor, [{The one-hot tensor.}]>:$output 10148 ); 10149 10150 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 10151 TF_DerivedOperandTypeAttr TI = TF_DerivedOperandTypeAttr<0>; 10152 10153 let builders = [ 10154 OpBuilder<(ins "Value":$indices, "Value":$depth, "Value":$on_value, 10155 "Value":$off_value, "IntegerAttr":$axis)> 10156 ]; 10157 10158 let hasVerifier = 1; 10159} 10160 10161def TF_OneShotIteratorOp : TF_Op<"OneShotIterator", []> { 10162 let summary = [{ 10163Makes a "one-shot" iterator that can be iterated only once. 10164 }]; 10165 10166 let description = [{ 10167A one-shot iterator bundles the logic for defining the dataset and 10168the state of the iterator in a single op, which allows simple input 10169pipelines to be defined without an additional initialization 10170("MakeIterator") step. 10171 10172One-shot iterators have the following limitations: 10173 10174* They do not support parameterization: all logic for creating the underlying 10175 dataset must be bundled in the `dataset_factory` function. 10176* They are not resettable. Once a one-shot iterator reaches the end of its 10177 underlying dataset, subsequent "IteratorGetNext" operations on that 10178 iterator will always produce an `OutOfRange` error. 10179 10180For greater flexibility, use "Iterator" and "MakeIterator" to define 10181an iterator using an arbitrary subgraph, which may capture tensors 10182(including fed values) as parameters, and which may be reset multiple 10183times by rerunning "MakeIterator". 10184 }]; 10185 10186 let arguments = (ins 10187 SymbolRefAttr:$dataset_factory, 10188 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 10189 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 10190 DefaultValuedAttr<StrAttr, "\"\"">:$container, 10191 DefaultValuedAttr<StrAttr, "\"\"">:$shared_name 10192 ); 10193 10194 let results = (outs 10195 Res<TF_ResourceTensor, [{A handle to the iterator that can be passed to an "IteratorGetNext" 10196op.}], [TF_DatasetIteratorAlloc]>:$handle 10197 ); 10198} 10199 10200def TF_OnesLikeOp : TF_Op<"OnesLike", [Idempotent, NoSideEffect, SameOperandsAndResultType]> { 10201 let summary = "Returns a tensor of ones with the same shape and type as x."; 10202 10203 let arguments = (ins 10204 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{a tensor of type T.}]>:$x 10205 ); 10206 10207 let results = (outs 10208 Res<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{a tensor of the same shape and type as x but filled with ones.}]>:$y 10209 ); 10210 10211 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10212} 10213 10214def TF_OptimizeDatasetV2Op : TF_Op<"OptimizeDatasetV2", [NoSideEffect]> { 10215 let summary = [{ 10216Creates a dataset by applying related optimizations to `input_dataset`. 10217 }]; 10218 10219 let description = [{ 10220Creates a dataset by applying related optimizations to `input_dataset`. 10221 }]; 10222 10223 let arguments = (ins 10224 Arg<TF_VariantTensor, [{A variant tensor representing the input dataset.}]>:$input_dataset, 10225 Arg<TF_StrTensor, [{A `tf.string` vector `tf.Tensor` identifying user enabled optimizations.}]>:$optimizations_enabled, 10226 Arg<TF_StrTensor, [{A `tf.string` vector `tf.Tensor` identifying user disabled optimizations.}]>:$optimizations_disabled, 10227 Arg<TF_StrTensor, [{A `tf.string` vector `tf.Tensor` identifying optimizations by default.}]>:$optimizations_default, 10228 10229 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 10230 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 10231 DefaultValuedAttr<StrArrayAttr, "{}">:$optimization_configs 10232 ); 10233 10234 let results = (outs 10235 TF_VariantTensor:$handle 10236 ); 10237} 10238 10239def TF_OptionalFromValueOp : TF_Op<"OptionalFromValue", [NoSideEffect]> { 10240 let summary = "Constructs an Optional variant from a tuple of tensors."; 10241 10242 let arguments = (ins 10243 Variadic<TF_Tensor>:$components 10244 ); 10245 10246 let results = (outs 10247 TF_VariantTensor:$optional 10248 ); 10249 10250 TF_DerivedOperandTypeListAttr Toutput_types = TF_DerivedOperandTypeListAttr<0>; 10251} 10252 10253def TF_OptionalGetValueOp : TF_Op<"OptionalGetValue", [NoSideEffect]> { 10254 let summary = [{ 10255Returns the value stored in an Optional variant or raises an error if none exists. 10256 }]; 10257 10258 let arguments = (ins 10259 TF_VariantTensor:$optional 10260 ); 10261 10262 let results = (outs 10263 Variadic<TF_Tensor>:$components 10264 ); 10265 10266 TF_DerivedResultShapeListAttr output_shapes = TF_DerivedResultShapeListAttr<0>; 10267 TF_DerivedResultTypeListAttr output_types = TF_DerivedResultTypeListAttr<0>; 10268} 10269 10270def TF_OptionalHasValueOp : TF_Op<"OptionalHasValue", [NoSideEffect]> { 10271 let summary = [{ 10272Returns true if and only if the given Optional variant has a value. 10273 }]; 10274 10275 let arguments = (ins 10276 TF_VariantTensor:$optional 10277 ); 10278 10279 let results = (outs 10280 TF_BoolTensor:$has_value 10281 ); 10282} 10283 10284def TF_OptionalNoneOp : TF_Op<"OptionalNone", [NoSideEffect]> { 10285 let summary = "Creates an Optional variant with no value."; 10286 10287 let arguments = (ins); 10288 10289 let results = (outs 10290 TF_VariantTensor:$optional 10291 ); 10292} 10293 10294def TF_OutfeedEnqueueTupleOp : TF_Op<"OutfeedEnqueueTuple", []> { 10295 let summary = "Enqueue multiple Tensor values on the computation outfeed."; 10296 10297 let arguments = (ins 10298 Arg<Variadic<TF_Tensor>, [{A list of tensors that will be inserted into the outfeed queue as an 10299XLA tuple.}]>:$inputs 10300 ); 10301 10302 let results = (outs); 10303 10304 TF_DerivedOperandTypeListAttr dtypes = TF_DerivedOperandTypeListAttr<0>; 10305} 10306 10307def TF_PackOp : TF_Op<"Pack", [NoSideEffect]> { 10308 let summary = [{ 10309Packs a list of `N` rank-`R` tensors into one rank-`(R+1)` tensor. 10310 }]; 10311 10312 let description = [{ 10313Packs the `N` tensors in `values` into a tensor with rank one higher than each 10314tensor in `values`, by packing them along the `axis` dimension. 10315Given a list of tensors of shape `(A, B, C)`; 10316 10317if `axis == 0` then the `output` tensor will have the shape `(N, A, B, C)`. 10318if `axis == 1` then the `output` tensor will have the shape `(A, N, B, C)`. 10319Etc. 10320 10321For example: 10322 10323``` 10324# 'x' is [1, 4] 10325# 'y' is [2, 5] 10326# 'z' is [3, 6] 10327pack([x, y, z]) => [[1, 4], [2, 5], [3, 6]] # Pack along first dim. 10328pack([x, y, z], axis=1) => [[1, 2, 3], [4, 5, 6]] 10329``` 10330 10331This is the opposite of `unpack`. 10332 }]; 10333 10334 let arguments = (ins 10335 Arg<Variadic<TF_Tensor>, [{Must be of same shape and type.}]>:$values, 10336 10337 DefaultValuedAttr<I64Attr, "0">:$axis 10338 ); 10339 10340 let results = (outs 10341 Res<TF_Tensor, [{The packed tensor.}]>:$output 10342 ); 10343 10344 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 10345 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10346 10347 let hasVerifier = 1; 10348 10349 let hasCanonicalizer = 1; 10350 10351 let hasFolder = 1; 10352} 10353 10354def TF_PadOp : TF_Op<"Pad", [NoSideEffect, TF_FoldOperandsTransposeInterface, TF_OperandHasRank<1, 2>]> { 10355 let summary = "Pads a tensor with zeros."; 10356 10357 let description = [{ 10358This operation pads a `input` with zeros according to the `paddings` you 10359specify. `paddings` is an integer tensor with shape `[Dn, 2]`, where n is the 10360rank of `input`. For each dimension D of `input`, `paddings[D, 0]` indicates 10361how many zeros to add before the contents of `input` in that dimension, and 10362`paddings[D, 1]` indicates how many zeros to add after the contents of `input` 10363in that dimension. 10364 10365The padded size of each dimension D of the output is: 10366 10367`paddings(D, 0) + input.dim_size(D) + paddings(D, 1)` 10368 10369For example: 10370 10371``` 10372# 't' is [[1, 1], [2, 2]] 10373# 'paddings' is [[1, 1], [2, 2]] 10374# rank of 't' is 2 10375pad(t, paddings) ==> [[0, 0, 0, 0, 0, 0] 10376 [0, 0, 1, 1, 0, 0] 10377 [0, 0, 2, 2, 0, 0] 10378 [0, 0, 0, 0, 0, 0]] 10379``` 10380 }]; 10381 10382 let arguments = (ins 10383 TF_Tensor:$input, 10384 TF_I32OrI64Tensor:$paddings 10385 ); 10386 10387 let results = (outs 10388 TF_Tensor:$output 10389 ); 10390 10391 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10392 TF_DerivedOperandTypeAttr Tpaddings = TF_DerivedOperandTypeAttr<1>; 10393 10394 let extraClassDeclaration = [{ 10395 // TF_FoldOperandsTransposeInterface: 10396 SmallVector<unsigned, 4> GetLayoutDependentArgs() { return {0}; } 10397 SmallVector<unsigned, 4> GetLayoutDependentResults() { return {0}; } 10398 LogicalResult FoldOperandsPermutation(ArrayRef<int64_t> permutation); 10399 }]; 10400} 10401 10402def TF_PadV2Op : TF_Op<"PadV2", [NoSideEffect, TF_OperandHasRank<1, 2>]> { 10403 let summary = "Pads a tensor."; 10404 10405 let description = [{ 10406This operation pads `input` according to the `paddings` and `constant_values` 10407you specify. `paddings` is an integer tensor with shape `[Dn, 2]`, where n is 10408the rank of `input`. For each dimension D of `input`, `paddings[D, 0]` indicates 10409how many padding values to add before the contents of `input` in that dimension, 10410and `paddings[D, 1]` indicates how many padding values to add after the contents 10411of `input` in that dimension. `constant_values` is a scalar tensor of the same 10412type as `input` that indicates the value to use for padding `input`. 10413 10414The padded size of each dimension D of the output is: 10415 10416`paddings(D, 0) + input.dim_size(D) + paddings(D, 1)` 10417 10418For example: 10419 10420``` 10421# 't' is [[1, 1], [2, 2]] 10422# 'paddings' is [[1, 1], [2, 2]] 10423# 'constant_values' is 0 10424# rank of 't' is 2 10425pad(t, paddings) ==> [[0, 0, 0, 0, 0, 0] 10426 [0, 0, 1, 1, 0, 0] 10427 [0, 0, 2, 2, 0, 0] 10428 [0, 0, 0, 0, 0, 0]] 10429``` 10430 }]; 10431 10432 let arguments = (ins 10433 TF_Tensor:$input, 10434 TF_I32OrI64Tensor:$paddings, 10435 TF_Tensor:$constant_values 10436 ); 10437 10438 let results = (outs 10439 TF_Tensor:$output 10440 ); 10441 10442 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10443 TF_DerivedOperandTypeAttr Tpaddings = TF_DerivedOperandTypeAttr<1>; 10444} 10445 10446def TF_ParallelDynamicStitchOp : TF_Op<"ParallelDynamicStitch", [NoSideEffect, SameVariadicOperandSize]> { 10447 let summary = [{ 10448Interleave the values from the `data` tensors into a single tensor. 10449 }]; 10450 10451 let description = [{ 10452Builds a merged tensor such that 10453 10454```python 10455 merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...] 10456``` 10457 10458For example, if each `indices[m]` is scalar or vector, we have 10459 10460```python 10461 # Scalar indices: 10462 merged[indices[m], ...] = data[m][...] 10463 10464 # Vector indices: 10465 merged[indices[m][i], ...] = data[m][i, ...] 10466``` 10467 10468Each `data[i].shape` must start with the corresponding `indices[i].shape`, 10469and the rest of `data[i].shape` must be constant w.r.t. `i`. That is, we 10470must have `data[i].shape = indices[i].shape + constant`. In terms of this 10471`constant`, the output shape is 10472 10473 merged.shape = [max(indices)] + constant 10474 10475Values may be merged in parallel, so if an index appears in both `indices[m][i]` 10476and `indices[n][j]`, the result may be invalid. This differs from the normal 10477DynamicStitch operator that defines the behavior in that case. 10478 10479For example: 10480 10481```python 10482 indices[0] = 6 10483 indices[1] = [4, 1] 10484 indices[2] = [[5, 2], [0, 3]] 10485 data[0] = [61, 62] 10486 data[1] = [[41, 42], [11, 12]] 10487 data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]] 10488 merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42], 10489 [51, 52], [61, 62]] 10490``` 10491 10492This method can be used to merge partitions created by `dynamic_partition` 10493as illustrated on the following example: 10494 10495```python 10496 # Apply function (increments x_i) on elements for which a certain condition 10497 # apply (x_i != -1 in this example). 10498 x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4]) 10499 condition_mask=tf.not_equal(x,tf.constant(-1.)) 10500 partitioned_data = tf.dynamic_partition( 10501 x, tf.cast(condition_mask, tf.int32) , 2) 10502 partitioned_data[1] = partitioned_data[1] + 1.0 10503 condition_indices = tf.dynamic_partition( 10504 tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2) 10505 x = tf.dynamic_stitch(condition_indices, partitioned_data) 10506 # Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain 10507 # unchanged. 10508``` 10509 10510<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 10511<img style="width:100%" src="https://www.tensorflow.org/images/DynamicStitch.png" alt> 10512</div> 10513 }]; 10514 10515 let arguments = (ins 10516 Variadic<TF_Int32Tensor>:$indices, 10517 Variadic<TF_Tensor>:$data 10518 ); 10519 10520 let results = (outs 10521 TF_Tensor:$merged 10522 ); 10523 10524 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 10525 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 10526} 10527 10528def TF_ParallelMapDatasetOp : TF_Op<"ParallelMapDataset", [NoSideEffect]> { 10529 let summary = [{ 10530Creates a dataset that applies `f` to the outputs of `input_dataset`. 10531 }]; 10532 10533 let description = [{ 10534Unlike a "MapDataset", which applies `f` sequentially, this dataset invokes up 10535to `num_parallel_calls` copies of `f` in parallel. 10536 }]; 10537 10538 let arguments = (ins 10539 TF_VariantTensor:$input_dataset, 10540 Variadic<TF_Tensor>:$other_arguments, 10541 Arg<TF_Int32Tensor, [{The number of concurrent invocations of `f` that process 10542elements from `input_dataset` in parallel.}]>:$num_parallel_calls, 10543 10544 SymbolRefAttr:$f, 10545 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 10546 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 10547 DefaultValuedAttr<BoolAttr, "true">:$use_inter_op_parallelism, 10548 DefaultValuedAttr<BoolAttr, "false">:$sloppy, 10549 DefaultValuedAttr<BoolAttr, "false">:$preserve_cardinality, 10550 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 10551 ); 10552 10553 let results = (outs 10554 TF_VariantTensor:$handle 10555 ); 10556 10557 TF_DerivedOperandTypeListAttr Targuments = TF_DerivedOperandTypeListAttr<1>; 10558} 10559 10560def TF_ParallelMapDatasetV2Op : TF_Op<"ParallelMapDatasetV2", [NoSideEffect]> { 10561 let summary = [{ 10562Creates a dataset that applies `f` to the outputs of `input_dataset`. 10563 }]; 10564 10565 let description = [{ 10566Unlike a "MapDataset", which applies `f` sequentially, this dataset invokes up 10567to `num_parallel_calls` copies of `f` in parallel. 10568 }]; 10569 10570 let arguments = (ins 10571 TF_VariantTensor:$input_dataset, 10572 Variadic<TF_Tensor>:$other_arguments, 10573 Arg<TF_Int64Tensor, [{The number of concurrent invocations of `f` that process 10574elements from `input_dataset` in parallel.}]>:$num_parallel_calls, 10575 10576 SymbolRefAttr:$f, 10577 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 10578 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 10579 DefaultValuedAttr<BoolAttr, "true">:$use_inter_op_parallelism, 10580 DefaultValuedAttr<StrAttr, "\"default\"">:$deterministic, 10581 DefaultValuedAttr<BoolAttr, "false">:$preserve_cardinality, 10582 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 10583 ); 10584 10585 let results = (outs 10586 TF_VariantTensor:$handle 10587 ); 10588 10589 TF_DerivedOperandTypeListAttr Targuments = TF_DerivedOperandTypeListAttr<1>; 10590} 10591 10592def TF_ParameterizedTruncatedNormalOp : TF_Op<"ParameterizedTruncatedNormal", [TF_CannotDuplicate]> { 10593 let summary = [{ 10594Outputs random values from a normal distribution. The parameters may each be a 10595 }]; 10596 10597 let description = [{ 10598scalar which applies to the entire output, or a vector of length shape[0] which 10599stores the parameters for each batch. 10600 }]; 10601 10602 let arguments = (ins 10603 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor. Batches are indexed by the 0th dimension.}]>:$shape, 10604 Arg<TF_FloatTensor, [{The mean parameter of each batch.}]>:$means, 10605 Arg<TF_FloatTensor, [{The standard deviation parameter of each batch. Must be greater than 0.}]>:$stdevs, 10606 Arg<TF_FloatTensor, [{The minimum cutoff. May be -infinity.}]>:$minvals, 10607 Arg<TF_FloatTensor, [{The maximum cutoff. May be +infinity, and must be more than the minval 10608for each batch.}]>:$maxvals, 10609 10610 DefaultValuedAttr<I64Attr, "0">:$seed, 10611 DefaultValuedAttr<I64Attr, "0">:$seed2 10612 ); 10613 10614 let results = (outs 10615 Res<TF_FloatTensor, [{A matrix of shape num_batches x samples_per_batch, filled with random 10616truncated normal values using the parameters for each row.}]>:$output 10617 ); 10618 10619 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10620 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<1>; 10621} 10622 10623def TF_PartitionedCallOp : TF_Op<"PartitionedCall", [CallOpInterface, NoSideEffect, SymbolUserOpInterface]> { 10624 let summary = [{ 10625returns `f(inputs)`, where `f`'s body is placed and partitioned. 10626 }]; 10627 10628 let description = [{ 10629Asynchronously executes a function, potentially across multiple devices but 10630within a single process. The kernel places and partitions a given function's 10631underlying graph, and executes each of the partitioned subgraphs as a function. 10632 }]; 10633 10634 let arguments = (ins 10635 Arg<Variadic<TF_Tensor>, [{A list of input tensors.}]>:$args, 10636 10637 SymbolRefAttr:$f, 10638 DefaultValuedAttr<StrAttr, "\"\"">:$config, 10639 DefaultValuedAttr<StrAttr, "\"\"">:$config_proto, 10640 DefaultValuedAttr<StrAttr, "\"\"">:$executor_type 10641 ); 10642 10643 let results = (outs 10644 Res<Variadic<TF_Tensor>, [{A list of return values.}]>:$output 10645 ); 10646 10647 TF_DerivedOperandTypeListAttr Tin = TF_DerivedOperandTypeListAttr<0>; 10648 TF_DerivedResultTypeListAttr Tout = TF_DerivedResultTypeListAttr<0>; 10649 10650 let extraClassDeclaration = [{ 10651 // Gets the argument operands to the called function. 10652 operand_range getArgOperands() { return args(); } 10653 10654 // Returns the callee of this operation. 10655 CallInterfaceCallable getCallableForCallee() { return fAttr(); } 10656 10657 // returns the callee of this operation. 10658 func::FuncOp func() { 10659 return SymbolTable::lookupNearestSymbolFrom<func::FuncOp>(*this, f()); 10660 } 10661 10662 // SymbolUserOpInterface verifier. 10663 LogicalResult verifySymbolUses(SymbolTableCollection &symbolTable); 10664 }]; 10665} 10666 10667def TF_PolygammaOp : TF_Op<"Polygamma", [NoSideEffect, ResultsBroadcastableShape]>, 10668 WithBroadcastableBinOpBuilder { 10669 let summary = [{ 10670Compute the polygamma function \\(\psi^{(n)}(x)\\). 10671 }]; 10672 10673 let description = [{ 10674The polygamma function is defined as: 10675 10676 10677\\(\psi^{(a)}(x) = \frac{d^a}{dx^a} \psi(x)\\) 10678 10679where \\(\psi(x)\\) is the digamma function. 10680The polygamma function is defined only for non-negative integer orders \\a\\. 10681 }]; 10682 10683 let arguments = (ins 10684 TF_F32OrF64Tensor:$a, 10685 TF_F32OrF64Tensor:$x 10686 ); 10687 10688 let results = (outs 10689 TF_F32OrF64Tensor:$z 10690 ); 10691 10692 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10693} 10694 10695def TF_PopulationCountOp : TF_Op<"PopulationCount", [NoSideEffect, SameOperandsAndResultShape]> { 10696 let summary = [{ 10697Computes element-wise population count (a.k.a. popcount, bitsum, bitcount). 10698 }]; 10699 10700 let description = [{ 10701For each entry in `x`, calculates the number of `1` (on) bits in the binary 10702representation of that entry. 10703 10704**NOTE**: It is more efficient to first `tf.bitcast` your tensors into 10705`int32` or `int64` and perform the bitcount on the result, than to feed in 107068- or 16-bit inputs and then aggregate the resulting counts. 10707 }]; 10708 10709 let arguments = (ins 10710 TF_IntTensor:$x 10711 ); 10712 10713 let results = (outs 10714 TF_Uint8Tensor:$y 10715 ); 10716 10717 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10718} 10719 10720def TF_PowOp : TF_Op<"Pow", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 10721 WithBroadcastableBinOpBuilder { 10722 let summary = "Computes the power of one value to another."; 10723 10724 let description = [{ 10725Given a tensor `x` and a tensor `y`, this operation computes \\(x^y\\) for 10726corresponding elements in `x` and `y`. For example: 10727 10728``` 10729# tensor 'x' is [[2, 2]], [3, 3]] 10730# tensor 'y' is [[8, 16], [2, 3]] 10731tf.pow(x, y) ==> [[256, 65536], [9, 27]] 10732``` 10733 }]; 10734 10735 let arguments = (ins 10736 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x, 10737 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 10738 ); 10739 10740 let results = (outs 10741 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$z 10742 ); 10743 10744 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10745 10746 let hasFolder = 1; 10747} 10748 10749def TF_PrefetchDatasetOp : TF_Op<"PrefetchDataset", [NoSideEffect]> { 10750 let summary = [{ 10751Creates a dataset that asynchronously prefetches elements from `input_dataset`. 10752 }]; 10753 10754 let arguments = (ins 10755 TF_VariantTensor:$input_dataset, 10756 Arg<TF_Int64Tensor, [{The maximum number of elements to buffer in an iterator over 10757this dataset.}]>:$buffer_size, 10758 10759 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 10760 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 10761 DefaultValuedAttr<I64Attr, "0">:$slack_period, 10762 DefaultValuedAttr<BoolAttr, "true">:$legacy_autotune, 10763 DefaultValuedAttr<I64Attr, "0">:$buffer_size_min, 10764 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 10765 ); 10766 10767 let results = (outs 10768 TF_VariantTensor:$handle 10769 ); 10770} 10771 10772def TF_PreventGradientOp : TF_Op<"PreventGradient", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 10773 let summary = [{ 10774An identity op that triggers an error if a gradient is requested. 10775 }]; 10776 10777 let description = [{ 10778When executed in a graph, this op outputs its input tensor as-is. 10779 10780When building ops to compute gradients, the TensorFlow gradient system 10781will return an error when trying to lookup the gradient of this op, 10782because no gradient must ever be registered for this function. This 10783op exists to prevent subtle bugs from silently returning unimplemented 10784gradients in some corner cases. 10785 }]; 10786 10787 let arguments = (ins 10788 Arg<TF_Tensor, [{any tensor.}]>:$input, 10789 10790 DefaultValuedAttr<StrAttr, "\"\"">:$message 10791 ); 10792 10793 let results = (outs 10794 Res<TF_Tensor, [{the same input tensor.}]>:$output 10795 ); 10796 10797 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10798} 10799 10800def TF_PrintOp : TF_Op<"Print", []> { 10801 let summary = "Prints a list of tensors."; 10802 10803 let description = [{ 10804Passes `input` through to `output` and prints `data` when evaluating. 10805 }]; 10806 10807 let arguments = (ins 10808 Arg<TF_Tensor, [{The tensor passed to `output`}]>:$input, 10809 Arg<Variadic<TF_Tensor>, [{A list of tensors to print out when op is evaluated.}]>:$data, 10810 10811 DefaultValuedAttr<StrAttr, "\"\"">:$message, 10812 DefaultValuedAttr<I64Attr, "-1">:$first_n, 10813 DefaultValuedAttr<I64Attr, "3">:$summarize 10814 ); 10815 10816 let results = (outs 10817 Res<TF_Tensor, [{The unmodified `input` tensor}]>:$output 10818 ); 10819 10820 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10821 TF_DerivedOperandTypeListAttr U = TF_DerivedOperandTypeListAttr<1>; 10822} 10823 10824def TF_PrintV2Op : TF_Op<"PrintV2", []> { 10825 let summary = "Prints a string scalar."; 10826 10827 let description = [{ 10828Prints a string scalar to the desired output_stream. 10829 }]; 10830 10831 let arguments = (ins 10832 Arg<TF_StrTensor, [{The string scalar to print.}]>:$input, 10833 10834 DefaultValuedAttr<StrAttr, "\"stderr\"">:$output_stream, 10835 DefaultValuedAttr<StrAttr, "\"\\n\"">:$end 10836 ); 10837 10838 let results = (outs); 10839} 10840 10841def TF_ProdOp : TF_Op<"Prod", [NoSideEffect]> { 10842 let summary = [{ 10843Computes the product of elements across dimensions of a tensor. 10844 }]; 10845 10846 let description = [{ 10847Reduces `input` along the dimensions given in `axis`. Unless 10848`keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in 10849`axis`. If `keep_dims` is true, the reduced dimensions are 10850retained with length 1. 10851 }]; 10852 10853 let arguments = (ins 10854 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The tensor to reduce.}]>:$input, 10855 Arg<TF_I32OrI64Tensor, [{The dimensions to reduce. Must be in the range 10856`[-rank(input), rank(input))`.}]>:$reduction_indices, 10857 10858 DefaultValuedAttr<BoolAttr, "false">:$keep_dims 10859 ); 10860 10861 let results = (outs 10862 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The reduced tensor.}]>:$output 10863 ); 10864 10865 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10866 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 10867} 10868 10869def TF_QrOp : TF_Op<"Qr", [NoSideEffect]> { 10870 let summary = "Computes the QR decompositions of one or more matrices."; 10871 10872 let description = [{ 10873Computes the QR decomposition of each inner matrix in `tensor` such that 10874`tensor[..., :, :] = q[..., :, :] * r[..., :,:])` 10875 10876Currently, the gradient for the QR decomposition is well-defined only when 10877the first `P` columns of the inner matrix are linearly independent, where 10878`P` is the minimum of `M` and `N`, the 2 inner-most dimmensions of `tensor`. 10879 10880```python 10881# a is a tensor. 10882# q is a tensor of orthonormal matrices. 10883# r is a tensor of upper triangular matrices. 10884q, r = qr(a) 10885q_full, r_full = qr(a, full_matrices=True) 10886``` 10887 }]; 10888 10889 let arguments = (ins 10890 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{A tensor of shape `[..., M, N]` whose inner-most 2 dimensions 10891form matrices of size `[M, N]`. Let `P` be the minimum of `M` and `N`.}]>:$input, 10892 10893 DefaultValuedAttr<BoolAttr, "false">:$full_matrices 10894 ); 10895 10896 let results = (outs 10897 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Orthonormal basis for range of `a`. If `full_matrices` is `False` then 10898shape is `[..., M, P]`; if `full_matrices` is `True` then shape is 10899`[..., M, M]`.}]>:$q, 10900 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Triangular factor. If `full_matrices` is `False` then shape is 10901`[..., P, N]`. If `full_matrices` is `True` then shape is `[..., M, N]`.}]>:$r 10902 ); 10903 10904 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10905 10906 let hasVerifier = 1; 10907} 10908 10909def TF_QuantizeAndDequantizeOp : TF_Op<"QuantizeAndDequantize", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 10910 let summary = "Use QuantizeAndDequantizeV2 instead."; 10911 10912 let arguments = (ins 10913 TF_FloatTensor:$input, 10914 10915 DefaultValuedAttr<BoolAttr, "true">:$signed_input, 10916 DefaultValuedAttr<I64Attr, "8">:$num_bits, 10917 DefaultValuedAttr<BoolAttr, "false">:$range_given, 10918 DefaultValuedAttr<F32Attr, "0.0f">:$input_min, 10919 DefaultValuedAttr<F32Attr, "0.0f">:$input_max 10920 ); 10921 10922 let results = (outs 10923 TF_FloatTensor:$output 10924 ); 10925 10926 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 10927} 10928 10929def TF_QuantizeAndDequantizeV2Op : TF_Op<"QuantizeAndDequantizeV2", [NoSideEffect]> { 10930 let summary = "Quantizes then dequantizes a tensor."; 10931 10932 let description = [{ 10933This op simulates the precision loss from the quantized forward pass by: 10934 109351. Quantizing the tensor to fixed point numbers, which should match the target 10936 quantization method when it is used in inference. 109372. Dequantizing it back to floating point numbers for the following ops, most 10938 likely matmul. 10939 10940There are different ways to quantize. This version uses only scaling, so 0.0 10941maps to 0. 10942 10943From the specified 'num_bits' in the quantized output type, it determines 10944minimum and maximum representable quantized values. 10945 10946e.g. 10947 10948* [-128, 127] for signed, num_bits = 8, or 10949* [0, 255] for unsigned, num_bits = 8. 10950 10951If range_given == False, the initial input_min, input_max will be determined 10952automatically as the minimum and maximum values in the input tensor, otherwise 10953the specified values of input_min, input_max are used. 10954 10955Note: If the input_min, input_max are specified, they do not need to equal the 10956actual minimum and maximum values in the tensor. e.g. in some cases it may be 10957beneficial to specify these values such that the low probability extremes of the 10958input distribution are clipped. 10959 10960This op determines the maximum scale_factor that would map the initial 10961[input_min, input_max] range to a range that lies within the representable 10962quantized range. 10963 10964It determines the scale from one of input_min and input_max, then updates the 10965other one to maximize the representable range. 10966 10967e.g. 10968 10969* if the output is signed, num_bits = 8, [input_min, input_max] = [-10.0, 10970 5.0]: it would use a scale_factor of -128 / -10.0 = 12.8 In this case, it 10971 would update input_max to be 127 / 12.8 = 9.921875 10972* if the output is signed, num_bits = 8, [input_min, input_max] = [-10.0, 10973 10.0]: it would use a scale_factor of 127 / 10.0 = 12.7 In this case, it 10974 would update input_min to be 128.0 / 12.7 = -10.07874 10975* if the output is unsigned, input_min is forced to be 0, and only the 10976 specified input_max is used. 10977 10978After determining the scale_factor and updating the input range, it applies the 10979following to each value in the 'input' tensor. 10980 10981output = round(clamp(value, input_min, input_max) * scale_factor) / scale_factor. 10982 10983The above round function rounds the value based on the given round_mode. 10984 }]; 10985 10986 let arguments = (ins 10987 Arg<TF_FloatTensor, [{Tensor to quantize and then dequantize.}]>:$input, 10988 Arg<TF_FloatTensor, [{If `range_given == True`, this specifies the minimum input value that needs to 10989be represented, otherwise it is determined from the min value of the `input` 10990tensor.}]>:$input_min, 10991 Arg<TF_FloatTensor, [{If `range_given == True`, this specifies the maximum input value that needs to 10992be represented, otherwise it is determined from the max value of the `input` 10993tensor.}]>:$input_max, 10994 10995 DefaultValuedAttr<BoolAttr, "true">:$signed_input, 10996 DefaultValuedAttr<I64Attr, "8">:$num_bits, 10997 DefaultValuedAttr<BoolAttr, "false">:$range_given, 10998 DefaultValuedAttr<TF_AnyStrAttrOf<["HALF_TO_EVEN", "HALF_UP"]>, "\"HALF_TO_EVEN\"">:$round_mode, 10999 DefaultValuedAttr<BoolAttr, "false">:$narrow_range, 11000 DefaultValuedAttr<I64Attr, "-1">:$axis 11001 ); 11002 11003 let results = (outs 11004 TF_FloatTensor:$output 11005 ); 11006 11007 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11008 11009 let hasCanonicalizer = 1; 11010} 11011 11012def TF_QuantizeAndDequantizeV3Op : TF_Op<"QuantizeAndDequantizeV3", [NoSideEffect]> { 11013 let summary = "Quantizes then dequantizes a tensor."; 11014 11015 let description = [{ 11016This is almost identical to QuantizeAndDequantizeV2, except that num_bits is a 11017tensor, so its value can change during training. 11018 }]; 11019 11020 let arguments = (ins 11021 TF_FloatTensor:$input, 11022 TF_FloatTensor:$input_min, 11023 TF_FloatTensor:$input_max, 11024 TF_Int32Tensor:$num_bits, 11025 11026 DefaultValuedAttr<BoolAttr, "true">:$signed_input, 11027 DefaultValuedAttr<BoolAttr, "true">:$range_given, 11028 DefaultValuedAttr<BoolAttr, "false">:$narrow_range, 11029 DefaultValuedAttr<I64Attr, "-1">:$axis 11030 ); 11031 11032 let results = (outs 11033 TF_FloatTensor:$output 11034 ); 11035 11036 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11037} 11038 11039def TF_QuantizeAndDequantizeV4Op : TF_Op<"QuantizeAndDequantizeV4", [NoSideEffect]> { 11040 let summary = "Quantizes then dequantizes a tensor."; 11041 11042 let description = [{ 11043This is almost identical to QuantizeAndDequantizeV2, except that it returns a 11044gradient of 1 for inputs that are within the quantization range, or 0 otherwise. 11045 }]; 11046 11047 let arguments = (ins 11048 Arg<TF_FloatTensor, [{Tensor to quantize and then dequantize.}]>:$input, 11049 Arg<TF_FloatTensor, [{If `range_given == True`, this specifies the minimum input value that needs to 11050be represented, otherwise it is determined from the min value of the `input` 11051tensor.}]>:$input_min, 11052 Arg<TF_FloatTensor, [{If `range_given == True`, this specifies the maximum input value that needs to 11053be represented, otherwise it is determined from the max value of the `input` 11054tensor.}]>:$input_max, 11055 11056 DefaultValuedAttr<BoolAttr, "true">:$signed_input, 11057 DefaultValuedAttr<I64Attr, "8">:$num_bits, 11058 DefaultValuedAttr<BoolAttr, "false">:$range_given, 11059 DefaultValuedAttr<TF_AnyStrAttrOf<["HALF_TO_EVEN", "HALF_UP"]>, "\"HALF_TO_EVEN\"">:$round_mode, 11060 DefaultValuedAttr<BoolAttr, "false">:$narrow_range, 11061 DefaultValuedAttr<I64Attr, "-1">:$axis 11062 ); 11063 11064 let results = (outs 11065 TF_FloatTensor:$output 11066 ); 11067 11068 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11069} 11070 11071def TF_QuantizeV2Op : TF_Op<"QuantizeV2", [NoSideEffect]> { 11072 let summary = [{ 11073Quantize the 'input' tensor of type float to 'output' tensor of type 'T'. 11074 }]; 11075 11076 let description = [{ 11077[min_range, max_range] are scalar floats that specify the range for 11078the 'input' data. The 'mode' attribute controls exactly which calculations are 11079used to convert the float values to their quantized equivalents. The 11080'round_mode' attribute controls which rounding tie-breaking algorithm is used 11081when rounding float values to their quantized equivalents. 11082 11083In 'MIN_COMBINED' mode, each value of the tensor will undergo the following: 11084 11085``` 11086out[i] = (in[i] - min_range) * range(T) / (max_range - min_range) 11087if T == qint8: out[i] -= (range(T) + 1) / 2.0 11088``` 11089 11090here `range(T) = numeric_limits<T>::max() - numeric_limits<T>::min()` 11091 11092*MIN_COMBINED Mode Example* 11093 11094Assume the input is type float and has a possible range of [0.0, 6.0] and the 11095output type is quint8 ([0, 255]). The min_range and max_range values should be 11096specified as 0.0 and 6.0. Quantizing from float to quint8 will multiply each 11097value of the input by 255/6 and cast to quint8. 11098 11099If the output type was qint8 ([-128, 127]), the operation will additionally 11100subtract each value by 128 prior to casting, so that the range of values aligns 11101with the range of qint8. 11102 11103If the mode is 'MIN_FIRST', then this approach is used: 11104 11105``` 11106num_discrete_values = 1 << (# of bits in T) 11107range_adjust = num_discrete_values / (num_discrete_values - 1) 11108range = (range_max - range_min) * range_adjust 11109range_scale = num_discrete_values / range 11110quantized = round(input * range_scale) - round(range_min * range_scale) + 11111 numeric_limits<T>::min() 11112quantized = max(quantized, numeric_limits<T>::min()) 11113quantized = min(quantized, numeric_limits<T>::max()) 11114``` 11115 11116The biggest difference between this and MIN_COMBINED is that the minimum range 11117is rounded first, before it's subtracted from the rounded value. With 11118MIN_COMBINED, a small bias is introduced where repeated iterations of quantizing 11119and dequantizing will introduce a larger and larger error. 11120 11121*SCALED mode Example* 11122 11123`SCALED` mode matches the quantization approach used in 11124`QuantizeAndDequantize{V2|V3}`. 11125 11126If the mode is `SCALED`, the quantization is performed by multiplying each 11127input value by a scaling_factor. 11128The scaling_factor is determined from `min_range` and `max_range` to be as large 11129as possible such that the range from `min_range` to `max_range` is representable 11130within values of type T. 11131 11132```c++ 11133 11134 const int min_T = std::numeric_limits<T>::min(); 11135 const int max_T = std::numeric_limits<T>::max(); 11136 const float max_float = std::numeric_limits<float>::max(); 11137 11138 const float scale_factor_from_min_side = 11139 (min_T * min_range > 0) ? min_T / min_range : max_float; 11140 const float scale_factor_from_max_side = 11141 (max_T * max_range > 0) ? max_T / max_range : max_float; 11142 11143 const float scale_factor = std::min(scale_factor_from_min_side, 11144 scale_factor_from_max_side); 11145``` 11146 11147We next use the scale_factor to adjust min_range and max_range as follows: 11148 11149```c++ 11150 min_range = min_T / scale_factor; 11151 max_range = max_T / scale_factor; 11152``` 11153 11154 11155e.g. if T = qint8, and initially min_range = -10, and max_range = 9, we would 11156compare -128/-10.0 = 12.8 to 127/9.0 = 14.11, and set scaling_factor = 12.8 11157In this case, min_range would remain -10, but max_range would be adjusted to 11158127 / 12.8 = 9.921875 11159 11160So we will quantize input values in the range (-10, 9.921875) to (-128, 127). 11161 11162The input tensor can now be quantized by clipping values to the range 11163`min_range` to `max_range`, then multiplying by scale_factor as follows: 11164 11165```c++ 11166result = round(min(max_range, max(min_range, input)) * scale_factor) 11167``` 11168 11169The adjusted `min_range` and `max_range` are returned as outputs 2 and 3 of 11170this operation. These outputs should be used as the range for any further 11171calculations. 11172 11173 11174*narrow_range (bool) attribute* 11175 11176If true, we do not use the minimum quantized value. 11177i.e. for int8 the quantized output, it would be restricted to the range 11178-127..127 instead of the full -128..127 range. 11179This is provided for compatibility with certain inference backends. 11180(Only applies to SCALED mode) 11181 11182 11183*axis (int) attribute* 11184 11185An optional `axis` attribute can specify a dimension index of the input tensor, 11186such that quantization ranges will be calculated and applied separately for each 11187slice of the tensor along that dimension. This is useful for per-channel 11188quantization. 11189 11190If axis is specified, min_range and max_range 11191 11192if `axis`=None, per-tensor quantization is performed as normal. 11193 11194 11195*ensure_minimum_range (float) attribute* 11196 11197Ensures the minimum quantization range is at least this value. 11198The legacy default value for this is 0.01, but it is strongly suggested to 11199set it to 0 for new uses. 11200 }]; 11201 11202 let arguments = (ins 11203 TF_Float32Tensor:$input, 11204 Arg<TF_Float32Tensor, [{The minimum value of the quantization range. This value may be adjusted by the 11205op depending on other parameters. The adjusted value is written to `output_min`. 11206If the `axis` attribute is specified, this must be a 1-D tensor whose size 11207matches the `axis` dimension of the input and output tensors.}]>:$min_range, 11208 Arg<TF_Float32Tensor, [{The maximum value of the quantization range. This value may be adjusted by the 11209op depending on other parameters. The adjusted value is written to `output_max`. 11210If the `axis` attribute is specified, this must be a 1-D tensor whose size 11211matches the `axis` dimension of the input and output tensors.}]>:$max_range, 11212 11213 DefaultValuedAttr<TF_AnyStrAttrOf<["MIN_COMBINED", "MIN_FIRST", "SCALED"]>, "\"MIN_COMBINED\"">:$mode, 11214 DefaultValuedAttr<TF_AnyStrAttrOf<["HALF_AWAY_FROM_ZERO", "HALF_TO_EVEN"]>, "\"HALF_AWAY_FROM_ZERO\"">:$round_mode, 11215 DefaultValuedAttr<BoolAttr, "false">:$narrow_range, 11216 DefaultValuedAttr<I64Attr, "-1">:$axis, 11217 DefaultValuedAttr<F32Attr, "0.01f">:$ensure_minimum_range 11218 ); 11219 11220 let results = (outs 11221 Res<TensorOf<[TF_Qint16, TF_Qint32, TF_Qint8, TF_Quint16, TF_Quint8]>, [{The quantized data produced from the float input.}]>:$output, 11222 Res<TF_Float32Tensor, [{The final quantization range minimum, used to clip input values before scaling 11223and rounding them to quantized values. 11224If the `axis` attribute is specified, this will be a 1-D tensor whose size 11225matches the `axis` dimension of the input and output tensors.}]>:$output_min, 11226 Res<TF_Float32Tensor, [{The final quantization range maximum, used to clip input values before scaling 11227and rounding them to quantized values. 11228If the `axis` attribute is specified, this will be a 1-D tensor whose size 11229matches the `axis` dimension of the input and output tensors.}]>:$output_max 11230 ); 11231 11232 TF_DerivedResultTypeAttr T = TF_DerivedResultTypeAttr<0>; 11233} 11234 11235def TF_QueueDequeueV2Op : TF_Op<"QueueDequeueV2", []> { 11236 let summary = "Dequeues a tuple of one or more tensors from the given queue."; 11237 11238 let description = [{ 11239This operation has k outputs, where k is the number of components 11240in the tuples stored in the given queue, and output i is the ith 11241component of the dequeued tuple. 11242 11243N.B. If the queue is empty, this operation will block until an element 11244has been dequeued (or 'timeout_ms' elapses, if specified). 11245 }]; 11246 11247 let arguments = (ins 11248 Arg<TF_ResourceTensor, [{The handle to a queue.}]>:$handle, 11249 11250 DefaultValuedAttr<I64Attr, "-1">:$timeout_ms 11251 ); 11252 11253 let results = (outs 11254 Res<Variadic<TF_Tensor>, [{One or more tensors that were dequeued as a tuple.}]>:$components 11255 ); 11256 11257 TF_DerivedResultTypeListAttr component_types = TF_DerivedResultTypeListAttr<0>; 11258} 11259 11260def TF_RFFTOp : TF_Op<"RFFT", [NoSideEffect]> { 11261 let summary = "Real-valued fast Fourier transform."; 11262 11263 let description = [{ 11264Computes the 1-dimensional discrete Fourier transform of a real-valued signal 11265over the inner-most dimension of `input`. 11266 11267Since the DFT of a real signal is Hermitian-symmetric, `RFFT` only returns the 11268`fft_length / 2 + 1` unique components of the FFT: the zero-frequency term, 11269followed by the `fft_length / 2` positive-frequency terms. 11270 11271Along the axis `RFFT` is computed on, if `fft_length` is smaller than the 11272corresponding dimension of `input`, the dimension is cropped. If it is larger, 11273the dimension is padded with zeros. 11274 }]; 11275 11276 let arguments = (ins 11277 Arg<TF_F32OrF64Tensor, [{A float32 tensor.}]>:$input, 11278 Arg<TF_Int32Tensor, [{An int32 tensor of shape [1]. The FFT length.}]>:$fft_length 11279 ); 11280 11281 let results = (outs 11282 Res<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex64 tensor of the same rank as `input`. The inner-most 11283 dimension of `input` is replaced with the `fft_length / 2 + 1` unique 11284 frequency components of its 1D Fourier transform. 11285 11286@compatibility(numpy) 11287Equivalent to np.fft.rfft 11288@end_compatibility}]>:$output 11289 ); 11290 11291 TF_DerivedOperandTypeAttr Treal = TF_DerivedOperandTypeAttr<0>; 11292 TF_DerivedResultTypeAttr Tcomplex = TF_DerivedResultTypeAttr<0>; 11293} 11294 11295def TF_RFFT2DOp : TF_Op<"RFFT2D", [NoSideEffect]> { 11296 let summary = "2D real-valued fast Fourier transform."; 11297 11298 let description = [{ 11299Computes the 2-dimensional discrete Fourier transform of a real-valued signal 11300over the inner-most 2 dimensions of `input`. 11301 11302Since the DFT of a real signal is Hermitian-symmetric, `RFFT2D` only returns the 11303`fft_length / 2 + 1` unique components of the FFT for the inner-most dimension 11304of `output`: the zero-frequency term, followed by the `fft_length / 2` 11305positive-frequency terms. 11306 11307Along each axis `RFFT2D` is computed on, if `fft_length` is smaller than the 11308corresponding dimension of `input`, the dimension is cropped. If it is larger, 11309the dimension is padded with zeros. 11310 }]; 11311 11312 let arguments = (ins 11313 Arg<TF_F32OrF64Tensor, [{A float32 tensor.}]>:$input, 11314 Arg<TF_Int32Tensor, [{An int32 tensor of shape [2]. The FFT length for each dimension.}]>:$fft_length 11315 ); 11316 11317 let results = (outs 11318 Res<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex64 tensor of the same rank as `input`. The inner-most 2 11319 dimensions of `input` are replaced with their 2D Fourier transform. The 11320 inner-most dimension contains `fft_length / 2 + 1` unique frequency 11321 components. 11322 11323@compatibility(numpy) 11324Equivalent to np.fft.rfft2 11325@end_compatibility}]>:$output 11326 ); 11327 11328 TF_DerivedOperandTypeAttr Treal = TF_DerivedOperandTypeAttr<0>; 11329 TF_DerivedResultTypeAttr Tcomplex = TF_DerivedResultTypeAttr<0>; 11330} 11331 11332def TF_RFFT3DOp : TF_Op<"RFFT3D", [NoSideEffect]> { 11333 let summary = "3D real-valued fast Fourier transform."; 11334 11335 let description = [{ 11336Computes the 3-dimensional discrete Fourier transform of a real-valued signal 11337over the inner-most 3 dimensions of `input`. 11338 11339Since the DFT of a real signal is Hermitian-symmetric, `RFFT3D` only returns the 11340`fft_length / 2 + 1` unique components of the FFT for the inner-most dimension 11341of `output`: the zero-frequency term, followed by the `fft_length / 2` 11342positive-frequency terms. 11343 11344Along each axis `RFFT3D` is computed on, if `fft_length` is smaller than the 11345corresponding dimension of `input`, the dimension is cropped. If it is larger, 11346the dimension is padded with zeros. 11347 }]; 11348 11349 let arguments = (ins 11350 Arg<TF_F32OrF64Tensor, [{A float32 tensor.}]>:$input, 11351 Arg<TF_Int32Tensor, [{An int32 tensor of shape [3]. The FFT length for each dimension.}]>:$fft_length 11352 ); 11353 11354 let results = (outs 11355 Res<TensorOf<[TF_Complex128, TF_Complex64]>, [{A complex64 tensor of the same rank as `input`. The inner-most 3 11356 dimensions of `input` are replaced with the their 3D Fourier transform. The 11357 inner-most dimension contains `fft_length / 2 + 1` unique frequency 11358 components. 11359 11360@compatibility(numpy) 11361Equivalent to np.fft.rfftn with 3 dimensions. 11362@end_compatibility}]>:$output 11363 ); 11364 11365 TF_DerivedOperandTypeAttr Treal = TF_DerivedOperandTypeAttr<0>; 11366 TF_DerivedResultTypeAttr Tcomplex = TF_DerivedResultTypeAttr<0>; 11367} 11368 11369def TF_RGBToHSVOp : TF_Op<"RGBToHSV", [NoSideEffect]> { 11370 let summary = "Converts one or more images from RGB to HSV."; 11371 11372 let description = [{ 11373Outputs a tensor of the same shape as the `images` tensor, containing the HSV 11374value of the pixels. The output is only well defined if the value in `images` 11375are in `[0,1]`. 11376 11377`output[..., 0]` contains hue, `output[..., 1]` contains saturation, and 11378`output[..., 2]` contains value. All HSV values are in `[0,1]`. A hue of 0 11379corresponds to pure red, hue 1/3 is pure green, and 2/3 is pure blue. 11380 11381Usage Example: 11382 11383>>> blue_image = tf.stack([ 11384... tf.zeros([5,5]), 11385... tf.zeros([5,5]), 11386... tf.ones([5,5])], 11387... axis=-1) 11388>>> blue_hsv_image = tf.image.rgb_to_hsv(blue_image) 11389>>> blue_hsv_image[0,0].numpy() 11390array([0.6666667, 1. , 1. ], dtype=float32) 11391 }]; 11392 11393 let arguments = (ins 11394 Arg<TF_FloatTensor, [{1-D or higher rank. RGB data to convert. Last dimension must be size 3.}]>:$images 11395 ); 11396 11397 let results = (outs 11398 Res<TF_FloatTensor, [{`images` converted to HSV.}]>:$output 11399 ); 11400 11401 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11402} 11403 11404def TF_RaggedGatherOp : TF_Op<"RaggedGather", [NoSideEffect]> { 11405 let summary = [{ 11406Gather ragged slices from `params` axis `0` according to `indices`. 11407 }]; 11408 11409 let description = [{ 11410Outputs a `RaggedTensor` output composed from `output_dense_values` and 11411`output_nested_splits`, such that: 11412 11413```python 11414output.shape = indices.shape + params.shape[1:] 11415output.ragged_rank = indices.shape.ndims + params.ragged_rank 11416output[i...j, d0...dn] = params[indices[i...j], d0...dn] 11417``` 11418 11419where 11420 11421* `params = 11422 ragged.from_nested_row_splits(params_dense_values, params_nested_splits)` 11423 provides the values that should be gathered. 11424* `indices` ia a dense tensor with dtype `int32` or `int64`, indicating which 11425 values should be gathered. 11426* `output = 11427 ragged.from_nested_row_splits(output_dense_values, output_nested_splits)` 11428 is the output tensor. 11429 11430(Note: This c++ op is used to implement the higher-level python 11431`tf.ragged.gather` op, which also supports ragged indices.) 11432 }]; 11433 11434 let arguments = (ins 11435 Arg<Variadic<TF_I32OrI64Tensor>, [{The `nested_row_splits` tensors that define the row-partitioning for the 11436`params` RaggedTensor input.}]>:$params_nested_splits, 11437 Arg<TF_Tensor, [{The `flat_values` for the `params` RaggedTensor. There was a terminology change 11438at the python level from dense_values to flat_values, so dense_values is the 11439deprecated name.}]>:$params_dense_values, 11440 Arg<TF_I32OrI64Tensor, [{Indices in the outermost dimension of `params` of the values that should be 11441gathered.}]>:$indices 11442 ); 11443 11444 let results = (outs 11445 Res<Variadic<TF_I32OrI64Tensor>, [{The `nested_row_splits` tensors that define the row-partitioning for the 11446returned RaggedTensor.}]>:$output_nested_splits, 11447 Res<TF_Tensor, [{The `flat_values` for the returned RaggedTensor.}]>:$output_dense_values 11448 ); 11449 11450 TF_DerivedOperandSizeAttr PARAMS_RAGGED_RANK = TF_DerivedOperandSizeAttr<0>; 11451 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<2>; 11452 TF_DerivedOperandTypeAttr Tsplits = TF_DerivedOperandTypeAttr<0>; 11453 TF_DerivedOperandTypeAttr Tvalues = TF_DerivedOperandTypeAttr<1>; 11454 TF_DerivedResultSizeAttr OUTPUT_RAGGED_RANK = TF_DerivedResultSizeAttr<0>; 11455} 11456 11457def TF_RaggedRangeOp : TF_Op<"RaggedRange", [NoSideEffect]> { 11458 let summary = [{ 11459Returns a `RaggedTensor` containing the specified sequences of numbers. 11460 }]; 11461 11462 let description = [{ 11463Returns a `RaggedTensor` `result` composed from `rt_dense_values` and 11464`rt_nested_splits`, such that 11465`result[i] = range(starts[i], limits[i], deltas[i])`. 11466 11467```python 11468(rt_nested_splits, rt_dense_values) = ragged_range( 11469 starts=[2, 5, 8], limits=[3, 5, 12], deltas=1) 11470result = tf.ragged.from_row_splits(rt_dense_values, rt_nested_splits) 11471print(result) 11472<tf.RaggedTensor [[2], [], [8, 9, 10, 11]] > 11473``` 11474 11475The input tensors `starts`, `limits`, and `deltas` may be scalars or vectors. 11476The vector inputs must all have the same size. Scalar inputs are broadcast 11477to match the size of the vector inputs. 11478 }]; 11479 11480 let arguments = (ins 11481 Arg<TensorOf<[TF_Bfloat16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{The starts of each range.}]>:$starts, 11482 Arg<TensorOf<[TF_Bfloat16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{The limits of each range.}]>:$limits, 11483 Arg<TensorOf<[TF_Bfloat16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{The deltas of each range.}]>:$deltas 11484 ); 11485 11486 let results = (outs 11487 Res<TF_I32OrI64Tensor, [{The `row_splits` for the returned `RaggedTensor`.}]>:$rt_nested_splits, 11488 Res<TensorOf<[TF_Bfloat16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{The `flat_values` for the returned `RaggedTensor`.}]>:$rt_dense_values 11489 ); 11490 11491 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11492 TF_DerivedResultTypeAttr Tsplits = TF_DerivedResultTypeAttr<0>; 11493} 11494 11495def TF_RandomGammaOp : TF_Op<"RandomGamma", [TF_CannotDuplicate, TF_RandomGeneratorSideEffect]> { 11496 let summary = [{ 11497Outputs random values from the Gamma distribution(s) described by alpha. 11498 }]; 11499 11500 let description = [{ 11501This op uses the algorithm by Marsaglia et al. to acquire samples via 11502transformation-rejection from pairs of uniform and normal random variables. 11503See http://dl.acm.org/citation.cfm?id=358414 11504 }]; 11505 11506 let arguments = (ins 11507 Arg<TF_I32OrI64Tensor, [{1-D integer tensor. Shape of independent samples to draw from each 11508distribution described by the shape parameters given in alpha.}]>:$shape, 11509 Arg<TensorOf<[TF_Float16, TF_Float32, TF_Float64]>, [{A tensor in which each scalar is a "shape" parameter describing the 11510associated gamma distribution.}]>:$alpha, 11511 11512 DefaultValuedAttr<I64Attr, "0">:$seed, 11513 DefaultValuedAttr<I64Attr, "0">:$seed2 11514 ); 11515 11516 let results = (outs 11517 Res<TensorOf<[TF_Float16, TF_Float32, TF_Float64]>, [{A tensor with shape `shape + shape(alpha)`. Each slice 11518`[:, ..., :, i0, i1, ...iN]` contains the samples drawn for 11519`alpha[i0, i1, ...iN]`. The dtype of the output matches the dtype of alpha.}]>:$output 11520 ); 11521 11522 TF_DerivedOperandTypeAttr S = TF_DerivedOperandTypeAttr<0>; 11523 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 11524} 11525 11526def TF_RandomGammaGradOp : TF_Op<"RandomGammaGrad", [NoSideEffect, ResultsBroadcastableShape]>, 11527 WithBroadcastableBinOpBuilder { 11528 let summary = [{ 11529Computes the derivative of a Gamma random sample w.r.t. `alpha`. 11530 }]; 11531 11532 let arguments = (ins 11533 TF_F32OrF64Tensor:$alpha, 11534 TF_F32OrF64Tensor:$sample 11535 ); 11536 11537 let results = (outs 11538 TF_F32OrF64Tensor:$output 11539 ); 11540 11541 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11542} 11543 11544def TF_RandomPoissonOp : TF_Op<"RandomPoisson", [TF_CannotDuplicate, TF_RandomGeneratorSideEffect]> { 11545 let summary = "Use RandomPoissonV2 instead."; 11546 11547 let arguments = (ins 11548 TF_I32OrI64Tensor:$shape, 11549 TensorOf<[TF_Float16, TF_Float32, TF_Float64]>:$rate, 11550 11551 DefaultValuedAttr<I64Attr, "0">:$seed, 11552 DefaultValuedAttr<I64Attr, "0">:$seed2 11553 ); 11554 11555 let results = (outs 11556 TensorOf<[TF_Float16, TF_Float32, TF_Float64]>:$output 11557 ); 11558 11559 TF_DerivedOperandTypeAttr S = TF_DerivedOperandTypeAttr<0>; 11560 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<1>; 11561} 11562 11563def TF_RandomPoissonV2Op : TF_Op<"RandomPoissonV2", [TF_CannotDuplicate, TF_RandomGeneratorSideEffect]> { 11564 let summary = [{ 11565Outputs random values from the Poisson distribution(s) described by rate. 11566 }]; 11567 11568 let description = [{ 11569This op uses two algorithms, depending on rate. If rate >= 10, then 11570the algorithm by Hormann is used to acquire samples via 11571transformation-rejection. 11572See http://www.sciencedirect.com/science/article/pii/0167668793909974. 11573 11574Otherwise, Knuth's algorithm is used to acquire samples via multiplying uniform 11575random variables. 11576See Donald E. Knuth (1969). Seminumerical Algorithms. The Art of Computer 11577Programming, Volume 2. Addison Wesley 11578 }]; 11579 11580 let arguments = (ins 11581 Arg<TF_I32OrI64Tensor, [{1-D integer tensor. Shape of independent samples to draw from each 11582distribution described by the shape parameters given in rate.}]>:$shape, 11583 Arg<TensorOf<[TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{A tensor in which each scalar is a "rate" parameter describing the 11584associated poisson distribution.}]>:$rate, 11585 11586 DefaultValuedAttr<I64Attr, "0">:$seed, 11587 DefaultValuedAttr<I64Attr, "0">:$seed2 11588 ); 11589 11590 let results = (outs 11591 Res<TensorOf<[TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{A tensor with shape `shape + shape(rate)`. Each slice 11592`[:, ..., :, i0, i1, ...iN]` contains the samples drawn for 11593`rate[i0, i1, ...iN]`.}]>:$output 11594 ); 11595 11596 TF_DerivedOperandTypeAttr R = TF_DerivedOperandTypeAttr<1>; 11597 TF_DerivedOperandTypeAttr S = TF_DerivedOperandTypeAttr<0>; 11598 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 11599} 11600 11601def TF_RandomShuffleOp : TF_Op<"RandomShuffle", [TF_CannotDuplicate, TF_RandomGeneratorSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 11602 let summary = "Randomly shuffles a tensor along its first dimension."; 11603 11604 let description = [{ 11605The tensor is shuffled along dimension 0, such that each `value[j]` is mapped 11606 to one and only one `output[i]`. For example, a mapping that might occur for a 11607 3x2 tensor is: 11608 11609``` 11610[[1, 2], [[5, 6], 11611 [3, 4], ==> [1, 2], 11612 [5, 6]] [3, 4]] 11613``` 11614 }]; 11615 11616 let arguments = (ins 11617 Arg<TF_Tensor, [{The tensor to be shuffled.}]>:$value, 11618 11619 DefaultValuedAttr<I64Attr, "0">:$seed, 11620 DefaultValuedAttr<I64Attr, "0">:$seed2 11621 ); 11622 11623 let results = (outs 11624 Res<TF_Tensor, [{A tensor of same shape and type as `value`, shuffled along its first 11625dimension.}]>:$output 11626 ); 11627 11628 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11629} 11630 11631def TF_RandomStandardNormalOp : TF_Op<"RandomStandardNormal", [TF_CannotDuplicate, TF_RandomGeneratorSideEffect]> { 11632 let summary = "Outputs random values from a normal distribution."; 11633 11634 let description = [{ 11635The generated values will have mean 0 and standard deviation 1. 11636 }]; 11637 11638 let arguments = (ins 11639 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 11640 11641 DefaultValuedAttr<I64Attr, "0">:$seed, 11642 DefaultValuedAttr<I64Attr, "0">:$seed2 11643 ); 11644 11645 let results = (outs 11646 Res<TF_FloatTensor, [{A tensor of the specified shape filled with random normal values.}]>:$output 11647 ); 11648 11649 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11650 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 11651} 11652 11653def TF_RandomUniformOp : TF_Op<"RandomUniform", [TF_CannotDuplicate, TF_RandomGeneratorSideEffect]> { 11654 let summary = "Outputs random values from a uniform distribution."; 11655 11656 let description = [{ 11657The generated values follow a uniform distribution in the range `[0, 1)`. The 11658lower bound 0 is included in the range, while the upper bound 1 is excluded. 11659 }]; 11660 11661 let arguments = (ins 11662 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 11663 11664 DefaultValuedAttr<I64Attr, "0">:$seed, 11665 DefaultValuedAttr<I64Attr, "0">:$seed2 11666 ); 11667 11668 let results = (outs 11669 Res<TF_FloatTensor, [{A tensor of the specified shape filled with uniform random values.}]>:$output 11670 ); 11671 11672 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11673 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 11674 11675 let hasVerifier = 1; 11676} 11677 11678def TF_RandomUniformIntOp : TF_Op<"RandomUniformInt", [TF_CannotDuplicate, TF_RandomGeneratorSideEffect]> { 11679 let summary = "Outputs random integers from a uniform distribution."; 11680 11681 let description = [{ 11682The generated values are uniform integers in the range `[minval, maxval)`. 11683The lower bound `minval` is included in the range, while the upper bound 11684`maxval` is excluded. 11685 11686The random integers are slightly biased unless `maxval - minval` is an exact 11687power of two. The bias is small for values of `maxval - minval` significantly 11688smaller than the range of the output (either `2^32` or `2^64`). 11689 }]; 11690 11691 let arguments = (ins 11692 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 11693 Arg<TF_I32OrI64Tensor, [{0-D. Inclusive lower bound on the generated integers.}]>:$minval, 11694 Arg<TF_I32OrI64Tensor, [{0-D. Exclusive upper bound on the generated integers.}]>:$maxval, 11695 11696 DefaultValuedAttr<I64Attr, "0">:$seed, 11697 DefaultValuedAttr<I64Attr, "0">:$seed2 11698 ); 11699 11700 let results = (outs 11701 Res<TF_I32OrI64Tensor, [{A tensor of the specified shape filled with uniform random integers.}]>:$output 11702 ); 11703 11704 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11705 TF_DerivedOperandTypeAttr Tout = TF_DerivedOperandTypeAttr<1>; 11706} 11707 11708def TF_RangeOp : TF_Op<"Range", [NoSideEffect, TF_SameOperandsAndResultElementTypeResolveRef]> { 11709 let summary = "Creates a sequence of numbers."; 11710 11711 let description = [{ 11712This operation creates a sequence of numbers that begins at `start` and 11713extends by increments of `delta` up to but not including `limit`. 11714 11715For example: 11716 11717``` 11718# 'start' is 3 11719# 'limit' is 18 11720# 'delta' is 3 11721tf.range(start, limit, delta) ==> [3, 6, 9, 12, 15] 11722``` 11723 }]; 11724 11725 let arguments = (ins 11726 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32]>, [{0-D (scalar). First entry in the sequence.}]>:$start, 11727 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32]>, [{0-D (scalar). Upper limit of sequence, exclusive.}]>:$limit, 11728 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32]>, [{0-D (scalar). Optional. Default is 1. Number that increments `start`.}]>:$delta 11729 ); 11730 11731 let results = (outs 11732 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32]>, [{1-D.}]>:$output 11733 ); 11734 11735 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<0>; 11736 11737 let builders = [ 11738 OpBuilder<(ins "Value":$start, "Value":$limit, "Value":$delta)> 11739 ]; 11740 11741 let hasFolder = 1; 11742 11743} 11744 11745def TF_RangeDatasetOp : TF_Op<"RangeDataset", [NoSideEffect, TF_NoConstantFold]> { 11746 let summary = [{ 11747Creates a dataset with a range of values. Corresponds to python's xrange. 11748 }]; 11749 11750 let arguments = (ins 11751 Arg<TF_Int64Tensor, [{corresponds to start in python's xrange().}]>:$start, 11752 Arg<TF_Int64Tensor, [{corresponds to stop in python's xrange().}]>:$stop, 11753 Arg<TF_Int64Tensor, [{corresponds to step in python's xrange().}]>:$step, 11754 11755 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 11756 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 11757 DefaultValuedAttr<StrAttr, "\"\"">:$metadata, 11758 DefaultValuedAttr<BoolAttr, "false">:$replicate_on_split 11759 ); 11760 11761 let results = (outs 11762 TF_VariantTensor:$handle 11763 ); 11764} 11765 11766def TF_RankOp : TF_Op<"Rank", [NoSideEffect]> { 11767 let summary = "Returns the rank of a tensor."; 11768 11769 let description = [{ 11770This operation returns an integer representing the rank of `input`. 11771 11772For example: 11773 11774``` 11775# 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]] 11776# shape of tensor 't' is [2, 2, 3] 11777rank(t) ==> 3 11778``` 11779 11780**Note**: The rank of a tensor is not the same as the rank of a matrix. The rank 11781of a tensor is the number of indices required to uniquely select each element 11782of the tensor. Rank is also known as "order", "degree", or "ndims." 11783 }]; 11784 11785 let arguments = (ins 11786 TF_Tensor:$input 11787 ); 11788 11789 let results = (outs 11790 TF_Int32Tensor:$output 11791 ); 11792 11793 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11794 11795 let builders = [ 11796 OpBuilder<(ins "Value":$input)> 11797 ]; 11798 11799 let hasFolder = 1; 11800} 11801 11802def TF_ReadVariableOp : TF_Op<"ReadVariableOp", []> { 11803 let summary = "Reads the value of a variable."; 11804 11805 let description = [{ 11806The tensor returned by this operation is immutable. 11807 11808The value returned by this operation is guaranteed to be influenced by all the 11809writes on which this operation depends directly or indirectly, and to not be 11810influenced by any of the writes which depend directly or indirectly on this 11811operation. 11812 }]; 11813 11814 let arguments = (ins 11815 Arg<TF_ResourceTensor, [{handle to the resource in which to store the variable.}], [TF_VariableRead]>:$resource 11816 ); 11817 11818 let results = (outs 11819 TF_Tensor:$value 11820 ); 11821 11822 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 11823 11824 let hasCanonicalizer = 1; 11825} 11826 11827def TF_RealOp : TF_Op<"Real", [NoSideEffect, SameOperandsAndResultShape]> { 11828 let summary = "Returns the real part of a complex number."; 11829 11830 let description = [{ 11831Given a tensor `input` of complex numbers, this operation returns a tensor of 11832type `float` that is the real part of each element in `input`. All elements in 11833`input` must be complex numbers of the form \\(a + bj\\), where *a* is the real 11834 part returned by this operation and *b* is the imaginary part. 11835 11836For example: 11837 11838``` 11839# tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] 11840tf.real(input) ==> [-2.25, 3.25] 11841``` 11842 }]; 11843 11844 let arguments = (ins 11845 TensorOf<[TF_Complex128, TF_Complex64]>:$input 11846 ); 11847 11848 let results = (outs 11849 TF_F32OrF64Tensor:$output 11850 ); 11851 11852 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11853 TF_DerivedResultTypeAttr Tout = TF_DerivedResultTypeAttr<0>; 11854} 11855 11856def TF_RealDivOp : TF_Op<"RealDiv", [NoSideEffect, ResultsBroadcastableShape, TF_CwiseBinary]>, 11857 WithBroadcastableBinOpBuilder { 11858 let summary = "Returns x / y element-wise for real types."; 11859 11860 let description = [{ 11861If `x` and `y` are reals, this will return the floating-point division. 11862 11863*NOTE*: `Div` supports broadcasting. More about broadcasting 11864[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 11865 }]; 11866 11867 let arguments = (ins 11868 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$x, 11869 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$y 11870 ); 11871 11872 let results = (outs 11873 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$z 11874 ); 11875 11876 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11877 11878 let hasCanonicalizer = 1; 11879 11880 let hasFolder = 1; 11881} 11882 11883def TF_ReciprocalOp : TF_Op<"Reciprocal", [Involution, NoSideEffect, SameOperandsAndResultType]> { 11884 let summary = "Computes the reciprocal of x element-wise."; 11885 11886 let description = [{ 11887I.e., \\(y = 1 / x\\). 11888 }]; 11889 11890 let arguments = (ins 11891 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x 11892 ); 11893 11894 let results = (outs 11895 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 11896 ); 11897 11898 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11899} 11900 11901def TF_ReciprocalGradOp : TF_Op<"ReciprocalGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 11902 let summary = "Computes the gradient for the inverse of `x` wrt its input."; 11903 11904 let description = [{ 11905Specifically, `grad = -dy * y*y`, where `y = 1/x`, and `dy` 11906is the corresponding input gradient. 11907 }]; 11908 11909 let arguments = (ins 11910 TF_FpOrComplexTensor:$y, 11911 TF_FpOrComplexTensor:$dy 11912 ); 11913 11914 let results = (outs 11915 TF_FpOrComplexTensor:$z 11916 ); 11917 11918 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 11919} 11920 11921def TF_RecvOp : TF_Op<"Recv", [TF_RecvSideEffect]> { 11922 let summary = "Receives the named tensor from send_device on recv_device."; 11923 11924 let arguments = (ins 11925 StrAttr:$tensor_name, 11926 StrAttr:$send_device, 11927 I64Attr:$send_device_incarnation, 11928 StrAttr:$recv_device, 11929 DefaultValuedAttr<BoolAttr, "false">:$client_terminated 11930 ); 11931 11932 let results = (outs 11933 Res<TF_Tensor, [{The tensor to receive.}]>:$tensor 11934 ); 11935 11936 TF_DerivedResultTypeAttr tensor_type = TF_DerivedResultTypeAttr<0>; 11937} 11938 11939def TF_RecvTPUEmbeddingActivationsOp : TF_Op<"RecvTPUEmbeddingActivations", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 11940 let summary = "An op that receives embedding activations on the TPU."; 11941 11942 let description = [{ 11943The TPU system performs the embedding lookups and aggregations specified by 11944the arguments to TPUEmbeddingEnqueue(Integer/Sparse/SparseTensor)Batch. The 11945results of these aggregations are visible to the Tensorflow Graph as the 11946outputs of a RecvTPUEmbeddingActivations op. This op returns a list containing 11947one Tensor of activations per table specified in the model. There can be at 11948most one RecvTPUEmbeddingActivations op in the TPU graph. 11949 }]; 11950 11951 let arguments = (ins 11952 StrAttr:$config 11953 ); 11954 11955 let results = (outs 11956 Res<Variadic<TF_Float32Tensor>, [{A TensorList of embedding activations containing one Tensor per 11957embedding table in the model.}]>:$outputs 11958 ); 11959 11960 TF_DerivedResultSizeAttr num_outputs = TF_DerivedResultSizeAttr<0>; 11961} 11962 11963def TF_ReduceJoinOp : TF_Op<"ReduceJoin", [NoSideEffect]> { 11964 let summary = "Joins a string Tensor across the given dimensions."; 11965 11966 let description = [{ 11967Computes the string join across dimensions in the given string Tensor of shape 11968`[\\(d_0, d_1, ..., d_{n-1}\\)]`. Returns a new Tensor created by joining the input 11969strings with the given separator (default: empty string). Negative indices are 11970counted backwards from the end, with `-1` being equivalent to `n - 1`. If 11971indices are not specified, joins across all dimensions beginning from `n - 1` 11972through `0`. 11973 11974For example: 11975 11976```python 11977# tensor `a` is [["a", "b"], ["c", "d"]] 11978tf.reduce_join(a, 0) ==> ["ac", "bd"] 11979tf.reduce_join(a, 1) ==> ["ab", "cd"] 11980tf.reduce_join(a, -2) = tf.reduce_join(a, 0) ==> ["ac", "bd"] 11981tf.reduce_join(a, -1) = tf.reduce_join(a, 1) ==> ["ab", "cd"] 11982tf.reduce_join(a, 0, keep_dims=True) ==> [["ac", "bd"]] 11983tf.reduce_join(a, 1, keep_dims=True) ==> [["ab"], ["cd"]] 11984tf.reduce_join(a, 0, separator=".") ==> ["a.c", "b.d"] 11985tf.reduce_join(a, [0, 1]) ==> "acbd" 11986tf.reduce_join(a, [1, 0]) ==> "abcd" 11987tf.reduce_join(a, []) ==> [["a", "b"], ["c", "d"]] 11988tf.reduce_join(a) = tf.reduce_join(a, [1, 0]) ==> "abcd" 11989``` 11990 }]; 11991 11992 let arguments = (ins 11993 Arg<TF_StrTensor, [{The input to be joined. All reduced indices must have non-zero size.}]>:$inputs, 11994 Arg<TF_Int32Tensor, [{The dimensions to reduce over. Dimensions are reduced in the 11995order specified. Omitting `reduction_indices` is equivalent to passing 11996`[n-1, n-2, ..., 0]`. Negative indices from `-n` to `-1` are supported.}]>:$reduction_indices, 11997 11998 DefaultValuedAttr<BoolAttr, "false">:$keep_dims, 11999 DefaultValuedAttr<StrAttr, "\"\"">:$separator 12000 ); 12001 12002 let results = (outs 12003 Res<TF_StrTensor, [{Has shape equal to that of the input with reduced dimensions removed or 12004set to `1` depending on `keep_dims`.}]>:$output 12005 ); 12006} 12007 12008def TF_ReluOp : TF_Op<"Relu", [Idempotent, NoSideEffect, SameOperandsAndResultType, TF_LayoutAgnostic]> { 12009 let summary = "Computes rectified linear: `max(features, 0)`."; 12010 12011 let description = [{ 12012See: https://en.wikipedia.org/wiki/Rectifier_(neural_networks) 12013Example usage: 12014>>> tf.nn.relu([-2., 0., 3.]).numpy() 12015array([0., 0., 3.], dtype=float32) 12016 }]; 12017 12018 let arguments = (ins 12019 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$features 12020 ); 12021 12022 let results = (outs 12023 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$activations 12024 ); 12025 12026 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 12027 12028 let hasCanonicalizer = 1; 12029 let extraClassDeclaration = [{ 12030 static bool isCompatibleReturnTypes(TypeRange inferred, TypeRange actual) { 12031 return ArraysAreCastCompatible(inferred, actual); 12032 } 12033 }]; 12034} 12035 12036def TF_Relu6Op : TF_Op<"Relu6", [Idempotent, NoSideEffect, SameOperandsAndResultType]> { 12037 let summary = "Computes rectified linear 6: `min(max(features, 0), 6)`."; 12038 12039 let arguments = (ins 12040 TF_IntOrFpTensor:$features 12041 ); 12042 12043 let results = (outs 12044 TF_IntOrFpTensor:$activations 12045 ); 12046 12047 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 12048} 12049 12050def TF_Relu6GradOp : TF_Op<"Relu6Grad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 12051 let summary = "Computes rectified linear 6 gradients for a Relu6 operation."; 12052 12053 let arguments = (ins 12054 Arg<TF_IntOrFpTensor, [{The backpropagated gradients to the corresponding Relu6 operation.}]>:$gradients, 12055 Arg<TF_IntOrFpTensor, [{The features passed as input to the corresponding Relu6 operation, or 12056its output; using either one produces the same result.}]>:$features 12057 ); 12058 12059 let results = (outs 12060 Res<TF_IntOrFpTensor, [{The gradients: 12061`gradients * (features > 0) * (features < 6)`.}]>:$backprops 12062 ); 12063 12064 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 12065} 12066 12067def TF_ReluGradOp : TF_Op<"ReluGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 12068 let summary = "Computes rectified linear gradients for a Relu operation."; 12069 12070 let arguments = (ins 12071 Arg<TF_IntOrFpTensor, [{The backpropagated gradients to the corresponding Relu operation.}]>:$gradients, 12072 Arg<TF_IntOrFpTensor, [{The features passed as input to the corresponding Relu operation, OR 12073the outputs of that operation (both work equivalently).}]>:$features 12074 ); 12075 12076 let results = (outs 12077 Res<TF_IntOrFpTensor, [{`gradients * (features > 0)`.}]>:$backprops 12078 ); 12079 12080 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 12081} 12082 12083def TF_RemoteCallOp : TF_Op<"RemoteCall", []> { 12084 let summary = "Runs function `f` on a remote device indicated by `target`."; 12085 12086 let arguments = (ins 12087 Arg<TF_StrTensor, [{A fully specified device name where we want to run the function.}]>:$target, 12088 Arg<Variadic<TF_Tensor>, [{A list of arguments for the function.}]>:$args, 12089 12090 SymbolRefAttr:$f 12091 ); 12092 12093 let results = (outs 12094 Res<Variadic<TF_Tensor>, [{A list of return values.}]>:$output 12095 ); 12096 12097 TF_DerivedOperandTypeListAttr Tin = TF_DerivedOperandTypeListAttr<1>; 12098 TF_DerivedResultTypeListAttr Tout = TF_DerivedResultTypeListAttr<0>; 12099} 12100 12101def TF_RepeatDatasetOp : TF_Op<"RepeatDataset", [NoSideEffect]> { 12102 let summary = [{ 12103Creates a dataset that emits the outputs of `input_dataset` `count` times. 12104 }]; 12105 12106 let arguments = (ins 12107 TF_VariantTensor:$input_dataset, 12108 Arg<TF_Int64Tensor, [{A scalar representing the number of times that `input_dataset` should 12109be repeated. A value of `-1` indicates that it should be repeated infinitely.}]>:$count, 12110 12111 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 12112 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 12113 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 12114 ); 12115 12116 let results = (outs 12117 TF_VariantTensor:$handle 12118 ); 12119} 12120 12121def TF_ReshapeOp : TF_Op<"Reshape", [NoSideEffect]> { 12122 let summary = "Reshapes a tensor."; 12123 12124 let description = [{ 12125Given `tensor`, this operation returns a tensor that has the same values 12126as `tensor` with shape `shape`. 12127 12128If one component of 1-D tensor `shape` is the special value -1, the size of that 12129dimension is computed so that the total size remains constant. In particular, a 12130`shape` of `[-1]` flattens into 1-D. At most one component of `shape` may be 12131unknown. 12132 12133The `shape` must be 1-D and the operation returns a tensor with shape 12134`shape` filled with the values of `tensor`. In this case, the number of elements 12135implied by `shape` must be the same as the number of elements in `tensor`. 12136 12137It is an error if `shape` is not 1-D. 12138 12139For example: 12140 12141``` 12142# tensor 't' is [1, 2, 3, 4, 5, 6, 7, 8, 9] 12143# tensor 't' has shape [9] 12144reshape(t, [3, 3]) ==> [[1, 2, 3], 12145 [4, 5, 6], 12146 [7, 8, 9]] 12147 12148# tensor 't' is [[[1, 1], [2, 2]], 12149# [[3, 3], [4, 4]]] 12150# tensor 't' has shape [2, 2, 2] 12151reshape(t, [2, 4]) ==> [[1, 1, 2, 2], 12152 [3, 3, 4, 4]] 12153 12154# tensor 't' is [[[1, 1, 1], 12155# [2, 2, 2]], 12156# [[3, 3, 3], 12157# [4, 4, 4]], 12158# [[5, 5, 5], 12159# [6, 6, 6]]] 12160# tensor 't' has shape [3, 2, 3] 12161# pass '[-1]' to flatten 't' 12162reshape(t, [-1]) ==> [1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 6, 6, 6] 12163 12164# -1 can also be used to infer the shape 12165 12166# -1 is inferred to be 9: 12167reshape(t, [2, -1]) ==> [[1, 1, 1, 2, 2, 2, 3, 3, 3], 12168 [4, 4, 4, 5, 5, 5, 6, 6, 6]] 12169# -1 is inferred to be 2: 12170reshape(t, [-1, 9]) ==> [[1, 1, 1, 2, 2, 2, 3, 3, 3], 12171 [4, 4, 4, 5, 5, 5, 6, 6, 6]] 12172# -1 is inferred to be 3: 12173reshape(t, [ 2, -1, 3]) ==> [[[1, 1, 1], 12174 [2, 2, 2], 12175 [3, 3, 3]], 12176 [[4, 4, 4], 12177 [5, 5, 5], 12178 [6, 6, 6]]] 12179 12180# tensor 't' is [7] 12181# shape `[]` reshapes to a scalar 12182reshape(t, []) ==> 7 12183``` 12184 }]; 12185 12186 let arguments = (ins 12187 TF_Tensor:$tensor, 12188 Arg<TF_I32OrI64Tensor, [{Defines the shape of the output tensor.}]>:$shape 12189 ); 12190 12191 let results = (outs 12192 TF_Tensor:$output 12193 ); 12194 12195 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 12196 TF_DerivedOperandTypeAttr Tshape = TF_DerivedOperandTypeAttr<1>; 12197 12198 let builders = [ 12199 OpBuilder<(ins "Value":$tensor, "Value":$shape)> 12200 ]; 12201 12202 let hasVerifier = 1; 12203 12204 let hasCanonicalizer = 1; 12205 let hasFolder = 1; 12206} 12207 12208def TF_ResizeBilinearOp : TF_Op<"ResizeBilinear", [NoSideEffect]> { 12209 let summary = "Resize `images` to `size` using bilinear interpolation."; 12210 12211 let description = [{ 12212Input images can be of different types but output images are always float. 12213 }]; 12214 12215 let arguments = (ins 12216 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint8]>, [{4-D with shape `[batch, height, width, channels]`.}]>:$images, 12217 Arg<TF_Int32Tensor, [{= A 1-D int32 Tensor of 2 elements: `new_height, new_width`. The 12218new size for the images.}]>:$size, 12219 12220 DefaultValuedAttr<BoolAttr, "false">:$align_corners, 12221 DefaultValuedAttr<BoolAttr, "false">:$half_pixel_centers 12222 ); 12223 12224 let results = (outs 12225 Res<TF_Float32Tensor, [{4-D with shape 12226`[batch, new_height, new_width, channels]`.}]>:$resized_images 12227 ); 12228 12229 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 12230} 12231 12232def TF_ResizeBilinearGradOp : TF_Op<"ResizeBilinearGrad", [NoSideEffect]> { 12233 let summary = "Computes the gradient of bilinear interpolation."; 12234 12235 let arguments = (ins 12236 Arg<TF_Float32Tensor, [{4-D with shape `[batch, height, width, channels]`.}]>:$grads, 12237 Arg<TF_FloatTensor, [{4-D with shape `[batch, orig_height, orig_width, channels]`, 12238The image tensor that was resized.}]>:$original_image, 12239 12240 DefaultValuedAttr<BoolAttr, "false">:$align_corners, 12241 DefaultValuedAttr<BoolAttr, "false">:$half_pixel_centers 12242 ); 12243 12244 let results = (outs 12245 Res<TF_FloatTensor, [{4-D with shape `[batch, orig_height, orig_width, channels]`. 12246Gradients with respect to the input image. Input image must have been 12247float or double.}]>:$output 12248 ); 12249 12250 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 12251} 12252 12253def TF_ResizeNearestNeighborOp : TF_Op<"ResizeNearestNeighbor", [NoSideEffect]> { 12254 let summary = [{ 12255Resize `images` to `size` using nearest neighbor interpolation. 12256 }]; 12257 12258 let arguments = (ins 12259 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint8]>, [{4-D with shape `[batch, height, width, channels]`.}]>:$images, 12260 Arg<TF_Int32Tensor, [{= A 1-D int32 Tensor of 2 elements: `new_height, new_width`. The 12261new size for the images.}]>:$size, 12262 12263 DefaultValuedAttr<BoolAttr, "false">:$align_corners, 12264 DefaultValuedAttr<BoolAttr, "false">:$half_pixel_centers 12265 ); 12266 12267 let results = (outs 12268 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint8]>, [{4-D with shape 12269`[batch, new_height, new_width, channels]`.}]>:$resized_images 12270 ); 12271 12272 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 12273} 12274 12275def TF_ResizeNearestNeighborGradOp : TF_Op<"ResizeNearestNeighborGrad", [NoSideEffect]> { 12276 let summary = "Computes the gradient of nearest neighbor interpolation."; 12277 12278 let arguments = (ins 12279 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int8, TF_Uint8]>, [{4-D with shape `[batch, height, width, channels]`.}]>:$grads, 12280 Arg<TF_Int32Tensor, [{= A 1-D int32 Tensor of 2 elements: `orig_height, orig_width`. The 12281original input size.}]>:$size, 12282 12283 DefaultValuedAttr<BoolAttr, "false">:$align_corners, 12284 DefaultValuedAttr<BoolAttr, "false">:$half_pixel_centers 12285 ); 12286 12287 let results = (outs 12288 Res<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int8, TF_Uint8]>, [{4-D with shape `[batch, orig_height, orig_width, channels]`. Gradients 12289with respect to the input image.}]>:$output 12290 ); 12291 12292 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 12293} 12294 12295def TF_ResourceApplyAdaMaxOp : TF_Op<"ResourceApplyAdaMax", []> { 12296 let summary = "Update '*var' according to the AdaMax algorithm."; 12297 12298 let description = [{ 12299m_t <- beta1 * m_{t-1} + (1 - beta1) * g 12300v_t <- max(beta2 * v_{t-1}, abs(g)) 12301variable <- variable - learning_rate / (1 - beta1^t) * m_t / (v_t + epsilon) 12302 }]; 12303 12304 let arguments = (ins 12305 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12306 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$m, 12307 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$v, 12308 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Must be a scalar.}]>:$beta1_power, 12309 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12310 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Momentum factor. Must be a scalar.}]>:$beta1, 12311 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Momentum factor. Must be a scalar.}]>:$beta2, 12312 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Ridge term. Must be a scalar.}]>:$epsilon, 12313 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12314 12315 DefaultValuedAttr<BoolAttr, "false">:$use_locking 12316 ); 12317 12318 let results = (outs); 12319 12320 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<3>; 12321} 12322 12323def TF_ResourceApplyAdadeltaOp : TF_Op<"ResourceApplyAdadelta", []> { 12324 let summary = "Update '*var' according to the adadelta scheme."; 12325 12326 let description = [{ 12327accum = rho() * accum + (1 - rho()) * grad.square(); 12328update = (update_accum + epsilon).sqrt() * (accum + epsilon()).rsqrt() * grad; 12329update_accum = rho() * update_accum + (1 - rho()) * update.square(); 12330var -= update; 12331 }]; 12332 12333 let arguments = (ins 12334 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12335 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 12336 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum_update, 12337 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12338 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Decay factor. Must be a scalar.}]>:$rho, 12339 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Constant factor. Must be a scalar.}]>:$epsilon, 12340 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12341 12342 DefaultValuedAttr<BoolAttr, "false">:$use_locking 12343 ); 12344 12345 let results = (outs); 12346 12347 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<3>; 12348} 12349 12350def TF_ResourceApplyAdagradOp : TF_Op<"ResourceApplyAdagrad", []> { 12351 let summary = "Update '*var' according to the adagrad scheme."; 12352 12353 let description = [{ 12354accum += grad * grad 12355var -= lr * grad * (1 / sqrt(accum)) 12356 }]; 12357 12358 let arguments = (ins 12359 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12360 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 12361 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12362 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12363 12364 DefaultValuedAttr<BoolAttr, "false">:$use_locking, 12365 DefaultValuedAttr<BoolAttr, "true">:$update_slots 12366 ); 12367 12368 let results = (outs); 12369 12370 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 12371} 12372 12373def TF_ResourceApplyAdagradDAOp : TF_Op<"ResourceApplyAdagradDA", []> { 12374 let summary = "Update '*var' according to the proximal adagrad scheme."; 12375 12376 let arguments = (ins 12377 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12378 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$gradient_accumulator, 12379 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$gradient_squared_accumulator, 12380 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12381 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12382 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L1 regularization. Must be a scalar.}]>:$l1, 12383 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L2 regularization. Must be a scalar.}]>:$l2, 12384 Arg<TF_Int64Tensor, [{Training step number. Must be a scalar.}]>:$global_step, 12385 12386 DefaultValuedAttr<BoolAttr, "false">:$use_locking 12387 ); 12388 12389 let results = (outs); 12390 12391 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<3>; 12392} 12393 12394def TF_ResourceApplyAdagradV2Op : TF_Op<"ResourceApplyAdagradV2", []> { 12395 let summary = "Update '*var' according to the adagrad scheme."; 12396 12397 let description = [{ 12398accum += grad * grad 12399var -= lr * grad * (1 / (sqrt(accum) + epsilon)) 12400 }]; 12401 12402 let arguments = (ins 12403 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12404 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 12405 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12406 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Constant factor. Must be a scalar.}]>:$epsilon, 12407 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12408 12409 DefaultValuedAttr<BoolAttr, "false">:$use_locking, 12410 DefaultValuedAttr<BoolAttr, "true">:$update_slots 12411 ); 12412 12413 let results = (outs); 12414 12415 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 12416} 12417 12418def TF_ResourceApplyAdamOp : TF_Op<"ResourceApplyAdam", []> { 12419 let summary = "Update '*var' according to the Adam algorithm."; 12420 12421 let description = [{ 12422$$\text{lr}_t := \mathrm{lr} \cdot \frac{\sqrt{1 - \beta_2^t}}{1 - \beta_1^t}$$ 12423$$m_t := \beta_1 \cdot m_{t-1} + (1 - \beta_1) \cdot g$$ 12424$$v_t := \beta_2 \cdot v_{t-1} + (1 - \beta_2) \cdot g^2$$ 12425$$\text{var} := \begin{cases} \text{var} - (m_t \beta_1 + g \cdot (1 - \beta_1))\cdot\text{lr}_t/(\sqrt{v_t} + \epsilon), &\text{if use_nesterov}\\\\ \text{var} - m_t \cdot \text{lr}_t /(\sqrt{v_t} + \epsilon), &\text{otherwise} \end{cases}$$ 12426 }]; 12427 12428 let arguments = (ins 12429 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12430 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$m, 12431 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$v, 12432 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Must be a scalar.}]>:$beta1_power, 12433 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Must be a scalar.}]>:$beta2_power, 12434 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12435 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Momentum factor. Must be a scalar.}]>:$beta1, 12436 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Momentum factor. Must be a scalar.}]>:$beta2, 12437 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Ridge term. Must be a scalar.}]>:$epsilon, 12438 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12439 12440 DefaultValuedAttr<BoolAttr, "false">:$use_locking, 12441 DefaultValuedAttr<BoolAttr, "false">:$use_nesterov 12442 ); 12443 12444 let results = (outs); 12445 12446 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<3>; 12447} 12448 12449def TF_ResourceApplyAddSignOp : TF_Op<"ResourceApplyAddSign", []> { 12450 let summary = "Update '*var' according to the AddSign update."; 12451 12452 let description = [{ 12453m_t <- beta1 * m_{t-1} + (1 - beta1) * g 12454update <- (alpha + sign_decay * sign(g) *sign(m)) * g 12455variable <- variable - lr_t * update 12456 }]; 12457 12458 let arguments = (ins 12459 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12460 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$m, 12461 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12462 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Must be a scalar.}]>:$alpha, 12463 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Must be a scalar.}]>:$sign_decay, 12464 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Must be a scalar.}]>:$beta, 12465 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12466 12467 DefaultValuedAttr<BoolAttr, "false">:$use_locking 12468 ); 12469 12470 let results = (outs); 12471 12472 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 12473} 12474 12475def TF_ResourceApplyCenteredRMSPropOp : TF_Op<"ResourceApplyCenteredRMSProp", []> { 12476 let summary = "Update '*var' according to the centered RMSProp algorithm."; 12477 12478 let description = [{ 12479The centered RMSProp algorithm uses an estimate of the centered second moment 12480(i.e., the variance) for normalization, as opposed to regular RMSProp, which 12481uses the (uncentered) second moment. This often helps with training, but is 12482slightly more expensive in terms of computation and memory. 12483 12484Note that in dense implementation of this algorithm, mg, ms, and mom will 12485update even if the grad is zero, but in this sparse implementation, mg, ms, 12486and mom will not update in iterations during which the grad is zero. 12487 12488mean_square = decay * mean_square + (1-decay) * gradient ** 2 12489mean_grad = decay * mean_grad + (1-decay) * gradient 12490 12491Delta = learning_rate * gradient / sqrt(mean_square + epsilon - mean_grad ** 2) 12492 12493mg <- rho * mg_{t-1} + (1-rho) * grad 12494ms <- rho * ms_{t-1} + (1-rho) * grad * grad 12495mom <- momentum * mom_{t-1} + lr * grad / sqrt(ms - mg * mg + epsilon) 12496var <- var - mom 12497 }]; 12498 12499 let arguments = (ins 12500 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12501 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$mg, 12502 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$ms, 12503 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$mom, 12504 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12505 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Decay rate. Must be a scalar.}]>:$rho, 12506 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Momentum Scale. Must be a scalar.}]>:$momentum, 12507 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Ridge term. Must be a scalar.}]>:$epsilon, 12508 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12509 12510 DefaultValuedAttr<BoolAttr, "false">:$use_locking 12511 ); 12512 12513 let results = (outs); 12514 12515 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<4>; 12516} 12517 12518def TF_ResourceApplyFtrlOp : TF_Op<"ResourceApplyFtrl", []> { 12519 let summary = "Update '*var' according to the Ftrl-proximal scheme."; 12520 12521 let description = [{ 12522accum_new = accum + grad * grad 12523linear += grad - (accum_new^(-lr_power) - accum^(-lr_power)) / lr * var 12524quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 12525var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 12526accum = accum_new 12527 }]; 12528 12529 let arguments = (ins 12530 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12531 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 12532 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$linear, 12533 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12534 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12535 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L1 regularization. Must be a scalar.}]>:$l1, 12536 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L2 regularization. Must be a scalar.}]>:$l2, 12537 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr_power, 12538 12539 DefaultValuedAttr<BoolAttr, "false">:$use_locking, 12540 DefaultValuedAttr<BoolAttr, "false">:$multiply_linear_by_lr 12541 ); 12542 12543 let results = (outs); 12544 12545 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<3>; 12546} 12547 12548def TF_ResourceApplyFtrlV2Op : TF_Op<"ResourceApplyFtrlV2", []> { 12549 let summary = "Update '*var' according to the Ftrl-proximal scheme."; 12550 12551 let description = [{ 12552accum_new = accum + grad * grad 12553grad_with_shrinkage = grad + 2 * l2_shrinkage * var 12554linear += grad_with_shrinkage + 12555 (accum_new^(-lr_power) - accum^(-lr_power)) / lr * var 12556quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 12557var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 12558accum = accum_new 12559 }]; 12560 12561 let arguments = (ins 12562 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12563 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 12564 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$linear, 12565 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12566 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12567 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L1 regularization. Must be a scalar.}]>:$l1, 12568 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L2 shrinkage regularization. Must be a scalar.}]>:$l2, 12569 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$l2_shrinkage, 12570 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr_power, 12571 12572 DefaultValuedAttr<BoolAttr, "false">:$use_locking, 12573 DefaultValuedAttr<BoolAttr, "false">:$multiply_linear_by_lr 12574 ); 12575 12576 let results = (outs); 12577 12578 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<3>; 12579} 12580 12581def TF_ResourceApplyGradientDescentOp : TF_Op<"ResourceApplyGradientDescent", []> { 12582 let summary = "Update '*var' by subtracting 'alpha' * 'delta' from it."; 12583 12584 let arguments = (ins 12585 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12586 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$alpha, 12587 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The change.}]>:$delta, 12588 12589 DefaultValuedAttr<BoolAttr, "false">:$use_locking 12590 ); 12591 12592 let results = (outs); 12593 12594 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 12595} 12596 12597def TF_ResourceApplyKerasMomentumOp : TF_Op<"ResourceApplyKerasMomentum", []> { 12598 let summary = "Update '*var' according to the momentum scheme."; 12599 12600 let description = [{ 12601Set use_nesterov = True if you want to use Nesterov momentum. 12602 12603accum = accum * momentum - lr * grad 12604var += accum 12605 }]; 12606 12607 let arguments = (ins 12608 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12609 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 12610 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12611 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12612 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Momentum. Must be a scalar.}]>:$momentum, 12613 12614 DefaultValuedAttr<BoolAttr, "false">:$use_locking, 12615 DefaultValuedAttr<BoolAttr, "false">:$use_nesterov 12616 ); 12617 12618 let results = (outs); 12619 12620 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 12621} 12622 12623def TF_ResourceApplyMomentumOp : TF_Op<"ResourceApplyMomentum", []> { 12624 let summary = "Update '*var' according to the momentum scheme."; 12625 12626 let description = [{ 12627Set use_nesterov = True if you want to use Nesterov momentum. 12628 12629accum = accum * momentum + grad 12630var -= lr * accum 12631 }]; 12632 12633 let arguments = (ins 12634 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12635 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 12636 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12637 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12638 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Momentum. Must be a scalar.}]>:$momentum, 12639 12640 DefaultValuedAttr<BoolAttr, "false">:$use_locking, 12641 DefaultValuedAttr<BoolAttr, "false">:$use_nesterov 12642 ); 12643 12644 let results = (outs); 12645 12646 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 12647} 12648 12649def TF_ResourceApplyPowerSignOp : TF_Op<"ResourceApplyPowerSign", []> { 12650 let summary = "Update '*var' according to the AddSign update."; 12651 12652 let description = [{ 12653m_t <- beta1 * m_{t-1} + (1 - beta1) * g 12654update <- exp(logbase * sign_decay * sign(g) * sign(m_t)) * g 12655variable <- variable - lr_t * update 12656 }]; 12657 12658 let arguments = (ins 12659 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12660 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$m, 12661 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12662 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Must be a scalar.}]>:$logbase, 12663 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Must be a scalar.}]>:$sign_decay, 12664 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Must be a scalar.}]>:$beta, 12665 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12666 12667 DefaultValuedAttr<BoolAttr, "false">:$use_locking 12668 ); 12669 12670 let results = (outs); 12671 12672 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 12673} 12674 12675def TF_ResourceApplyProximalAdagradOp : TF_Op<"ResourceApplyProximalAdagrad", []> { 12676 let summary = [{ 12677Update '*var' and '*accum' according to FOBOS with Adagrad learning rate. 12678 }]; 12679 12680 let description = [{ 12681accum += grad * grad 12682prox_v = var - lr * grad * (1 / sqrt(accum)) 12683var = sign(prox_v)/(1+lr*l2) * max{|prox_v|-lr*l1,0} 12684 }]; 12685 12686 let arguments = (ins 12687 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12688 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 12689 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12690 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L1 regularization. Must be a scalar.}]>:$l1, 12691 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L2 regularization. Must be a scalar.}]>:$l2, 12692 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12693 12694 DefaultValuedAttr<BoolAttr, "false">:$use_locking 12695 ); 12696 12697 let results = (outs); 12698 12699 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 12700} 12701 12702def TF_ResourceApplyProximalGradientDescentOp : TF_Op<"ResourceApplyProximalGradientDescent", []> { 12703 let summary = "Update '*var' as FOBOS algorithm with fixed learning rate."; 12704 12705 let description = [{ 12706prox_v = var - alpha * delta 12707var = sign(prox_v)/(1+alpha*l2) * max{|prox_v|-alpha*l1,0} 12708 }]; 12709 12710 let arguments = (ins 12711 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12712 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$alpha, 12713 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L1 regularization. Must be a scalar.}]>:$l1, 12714 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L2 regularization. Must be a scalar.}]>:$l2, 12715 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The change.}]>:$delta, 12716 12717 DefaultValuedAttr<BoolAttr, "false">:$use_locking 12718 ); 12719 12720 let results = (outs); 12721 12722 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 12723} 12724 12725def TF_ResourceApplyRMSPropOp : TF_Op<"ResourceApplyRMSProp", []> { 12726 let summary = "Update '*var' according to the RMSProp algorithm."; 12727 12728 let description = [{ 12729Note that in dense implementation of this algorithm, ms and mom will 12730update even if the grad is zero, but in this sparse implementation, ms 12731and mom will not update in iterations during which the grad is zero. 12732 12733mean_square = decay * mean_square + (1-decay) * gradient ** 2 12734Delta = learning_rate * gradient / sqrt(mean_square + epsilon) 12735 12736ms <- rho * ms_{t-1} + (1-rho) * grad * grad 12737mom <- momentum * mom_{t-1} + lr * grad / sqrt(ms + epsilon) 12738var <- var - mom 12739 }]; 12740 12741 let arguments = (ins 12742 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 12743 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$ms, 12744 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$mom, 12745 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 12746 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Decay rate. Must be a scalar.}]>:$rho, 12747 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$momentum, 12748 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Ridge term. Must be a scalar.}]>:$epsilon, 12749 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 12750 12751 DefaultValuedAttr<BoolAttr, "false">:$use_locking 12752 ); 12753 12754 let results = (outs); 12755 12756 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<3>; 12757} 12758 12759def TF_ResourceGatherOp : TF_Op<"ResourceGather", []> { 12760 let summary = [{ 12761Gather slices from the variable pointed to by `resource` according to `indices`. 12762 }]; 12763 12764 let description = [{ 12765`indices` must be an integer tensor of any dimension (usually 0-D or 1-D). 12766Produces an output tensor with shape `indices.shape + params.shape[1:]` where: 12767 12768```python 12769 # Scalar indices 12770 output[:, ..., :] = params[indices, :, ... :] 12771 12772 # Vector indices 12773 output[i, :, ..., :] = params[indices[i], :, ... :] 12774 12775 # Higher rank indices 12776 output[i, ..., j, :, ... :] = params[indices[i, ..., j], :, ..., :] 12777``` 12778 }]; 12779 12780 let arguments = (ins 12781 Arg<TF_ResourceTensor, "", [TF_VariableRead]>:$resource, 12782 TF_I32OrI64Tensor:$indices, 12783 12784 DefaultValuedAttr<I64Attr, "0">:$batch_dims, 12785 DefaultValuedAttr<BoolAttr, "true">:$validate_indices 12786 ); 12787 12788 let results = (outs 12789 TF_Tensor:$output 12790 ); 12791 12792 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 12793 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 12794} 12795 12796def TF_ResourceScatterAddOp : TF_Op<"ResourceScatterAdd", []> { 12797 let summary = "Adds sparse updates to the variable referenced by `resource`."; 12798 12799 let description = [{ 12800This operation computes 12801 12802 # Scalar indices 12803 ref[indices, ...] += updates[...] 12804 12805 # Vector indices (for each i) 12806 ref[indices[i], ...] += updates[i, ...] 12807 12808 # High rank indices (for each i, ..., j) 12809 ref[indices[i, ..., j], ...] += updates[i, ..., j, ...] 12810 12811Duplicate entries are handled correctly: if multiple `indices` reference 12812the same location, their contributions add. 12813 12814Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`. 12815 12816<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 12817<img style="width:100%" src='https://www.tensorflow.org/images/ScatterAdd.png' alt> 12818</div> 12819 }]; 12820 12821 let arguments = (ins 12822 Arg<TF_ResourceTensor, [{Should be from a `Variable` node.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 12823 Arg<TF_I32OrI64Tensor, [{A tensor of indices into the first dimension of `ref`.}]>:$indices, 12824 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A tensor of updated values to add to `ref`.}]>:$updates 12825 ); 12826 12827 let results = (outs); 12828 12829 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 12830 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<2>; 12831} 12832 12833def TF_ResourceScatterDivOp : TF_Op<"ResourceScatterDiv", []> { 12834 let summary = [{ 12835Divides sparse updates into the variable referenced by `resource`. 12836 }]; 12837 12838 let description = [{ 12839This operation computes 12840 12841 # Scalar indices 12842 ref[indices, ...] /= updates[...] 12843 12844 # Vector indices (for each i) 12845 ref[indices[i], ...] /= updates[i, ...] 12846 12847 # High rank indices (for each i, ..., j) 12848 ref[indices[i, ..., j], ...] /= updates[i, ..., j, ...] 12849 12850Duplicate entries are handled correctly: if multiple `indices` reference 12851the same location, their contributions multiply. 12852 12853Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`. 12854 12855<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 12856<img style="width:100%" src='https://www.tensorflow.org/images/ScatterAdd.png' alt> 12857</div> 12858 }]; 12859 12860 let arguments = (ins 12861 Arg<TF_ResourceTensor, [{Should be from a `Variable` node.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 12862 Arg<TF_I32OrI64Tensor, [{A tensor of indices into the first dimension of `ref`.}]>:$indices, 12863 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A tensor of updated values to add to `ref`.}]>:$updates 12864 ); 12865 12866 let results = (outs); 12867 12868 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 12869 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<2>; 12870} 12871 12872def TF_ResourceScatterMaxOp : TF_Op<"ResourceScatterMax", []> { 12873 let summary = [{ 12874Reduces sparse updates into the variable referenced by `resource` using the `max` operation. 12875 }]; 12876 12877 let description = [{ 12878This operation computes 12879 12880 # Scalar indices 12881 ref[indices, ...] = max(ref[indices, ...], updates[...]) 12882 12883 # Vector indices (for each i) 12884 ref[indices[i], ...] = max(ref[indices[i], ...], updates[i, ...]) 12885 12886 # High rank indices (for each i, ..., j) 12887 ref[indices[i, ..., j], ...] = max(ref[indices[i, ..., j], ...], updates[i, ..., j, ...]) 12888 12889Duplicate entries are handled correctly: if multiple `indices` reference 12890the same location, their contributions are combined. 12891 12892Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`. 12893 12894<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 12895<img style="width:100%" src='https://www.tensorflow.org/images/ScatterAdd.png' alt> 12896</div> 12897 }]; 12898 12899 let arguments = (ins 12900 Arg<TF_ResourceTensor, [{Should be from a `Variable` node.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 12901 Arg<TF_I32OrI64Tensor, [{A tensor of indices into the first dimension of `ref`.}]>:$indices, 12902 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A tensor of updated values to add to `ref`.}]>:$updates 12903 ); 12904 12905 let results = (outs); 12906 12907 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 12908 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<2>; 12909} 12910 12911def TF_ResourceScatterMinOp : TF_Op<"ResourceScatterMin", []> { 12912 let summary = [{ 12913Reduces sparse updates into the variable referenced by `resource` using the `min` operation. 12914 }]; 12915 12916 let description = [{ 12917This operation computes 12918 12919 # Scalar indices 12920 ref[indices, ...] = min(ref[indices, ...], updates[...]) 12921 12922 # Vector indices (for each i) 12923 ref[indices[i], ...] = min(ref[indices[i], ...], updates[i, ...]) 12924 12925 # High rank indices (for each i, ..., j) 12926 ref[indices[i, ..., j], ...] = min(ref[indices[i, ..., j], ...], updates[i, ..., j, ...]) 12927 12928Duplicate entries are handled correctly: if multiple `indices` reference 12929the same location, their contributions are combined. 12930 12931Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`. 12932 12933<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 12934<img style="width:100%" src='https://www.tensorflow.org/images/ScatterAdd.png' alt> 12935</div> 12936 }]; 12937 12938 let arguments = (ins 12939 Arg<TF_ResourceTensor, [{Should be from a `Variable` node.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 12940 Arg<TF_I32OrI64Tensor, [{A tensor of indices into the first dimension of `ref`.}]>:$indices, 12941 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A tensor of updated values to add to `ref`.}]>:$updates 12942 ); 12943 12944 let results = (outs); 12945 12946 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 12947 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<2>; 12948} 12949 12950def TF_ResourceScatterMulOp : TF_Op<"ResourceScatterMul", []> { 12951 let summary = [{ 12952Multiplies sparse updates into the variable referenced by `resource`. 12953 }]; 12954 12955 let description = [{ 12956This operation computes 12957 12958 # Scalar indices 12959 ref[indices, ...] *= updates[...] 12960 12961 # Vector indices (for each i) 12962 ref[indices[i], ...] *= updates[i, ...] 12963 12964 # High rank indices (for each i, ..., j) 12965 ref[indices[i, ..., j], ...] *= updates[i, ..., j, ...] 12966 12967Duplicate entries are handled correctly: if multiple `indices` reference 12968the same location, their contributions multiply. 12969 12970Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`. 12971 12972<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 12973<img style="width:100%" src='https://www.tensorflow.org/images/ScatterAdd.png' alt> 12974</div> 12975 }]; 12976 12977 let arguments = (ins 12978 Arg<TF_ResourceTensor, [{Should be from a `Variable` node.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 12979 Arg<TF_I32OrI64Tensor, [{A tensor of indices into the first dimension of `ref`.}]>:$indices, 12980 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A tensor of updated values to add to `ref`.}]>:$updates 12981 ); 12982 12983 let results = (outs); 12984 12985 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 12986 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<2>; 12987} 12988 12989def TF_ResourceScatterNdAddOp : TF_Op<"ResourceScatterNdAdd", []> { 12990 let summary = [{ 12991Applies sparse addition to individual values or slices in a Variable. 12992 }]; 12993 12994 let description = [{ 12995`ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. 12996 12997`indices` must be integer tensor, containing indices into `ref`. 12998It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. 12999 13000The innermost dimension of `indices` (with length `K`) corresponds to 13001indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th 13002dimension of `ref`. 13003 13004`updates` is `Tensor` of rank `Q-1+P-K` with shape: 13005 13006``` 13007[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]] 13008``` 13009 13010For example, say we want to add 4 scattered elements to a rank-1 tensor to 130118 elements. In Python, that addition would look like this: 13012 13013```python 13014ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8], use_resource=True) 13015indices = tf.constant([[4], [3], [1], [7]]) 13016updates = tf.constant([9, 10, 11, 12]) 13017add = tf.scatter_nd_add(ref, indices, updates) 13018with tf.Session() as sess: 13019 print sess.run(add) 13020``` 13021 13022The resulting update to ref would look like this: 13023 13024 [1, 13, 3, 14, 14, 6, 7, 20] 13025 13026See `tf.scatter_nd` for more details about how to make updates to 13027slices. 13028 }]; 13029 13030 let arguments = (ins 13031 Arg<TF_ResourceTensor, [{A resource handle. Must be from a VarHandleOp.}], [TF_VariableRead, TF_VariableWrite]>:$ref, 13032 Arg<TF_I32OrI64Tensor, [{A Tensor. Must be one of the following types: int32, int64. 13033A tensor of indices into ref.}]>:$indices, 13034 Arg<TF_Tensor, [{A Tensor. Must have the same type as ref. A tensor of 13035values to add to ref.}]>:$updates, 13036 13037 DefaultValuedAttr<BoolAttr, "true">:$use_locking 13038 ); 13039 13040 let results = (outs); 13041 13042 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 13043 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 13044} 13045 13046def TF_ResourceScatterNdSubOp : TF_Op<"ResourceScatterNdSub", []> { 13047 let summary = [{ 13048Applies sparse subtraction to individual values or slices in a Variable. 13049 }]; 13050 13051 let description = [{ 13052`ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. 13053 13054`indices` must be integer tensor, containing indices into `ref`. 13055It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. 13056 13057The innermost dimension of `indices` (with length `K`) corresponds to 13058indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th 13059dimension of `ref`. 13060 13061`updates` is `Tensor` of rank `Q-1+P-K` with shape: 13062 13063``` 13064[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]] 13065``` 13066 13067For example, say we want to subtract 4 scattered elements from a rank-1 tensor 13068with 8 elements. In Python, that subtraction would look like this: 13069 13070```python 13071ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8], use_resource=True) 13072indices = tf.constant([[4], [3], [1], [7]]) 13073updates = tf.constant([9, 10, 11, 12]) 13074sub = tf.scatter_nd_sub(ref, indices, updates) 13075with tf.Session() as sess: 13076 print sess.run(sub) 13077``` 13078 13079The resulting update to ref would look like this: 13080 13081 [1, -9, 3, -6, -4, 6, 7, -4] 13082 13083See `tf.scatter_nd` for more details about how to make updates to 13084slices. 13085 }]; 13086 13087 let arguments = (ins 13088 Arg<TF_ResourceTensor, [{A resource handle. Must be from a VarHandleOp.}], [TF_VariableRead, TF_VariableWrite]>:$ref, 13089 Arg<TF_I32OrI64Tensor, [{A Tensor. Must be one of the following types: int32, int64. 13090A tensor of indices into ref.}]>:$indices, 13091 Arg<TF_Tensor, [{A Tensor. Must have the same type as ref. A tensor of 13092values to add to ref.}]>:$updates, 13093 13094 DefaultValuedAttr<BoolAttr, "true">:$use_locking 13095 ); 13096 13097 let results = (outs); 13098 13099 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 13100 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 13101} 13102 13103def TF_ResourceScatterNdUpdateOp : TF_Op<"ResourceScatterNdUpdate", []> { 13104 let summary = [{ 13105Applies sparse `updates` to individual values or slices within a given 13106 }]; 13107 13108 let description = [{ 13109variable according to `indices`. 13110 13111`ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`. 13112 13113`indices` must be integer tensor, containing indices into `ref`. 13114It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`. 13115 13116The innermost dimension of `indices` (with length `K`) corresponds to 13117indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th 13118dimension of `ref`. 13119 13120`updates` is `Tensor` of rank `Q-1+P-K` with shape: 13121 13122``` 13123[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]. 13124``` 13125 13126For example, say we want to update 4 scattered elements to a rank-1 tensor to 131278 elements. In Python, that update would look like this: 13128 13129```python 13130 ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) 13131 indices = tf.constant([[4], [3], [1] ,[7]]) 13132 updates = tf.constant([9, 10, 11, 12]) 13133 update = tf.scatter_nd_update(ref, indices, updates) 13134 with tf.Session() as sess: 13135 print sess.run(update) 13136``` 13137 13138The resulting update to ref would look like this: 13139 13140 [1, 11, 3, 10, 9, 6, 7, 12] 13141 13142See `tf.scatter_nd` for more details about how to make updates to 13143slices. 13144 }]; 13145 13146 let arguments = (ins 13147 Arg<TF_ResourceTensor, [{A resource handle. Must be from a VarHandleOp.}], [TF_VariableRead, TF_VariableWrite]>:$ref, 13148 Arg<TF_I32OrI64Tensor, [{A Tensor. Must be one of the following types: int32, int64. 13149A tensor of indices into ref.}]>:$indices, 13150 Arg<TF_Tensor, [{A Tensor. Must have the same type as ref. A tensor of updated 13151values to add to ref.}]>:$updates, 13152 13153 DefaultValuedAttr<BoolAttr, "true">:$use_locking 13154 ); 13155 13156 let results = (outs); 13157 13158 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 13159 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 13160} 13161 13162def TF_ResourceScatterSubOp : TF_Op<"ResourceScatterSub", []> { 13163 let summary = [{ 13164Subtracts sparse updates from the variable referenced by `resource`. 13165 }]; 13166 13167 let description = [{ 13168This operation computes 13169 13170 # Scalar indices 13171 ref[indices, ...] -= updates[...] 13172 13173 # Vector indices (for each i) 13174 ref[indices[i], ...] -= updates[i, ...] 13175 13176 # High rank indices (for each i, ..., j) 13177 ref[indices[i, ..., j], ...] -= updates[i, ..., j, ...] 13178 13179Duplicate entries are handled correctly: if multiple `indices` reference 13180the same location, their contributions add. 13181 13182Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`. 13183 13184<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 13185<img style="width:100%" src='https://www.tensorflow.org/images/ScatterAdd.png' alt> 13186</div> 13187 }]; 13188 13189 let arguments = (ins 13190 Arg<TF_ResourceTensor, [{Should be from a `Variable` node.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 13191 Arg<TF_I32OrI64Tensor, [{A tensor of indices into the first dimension of `ref`.}]>:$indices, 13192 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{A tensor of updated values to add to `ref`.}]>:$updates 13193 ); 13194 13195 let results = (outs); 13196 13197 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 13198 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<2>; 13199} 13200 13201def TF_ResourceScatterUpdateOp : TF_Op<"ResourceScatterUpdate", []> { 13202 let summary = [{ 13203Assigns sparse updates to the variable referenced by `resource`. 13204 }]; 13205 13206 let description = [{ 13207This operation computes 13208 13209 # Scalar indices 13210 ref[indices, ...] = updates[...] 13211 13212 # Vector indices (for each i) 13213 ref[indices[i], ...] = updates[i, ...] 13214 13215 # High rank indices (for each i, ..., j) 13216 ref[indices[i, ..., j], ...] = updates[i, ..., j, ...] 13217 }]; 13218 13219 let arguments = (ins 13220 Arg<TF_ResourceTensor, [{Should be from a `Variable` node.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 13221 Arg<TF_I32OrI64Tensor, [{A tensor of indices into the first dimension of `ref`.}]>:$indices, 13222 Arg<TF_Tensor, [{A tensor of updated values to add to `ref`.}]>:$updates 13223 ); 13224 13225 let results = (outs); 13226 13227 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 13228 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<2>; 13229} 13230 13231def TF_ResourceSparseApplyAdagradOp : TF_Op<"ResourceSparseApplyAdagrad", []> { 13232 let summary = [{ 13233Update relevant entries in '*var' and '*accum' according to the adagrad scheme. 13234 }]; 13235 13236 let description = [{ 13237That is for rows we have grad for, we update var and accum as follows: 13238accum += grad * grad 13239var -= lr * grad * (1 / sqrt(accum)) 13240 }]; 13241 13242 let arguments = (ins 13243 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 13244 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 13245 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Learning rate. Must be a scalar.}]>:$lr, 13246 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 13247 Arg<TF_I32OrI64Tensor, [{A vector of indices into the first dimension of var and accum.}]>:$indices, 13248 13249 DefaultValuedAttr<BoolAttr, "false">:$use_locking, 13250 DefaultValuedAttr<BoolAttr, "true">:$update_slots 13251 ); 13252 13253 let results = (outs); 13254 13255 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 13256 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<4>; 13257} 13258 13259def TF_ResourceSparseApplyAdagradV2Op : TF_Op<"ResourceSparseApplyAdagradV2", []> { 13260 let summary = [{ 13261Update relevant entries in '*var' and '*accum' according to the adagrad scheme. 13262 }]; 13263 13264 let description = [{ 13265That is for rows we have grad for, we update var and accum as follows: 13266accum += grad * grad 13267var -= lr * grad * (1 / sqrt(accum)) 13268 }]; 13269 13270 let arguments = (ins 13271 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 13272 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 13273 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Learning rate. Must be a scalar.}]>:$lr, 13274 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Constant factor. Must be a scalar.}]>:$epsilon, 13275 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 13276 Arg<TF_I32OrI64Tensor, [{A vector of indices into the first dimension of var and accum.}]>:$indices, 13277 13278 DefaultValuedAttr<BoolAttr, "false">:$use_locking, 13279 DefaultValuedAttr<BoolAttr, "true">:$update_slots 13280 ); 13281 13282 let results = (outs); 13283 13284 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 13285 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<5>; 13286} 13287 13288def TF_ResourceSparseApplyFtrlOp : TF_Op<"ResourceSparseApplyFtrl", []> { 13289 let summary = [{ 13290Update relevant entries in '*var' according to the Ftrl-proximal scheme. 13291 }]; 13292 13293 let description = [{ 13294That is for rows we have grad for, we update var, accum and linear as follows: 13295accum_new = accum + grad * grad 13296linear += grad - (accum_new^(-lr_power) - accum^(-lr_power)) / lr * var 13297quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 13298var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 13299accum = accum_new 13300 }]; 13301 13302 let arguments = (ins 13303 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$var, 13304 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$accum, 13305 Arg<TF_ResourceTensor, [{Should be from a Variable().}], [TF_VariableRead, TF_VariableWrite]>:$linear, 13306 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The gradient.}]>:$grad, 13307 Arg<TF_I32OrI64Tensor, [{A vector of indices into the first dimension of var and accum.}]>:$indices, 13308 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr, 13309 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L1 regularization. Must be a scalar.}]>:$l1, 13310 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{L2 regularization. Must be a scalar.}]>:$l2, 13311 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Scaling factor. Must be a scalar.}]>:$lr_power, 13312 13313 DefaultValuedAttr<BoolAttr, "false">:$use_locking, 13314 DefaultValuedAttr<BoolAttr, "false">:$multiply_linear_by_lr 13315 ); 13316 13317 let results = (outs); 13318 13319 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<3>; 13320 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<4>; 13321} 13322 13323def TF_ResourceStridedSliceAssignOp : TF_Op<"ResourceStridedSliceAssign", []> { 13324 let summary = "Assign `value` to the sliced l-value reference of `ref`."; 13325 13326 let description = [{ 13327The values of `value` are assigned to the positions in the variable 13328`ref` that are selected by the slice parameters. The slice parameters 13329`begin, `end`, `strides`, etc. work exactly as in `StridedSlice`. 13330 13331NOTE this op currently does not support broadcasting and so `value`'s 13332shape must be exactly the shape produced by the slice of `ref`. 13333 }]; 13334 13335 let arguments = (ins 13336 Arg<TF_ResourceTensor, "", [TF_VariableRead, TF_VariableWrite]>:$ref, 13337 TF_I32OrI64Tensor:$begin, 13338 TF_I32OrI64Tensor:$end, 13339 TF_I32OrI64Tensor:$strides, 13340 TF_Tensor:$value, 13341 13342 DefaultValuedAttr<I64Attr, "0">:$begin_mask, 13343 DefaultValuedAttr<I64Attr, "0">:$end_mask, 13344 DefaultValuedAttr<I64Attr, "0">:$ellipsis_mask, 13345 DefaultValuedAttr<I64Attr, "0">:$new_axis_mask, 13346 DefaultValuedAttr<I64Attr, "0">:$shrink_axis_mask 13347 ); 13348 13349 let results = (outs); 13350 13351 TF_DerivedOperandTypeAttr Index = TF_DerivedOperandTypeAttr<1>; 13352 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<4>; 13353} 13354 13355def TF_RestoreOp : TF_Op<"Restore", []> { 13356 let summary = "Restores a tensor from checkpoint files."; 13357 13358 let description = [{ 13359Reads a tensor stored in one or several files. If there are several files (for 13360instance because a tensor was saved as slices), `file_pattern` may contain 13361wildcard symbols (`*` and `?`) in the filename portion only, not in the 13362directory portion. 13363 13364If a `file_pattern` matches several files, `preferred_shard` can be used to hint 13365in which file the requested tensor is likely to be found. This op will first 13366open the file at index `preferred_shard` in the list of matching files and try 13367to restore tensors from that file. Only if some tensors or tensor slices are 13368not found in that first file, then the Op opens all the files. Setting 13369`preferred_shard` to match the value passed as the `shard` input 13370of a matching `Save` Op may speed up Restore. This attribute only affects 13371performance, not correctness. The default value -1 means files are processed in 13372order. 13373 13374See also `RestoreSlice`. 13375 }]; 13376 13377 let arguments = (ins 13378 Arg<TF_StrTensor, [{Must have a single element. The pattern of the files from 13379which we read the tensor.}]>:$file_pattern, 13380 Arg<TF_StrTensor, [{Must have a single element. The name of the tensor to be 13381restored.}]>:$tensor_name, 13382 13383 DefaultValuedAttr<I64Attr, "-1">:$preferred_shard 13384 ); 13385 13386 let results = (outs 13387 Res<TF_Tensor, [{The restored tensor.}]>:$tensor 13388 ); 13389 13390 TF_DerivedResultTypeAttr dt = TF_DerivedResultTypeAttr<0>; 13391} 13392 13393def TF_RestoreV2Op : TF_Op<"RestoreV2", []> { 13394 let summary = "Restores tensors from a V2 checkpoint."; 13395 13396 let description = [{ 13397For backward compatibility with the V1 format, this Op currently allows 13398restoring from a V1 checkpoint as well: 13399 - This Op first attempts to find the V2 index file pointed to by "prefix", and 13400 if found proceed to read it as a V2 checkpoint; 13401 - Otherwise the V1 read path is invoked. 13402Relying on this behavior is not recommended, as the ability to fall back to read 13403V1 might be deprecated and eventually removed. 13404 13405By default, restores the named tensors in full. If the caller wishes to restore 13406specific slices of stored tensors, "shape_and_slices" should be non-empty 13407strings and correspondingly well-formed. 13408 13409Callers must ensure all the named tensors are indeed stored in the checkpoint. 13410 }]; 13411 13412 let arguments = (ins 13413 Arg<TF_StrTensor, [{Must have a single element. The prefix of a V2 checkpoint.}]>:$prefix, 13414 Arg<TF_StrTensor, [{shape {N}. The names of the tensors to be restored.}]>:$tensor_names, 13415 Arg<TF_StrTensor, [{shape {N}. The slice specs of the tensors to be restored. 13416Empty strings indicate that they are non-partitioned tensors.}]>:$shape_and_slices 13417 ); 13418 13419 let results = (outs 13420 Res<Variadic<TF_Tensor>, [{shape {N}. The restored tensors, whose shapes are read from the 13421checkpoint directly.}]>:$tensors 13422 ); 13423 13424 TF_DerivedResultTypeListAttr dtypes = TF_DerivedResultTypeListAttr<0>; 13425} 13426 13427def TF_RetrieveTPUEmbeddingADAMParametersOp : TF_Op<"RetrieveTPUEmbeddingADAMParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13428 let summary = "Retrieve ADAM embedding parameters."; 13429 13430 let description = [{ 13431An op that retrieves optimization parameters from embedding to host 13432memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up 13433the correct embedding table configuration. For example, this op is 13434used to retrieve updated parameters before saving a checkpoint. 13435 }]; 13436 13437 let arguments = (ins 13438 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13439 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13440 I64Attr:$num_shards, 13441 I64Attr:$shard_id, 13442 DefaultValuedAttr<StrAttr, "\"\"">:$config 13443 ); 13444 13445 let results = (outs 13446 Res<TF_Float32Tensor, [{Parameter parameters updated by the ADAM optimization algorithm.}]>:$parameters, 13447 Res<TF_Float32Tensor, [{Parameter momenta updated by the ADAM optimization algorithm.}]>:$momenta, 13448 Res<TF_Float32Tensor, [{Parameter velocities updated by the ADAM optimization algorithm.}]>:$velocities 13449 ); 13450} 13451 13452def TF_RetrieveTPUEmbeddingADAMParametersGradAccumDebugOp : TF_Op<"RetrieveTPUEmbeddingADAMParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13453 let summary = ""; 13454 13455 let arguments = (ins 13456 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13457 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13458 I64Attr:$num_shards, 13459 I64Attr:$shard_id, 13460 DefaultValuedAttr<StrAttr, "\"\"">:$config 13461 ); 13462 13463 let results = (outs 13464 TF_Float32Tensor:$parameters, 13465 TF_Float32Tensor:$momenta, 13466 TF_Float32Tensor:$velocities, 13467 TF_Float32Tensor:$gradient_accumulators 13468 ); 13469} 13470 13471def TF_RetrieveTPUEmbeddingAdadeltaParametersOp : TF_Op<"RetrieveTPUEmbeddingAdadeltaParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13472 let summary = "Retrieve Adadelta embedding parameters."; 13473 13474 let description = [{ 13475An op that retrieves optimization parameters from embedding to host 13476memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up 13477the correct embedding table configuration. For example, this op is 13478used to retrieve updated parameters before saving a checkpoint. 13479 }]; 13480 13481 let arguments = (ins 13482 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13483 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13484 I64Attr:$num_shards, 13485 I64Attr:$shard_id, 13486 DefaultValuedAttr<StrAttr, "\"\"">:$config 13487 ); 13488 13489 let results = (outs 13490 Res<TF_Float32Tensor, [{Parameter parameters updated by the Adadelta optimization algorithm.}]>:$parameters, 13491 Res<TF_Float32Tensor, [{Parameter accumulators updated by the Adadelta optimization algorithm.}]>:$accumulators, 13492 Res<TF_Float32Tensor, [{Parameter updates updated by the Adadelta optimization algorithm.}]>:$updates 13493 ); 13494} 13495 13496def TF_RetrieveTPUEmbeddingAdadeltaParametersGradAccumDebugOp : TF_Op<"RetrieveTPUEmbeddingAdadeltaParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13497 let summary = ""; 13498 13499 let arguments = (ins 13500 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13501 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13502 I64Attr:$num_shards, 13503 I64Attr:$shard_id, 13504 DefaultValuedAttr<StrAttr, "\"\"">:$config 13505 ); 13506 13507 let results = (outs 13508 TF_Float32Tensor:$parameters, 13509 TF_Float32Tensor:$accumulators, 13510 TF_Float32Tensor:$updates, 13511 TF_Float32Tensor:$gradient_accumulators 13512 ); 13513} 13514 13515def TF_RetrieveTPUEmbeddingAdagradParametersOp : TF_Op<"RetrieveTPUEmbeddingAdagradParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13516 let summary = "Retrieve Adagrad embedding parameters."; 13517 13518 let description = [{ 13519An op that retrieves optimization parameters from embedding to host 13520memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up 13521the correct embedding table configuration. For example, this op is 13522used to retrieve updated parameters before saving a checkpoint. 13523 }]; 13524 13525 let arguments = (ins 13526 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13527 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13528 I64Attr:$num_shards, 13529 I64Attr:$shard_id, 13530 DefaultValuedAttr<StrAttr, "\"\"">:$config 13531 ); 13532 13533 let results = (outs 13534 Res<TF_Float32Tensor, [{Parameter parameters updated by the Adagrad optimization algorithm.}]>:$parameters, 13535 Res<TF_Float32Tensor, [{Parameter accumulators updated by the Adagrad optimization algorithm.}]>:$accumulators 13536 ); 13537} 13538 13539def TF_RetrieveTPUEmbeddingAdagradParametersGradAccumDebugOp : TF_Op<"RetrieveTPUEmbeddingAdagradParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13540 let summary = ""; 13541 13542 let arguments = (ins 13543 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13544 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13545 I64Attr:$num_shards, 13546 I64Attr:$shard_id, 13547 DefaultValuedAttr<StrAttr, "\"\"">:$config 13548 ); 13549 13550 let results = (outs 13551 TF_Float32Tensor:$parameters, 13552 TF_Float32Tensor:$accumulators, 13553 TF_Float32Tensor:$gradient_accumulators 13554 ); 13555} 13556 13557def TF_RetrieveTPUEmbeddingCenteredRMSPropParametersOp : TF_Op<"RetrieveTPUEmbeddingCenteredRMSPropParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13558 let summary = "Retrieve centered RMSProp embedding parameters."; 13559 13560 let description = [{ 13561An op that retrieves optimization parameters from embedding to host 13562memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up 13563the correct embedding table configuration. For example, this op is 13564used to retrieve updated parameters before saving a checkpoint. 13565 }]; 13566 13567 let arguments = (ins 13568 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13569 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13570 I64Attr:$num_shards, 13571 I64Attr:$shard_id, 13572 DefaultValuedAttr<StrAttr, "\"\"">:$config 13573 ); 13574 13575 let results = (outs 13576 Res<TF_Float32Tensor, [{Parameter parameters updated by the centered RMSProp optimization algorithm.}]>:$parameters, 13577 Res<TF_Float32Tensor, [{Parameter ms updated by the centered RMSProp optimization algorithm.}]>:$ms, 13578 Res<TF_Float32Tensor, [{Parameter mom updated by the centered RMSProp optimization algorithm.}]>:$mom, 13579 Res<TF_Float32Tensor, [{Parameter mg updated by the centered RMSProp optimization algorithm.}]>:$mg 13580 ); 13581} 13582 13583def TF_RetrieveTPUEmbeddingFTRLParametersOp : TF_Op<"RetrieveTPUEmbeddingFTRLParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13584 let summary = "Retrieve FTRL embedding parameters."; 13585 13586 let description = [{ 13587An op that retrieves optimization parameters from embedding to host 13588memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up 13589the correct embedding table configuration. For example, this op is 13590used to retrieve updated parameters before saving a checkpoint. 13591 }]; 13592 13593 let arguments = (ins 13594 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13595 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13596 I64Attr:$num_shards, 13597 I64Attr:$shard_id, 13598 DefaultValuedAttr<StrAttr, "\"\"">:$config 13599 ); 13600 13601 let results = (outs 13602 Res<TF_Float32Tensor, [{Parameter parameters updated by the FTRL optimization algorithm.}]>:$parameters, 13603 Res<TF_Float32Tensor, [{Parameter accumulators updated by the FTRL optimization algorithm.}]>:$accumulators, 13604 Res<TF_Float32Tensor, [{Parameter linears updated by the FTRL optimization algorithm.}]>:$linears 13605 ); 13606} 13607 13608def TF_RetrieveTPUEmbeddingFTRLParametersGradAccumDebugOp : TF_Op<"RetrieveTPUEmbeddingFTRLParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13609 let summary = ""; 13610 13611 let arguments = (ins 13612 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13613 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13614 I64Attr:$num_shards, 13615 I64Attr:$shard_id, 13616 DefaultValuedAttr<StrAttr, "\"\"">:$config 13617 ); 13618 13619 let results = (outs 13620 TF_Float32Tensor:$parameters, 13621 TF_Float32Tensor:$accumulators, 13622 TF_Float32Tensor:$linears, 13623 TF_Float32Tensor:$gradient_accumulators 13624 ); 13625} 13626 13627def TF_RetrieveTPUEmbeddingMDLAdagradLightParametersOp : TF_Op<"RetrieveTPUEmbeddingMDLAdagradLightParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13628 let summary = "Retrieve MDL Adagrad Light embedding parameters."; 13629 13630 let description = [{ 13631An op that retrieves optimization parameters from embedding to host 13632memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up 13633the correct embedding table configuration. For example, this op is 13634used to retrieve updated parameters before saving a checkpoint. 13635 }]; 13636 13637 let arguments = (ins 13638 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13639 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13640 I64Attr:$num_shards, 13641 I64Attr:$shard_id, 13642 DefaultValuedAttr<StrAttr, "\"\"">:$config 13643 ); 13644 13645 let results = (outs 13646 Res<TF_Float32Tensor, [{Parameter parameters updated by the MDL Adagrad Light optimization algorithm.}]>:$parameters, 13647 Res<TF_Float32Tensor, [{Parameter accumulators updated by the MDL Adagrad Light optimization algorithm.}]>:$accumulators, 13648 Res<TF_Float32Tensor, [{Parameter weights updated by the MDL Adagrad Light optimization algorithm.}]>:$weights, 13649 Res<TF_Float32Tensor, [{Parameter benefits updated by the MDL Adagrad Light optimization algorithm.}]>:$benefits 13650 ); 13651} 13652 13653def TF_RetrieveTPUEmbeddingMomentumParametersOp : TF_Op<"RetrieveTPUEmbeddingMomentumParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13654 let summary = "Retrieve Momentum embedding parameters."; 13655 13656 let description = [{ 13657An op that retrieves optimization parameters from embedding to host 13658memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up 13659the correct embedding table configuration. For example, this op is 13660used to retrieve updated parameters before saving a checkpoint. 13661 }]; 13662 13663 let arguments = (ins 13664 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13665 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13666 I64Attr:$num_shards, 13667 I64Attr:$shard_id, 13668 DefaultValuedAttr<StrAttr, "\"\"">:$config 13669 ); 13670 13671 let results = (outs 13672 Res<TF_Float32Tensor, [{Parameter parameters updated by the Momentum optimization algorithm.}]>:$parameters, 13673 Res<TF_Float32Tensor, [{Parameter momenta updated by the Momentum optimization algorithm.}]>:$momenta 13674 ); 13675} 13676 13677def TF_RetrieveTPUEmbeddingMomentumParametersGradAccumDebugOp : TF_Op<"RetrieveTPUEmbeddingMomentumParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13678 let summary = ""; 13679 13680 let arguments = (ins 13681 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13682 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13683 I64Attr:$num_shards, 13684 I64Attr:$shard_id, 13685 DefaultValuedAttr<StrAttr, "\"\"">:$config 13686 ); 13687 13688 let results = (outs 13689 TF_Float32Tensor:$parameters, 13690 TF_Float32Tensor:$momenta, 13691 TF_Float32Tensor:$gradient_accumulators 13692 ); 13693} 13694 13695def TF_RetrieveTPUEmbeddingProximalAdagradParametersOp : TF_Op<"RetrieveTPUEmbeddingProximalAdagradParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13696 let summary = "Retrieve proximal Adagrad embedding parameters."; 13697 13698 let description = [{ 13699An op that retrieves optimization parameters from embedding to host 13700memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up 13701the correct embedding table configuration. For example, this op is 13702used to retrieve updated parameters before saving a checkpoint. 13703 }]; 13704 13705 let arguments = (ins 13706 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13707 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13708 I64Attr:$num_shards, 13709 I64Attr:$shard_id, 13710 DefaultValuedAttr<StrAttr, "\"\"">:$config 13711 ); 13712 13713 let results = (outs 13714 Res<TF_Float32Tensor, [{Parameter parameters updated by the proximal Adagrad optimization algorithm.}]>:$parameters, 13715 Res<TF_Float32Tensor, [{Parameter accumulators updated by the proximal Adagrad optimization algorithm.}]>:$accumulators 13716 ); 13717} 13718 13719def TF_RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebugOp : TF_Op<"RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13720 let summary = ""; 13721 13722 let arguments = (ins 13723 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13724 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13725 I64Attr:$num_shards, 13726 I64Attr:$shard_id, 13727 DefaultValuedAttr<StrAttr, "\"\"">:$config 13728 ); 13729 13730 let results = (outs 13731 TF_Float32Tensor:$parameters, 13732 TF_Float32Tensor:$accumulators, 13733 TF_Float32Tensor:$gradient_accumulators 13734 ); 13735} 13736 13737def TF_RetrieveTPUEmbeddingProximalYogiParametersOp : TF_Op<"RetrieveTPUEmbeddingProximalYogiParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13738 let summary = ""; 13739 13740 let arguments = (ins 13741 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13742 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13743 I64Attr:$num_shards, 13744 I64Attr:$shard_id, 13745 DefaultValuedAttr<StrAttr, "\"\"">:$config 13746 ); 13747 13748 let results = (outs 13749 TF_Float32Tensor:$parameters, 13750 TF_Float32Tensor:$v, 13751 TF_Float32Tensor:$m 13752 ); 13753} 13754 13755def TF_RetrieveTPUEmbeddingProximalYogiParametersGradAccumDebugOp : TF_Op<"RetrieveTPUEmbeddingProximalYogiParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13756 let summary = ""; 13757 13758 let arguments = (ins 13759 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13760 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13761 I64Attr:$num_shards, 13762 I64Attr:$shard_id, 13763 DefaultValuedAttr<StrAttr, "\"\"">:$config 13764 ); 13765 13766 let results = (outs 13767 TF_Float32Tensor:$parameters, 13768 TF_Float32Tensor:$v, 13769 TF_Float32Tensor:$m, 13770 TF_Float32Tensor:$gradient_accumulators 13771 ); 13772} 13773 13774def TF_RetrieveTPUEmbeddingRMSPropParametersOp : TF_Op<"RetrieveTPUEmbeddingRMSPropParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13775 let summary = "Retrieve RMSProp embedding parameters."; 13776 13777 let description = [{ 13778An op that retrieves optimization parameters from embedding to host 13779memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up 13780the correct embedding table configuration. For example, this op is 13781used to retrieve updated parameters before saving a checkpoint. 13782 }]; 13783 13784 let arguments = (ins 13785 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13786 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13787 I64Attr:$num_shards, 13788 I64Attr:$shard_id, 13789 DefaultValuedAttr<StrAttr, "\"\"">:$config 13790 ); 13791 13792 let results = (outs 13793 Res<TF_Float32Tensor, [{Parameter parameters updated by the RMSProp optimization algorithm.}]>:$parameters, 13794 Res<TF_Float32Tensor, [{Parameter ms updated by the RMSProp optimization algorithm.}]>:$ms, 13795 Res<TF_Float32Tensor, [{Parameter mom updated by the RMSProp optimization algorithm.}]>:$mom 13796 ); 13797} 13798 13799def TF_RetrieveTPUEmbeddingRMSPropParametersGradAccumDebugOp : TF_Op<"RetrieveTPUEmbeddingRMSPropParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13800 let summary = ""; 13801 13802 let arguments = (ins 13803 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13804 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13805 I64Attr:$num_shards, 13806 I64Attr:$shard_id, 13807 DefaultValuedAttr<StrAttr, "\"\"">:$config 13808 ); 13809 13810 let results = (outs 13811 TF_Float32Tensor:$parameters, 13812 TF_Float32Tensor:$ms, 13813 TF_Float32Tensor:$mom, 13814 TF_Float32Tensor:$gradient_accumulators 13815 ); 13816} 13817 13818def TF_RetrieveTPUEmbeddingStochasticGradientDescentParametersOp : TF_Op<"RetrieveTPUEmbeddingStochasticGradientDescentParameters", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13819 let summary = "Retrieve SGD embedding parameters."; 13820 13821 let description = [{ 13822An op that retrieves optimization parameters from embedding to host 13823memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up 13824the correct embedding table configuration. For example, this op is 13825used to retrieve updated parameters before saving a checkpoint. 13826 }]; 13827 13828 let arguments = (ins 13829 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13830 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13831 I64Attr:$num_shards, 13832 I64Attr:$shard_id, 13833 DefaultValuedAttr<StrAttr, "\"\"">:$config 13834 ); 13835 13836 let results = (outs 13837 Res<TF_Float32Tensor, [{Parameter parameters updated by the stochastic gradient descent optimization algorithm.}]>:$parameters 13838 ); 13839} 13840 13841def TF_RetrieveTPUEmbeddingStochasticGradientDescentParametersGradAccumDebugOp : TF_Op<"RetrieveTPUEmbeddingStochasticGradientDescentParametersGradAccumDebug", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 13842 let summary = ""; 13843 13844 let arguments = (ins 13845 DefaultValuedAttr<I64Attr, "-1">:$table_id, 13846 DefaultValuedAttr<StrAttr, "\"\"">:$table_name, 13847 I64Attr:$num_shards, 13848 I64Attr:$shard_id, 13849 DefaultValuedAttr<StrAttr, "\"\"">:$config 13850 ); 13851 13852 let results = (outs 13853 TF_Float32Tensor:$parameters, 13854 TF_Float32Tensor:$gradient_accumulators 13855 ); 13856} 13857 13858def TF_ReverseOp : TF_Op<"Reverse", [NoSideEffect]> { 13859 let summary = "Reverses specific dimensions of a tensor."; 13860 13861 let description = [{ 13862Given a `tensor`, and a `bool` tensor `dims` representing the dimensions 13863of `tensor`, this operation reverses each dimension i of `tensor` where 13864`dims[i]` is `True`. 13865 13866`tensor` can have up to 8 dimensions. The number of dimensions 13867of `tensor` must equal the number of elements in `dims`. In other words: 13868 13869`rank(tensor) = size(dims)` 13870 13871For example: 13872 13873``` 13874# tensor 't' is [[[[ 0, 1, 2, 3], 13875# [ 4, 5, 6, 7], 13876# [ 8, 9, 10, 11]], 13877# [[12, 13, 14, 15], 13878# [16, 17, 18, 19], 13879# [20, 21, 22, 23]]]] 13880# tensor 't' shape is [1, 2, 3, 4] 13881 13882# 'dims' is [False, False, False, True] 13883reverse(t, dims) ==> [[[[ 3, 2, 1, 0], 13884 [ 7, 6, 5, 4], 13885 [ 11, 10, 9, 8]], 13886 [[15, 14, 13, 12], 13887 [19, 18, 17, 16], 13888 [23, 22, 21, 20]]]] 13889 13890# 'dims' is [False, True, False, False] 13891reverse(t, dims) ==> [[[[12, 13, 14, 15], 13892 [16, 17, 18, 19], 13893 [20, 21, 22, 23] 13894 [[ 0, 1, 2, 3], 13895 [ 4, 5, 6, 7], 13896 [ 8, 9, 10, 11]]]] 13897 13898# 'dims' is [False, False, True, False] 13899reverse(t, dims) ==> [[[[8, 9, 10, 11], 13900 [4, 5, 6, 7], 13901 [0, 1, 2, 3]] 13902 [[20, 21, 22, 23], 13903 [16, 17, 18, 19], 13904 [12, 13, 14, 15]]]] 13905``` 13906 }]; 13907 13908 let arguments = (ins 13909 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Str, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Up to 8-D.}]>:$tensor, 13910 Arg<TF_BoolTensor, [{1-D. The dimensions to reverse.}]>:$dims 13911 ); 13912 13913 let results = (outs 13914 Res<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Str, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The same shape as `tensor`.}]>:$output 13915 ); 13916 13917 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 13918} 13919 13920def TF_ReverseSequenceOp : TF_Op<"ReverseSequence", [NoSideEffect]> { 13921 let summary = "Reverses variable length slices."; 13922 13923 let description = [{ 13924This op first slices `input` along the dimension `batch_dim`, and for each 13925slice `i`, reverses the first `seq_lengths[i]` elements along 13926the dimension `seq_dim`. 13927 13928The elements of `seq_lengths` must obey `seq_lengths[i] <= input.dims[seq_dim]`, 13929and `seq_lengths` must be a vector of length `input.dims[batch_dim]`. 13930 13931The output slice `i` along dimension `batch_dim` is then given by input 13932slice `i`, with the first `seq_lengths[i]` slices along dimension 13933`seq_dim` reversed. 13934 13935For example: 13936 13937``` 13938# Given this: 13939batch_dim = 0 13940seq_dim = 1 13941input.dims = (4, 8, ...) 13942seq_lengths = [7, 2, 3, 5] 13943 13944# then slices of input are reversed on seq_dim, but only up to seq_lengths: 13945output[0, 0:7, :, ...] = input[0, 7:0:-1, :, ...] 13946output[1, 0:2, :, ...] = input[1, 2:0:-1, :, ...] 13947output[2, 0:3, :, ...] = input[2, 3:0:-1, :, ...] 13948output[3, 0:5, :, ...] = input[3, 5:0:-1, :, ...] 13949 13950# while entries past seq_lens are copied through: 13951output[0, 7:, :, ...] = input[0, 7:, :, ...] 13952output[1, 2:, :, ...] = input[1, 2:, :, ...] 13953output[2, 3:, :, ...] = input[2, 3:, :, ...] 13954output[3, 2:, :, ...] = input[3, 2:, :, ...] 13955``` 13956 13957In contrast, if: 13958 13959``` 13960# Given this: 13961batch_dim = 2 13962seq_dim = 0 13963input.dims = (8, ?, 4, ...) 13964seq_lengths = [7, 2, 3, 5] 13965 13966# then slices of input are reversed on seq_dim, but only up to seq_lengths: 13967output[0:7, :, 0, :, ...] = input[7:0:-1, :, 0, :, ...] 13968output[0:2, :, 1, :, ...] = input[2:0:-1, :, 1, :, ...] 13969output[0:3, :, 2, :, ...] = input[3:0:-1, :, 2, :, ...] 13970output[0:5, :, 3, :, ...] = input[5:0:-1, :, 3, :, ...] 13971 13972# while entries past seq_lens are copied through: 13973output[7:, :, 0, :, ...] = input[7:, :, 0, :, ...] 13974output[2:, :, 1, :, ...] = input[2:, :, 1, :, ...] 13975output[3:, :, 2, :, ...] = input[3:, :, 2, :, ...] 13976output[2:, :, 3, :, ...] = input[2:, :, 3, :, ...] 13977``` 13978 }]; 13979 13980 let arguments = (ins 13981 Arg<TF_Tensor, [{The input to reverse.}]>:$input, 13982 Arg<TF_I32OrI64Tensor, [{1-D with length `input.dims(batch_dim)` and 13983`max(seq_lengths) <= input.dims(seq_dim)`}]>:$seq_lengths, 13984 13985 I64Attr:$seq_dim, 13986 DefaultValuedAttr<I64Attr, "0">:$batch_dim 13987 ); 13988 13989 let results = (outs 13990 Res<TF_Tensor, [{The partially reversed input. It has the same shape as `input`.}]>:$output 13991 ); 13992 13993 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 13994 TF_DerivedOperandTypeAttr Tlen = TF_DerivedOperandTypeAttr<1>; 13995} 13996 13997def TF_ReverseV2Op : TF_Op<"ReverseV2", [NoSideEffect]> { 13998 let summary = "Reverses specific dimensions of a tensor."; 13999 14000 let description = [{ 14001Given a `tensor`, and a `int32` tensor `axis` representing the set of 14002dimensions of `tensor` to reverse. This operation reverses each dimension 14003`i` for which there exists `j` s.t. `axis[j] == i`. 14004 14005`tensor` can have up to 8 dimensions. The number of dimensions specified 14006in `axis` may be 0 or more entries. If an index is specified more than 14007once, a InvalidArgument error is raised. 14008 14009For example: 14010 14011``` 14012# tensor 't' is [[[[ 0, 1, 2, 3], 14013# [ 4, 5, 6, 7], 14014# [ 8, 9, 10, 11]], 14015# [[12, 13, 14, 15], 14016# [16, 17, 18, 19], 14017# [20, 21, 22, 23]]]] 14018# tensor 't' shape is [1, 2, 3, 4] 14019 14020# 'dims' is [3] or 'dims' is [-1] 14021reverse(t, dims) ==> [[[[ 3, 2, 1, 0], 14022 [ 7, 6, 5, 4], 14023 [ 11, 10, 9, 8]], 14024 [[15, 14, 13, 12], 14025 [19, 18, 17, 16], 14026 [23, 22, 21, 20]]]] 14027 14028# 'dims' is '[1]' (or 'dims' is '[-3]') 14029reverse(t, dims) ==> [[[[12, 13, 14, 15], 14030 [16, 17, 18, 19], 14031 [20, 21, 22, 23] 14032 [[ 0, 1, 2, 3], 14033 [ 4, 5, 6, 7], 14034 [ 8, 9, 10, 11]]]] 14035 14036# 'dims' is '[2]' (or 'dims' is '[-2]') 14037reverse(t, dims) ==> [[[[8, 9, 10, 11], 14038 [4, 5, 6, 7], 14039 [0, 1, 2, 3]] 14040 [[20, 21, 22, 23], 14041 [16, 17, 18, 19], 14042 [12, 13, 14, 15]]]] 14043``` 14044 }]; 14045 14046 let arguments = (ins 14047 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Str, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Up to 8-D.}]>:$tensor, 14048 Arg<TF_I32OrI64Tensor, [{1-D. The indices of the dimensions to reverse. Must be in the range 14049`[-rank(tensor), rank(tensor))`.}]>:$axis 14050 ); 14051 14052 let results = (outs 14053 Res<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Str, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The same shape as `tensor`.}]>:$output 14054 ); 14055 14056 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14057 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 14058} 14059 14060def TF_RightShiftOp : TF_Op<"RightShift", [NoSideEffect, ResultsBroadcastableShape]>, 14061 WithBroadcastableBinOpBuilder { 14062 let summary = "Elementwise computes the bitwise right-shift of `x` and `y`."; 14063 14064 let description = [{ 14065Performs a logical shift for unsigned integer types, and an arithmetic shift 14066for signed integer types. 14067 14068If `y` is negative, or greater than or equal to than the width of `x` in bits 14069the result is implementation defined. 14070 14071Example: 14072 14073```python 14074import tensorflow as tf 14075from tensorflow.python.ops import bitwise_ops 14076import numpy as np 14077dtype_list = [tf.int8, tf.int16, tf.int32, tf.int64] 14078 14079for dtype in dtype_list: 14080 lhs = tf.constant([-1, -5, -3, -14], dtype=dtype) 14081 rhs = tf.constant([5, 0, 7, 11], dtype=dtype) 14082 14083 right_shift_result = bitwise_ops.right_shift(lhs, rhs) 14084 14085 print(right_shift_result) 14086 14087# This will print: 14088# tf.Tensor([-1 -5 -1 -1], shape=(4,), dtype=int8) 14089# tf.Tensor([-1 -5 -1 -1], shape=(4,), dtype=int16) 14090# tf.Tensor([-1 -5 -1 -1], shape=(4,), dtype=int32) 14091# tf.Tensor([-1 -5 -1 -1], shape=(4,), dtype=int64) 14092 14093lhs = np.array([-2, 64, 101, 32], dtype=np.int8) 14094rhs = np.array([-1, -5, -3, -14], dtype=np.int8) 14095bitwise_ops.right_shift(lhs, rhs) 14096# <tf.Tensor: shape=(4,), dtype=int8, numpy=array([ -2, 64, 101, 32], dtype=int8)> 14097``` 14098 }]; 14099 14100 let arguments = (ins 14101 TF_IntTensor:$x, 14102 TF_IntTensor:$y 14103 ); 14104 14105 let results = (outs 14106 TF_IntTensor:$z 14107 ); 14108 14109 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14110} 14111 14112def TF_RintOp : TF_Op<"Rint", [Idempotent, NoSideEffect, SameOperandsAndResultType]> { 14113 let summary = "Returns element-wise integer closest to x."; 14114 14115 let description = [{ 14116If the result is midway between two representable values, 14117the even representable is chosen. 14118For example: 14119 14120``` 14121rint(-1.5) ==> -2.0 14122rint(0.5000001) ==> 1.0 14123rint([-1.7, -1.5, -0.2, 0.2, 1.5, 1.7, 2.0]) ==> [-2., -2., -0., 0., 2., 2., 2.] 14124``` 14125 }]; 14126 14127 let arguments = (ins 14128 TF_FloatTensor:$x 14129 ); 14130 14131 let results = (outs 14132 TF_FloatTensor:$y 14133 ); 14134 14135 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14136} 14137 14138def TF_RiscAddOp : TF_Op<"RiscAdd", [Commutative, NoSideEffect]> { 14139 let summary = "Returns x + y element-wise."; 14140 14141 let description = [{ 14142*NOTE*: `RiscAdd` does not supports broadcasting. 14143 14144Given two input tensors, the `tf.risc_add` operation computes the sum for every element in the tensor. 14145 14146Both input and output have a range `(-inf, inf)`. 14147 }]; 14148 14149 let arguments = (ins 14150 TF_FloatTensor:$x, 14151 TF_FloatTensor:$y 14152 ); 14153 14154 let results = (outs 14155 TF_FloatTensor:$z 14156 ); 14157 14158 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14159} 14160 14161def TF_RiscDotOp : TF_Op<"RiscDot", [NoSideEffect]> { 14162 let summary = ""; 14163 14164 let arguments = (ins 14165 TF_FloatTensor:$a, 14166 TF_FloatTensor:$b, 14167 14168 DefaultValuedAttr<BoolAttr, "false">:$transpose_a, 14169 DefaultValuedAttr<BoolAttr, "false">:$transpose_b 14170 ); 14171 14172 let results = (outs 14173 TF_FloatTensor:$product 14174 ); 14175 14176 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14177} 14178 14179def TF_RngReadAndSkipOp : TF_Op<"RngReadAndSkip", []> { 14180 let summary = "Advance the counter of a counter-based RNG."; 14181 14182 let description = [{ 14183The state of the RNG after 14184`rng_read_and_skip(n)` will be the same as that after `uniform([n])` 14185(or any other distribution). The actual increment added to the 14186counter is an unspecified implementation choice. 14187 }]; 14188 14189 let arguments = (ins 14190 Arg<TF_ResourceTensor, [{The handle of the resource variable that stores the state of the RNG.}]>:$resource, 14191 Arg<TF_Int32Tensor, [{The RNG algorithm.}]>:$alg, 14192 Arg<TF_Uint64Tensor, [{The amount of advancement.}]>:$delta 14193 ); 14194 14195 let results = (outs 14196 Res<TF_Int64Tensor, [{The old value of the resource variable, before incrementing. Since state size is algorithm-dependent, this output will be right-padded with zeros to reach shape int64[3] (the current maximal state size among algorithms).}]>:$value 14197 ); 14198} 14199 14200def TF_RollOp : TF_Op<"Roll", [NoSideEffect]> { 14201 let summary = "Rolls the elements of a tensor along an axis."; 14202 14203 let description = [{ 14204The elements are shifted positively (towards larger indices) by the offset of 14205`shift` along the dimension of `axis`. Negative `shift` values will shift 14206elements in the opposite direction. Elements that roll passed the last position 14207will wrap around to the first and vice versa. Multiple shifts along multiple 14208axes may be specified. 14209 14210For example: 14211 14212``` 14213# 't' is [0, 1, 2, 3, 4] 14214roll(t, shift=2, axis=0) ==> [3, 4, 0, 1, 2] 14215 14216# shifting along multiple dimensions 14217# 't' is [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]] 14218roll(t, shift=[1, -2], axis=[0, 1]) ==> [[7, 8, 9, 5, 6], [2, 3, 4, 0, 1]] 14219 14220# shifting along the same axis multiple times 14221# 't' is [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]] 14222roll(t, shift=[2, -3], axis=[1, 1]) ==> [[1, 2, 3, 4, 0], [6, 7, 8, 9, 5]] 14223``` 14224 }]; 14225 14226 let arguments = (ins 14227 TF_Tensor:$input, 14228 Arg<TF_I32OrI64Tensor, [{Dimension must be 0-D or 1-D. `shift[i]` specifies the number of places by which 14229elements are shifted positively (towards larger indices) along the dimension 14230specified by `axis[i]`. Negative shifts will roll the elements in the opposite 14231direction.}]>:$shift, 14232 Arg<TF_I32OrI64Tensor, [{Dimension must be 0-D or 1-D. `axis[i]` specifies the dimension that the shift 14233`shift[i]` should occur. If the same axis is referenced more than once, the 14234total shift for that axis will be the sum of all the shifts that belong to that 14235axis.}]>:$axis 14236 ); 14237 14238 let results = (outs 14239 Res<TF_Tensor, [{Has the same shape and size as the input. The elements are shifted 14240positively (towards larger indices) by the offsets of `shift` along the 14241dimensions of `axis`.}]>:$output 14242 ); 14243 14244 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14245 TF_DerivedOperandTypeAttr Taxis = TF_DerivedOperandTypeAttr<2>; 14246 TF_DerivedOperandTypeAttr Tshift = TF_DerivedOperandTypeAttr<1>; 14247} 14248 14249def TF_RoundOp : TF_Op<"Round", [Idempotent, NoSideEffect, SameOperandsAndResultType]> { 14250 let summary = [{ 14251Rounds the values of a tensor to the nearest integer, element-wise. 14252 }]; 14253 14254 let description = [{ 14255Rounds half to even. Also known as bankers rounding. If you want to round 14256according to the current system rounding mode use std::cint. 14257 }]; 14258 14259 let arguments = (ins 14260 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x 14261 ); 14262 14263 let results = (outs 14264 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 14265 ); 14266 14267 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14268} 14269 14270def TF_RsqrtOp : TF_Op<"Rsqrt", [NoSideEffect, SameOperandsAndResultType]> { 14271 let summary = "Computes reciprocal of square root of x element-wise."; 14272 14273 let description = [{ 14274I.e., \\(y = 1 / \sqrt{x}\\). 14275 }]; 14276 14277 let arguments = (ins 14278 TF_FpOrComplexTensor:$x 14279 ); 14280 14281 let results = (outs 14282 TF_FpOrComplexTensor:$y 14283 ); 14284 14285 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14286} 14287 14288def TF_RsqrtGradOp : TF_Op<"RsqrtGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 14289 let summary = "Computes the gradient for the rsqrt of `x` wrt its input."; 14290 14291 let description = [{ 14292Specifically, `grad = dy * -0.5 * y^3`, where `y = rsqrt(x)`, and `dy` 14293is the corresponding input gradient. 14294 }]; 14295 14296 let arguments = (ins 14297 TF_FpOrComplexTensor:$y, 14298 TF_FpOrComplexTensor:$dy 14299 ); 14300 14301 let results = (outs 14302 TF_FpOrComplexTensor:$z 14303 ); 14304 14305 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14306} 14307 14308def TF_SaveOp : TF_Op<"Save", []> { 14309 let summary = "Saves the input tensors to disk."; 14310 14311 let description = [{ 14312The size of `tensor_names` must match the number of tensors in `data`. `data[i]` 14313is written to `filename` with name `tensor_names[i]`. 14314 14315See also `SaveSlices`. 14316 }]; 14317 14318 let arguments = (ins 14319 Arg<TF_StrTensor, [{Must have a single element. The name of the file to which we write 14320the tensor.}]>:$filename, 14321 Arg<TF_StrTensor, [{Shape `[N]`. The names of the tensors to be saved.}]>:$tensor_names, 14322 Arg<Variadic<TF_Tensor>, [{`N` tensors to save.}]>:$data 14323 ); 14324 14325 let results = (outs); 14326 14327 TF_DerivedOperandTypeListAttr T = TF_DerivedOperandTypeListAttr<2>; 14328} 14329 14330def TF_SaveSlicesOp : TF_Op<"SaveSlices", []> { 14331 let summary = "Saves input tensors slices to disk."; 14332 14333 let description = [{ 14334This is like `Save` except that tensors can be listed in the saved file as being 14335a slice of a larger tensor. `shapes_and_slices` specifies the shape of the 14336larger tensor and the slice that this tensor covers. `shapes_and_slices` must 14337have as many elements as `tensor_names`. 14338 14339Elements of the `shapes_and_slices` input must either be: 14340 14341* The empty string, in which case the corresponding tensor is 14342 saved normally. 14343* A string of the form `dim0 dim1 ... dimN-1 slice-spec` where the 14344 `dimI` are the dimensions of the larger tensor and `slice-spec` 14345 specifies what part is covered by the tensor to save. 14346 14347`slice-spec` itself is a `:`-separated list: `slice0:slice1:...:sliceN-1` 14348where each `sliceI` is either: 14349 14350* The string `-` meaning that the slice covers all indices of this dimension 14351* `start,length` where `start` and `length` are integers. In that 14352 case the slice covers `length` indices starting at `start`. 14353 14354See also `Save`. 14355 }]; 14356 14357 let arguments = (ins 14358 Arg<TF_StrTensor, [{Must have a single element. The name of the file to which we write the 14359tensor.}]>:$filename, 14360 Arg<TF_StrTensor, [{Shape `[N]`. The names of the tensors to be saved.}]>:$tensor_names, 14361 Arg<TF_StrTensor, [{Shape `[N]`. The shapes and slice specifications to use when 14362saving the tensors.}]>:$shapes_and_slices, 14363 Arg<Variadic<TF_Tensor>, [{`N` tensors to save.}]>:$data 14364 ); 14365 14366 let results = (outs); 14367 14368 TF_DerivedOperandTypeListAttr T = TF_DerivedOperandTypeListAttr<3>; 14369} 14370 14371def TF_SaveV2Op : TF_Op<"SaveV2", []> { 14372 let summary = "Saves tensors in V2 checkpoint format."; 14373 14374 let description = [{ 14375By default, saves the named tensors in full. If the caller wishes to save 14376specific slices of full tensors, "shape_and_slices" should be non-empty strings 14377and correspondingly well-formed. 14378 }]; 14379 14380 let arguments = (ins 14381 Arg<TF_StrTensor, [{Must have a single element. The prefix of the V2 checkpoint to which we 14382write the tensors.}]>:$prefix, 14383 Arg<TF_StrTensor, [{shape {N}. The names of the tensors to be saved.}]>:$tensor_names, 14384 Arg<TF_StrTensor, [{shape {N}. The slice specs of the tensors to be saved. 14385Empty strings indicate that they are non-partitioned tensors.}]>:$shape_and_slices, 14386 Arg<Variadic<TF_Tensor>, [{`N` tensors to save.}]>:$tensors 14387 ); 14388 14389 let results = (outs); 14390 14391 TF_DerivedOperandTypeListAttr dtypes = TF_DerivedOperandTypeListAttr<3>; 14392} 14393 14394def TF_ScatterNdOp : TF_Op<"ScatterNd", [NoSideEffect]> { 14395 let summary = [{ 14396Scatters `updates` into a tensor of shape `shape` according to `indices`. 14397 }]; 14398 14399 let description = [{ 14400Scatter sparse `updates` according to individual values at the specified 14401`indices`. This op returns an output tensor with the `shape` you specify. This 14402op is the inverse of the `tf.gather_nd` operator which extracts values or slices 14403from a given tensor. 14404 14405This operation is similar to `tf.tensor_scatter_nd_add`, except that the tensor 14406is zero-initialized. Calling `tf.scatter_nd(indices, updates, shape)` 14407is identical to calling 14408`tf.tensor_scatter_nd_add(tf.zeros(shape, updates.dtype), indices, updates)` 14409 14410If `indices` contains duplicates, the associated `updates` are accumulated 14411(summed) into the output tensor. 14412 14413**WARNING**: For floating-point data types, the output may be nondeterministic. 14414This is because the order in which the updates are applied is nondeterministic 14415and when floating-point numbers are added in different orders the resulting 14416numerical approximation error can be slightly different. However, the output 14417will be deterministic if op determinism is enabled via 14418`tf.config.experimental.enable_op_determinism`. 14419 14420`indices` is an integer tensor containing indices into the output tensor. The 14421last dimension of `indices` can be at most the rank of `shape`: 14422 14423 indices.shape[-1] <= shape.rank 14424 14425The last dimension of `indices` corresponds to indices of elements 14426(if `indices.shape[-1] = shape.rank`) or slices 14427(if `indices.shape[-1] < shape.rank`) along dimension `indices.shape[-1]` of 14428`shape`. 14429 14430`updates` is a tensor with shape: 14431 14432 indices.shape[:-1] + shape[indices.shape[-1]:] 14433 14434The simplest form of the scatter op is to insert individual elements in 14435a tensor by index. Consider an example where you want to insert 4 scattered 14436elements in a rank-1 tensor with 8 elements. 14437 14438<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 14439<img style="width:100%" src="https://www.tensorflow.org/images/ScatterNd1.png" alt> 14440</div> 14441 14442In Python, this scatter operation would look like this: 14443 14444```python 14445 indices = tf.constant([[4], [3], [1], [7]]) 14446 updates = tf.constant([9, 10, 11, 12]) 14447 shape = tf.constant([8]) 14448 scatter = tf.scatter_nd(indices, updates, shape) 14449 print(scatter) 14450``` 14451 14452The resulting tensor would look like this: 14453 14454 [0, 11, 0, 10, 9, 0, 0, 12] 14455 14456You can also insert entire slices of a higher rank tensor all at once. For 14457example, you can insert two slices in the first dimension of a rank-3 tensor 14458with two matrices of new values. 14459 14460<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 14461<img style="width:100%" src="https://www.tensorflow.org/images/ScatterNd2.png" alt> 14462</div> 14463 14464In Python, this scatter operation would look like this: 14465 14466```python 14467 indices = tf.constant([[0], [2]]) 14468 updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6], 14469 [7, 7, 7, 7], [8, 8, 8, 8]], 14470 [[5, 5, 5, 5], [6, 6, 6, 6], 14471 [7, 7, 7, 7], [8, 8, 8, 8]]]) 14472 shape = tf.constant([4, 4, 4]) 14473 scatter = tf.scatter_nd(indices, updates, shape) 14474 print(scatter) 14475``` 14476 14477The resulting tensor would look like this: 14478 14479 [[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], 14480 [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]], 14481 [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], 14482 [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]] 14483 14484Note that on CPU, if an out of bound index is found, an error is returned. 14485On GPU, if an out of bound index is found, the index is ignored. 14486 }]; 14487 14488 let arguments = (ins 14489 Arg<TensorOf<[TF_Int16, TF_Int32, TF_Int64]>, [{Tensor of indices.}]>:$indices, 14490 Arg<TF_Tensor, [{Values to scatter into the output tensor.}]>:$updates, 14491 Arg<TensorOf<[TF_Int16, TF_Int32, TF_Int64]>, [{1-D. The shape of the output tensor.}]>:$shape 14492 ); 14493 14494 let results = (outs 14495 Res<TF_Tensor, [{A new tensor with the given shape and updates applied according 14496to the indices.}]>:$output 14497 ); 14498 14499 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 14500 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<0>; 14501} 14502 14503def TF_SegmentMaxOp : TF_Op<"SegmentMax", [NoSideEffect]> { 14504 let summary = "Computes the maximum along segments of a tensor."; 14505 14506 let description = [{ 14507Read 14508[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 14509for an explanation of segments. 14510 14511Computes a tensor such that 14512\\(output_i = \max_j(data_j)\\) where `max` is over `j` such 14513that `segment_ids[j] == i`. 14514 14515If the max is empty for a given segment ID `i`, `output[i] = 0`. 14516 14517Caution: On CPU, values in `segment_ids` are always validated to be sorted, 14518and an error is thrown for indices that are not increasing. On GPU, this 14519does not throw an error for unsorted indices. On GPU, out-of-order indices 14520result in safe but unspecified behavior, which may include treating 14521out-of-order indices as the same as a smaller following index. 14522 14523<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 14524<img style="width:100%" src="https://www.tensorflow.org/images/SegmentMax.png" alt> 14525</div> 14526 14527For example: 14528 14529>>> c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]]) 14530>>> tf.math.segment_max(c, tf.constant([0, 0, 1])).numpy() 14531array([[4, 3, 3, 4], 14532 [5, 6, 7, 8]], dtype=int32) 14533 }]; 14534 14535 let arguments = (ins 14536 TF_IntOrFpTensor:$data, 14537 Arg<TF_I32OrI64Tensor, [{A 1-D tensor whose size is equal to the size of `data`'s 14538first dimension. Values should be sorted and can be repeated. 14539 14540Caution: The values are always validated to be sorted on CPU, never validated 14541on GPU.}]>:$segment_ids 14542 ); 14543 14544 let results = (outs 14545 Res<TF_IntOrFpTensor, [{Has same shape as data, except for dimension 0 which 14546has size `k`, the number of segments.}]>:$output 14547 ); 14548 14549 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14550 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 14551} 14552 14553def TF_SegmentMeanOp : TF_Op<"SegmentMean", [NoSideEffect]> { 14554 let summary = "Computes the mean along segments of a tensor."; 14555 14556 let description = [{ 14557Read 14558[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 14559for an explanation of segments. 14560 14561Computes a tensor such that 14562\\(output_i = \frac{\sum_j data_j}{N}\\) where `mean` is 14563over `j` such that `segment_ids[j] == i` and `N` is the total number of 14564values summed. 14565 14566If the mean is empty for a given segment ID `i`, `output[i] = 0`. 14567 14568Caution: On CPU, values in `segment_ids` are always validated to be sorted, 14569and an error is thrown for indices that are not increasing. On GPU, this 14570does not throw an error for unsorted indices. On GPU, out-of-order indices 14571result in safe but unspecified behavior, which may include treating 14572out-of-order indices as a smaller following index when computing the numerator 14573of the mean. 14574 14575<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 14576<img style="width:100%" src="https://www.tensorflow.org/images/SegmentMean.png" alt> 14577</div> 14578 14579For example: 14580 14581>>> c = tf.constant([[1.0,2,3,4], [4, 3, 2, 1], [5,6,7,8]]) 14582>>> tf.math.segment_mean(c, tf.constant([0, 0, 1])).numpy() 14583array([[2.5, 2.5, 2.5, 2.5], 14584 [5., 6., 7., 8.]], dtype=float32) 14585 }]; 14586 14587 let arguments = (ins 14588 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$data, 14589 Arg<TF_I32OrI64Tensor, [{A 1-D tensor whose size is equal to the size of `data`'s 14590first dimension. Values should be sorted and can be repeated. 14591 14592Caution: The values are always validated to be sorted on CPU, never validated 14593on GPU.}]>:$segment_ids 14594 ); 14595 14596 let results = (outs 14597 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Has same shape as data, except for dimension 0 which 14598has size `k`, the number of segments.}]>:$output 14599 ); 14600 14601 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14602 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 14603} 14604 14605def TF_SegmentMinOp : TF_Op<"SegmentMin", [NoSideEffect]> { 14606 let summary = "Computes the minimum along segments of a tensor."; 14607 14608 let description = [{ 14609Read 14610[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 14611for an explanation of segments. 14612 14613Computes a tensor such that 14614\\(output_i = \min_j(data_j)\\) where `min` is over `j` such 14615that `segment_ids[j] == i`. 14616 14617If the min is empty for a given segment ID `i`, `output[i] = 0`. 14618 14619Caution: On CPU, values in `segment_ids` are always validated to be sorted, 14620and an error is thrown for indices that are not increasing. On GPU, this 14621does not throw an error for unsorted indices. On GPU, out-of-order indices 14622result in safe but unspecified behavior, which may include treating 14623out-of-order indices as the same as a smaller following index. 14624 14625<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 14626<img style="width:100%" src="https://www.tensorflow.org/images/SegmentMin.png" alt> 14627</div> 14628 14629For example: 14630 14631>>> c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]]) 14632>>> tf.math.segment_min(c, tf.constant([0, 0, 1])).numpy() 14633array([[1, 2, 2, 1], 14634 [5, 6, 7, 8]], dtype=int32) 14635 }]; 14636 14637 let arguments = (ins 14638 TF_IntOrFpTensor:$data, 14639 Arg<TF_I32OrI64Tensor, [{A 1-D tensor whose size is equal to the size of `data`'s 14640first dimension. Values should be sorted and can be repeated. 14641 14642Caution: The values are always validated to be sorted on CPU, never validated 14643on GPU.}]>:$segment_ids 14644 ); 14645 14646 let results = (outs 14647 Res<TF_IntOrFpTensor, [{Has same shape as data, except for dimension 0 which 14648has size `k`, the number of segments.}]>:$output 14649 ); 14650 14651 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14652 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 14653} 14654 14655def TF_SegmentProdOp : TF_Op<"SegmentProd", [NoSideEffect]> { 14656 let summary = "Computes the product along segments of a tensor."; 14657 14658 let description = [{ 14659Read 14660[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 14661for an explanation of segments. 14662 14663Computes a tensor such that 14664\\(output_i = \prod_j data_j\\) where the product is over `j` such 14665that `segment_ids[j] == i`. 14666 14667If the product is empty for a given segment ID `i`, `output[i] = 1`. 14668 14669Caution: On CPU, values in `segment_ids` are always validated to be sorted, 14670and an error is thrown for indices that are not increasing. On GPU, this 14671does not throw an error for unsorted indices. On GPU, out-of-order indices 14672result in safe but unspecified behavior, which may include treating 14673out-of-order indices as the same as a smaller following index. 14674 14675<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 14676<img style="width:100%" src="https://www.tensorflow.org/images/SegmentProd.png" alt> 14677</div> 14678 14679For example: 14680 14681>>> c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]]) 14682>>> tf.math.segment_prod(c, tf.constant([0, 0, 1])).numpy() 14683array([[4, 6, 6, 4], 14684 [5, 6, 7, 8]], dtype=int32) 14685 }]; 14686 14687 let arguments = (ins 14688 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$data, 14689 Arg<TF_I32OrI64Tensor, [{A 1-D tensor whose size is equal to the size of `data`'s 14690first dimension. Values should be sorted and can be repeated. 14691 14692Caution: The values are always validated to be sorted on CPU, never validated 14693on GPU.}]>:$segment_ids 14694 ); 14695 14696 let results = (outs 14697 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Has same shape as data, except for dimension 0 which 14698has size `k`, the number of segments.}]>:$output 14699 ); 14700 14701 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14702 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 14703} 14704 14705def TF_SegmentSumOp : TF_Op<"SegmentSum", [NoSideEffect]> { 14706 let summary = "Computes the sum along segments of a tensor."; 14707 14708 let description = [{ 14709Read 14710[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 14711for an explanation of segments. 14712 14713Computes a tensor such that 14714\\(output_i = \sum_j data_j\\) where sum is over `j` such 14715that `segment_ids[j] == i`. 14716 14717If the sum is empty for a given segment ID `i`, `output[i] = 0`. 14718 14719Caution: On CPU, values in `segment_ids` are always validated to be sorted, 14720and an error is thrown for indices that are not increasing. On GPU, this 14721does not throw an error for unsorted indices. On GPU, out-of-order indices 14722result in safe but unspecified behavior, which may include treating 14723out-of-order indices as the same as a smaller following index. 14724 14725<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 14726<img style="width:100%" src="https://www.tensorflow.org/images/SegmentSum.png" alt> 14727</div> 14728 14729For example: 14730 14731>>> c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]]) 14732>>> tf.math.segment_sum(c, tf.constant([0, 0, 1])).numpy() 14733array([[5, 5, 5, 5], 14734 [5, 6, 7, 8]], dtype=int32) 14735 }]; 14736 14737 let arguments = (ins 14738 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$data, 14739 Arg<TF_I32OrI64Tensor, [{A 1-D tensor whose size is equal to the size of `data`'s 14740first dimension. Values should be sorted and can be repeated. 14741 14742Caution: The values are always validated to be sorted on CPU, never validated 14743on GPU.}]>:$segment_ids 14744 ); 14745 14746 let results = (outs 14747 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Has same shape as data, except for dimension 0 which 14748has size `k`, the number of segments.}]>:$output 14749 ); 14750 14751 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14752 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 14753} 14754 14755def TF_SelectOp : TF_Op<"Select", [NoSideEffect]> { 14756 let summary = "Selects elements from `x` or `y`, depending on `condition`."; 14757 14758 let description = [{ 14759The `x`, and `y` tensors must all have the same shape, and the 14760output will also have that shape. 14761 14762The `condition` tensor must be a scalar if `x` and `y` are scalars. 14763If `x` and `y` are vectors or higher rank, then `condition` must be either a 14764scalar, a vector with size matching the first dimension of `x`, or must have 14765the same shape as `x`. 14766 14767The `condition` tensor acts as a mask that chooses, based on the value at each 14768element, whether the corresponding element / row in the output should be 14769taken from `x` (if true) or `y` (if false). 14770 14771If `condition` is a vector and `x` and `y` are higher rank matrices, then 14772it chooses which row (outer dimension) to copy from `x` and `y`. 14773If `condition` has the same shape as `x` and `y`, then it chooses which 14774element to copy from `x` and `y`. 14775 14776For example: 14777 14778```python 14779# 'condition' tensor is [[True, False] 14780# [False, True]] 14781# 't' is [[1, 2], 14782# [3, 4]] 14783# 'e' is [[5, 6], 14784# [7, 8]] 14785select(condition, t, e) # => [[1, 6], [7, 4]] 14786 14787 14788# 'condition' tensor is [True, False] 14789# 't' is [[1, 2], 14790# [3, 4]] 14791# 'e' is [[5, 6], 14792# [7, 8]] 14793select(condition, t, e) ==> [[1, 2], 14794 [7, 8]] 14795 14796``` 14797 }]; 14798 14799 let arguments = (ins 14800 TF_BoolTensor:$condition, 14801 Arg<TF_Tensor, [{= A `Tensor` which may have the same shape as `condition`. 14802If `condition` is rank 1, `x` may have higher rank, 14803but its first dimension must match the size of `condition`.}]>:$t, 14804 Arg<TF_Tensor, [{= A `Tensor` with the same type and shape as `x`.}]>:$e 14805 ); 14806 14807 let results = (outs 14808 Res<TF_Tensor, [{= A `Tensor` with the same type and shape as `x` and `y`.}]>:$output 14809 ); 14810 14811 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 14812 14813 let hasVerifier = 1; 14814} 14815 14816def TF_SelectV2Op : TF_Op<"SelectV2", [NoSideEffect, ResultsBroadcastableShape]> { 14817 let summary = ""; 14818 14819 let arguments = (ins 14820 TF_BoolTensor:$condition, 14821 TF_Tensor:$t, 14822 TF_Tensor:$e 14823 ); 14824 14825 let results = (outs 14826 TF_Tensor:$output 14827 ); 14828 14829 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 14830 14831 let builders = [ 14832 OpBuilder<(ins "Value":$condition, "Value":$e, "Value":$t)> 14833 ]; 14834} 14835 14836def TF_SelfAdjointEigV2Op : TF_Op<"SelfAdjointEigV2", [NoSideEffect]> { 14837 let summary = [{ 14838Computes the eigen decomposition of one or more square self-adjoint matrices. 14839 }]; 14840 14841 let description = [{ 14842Computes the eigenvalues and (optionally) eigenvectors of each inner matrix in 14843`input` such that `input[..., :, :] = v[..., :, :] * diag(e[..., :])`. The eigenvalues 14844are sorted in non-decreasing order. 14845 14846```python 14847# a is a tensor. 14848# e is a tensor of eigenvalues. 14849# v is a tensor of eigenvectors. 14850e, v = self_adjoint_eig(a) 14851e = self_adjoint_eig(a, compute_v=False) 14852``` 14853 }]; 14854 14855 let arguments = (ins 14856 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{`Tensor` input of shape `[N, N]`.}]>:$input, 14857 14858 DefaultValuedAttr<BoolAttr, "true">:$compute_v 14859 ); 14860 14861 let results = (outs 14862 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Eigenvalues. Shape is `[N]`.}]>:$e, 14863 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Eigenvectors. Shape is `[N, N]`.}]>:$v 14864 ); 14865 14866 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14867} 14868 14869def TF_SeluOp : TF_Op<"Selu", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 14870 let summary = [{ 14871Computes scaled exponential linear: `scale * alpha * (exp(features) - 1)` 14872 }]; 14873 14874 let description = [{ 14875if < 0, `scale * features` otherwise. 14876 14877To be used together with 14878`initializer = tf.variance_scaling_initializer(factor=1.0, mode='FAN_IN')`. 14879For correct dropout, use `tf.contrib.nn.alpha_dropout`. 14880 14881See [Self-Normalizing Neural Networks](https://arxiv.org/abs/1706.02515) 14882 }]; 14883 14884 let arguments = (ins 14885 TF_FloatTensor:$features 14886 ); 14887 14888 let results = (outs 14889 TF_FloatTensor:$activations 14890 ); 14891 14892 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14893} 14894 14895def TF_SeluGradOp : TF_Op<"SeluGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 14896 let summary = [{ 14897Computes gradients for the scaled exponential linear (Selu) operation. 14898 }]; 14899 14900 let arguments = (ins 14901 Arg<TF_FloatTensor, [{The backpropagated gradients to the corresponding Selu operation.}]>:$gradients, 14902 Arg<TF_FloatTensor, [{The outputs of the corresponding Selu operation.}]>:$outputs 14903 ); 14904 14905 let results = (outs 14906 Res<TF_FloatTensor, [{The gradients: `gradients * (outputs + scale * alpha)` 14907if outputs < 0, `scale * gradients` otherwise.}]>:$backprops 14908 ); 14909 14910 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14911} 14912 14913def TF_SendOp : TF_Op<"Send", [TF_SendSideEffect]> { 14914 let summary = "Sends the named tensor from send_device to recv_device."; 14915 14916 let arguments = (ins 14917 Arg<TF_Tensor, [{The tensor to send.}]>:$tensor, 14918 14919 StrAttr:$tensor_name, 14920 StrAttr:$send_device, 14921 I64Attr:$send_device_incarnation, 14922 StrAttr:$recv_device, 14923 DefaultValuedAttr<BoolAttr, "false">:$client_terminated 14924 ); 14925 14926 let results = (outs); 14927 14928 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 14929} 14930 14931def TF_SendTPUEmbeddingGradientsOp : TF_Op<"SendTPUEmbeddingGradients", [AttrSizedOperandSegments, TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 14932 let summary = "Performs gradient updates of embedding tables."; 14933 14934 let arguments = (ins 14935 Arg<Variadic<TF_Float32Tensor>, [{A TensorList of gradients with which to update embedding tables. 14936This argument has the same length and shapes as the return value of 14937RecvTPUEmbeddingActivations, but contains gradients of the model's loss 14938with respect to the embedding activations. The embedding tables are updated 14939from these gradients via the optimizer specified in the TPU embedding 14940configuration given to tpu.initialize_system.}]>:$inputs, 14941 Arg<Variadic<TF_Float32Tensor>, [{A TensorList of float32 scalars, one for each dynamic learning 14942rate tag: see the comments in 14943//third_party/tensorflow/core/protobuf/tpu/optimization_parameters.proto. 14944Multiple tables can share the same dynamic learning rate tag as specified 14945in the configuration. If the learning rates for all tables are constant, 14946this list should be empty.}]>:$learning_rates, 14947 14948 StrAttr:$config 14949 ); 14950 14951 let results = (outs); 14952 14953 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 14954 TF_DerivedOperandSizeAttr NN = TF_DerivedOperandSizeAttr<1>; 14955} 14956 14957def TF_SerializeIteratorOp : TF_Op<"SerializeIterator", []> { 14958 let summary = [{ 14959Converts the given `resource_handle` representing an iterator to a variant tensor. 14960 }]; 14961 14962 let arguments = (ins 14963 Arg<TF_ResourceTensor, [{A handle to an iterator resource.}], [TF_DatasetIteratorRead]>:$resource_handle, 14964 14965 DefaultValuedAttr<I64Attr, "0">:$external_state_policy 14966 ); 14967 14968 let results = (outs 14969 Res<TF_VariantTensor, [{A variant tensor storing the state of the iterator contained in the 14970resource.}]>:$serialized 14971 ); 14972} 14973 14974def TF_SerializeSparseOp : TF_Op<"SerializeSparse", [NoSideEffect]> { 14975 let summary = "Serialize a `SparseTensor` into a `[3]` `Tensor` object."; 14976 14977 let arguments = (ins 14978 Arg<TF_Int64Tensor, [{2-D. The `indices` of the `SparseTensor`.}]>:$sparse_indices, 14979 Arg<TF_Tensor, [{1-D. The `values` of the `SparseTensor`.}]>:$sparse_values, 14980 Arg<TF_Int64Tensor, [{1-D. The `shape` of the `SparseTensor`.}]>:$sparse_shape 14981 ); 14982 14983 let results = (outs 14984 TensorOf<[TF_Str, TF_Variant]>:$serialized_sparse 14985 ); 14986 14987 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 14988 TF_DerivedResultTypeAttr out_type = TF_DerivedResultTypeAttr<0>; 14989} 14990 14991def TF_ShapeOp : TF_Op<"Shape", [NoSideEffect]> { 14992 let summary = "Returns the shape of a tensor."; 14993 14994 let description = [{ 14995This operation returns a 1-D integer tensor representing the shape of `input`. 14996 14997For example: 14998 14999``` 15000# 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]] 15001shape(t) ==> [2, 2, 3] 15002``` 15003 }]; 15004 15005 let arguments = (ins 15006 TF_Tensor:$input 15007 ); 15008 15009 let results = (outs 15010 TF_I32OrI64Tensor:$output 15011 ); 15012 15013 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15014 TF_DerivedResultTypeAttr out_type = TF_DerivedResultTypeAttr<0>; 15015 15016 let hasVerifier = 1; 15017 15018 let builders = [ 15019 OpBuilder<(ins "Value":$input, "BoolAttr":$use32Bit)> 15020 ]; 15021 15022 let hasFolder = 1; 15023} 15024 15025def TF_ShapeNOp : TF_Op<"ShapeN", [NoSideEffect]> { 15026 let summary = "Returns shape of tensors."; 15027 15028 let description = [{ 15029This operation returns N 1-D integer tensors representing shape of `input[i]s`. 15030 }]; 15031 15032 let arguments = (ins 15033 Variadic<TF_Tensor>:$input 15034 ); 15035 15036 let results = (outs 15037 Variadic<TF_I32OrI64Tensor>:$output 15038 ); 15039 15040 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 15041 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15042 TF_DerivedResultTypeAttr out_type = TF_DerivedResultTypeAttr<0>; 15043 15044 let hasVerifier = 1; 15045 15046 let hasCanonicalizer = 1; 15047} 15048 15049def TF_ShardedFilenameOp : TF_Op<"ShardedFilename", [NoSideEffect]> { 15050 let summary = [{ 15051Generate a sharded filename. The filename is printf formatted as 15052 }]; 15053 15054 let description = [{ 15055%s-%05d-of-%05d, basename, shard, num_shards. 15056 }]; 15057 15058 let arguments = (ins 15059 TF_StrTensor:$basename, 15060 TF_Int32Tensor:$shard, 15061 TF_Int32Tensor:$num_shards 15062 ); 15063 15064 let results = (outs 15065 TF_StrTensor:$filename 15066 ); 15067} 15068 15069def TF_ShuffleAndRepeatDatasetV2Op : TF_Op<"ShuffleAndRepeatDatasetV2", []> { 15070 let summary = ""; 15071 15072 let arguments = (ins 15073 TF_VariantTensor:$input_dataset, 15074 TF_Int64Tensor:$buffer_size, 15075 TF_Int64Tensor:$seed, 15076 TF_Int64Tensor:$seed2, 15077 TF_Int64Tensor:$count, 15078 Arg<TF_ResourceTensor, "", [TF_DatasetSeedGeneratorRead, TF_DatasetSeedGeneratorWrite]>:$seed_generator, 15079 15080 DefaultValuedAttr<BoolAttr, "true">:$reshuffle_each_iteration, 15081 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 15082 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 15083 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 15084 ); 15085 15086 let results = (outs 15087 TF_VariantTensor:$handle 15088 ); 15089} 15090 15091def TF_ShuffleDatasetV2Op : TF_Op<"ShuffleDatasetV2", []> { 15092 let summary = ""; 15093 15094 let arguments = (ins 15095 TF_VariantTensor:$input_dataset, 15096 TF_Int64Tensor:$buffer_size, 15097 Arg<TF_ResourceTensor, "", [TF_DatasetSeedGeneratorRead, TF_DatasetSeedGeneratorWrite]>:$seed_generator, 15098 15099 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 15100 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 15101 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 15102 ); 15103 15104 let results = (outs 15105 TF_VariantTensor:$handle 15106 ); 15107} 15108 15109def TF_ShuffleDatasetV3Op : TF_Op<"ShuffleDatasetV3", []> { 15110 let summary = ""; 15111 15112 let arguments = (ins 15113 TF_VariantTensor:$input_dataset, 15114 TF_Int64Tensor:$buffer_size, 15115 TF_Int64Tensor:$seed, 15116 TF_Int64Tensor:$seed2, 15117 Arg<TF_ResourceTensor, "", [TF_DatasetSeedGeneratorRead, TF_DatasetSeedGeneratorWrite]>:$seed_generator, 15118 15119 DefaultValuedAttr<BoolAttr, "true">:$reshuffle_each_iteration, 15120 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 15121 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 15122 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 15123 ); 15124 15125 let results = (outs 15126 TF_VariantTensor:$handle 15127 ); 15128} 15129 15130def TF_ShutdownDistributedTPUOp : TF_Op<"ShutdownDistributedTPU", []> { 15131 let summary = "Shuts down a running distributed TPU system."; 15132 15133 let description = [{ 15134The op returns an error if no system is running. 15135 }]; 15136 15137 let arguments = (ins); 15138 15139 let results = (outs); 15140} 15141 15142def TF_SigmoidOp : TF_Op<"Sigmoid", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 15143 let summary = "Computes sigmoid of `x` element-wise."; 15144 15145 let description = [{ 15146Specifically, `y = 1 / (1 + exp(-x))`. 15147 }]; 15148 15149 let arguments = (ins 15150 TF_FpOrComplexTensor:$x 15151 ); 15152 15153 let results = (outs 15154 TF_FpOrComplexTensor:$y 15155 ); 15156 15157 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15158} 15159 15160def TF_SigmoidGradOp : TF_Op<"SigmoidGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 15161 let summary = "Computes the gradient of the sigmoid of `x` wrt its input."; 15162 15163 let description = [{ 15164Specifically, `grad = dy * y * (1 - y)`, where `y = sigmoid(x)`, and 15165`dy` is the corresponding input gradient. 15166 }]; 15167 15168 let arguments = (ins 15169 TF_FpOrComplexTensor:$y, 15170 TF_FpOrComplexTensor:$dy 15171 ); 15172 15173 let results = (outs 15174 TF_FpOrComplexTensor:$z 15175 ); 15176 15177 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15178} 15179 15180def TF_SignOp : TF_Op<"Sign", [Idempotent, NoSideEffect, SameOperandsAndResultType]> { 15181 let summary = "Returns an element-wise indication of the sign of a number."; 15182 15183 let description = [{ 15184`y = sign(x) = -1` if `x < 0`; 0 if `x == 0`; 1 if `x > 0`. 15185 15186For complex numbers, `y = sign(x) = x / |x|` if `x != 0`, otherwise `y = 0`. 15187 15188Example usage: 15189>>> tf.math.sign([0., 2., -3.]) 15190<tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 0., 1., -1.], dtype=float32)> 15191 }]; 15192 15193 let arguments = (ins 15194 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x 15195 ); 15196 15197 let results = (outs 15198 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 15199 ); 15200 15201 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15202} 15203 15204def TF_SinOp : TF_Op<"Sin", [NoSideEffect, SameOperandsAndResultType]> { 15205 let summary = "Computes sine of x element-wise."; 15206 15207 let description = [{ 15208Given an input tensor, this function computes sine of every 15209 element in the tensor. Input range is `(-inf, inf)` and 15210 output range is `[-1,1]`. 15211 15212 ```python 15213 x = tf.constant([-float("inf"), -9, -0.5, 1, 1.2, 200, 10, float("inf")]) 15214 tf.math.sin(x) ==> [nan -0.4121185 -0.47942555 0.84147096 0.9320391 -0.87329733 -0.54402107 nan] 15215 ``` 15216 }]; 15217 15218 let arguments = (ins 15219 TF_FpOrComplexTensor:$x 15220 ); 15221 15222 let results = (outs 15223 TF_FpOrComplexTensor:$y 15224 ); 15225 15226 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15227} 15228 15229def TF_SinhOp : TF_Op<"Sinh", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 15230 let summary = "Computes hyperbolic sine of x element-wise."; 15231 15232 let description = [{ 15233Given an input tensor, this function computes hyperbolic sine of every 15234 element in the tensor. Input range is `[-inf,inf]` and output range 15235 is `[-inf,inf]`. 15236 15237 ```python 15238 x = tf.constant([-float("inf"), -9, -0.5, 1, 1.2, 2, 10, float("inf")]) 15239 tf.math.sinh(x) ==> [-inf -4.0515420e+03 -5.2109528e-01 1.1752012e+00 1.5094614e+00 3.6268604e+00 1.1013232e+04 inf] 15240 ``` 15241 }]; 15242 15243 let arguments = (ins 15244 TF_FpOrComplexTensor:$x 15245 ); 15246 15247 let results = (outs 15248 TF_FpOrComplexTensor:$y 15249 ); 15250 15251 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15252} 15253 15254def TF_SizeOp : TF_Op<"Size", [NoSideEffect]> { 15255 let summary = "Returns the size of a tensor."; 15256 15257 let description = [{ 15258This operation returns an integer representing the number of elements in 15259`input`. 15260 15261For example: 15262 15263``` 15264# 't' is [[[1, 1,, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]]] 15265size(t) ==> 12 15266``` 15267 }]; 15268 15269 let arguments = (ins 15270 TF_Tensor:$input 15271 ); 15272 15273 let results = (outs 15274 TF_I32OrI64Tensor:$output 15275 ); 15276 15277 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15278 TF_DerivedResultTypeAttr out_type = TF_DerivedResultTypeAttr<0>; 15279 15280 let hasVerifier = 1; 15281 15282 let hasFolder = 1; 15283} 15284 15285def TF_SliceOp : TF_Op<"Slice", [NoSideEffect, PredOpTrait<"input and output must have same element type", TCresVTEtIsSameAsOp<0, 0>>]> { 15286 let summary = "Return a slice from 'input'."; 15287 15288 let description = [{ 15289The output tensor is a tensor with dimensions described by 'size' 15290whose values are extracted from 'input' starting at the offsets in 15291'begin'. 15292 15293*Requirements*: 15294 0 <= begin[i] <= begin[i] + size[i] <= Di for i in [0, n) 15295 }]; 15296 15297 let arguments = (ins 15298 TF_Tensor:$input, 15299 Arg<TF_I32OrI64Tensor, [{begin[i] specifies the offset into the 'i'th dimension of 15300'input' to slice from.}]>:$begin, 15301 Arg<TF_I32OrI64Tensor, [{size[i] specifies the number of elements of the 'i'th dimension 15302of 'input' to slice. If size[i] is -1, all remaining elements in dimension 15303i are included in the slice (i.e. this is equivalent to setting 15304size[i] = input.dim_size(i) - begin[i]).}]>:$size 15305 ); 15306 15307 let results = (outs 15308 TF_Tensor:$output 15309 ); 15310 15311 TF_DerivedOperandTypeAttr Index = TF_DerivedOperandTypeAttr<1>; 15312 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15313 15314 let hasVerifier = 1; 15315} 15316 15317def TF_SnapshotOp : TF_Op<"Snapshot", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 15318 let summary = "Returns a copy of the input tensor."; 15319 15320 let arguments = (ins 15321 TF_Tensor:$input 15322 ); 15323 15324 let results = (outs 15325 TF_Tensor:$output 15326 ); 15327 15328 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15329} 15330 15331def TF_SoftmaxOp : TF_Op<"Softmax", [NoSideEffect, SameOperandsAndResultType]> { 15332 let summary = "Computes softmax activations."; 15333 15334 let description = [{ 15335For each batch `i` and class `j` we have 15336 15337 $$softmax[i, j] = exp(logits[i, j]) / sum_j(exp(logits[i, j]))$$ 15338 }]; 15339 15340 let arguments = (ins 15341 Arg<TF_FloatTensor, [{2-D with shape `[batch_size, num_classes]`.}]>:$logits 15342 ); 15343 15344 let results = (outs 15345 Res<TF_FloatTensor, [{Same shape as `logits`.}]>:$softmax 15346 ); 15347 15348 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15349 15350 let hasVerifier = 1; 15351} 15352 15353def TF_SoftmaxCrossEntropyWithLogitsOp : TF_Op<"SoftmaxCrossEntropyWithLogits", [NoSideEffect]> { 15354 let summary = [{ 15355Computes softmax cross entropy cost and gradients to backpropagate. 15356 }]; 15357 15358 let description = [{ 15359Inputs are the logits, not probabilities. 15360 }]; 15361 15362 let arguments = (ins 15363 Arg<TF_FloatTensor, [{batch_size x num_classes matrix}]>:$features, 15364 Arg<TF_FloatTensor, [{batch_size x num_classes matrix 15365The caller must ensure that each batch of labels represents a valid 15366probability distribution.}]>:$labels 15367 ); 15368 15369 let results = (outs 15370 Res<TF_FloatTensor, [{Per example loss (batch_size vector).}]>:$loss, 15371 Res<TF_FloatTensor, [{backpropagated gradients (batch_size x num_classes matrix).}]>:$backprop 15372 ); 15373 15374 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15375 15376 let hasVerifier = 1; 15377} 15378 15379def TF_SoftplusOp : TF_Op<"Softplus", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 15380 let summary = ""; 15381 15382 let arguments = (ins 15383 TF_FloatTensor:$features 15384 ); 15385 15386 let results = (outs 15387 TF_FloatTensor:$activations 15388 ); 15389 15390 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15391} 15392 15393def TF_SoftplusGradOp : TF_Op<"SoftplusGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 15394 let summary = "Computes softplus gradients for a softplus operation."; 15395 15396 let arguments = (ins 15397 Arg<TF_FloatTensor, [{The backpropagated gradients to the corresponding softplus operation.}]>:$gradients, 15398 Arg<TF_FloatTensor, [{The features passed as input to the corresponding softplus operation.}]>:$features 15399 ); 15400 15401 let results = (outs 15402 Res<TF_FloatTensor, [{The gradients: `gradients / (1 + exp(-features))`.}]>:$backprops 15403 ); 15404 15405 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15406} 15407 15408def TF_SoftsignOp : TF_Op<"Softsign", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 15409 let summary = "Computes softsign: `features / (abs(features) + 1)`."; 15410 15411 let arguments = (ins 15412 TF_FloatTensor:$features 15413 ); 15414 15415 let results = (outs 15416 TF_FloatTensor:$activations 15417 ); 15418 15419 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15420} 15421 15422def TF_SoftsignGradOp : TF_Op<"SoftsignGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 15423 let summary = "Computes softsign gradients for a softsign operation."; 15424 15425 let arguments = (ins 15426 Arg<TF_FloatTensor, [{The backpropagated gradients to the corresponding softsign operation.}]>:$gradients, 15427 Arg<TF_FloatTensor, [{The features passed as input to the corresponding softsign operation.}]>:$features 15428 ); 15429 15430 let results = (outs 15431 Res<TF_FloatTensor, [{The gradients: `gradients / (1 + abs(features)) ** 2`.}]>:$backprops 15432 ); 15433 15434 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15435} 15436 15437def TF_SpaceToBatchOp : TF_Op<"SpaceToBatch", [NoSideEffect]> { 15438 let summary = "SpaceToBatch for 4-D tensors of type T."; 15439 15440 let description = [{ 15441This is a legacy version of the more general SpaceToBatchND. 15442 15443Zero-pads and then rearranges (permutes) blocks of spatial data into batch. 15444More specifically, this op outputs a copy of the input tensor where values from 15445the `height` and `width` dimensions are moved to the `batch` dimension. After 15446the zero-padding, both `height` and `width` of the input must be divisible by the 15447block size. 15448 15449The attr `block_size` must be greater than one. It indicates the block size. 15450 15451 * Non-overlapping blocks of size `block_size x block size` in the height and 15452 width dimensions are rearranged into the batch dimension at each location. 15453 * The batch of the output tensor is `batch * block_size * block_size`. 15454 * Both height_pad and width_pad must be divisible by block_size. 15455 15456The shape of the output will be: 15457 15458 [batch*block_size*block_size, height_pad/block_size, width_pad/block_size, 15459 depth] 15460 15461Some examples: 15462 15463(1) For the following input of shape `[1, 2, 2, 1]` and block_size of 2: 15464 15465``` 15466x = [[[[1], [2]], [[3], [4]]]] 15467``` 15468 15469The output tensor has shape `[4, 1, 1, 1]` and value: 15470 15471``` 15472[[[[1]]], [[[2]]], [[[3]]], [[[4]]]] 15473``` 15474 15475(2) For the following input of shape `[1, 2, 2, 3]` and block_size of 2: 15476 15477``` 15478x = [[[[1, 2, 3], [4, 5, 6]], 15479 [[7, 8, 9], [10, 11, 12]]]] 15480``` 15481 15482The output tensor has shape `[4, 1, 1, 3]` and value: 15483 15484``` 15485[[[[1, 2, 3]]], [[[4, 5, 6]]], [[[7, 8, 9]]], [[[10, 11, 12]]]] 15486``` 15487 15488(3) For the following input of shape `[1, 4, 4, 1]` and block_size of 2: 15489 15490``` 15491x = [[[[1], [2], [3], [4]], 15492 [[5], [6], [7], [8]], 15493 [[9], [10], [11], [12]], 15494 [[13], [14], [15], [16]]]] 15495``` 15496 15497The output tensor has shape `[4, 2, 2, 1]` and value: 15498 15499``` 15500x = [[[[1], [3]], [[9], [11]]], 15501 [[[2], [4]], [[10], [12]]], 15502 [[[5], [7]], [[13], [15]]], 15503 [[[6], [8]], [[14], [16]]]] 15504``` 15505 15506(4) For the following input of shape `[2, 2, 4, 1]` and block_size of 2: 15507 15508``` 15509x = [[[[1], [2], [3], [4]], 15510 [[5], [6], [7], [8]]], 15511 [[[9], [10], [11], [12]], 15512 [[13], [14], [15], [16]]]] 15513``` 15514 15515The output tensor has shape `[8, 1, 2, 1]` and value: 15516 15517``` 15518x = [[[[1], [3]]], [[[9], [11]]], [[[2], [4]]], [[[10], [12]]], 15519 [[[5], [7]]], [[[13], [15]]], [[[6], [8]]], [[[14], [16]]]] 15520``` 15521 15522Among others, this operation is useful for reducing atrous convolution into 15523regular convolution. 15524 }]; 15525 15526 let arguments = (ins 15527 Arg<TF_Tensor, [{4-D with shape `[batch, height, width, depth]`.}]>:$input, 15528 Arg<TF_I32OrI64Tensor, [{2-D tensor of non-negative integers with shape `[2, 2]`. It specifies 15529 the padding of the input with zeros across the spatial dimensions as follows: 15530 15531 paddings = [[pad_top, pad_bottom], [pad_left, pad_right]] 15532 15533 The effective spatial dimensions of the zero-padded input tensor will be: 15534 15535 height_pad = pad_top + height + pad_bottom 15536 width_pad = pad_left + width + pad_right}]>:$paddings, 15537 15538 ConfinedAttr<I64Attr, [IntMinValue<2>]>:$block_size 15539 ); 15540 15541 let results = (outs 15542 TF_Tensor:$output 15543 ); 15544 15545 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15546 TF_DerivedOperandTypeAttr Tpaddings = TF_DerivedOperandTypeAttr<1>; 15547} 15548 15549def TF_SpaceToBatchNDOp : TF_Op<"SpaceToBatchND", [NoSideEffect]> { 15550 let summary = "SpaceToBatch for N-D tensors of type T."; 15551 15552 let description = [{ 15553This operation divides "spatial" dimensions `[1, ..., M]` of the input into a 15554grid of blocks of shape `block_shape`, and interleaves these blocks with the 15555"batch" dimension (0) such that in the output, the spatial dimensions 15556`[1, ..., M]` correspond to the position within the grid, and the batch 15557dimension combines both the position within a spatial block and the original 15558batch position. Prior to division into blocks, the spatial dimensions of the 15559input are optionally zero padded according to `paddings`. See below for a 15560precise description. 15561 15562This operation is equivalent to the following steps: 15563 155641. Zero-pad the start and end of dimensions `[1, ..., M]` of the 15565 input according to `paddings` to produce `padded` of shape `padded_shape`. 15566 155672. Reshape `padded` to `reshaped_padded` of shape: 15568 15569 [batch] + 15570 [padded_shape[1] / block_shape[0], 15571 block_shape[0], 15572 ..., 15573 padded_shape[M] / block_shape[M-1], 15574 block_shape[M-1]] + 15575 remaining_shape 15576 155773. Permute dimensions of `reshaped_padded` to produce 15578 `permuted_reshaped_padded` of shape: 15579 15580 block_shape + 15581 [batch] + 15582 [padded_shape[1] / block_shape[0], 15583 ..., 15584 padded_shape[M] / block_shape[M-1]] + 15585 remaining_shape 15586 155874. Reshape `permuted_reshaped_padded` to flatten `block_shape` into the batch 15588 dimension, producing an output tensor of shape: 15589 15590 [batch * prod(block_shape)] + 15591 [padded_shape[1] / block_shape[0], 15592 ..., 15593 padded_shape[M] / block_shape[M-1]] + 15594 remaining_shape 15595 15596Some examples: 15597 15598(1) For the following input of shape `[1, 2, 2, 1]`, `block_shape = [2, 2]`, and 15599 `paddings = [[0, 0], [0, 0]]`: 15600 15601``` 15602x = [[[[1], [2]], [[3], [4]]]] 15603``` 15604 15605The output tensor has shape `[4, 1, 1, 1]` and value: 15606 15607``` 15608[[[[1]]], [[[2]]], [[[3]]], [[[4]]]] 15609``` 15610 15611(2) For the following input of shape `[1, 2, 2, 3]`, `block_shape = [2, 2]`, and 15612 `paddings = [[0, 0], [0, 0]]`: 15613 15614``` 15615x = [[[[1, 2, 3], [4, 5, 6]], 15616 [[7, 8, 9], [10, 11, 12]]]] 15617``` 15618 15619The output tensor has shape `[4, 1, 1, 3]` and value: 15620 15621``` 15622[[[[1, 2, 3]]], [[[4, 5, 6]]], [[[7, 8, 9]]], [[[10, 11, 12]]]] 15623``` 15624 15625(3) For the following input of shape `[1, 4, 4, 1]`, `block_shape = [2, 2]`, and 15626 `paddings = [[0, 0], [0, 0]]`: 15627 15628``` 15629x = [[[[1], [2], [3], [4]], 15630 [[5], [6], [7], [8]], 15631 [[9], [10], [11], [12]], 15632 [[13], [14], [15], [16]]]] 15633``` 15634 15635The output tensor has shape `[4, 2, 2, 1]` and value: 15636 15637``` 15638x = [[[[1], [3]], [[9], [11]]], 15639 [[[2], [4]], [[10], [12]]], 15640 [[[5], [7]], [[13], [15]]], 15641 [[[6], [8]], [[14], [16]]]] 15642``` 15643 15644(4) For the following input of shape `[2, 2, 4, 1]`, block_shape = `[2, 2]`, and 15645 paddings = `[[0, 0], [2, 0]]`: 15646 15647``` 15648x = [[[[1], [2], [3], [4]], 15649 [[5], [6], [7], [8]]], 15650 [[[9], [10], [11], [12]], 15651 [[13], [14], [15], [16]]]] 15652``` 15653 15654The output tensor has shape `[8, 1, 3, 1]` and value: 15655 15656``` 15657x = [[[[0], [1], [3]]], [[[0], [9], [11]]], 15658 [[[0], [2], [4]]], [[[0], [10], [12]]], 15659 [[[0], [5], [7]]], [[[0], [13], [15]]], 15660 [[[0], [6], [8]]], [[[0], [14], [16]]]] 15661``` 15662 15663Among others, this operation is useful for reducing atrous convolution into 15664regular convolution. 15665 }]; 15666 15667 let arguments = (ins 15668 Arg<TF_Tensor, [{N-D with shape `input_shape = [batch] + spatial_shape + remaining_shape`, 15669where spatial_shape has `M` dimensions.}]>:$input, 15670 Arg<TF_I32OrI64Tensor, [{1-D with shape `[M]`, all values must be >= 1.}]>:$block_shape, 15671 Arg<TF_I32OrI64Tensor, [{2-D with shape `[M, 2]`, all values must be >= 0. 15672 `paddings[i] = [pad_start, pad_end]` specifies the padding for input dimension 15673 `i + 1`, which corresponds to spatial dimension `i`. It is required that 15674 `block_shape[i]` divides `input_shape[i + 1] + pad_start + pad_end`.}]>:$paddings 15675 ); 15676 15677 let results = (outs 15678 TF_Tensor:$output 15679 ); 15680 15681 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15682 TF_DerivedOperandTypeAttr Tblock_shape = TF_DerivedOperandTypeAttr<1>; 15683 TF_DerivedOperandTypeAttr Tpaddings = TF_DerivedOperandTypeAttr<2>; 15684 15685 let hasVerifier = 1; 15686 15687 let extraClassDeclaration = [{ 15688 static bool isCompatibleReturnTypes(TypeRange l, TypeRange r) { 15689 return ArraysAreCastCompatible(l, r); 15690 } 15691 }]; 15692} 15693 15694def TF_SpaceToDepthOp : TF_Op<"SpaceToDepth", [NoSideEffect]> { 15695 let summary = "SpaceToDepth for tensors of type T."; 15696 15697 let description = [{ 15698Rearranges blocks of spatial data, into depth. More specifically, 15699this op outputs a copy of the input tensor where values from the `height` 15700and `width` dimensions are moved to the `depth` dimension. 15701The attr `block_size` indicates the input block size. 15702 15703 * Non-overlapping blocks of size `block_size x block size` are rearranged 15704 into depth at each location. 15705 * The depth of the output tensor is `block_size * block_size * input_depth`. 15706 * The Y, X coordinates within each block of the input become the high order 15707 component of the output channel index. 15708 * The input tensor's height and width must be divisible by block_size. 15709 15710The `data_format` attr specifies the layout of the input and output tensors 15711with the following options: 15712 "NHWC": `[ batch, height, width, channels ]` 15713 "NCHW": `[ batch, channels, height, width ]` 15714 "NCHW_VECT_C": 15715 `qint8 [ batch, channels / 4, height, width, 4 ]` 15716 15717It is useful to consider the operation as transforming a 6-D Tensor. 15718e.g. for data_format = NHWC, 15719 Each element in the input tensor can be specified via 6 coordinates, 15720 ordered by decreasing memory layout significance as: 15721 n,oY,bY,oX,bX,iC (where n=batch index, oX, oY means X or Y coordinates 15722 within the output image, bX, bY means coordinates 15723 within the input block, iC means input channels). 15724 The output would be a transpose to the following layout: 15725 n,oY,oX,bY,bX,iC 15726 15727This operation is useful for resizing the activations between convolutions 15728(but keeping all data), e.g. instead of pooling. It is also useful for training 15729purely convolutional models. 15730 15731For example, given an input of shape `[1, 2, 2, 1]`, data_format = "NHWC" and 15732block_size = 2: 15733 15734``` 15735x = [[[[1], [2]], 15736 [[3], [4]]]] 15737``` 15738 15739This operation will output a tensor of shape `[1, 1, 1, 4]`: 15740 15741``` 15742[[[[1, 2, 3, 4]]]] 15743``` 15744 15745Here, the input has a batch of 1 and each batch element has shape `[2, 2, 1]`, 15746the corresponding output will have a single element (i.e. width and height are 15747both 1) and will have a depth of 4 channels (1 * block_size * block_size). 15748The output element shape is `[1, 1, 4]`. 15749 15750For an input tensor with larger depth, here of shape `[1, 2, 2, 3]`, e.g. 15751 15752``` 15753x = [[[[1, 2, 3], [4, 5, 6]], 15754 [[7, 8, 9], [10, 11, 12]]]] 15755``` 15756 15757This operation, for block_size of 2, will return the following tensor of shape 15758`[1, 1, 1, 12]` 15759 15760``` 15761[[[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]]]] 15762``` 15763 15764Similarly, for the following input of shape `[1 4 4 1]`, and a block size of 2: 15765 15766``` 15767x = [[[[1], [2], [5], [6]], 15768 [[3], [4], [7], [8]], 15769 [[9], [10], [13], [14]], 15770 [[11], [12], [15], [16]]]] 15771``` 15772 15773the operator will return the following tensor of shape `[1 2 2 4]`: 15774 15775``` 15776x = [[[[1, 2, 3, 4], 15777 [5, 6, 7, 8]], 15778 [[9, 10, 11, 12], 15779 [13, 14, 15, 16]]]] 15780``` 15781 }]; 15782 15783 let arguments = (ins 15784 TF_Tensor:$input, 15785 15786 ConfinedAttr<I64Attr, [IntMinValue<2>]>:$block_size, 15787 DefaultValuedAttr<TF_AnyStrAttrOf<["NHWC", "NCHW", "NCHW_VECT_C"]>, "\"NHWC\"">:$data_format 15788 ); 15789 15790 let results = (outs 15791 TF_Tensor:$output 15792 ); 15793 15794 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 15795} 15796 15797def TF_SparseAddOp : TF_Op<"SparseAdd", [NoSideEffect]> { 15798 let summary = [{ 15799Adds two `SparseTensor` objects to produce another `SparseTensor`. 15800 }]; 15801 15802 let description = [{ 15803The input `SparseTensor` objects' indices are assumed ordered in standard 15804lexicographic order. If this is not the case, before this step run 15805`SparseReorder` to restore index ordering. 15806 15807By default, if two values sum to zero at some index, the output `SparseTensor` 15808would still include that particular location in its index, storing a zero in the 15809corresponding value slot. To override this, callers can specify `thresh`, 15810indicating that if the sum has a magnitude strictly smaller than `thresh`, its 15811corresponding value and index would then not be included. In particular, 15812`thresh == 0` (default) means everything is kept and actual thresholding happens 15813only for a positive value. 15814 15815In the following shapes, `nnz` is the count after taking `thresh` into account. 15816 }]; 15817 15818 let arguments = (ins 15819 Arg<TF_Int64Tensor, [{2-D. The `indices` of the first `SparseTensor`, size `[nnz, ndims]` Matrix.}]>:$a_indices, 15820 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{1-D. The `values` of the first `SparseTensor`, size `[nnz]` Vector.}]>:$a_values, 15821 Arg<TF_Int64Tensor, [{1-D. The `shape` of the first `SparseTensor`, size `[ndims]` Vector.}]>:$a_shape, 15822 Arg<TF_Int64Tensor, [{2-D. The `indices` of the second `SparseTensor`, size `[nnz, ndims]` Matrix.}]>:$b_indices, 15823 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{1-D. The `values` of the second `SparseTensor`, size `[nnz]` Vector.}]>:$b_values, 15824 Arg<TF_Int64Tensor, [{1-D. The `shape` of the second `SparseTensor`, size `[ndims]` Vector.}]>:$b_shape, 15825 Arg<TF_IntOrFpTensor, [{0-D. The magnitude threshold that determines if an output value/index 15826pair takes space.}]>:$thresh 15827 ); 15828 15829 let results = (outs 15830 TF_Int64Tensor:$sum_indices, 15831 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$sum_values, 15832 TF_Int64Tensor:$sum_shape 15833 ); 15834 15835 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 15836 TF_DerivedOperandTypeAttr Treal = TF_DerivedOperandTypeAttr<6>; 15837} 15838 15839def TF_SparseFillEmptyRowsOp : TF_Op<"SparseFillEmptyRows", [NoSideEffect]> { 15840 let summary = [{ 15841Fills empty rows in the input 2-D `SparseTensor` with a default value. 15842 }]; 15843 15844 let description = [{ 15845The input `SparseTensor` is represented via the tuple of inputs 15846(`indices`, `values`, `dense_shape`). The output `SparseTensor` has the 15847same `dense_shape` but with indices `output_indices` and values 15848`output_values`. 15849 15850This op inserts a single entry for every row that doesn't have any values. 15851The index is created as `[row, 0, ..., 0]` and the inserted value 15852is `default_value`. 15853 15854For example, suppose `sp_input` has shape `[5, 6]` and non-empty values: 15855 15856 [0, 1]: a 15857 [0, 3]: b 15858 [2, 0]: c 15859 [3, 1]: d 15860 15861Rows 1 and 4 are empty, so the output will be of shape `[5, 6]` with values: 15862 15863 [0, 1]: a 15864 [0, 3]: b 15865 [1, 0]: default_value 15866 [2, 0]: c 15867 [3, 1]: d 15868 [4, 0]: default_value 15869 15870The output `SparseTensor` will be in row-major order and will have the 15871same shape as the input. 15872 15873This op also returns an indicator vector shaped `[dense_shape[0]]` such that 15874 15875 empty_row_indicator[i] = True iff row i was an empty row. 15876 15877And a reverse index map vector shaped `[indices.shape[0]]` that is used during 15878backpropagation, 15879 15880 reverse_index_map[j] = out_j s.t. indices[j, :] == output_indices[out_j, :] 15881 }]; 15882 15883 let arguments = (ins 15884 Arg<TF_Int64Tensor, [{2-D. the indices of the sparse tensor.}]>:$indices, 15885 Arg<TF_Tensor, [{1-D. the values of the sparse tensor.}]>:$values, 15886 Arg<TF_Int64Tensor, [{1-D. the shape of the sparse tensor.}]>:$dense_shape, 15887 Arg<TF_Tensor, [{0-D. default value to insert into location `[row, 0, ..., 0]` 15888 for rows missing from the input sparse tensor. 15889output indices: 2-D. the indices of the filled sparse tensor.}]>:$default_value 15890 ); 15891 15892 let results = (outs 15893 TF_Int64Tensor:$output_indices, 15894 Res<TF_Tensor, [{1-D. the values of the filled sparse tensor.}]>:$output_values, 15895 Res<TF_BoolTensor, [{1-D. whether the dense row was missing in the 15896input sparse tensor.}]>:$empty_row_indicator, 15897 Res<TF_Int64Tensor, [{1-D. a map from the input indices to the output indices.}]>:$reverse_index_map 15898 ); 15899 15900 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 15901} 15902 15903def TF_SparseMatMulOp : TF_Op<"SparseMatMul", [NoSideEffect]> { 15904 let summary = [{ 15905Multiply matrix "a" by matrix "b". 15906 }]; 15907 15908 let description = [{ 15909The inputs must be two-dimensional matrices and the inner dimension of "a" must 15910match the outer dimension of "b". Both "a" and "b" must be `Tensor`s not 15911`SparseTensor`s. This op is optimized for the case where at least one of "a" or 15912"b" is sparse, in the sense that they have a large proportion of zero values. 15913The breakeven for using this versus a dense matrix multiply on one platform was 1591430% zero values in the sparse matrix. 15915 15916The gradient computation of this operation will only take advantage of sparsity 15917in the input gradient when that gradient comes from a Relu. 15918 }]; 15919 15920 let arguments = (ins 15921 TensorOf<[TF_Bfloat16, TF_Float32]>:$a, 15922 TensorOf<[TF_Bfloat16, TF_Float32]>:$b, 15923 15924 DefaultValuedAttr<BoolAttr, "false">:$transpose_a, 15925 DefaultValuedAttr<BoolAttr, "false">:$transpose_b, 15926 DefaultValuedAttr<BoolAttr, "false">:$a_is_sparse, 15927 DefaultValuedAttr<BoolAttr, "false">:$b_is_sparse 15928 ); 15929 15930 let results = (outs 15931 TF_Float32Tensor:$product 15932 ); 15933 15934 TF_DerivedOperandTypeAttr Ta = TF_DerivedOperandTypeAttr<0>; 15935 TF_DerivedOperandTypeAttr Tb = TF_DerivedOperandTypeAttr<1>; 15936} 15937 15938def TF_SparseReduceSumOp : TF_Op<"SparseReduceSum", [NoSideEffect]> { 15939 let summary = [{ 15940Computes the sum of elements across dimensions of a SparseTensor. 15941 }]; 15942 15943 let description = [{ 15944This Op takes a SparseTensor and is the sparse counterpart to 15945`tf.reduce_sum()`. In particular, this Op also returns a dense `Tensor` 15946instead of a sparse one. 15947 15948Reduces `sp_input` along the dimensions given in `reduction_axes`. Unless 15949`keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in 15950`reduction_axes`. If `keep_dims` is true, the reduced dimensions are retained 15951with length 1. 15952 15953If `reduction_axes` has no entries, all dimensions are reduced, and a tensor 15954with a single element is returned. Additionally, the axes can be negative, 15955which are interpreted according to the indexing rules in Python. 15956 }]; 15957 15958 let arguments = (ins 15959 Arg<TF_Int64Tensor, [{2-D. `N x R` matrix with the indices of non-empty values in a 15960SparseTensor, possibly not in canonical ordering.}]>:$input_indices, 15961 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{1-D. `N` non-empty values corresponding to `input_indices`.}]>:$input_values, 15962 Arg<TF_Int64Tensor, [{1-D. Shape of the input SparseTensor.}]>:$input_shape, 15963 Arg<TF_Int32Tensor, [{1-D. Length-`K` vector containing the reduction axes.}]>:$reduction_axes, 15964 15965 DefaultValuedAttr<BoolAttr, "false">:$keep_dims 15966 ); 15967 15968 let results = (outs 15969 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{`R-K`-D. The reduced Tensor.}]>:$output 15970 ); 15971 15972 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 15973} 15974 15975def TF_SparseReshapeOp : TF_Op<"SparseReshape", [NoSideEffect]> { 15976 let summary = [{ 15977Reshapes a SparseTensor to represent values in a new dense shape. 15978 }]; 15979 15980 let description = [{ 15981This operation has the same semantics as reshape on the represented dense 15982tensor. The `input_indices` are recomputed based on the requested `new_shape`. 15983 15984If one component of `new_shape` is the special value -1, the size of that 15985dimension is computed so that the total dense size remains constant. At 15986most one component of `new_shape` can be -1. The number of dense elements 15987implied by `new_shape` must be the same as the number of dense elements 15988originally implied by `input_shape`. 15989 15990Reshaping does not affect the order of values in the SparseTensor. 15991 15992If the input tensor has rank `R_in` and `N` non-empty values, and `new_shape` 15993has length `R_out`, then `input_indices` has shape `[N, R_in]`, 15994`input_shape` has length `R_in`, `output_indices` has shape `[N, R_out]`, and 15995`output_shape` has length `R_out`. 15996 }]; 15997 15998 let arguments = (ins 15999 Arg<TF_Int64Tensor, [{2-D. `N x R_in` matrix with the indices of non-empty values in a 16000SparseTensor.}]>:$input_indices, 16001 Arg<TF_Int64Tensor, [{1-D. `R_in` vector with the input SparseTensor's dense shape.}]>:$input_shape, 16002 Arg<TF_Int64Tensor, [{1-D. `R_out` vector with the requested new dense shape.}]>:$new_shape 16003 ); 16004 16005 let results = (outs 16006 Res<TF_Int64Tensor, [{2-D. `N x R_out` matrix with the updated indices of non-empty 16007values in the output SparseTensor.}]>:$output_indices, 16008 Res<TF_Int64Tensor, [{1-D. `R_out` vector with the full dense shape of the output 16009SparseTensor. This is the same as `new_shape` but with any -1 dimensions 16010filled in.}]>:$output_shape 16011 ); 16012} 16013 16014def TF_SparseSegmentMeanOp : TF_Op<"SparseSegmentMean", [NoSideEffect]> { 16015 let summary = "Computes the mean along sparse segments of a tensor."; 16016 16017 let description = [{ 16018See `tf.sparse.segment_sum` for usage examples. 16019 16020Like `SegmentMean`, but `segment_ids` can have rank less than `data`'s first 16021dimension, selecting a subset of dimension 0, specified by `indices`. 16022 }]; 16023 16024 let arguments = (ins 16025 TF_FloatTensor:$data, 16026 Arg<TF_I32OrI64Tensor, [{A 1-D tensor. Has same rank as `segment_ids`.}]>:$indices, 16027 Arg<TF_I32OrI64Tensor, [{A 1-D tensor. Values should be sorted and can be repeated.}]>:$segment_ids 16028 ); 16029 16030 let results = (outs 16031 Res<TF_FloatTensor, [{Has same shape as data, except for dimension 0 which 16032has size `k`, the number of segments.}]>:$output 16033 ); 16034 16035 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16036 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 16037 TF_DerivedOperandTypeAttr Tsegmentids = TF_DerivedOperandTypeAttr<2>; 16038} 16039 16040def TF_SparseSegmentMeanGradOp : TF_Op<"SparseSegmentMeanGrad", [NoSideEffect]> { 16041 let summary = "Computes gradients for SparseSegmentMean."; 16042 16043 let description = [{ 16044Returns tensor "output" with same shape as grad, except for dimension 0 whose 16045value is output_dim0. 16046 }]; 16047 16048 let arguments = (ins 16049 Arg<TF_FloatTensor, [{gradient propagated to the SparseSegmentMean op.}]>:$grad, 16050 Arg<TF_I32OrI64Tensor, [{indices passed to the corresponding SparseSegmentMean op.}]>:$indices, 16051 Arg<TF_I32OrI64Tensor, [{segment_ids passed to the corresponding SparseSegmentMean op.}]>:$segment_ids, 16052 Arg<TF_Int32Tensor, [{dimension 0 of "data" passed to SparseSegmentMean op.}]>:$output_dim0 16053 ); 16054 16055 let results = (outs 16056 TF_FloatTensor:$output 16057 ); 16058 16059 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16060 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 16061 TF_DerivedOperandTypeAttr Tsegmentids = TF_DerivedOperandTypeAttr<2>; 16062} 16063 16064def TF_SparseSegmentMeanWithNumSegmentsOp : TF_Op<"SparseSegmentMeanWithNumSegments", [NoSideEffect]> { 16065 let summary = "Computes the mean along sparse segments of a tensor."; 16066 16067 let description = [{ 16068Like `SparseSegmentMean`, but allows missing ids in `segment_ids`. If an id is 16069missing, the `output` tensor at that position will be zeroed. 16070 16071Read 16072[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 16073for an explanation of segments. 16074 }]; 16075 16076 let arguments = (ins 16077 TF_FloatTensor:$data, 16078 Arg<TF_I32OrI64Tensor, [{A 1-D tensor. Has same rank as `segment_ids`.}]>:$indices, 16079 Arg<TF_I32OrI64Tensor, [{A 1-D tensor. Values should be sorted and can be repeated.}]>:$segment_ids, 16080 Arg<TF_I32OrI64Tensor, [{Should equal the number of distinct segment IDs.}]>:$num_segments 16081 ); 16082 16083 let results = (outs 16084 Res<TF_FloatTensor, [{Has same shape as data, except for dimension 0 which has size 16085`num_segments`.}]>:$output 16086 ); 16087 16088 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16089 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 16090 TF_DerivedOperandTypeAttr Tnumsegments = TF_DerivedOperandTypeAttr<3>; 16091 TF_DerivedOperandTypeAttr Tsegmentids = TF_DerivedOperandTypeAttr<2>; 16092} 16093 16094def TF_SparseSegmentSqrtNOp : TF_Op<"SparseSegmentSqrtN", [NoSideEffect]> { 16095 let summary = [{ 16096Computes the sum along sparse segments of a tensor divided by the sqrt of N. 16097 }]; 16098 16099 let description = [{ 16100N is the size of the segment being reduced. 16101 16102See `tf.sparse.segment_sum` for usage examples. 16103 }]; 16104 16105 let arguments = (ins 16106 TF_FloatTensor:$data, 16107 Arg<TF_I32OrI64Tensor, [{A 1-D tensor. Has same rank as `segment_ids`.}]>:$indices, 16108 Arg<TF_I32OrI64Tensor, [{A 1-D tensor. Values should be sorted and can be repeated.}]>:$segment_ids 16109 ); 16110 16111 let results = (outs 16112 Res<TF_FloatTensor, [{Has same shape as data, except for dimension 0 which 16113has size `k`, the number of segments.}]>:$output 16114 ); 16115 16116 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16117 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 16118 TF_DerivedOperandTypeAttr Tsegmentids = TF_DerivedOperandTypeAttr<2>; 16119} 16120 16121def TF_SparseSegmentSqrtNGradOp : TF_Op<"SparseSegmentSqrtNGrad", [NoSideEffect]> { 16122 let summary = "Computes gradients for SparseSegmentSqrtN."; 16123 16124 let description = [{ 16125Returns tensor "output" with same shape as grad, except for dimension 0 whose 16126value is output_dim0. 16127 }]; 16128 16129 let arguments = (ins 16130 Arg<TF_FloatTensor, [{gradient propagated to the SparseSegmentSqrtN op.}]>:$grad, 16131 Arg<TF_I32OrI64Tensor, [{indices passed to the corresponding SparseSegmentSqrtN op.}]>:$indices, 16132 Arg<TF_I32OrI64Tensor, [{segment_ids passed to the corresponding SparseSegmentSqrtN op.}]>:$segment_ids, 16133 Arg<TF_Int32Tensor, [{dimension 0 of "data" passed to SparseSegmentSqrtN op.}]>:$output_dim0 16134 ); 16135 16136 let results = (outs 16137 TF_FloatTensor:$output 16138 ); 16139 16140 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16141 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 16142 TF_DerivedOperandTypeAttr Tsegmentids = TF_DerivedOperandTypeAttr<2>; 16143} 16144 16145def TF_SparseSegmentSqrtNWithNumSegmentsOp : TF_Op<"SparseSegmentSqrtNWithNumSegments", [NoSideEffect]> { 16146 let summary = [{ 16147Computes the sum along sparse segments of a tensor divided by the sqrt of N. 16148 }]; 16149 16150 let description = [{ 16151N is the size of the segment being reduced. 16152 16153Like `SparseSegmentSqrtN`, but allows missing ids in `segment_ids`. If an id is 16154missing, the `output` tensor at that position will be zeroed. 16155 16156Read 16157[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 16158for an explanation of segments. 16159 }]; 16160 16161 let arguments = (ins 16162 TF_FloatTensor:$data, 16163 Arg<TF_I32OrI64Tensor, [{A 1-D tensor. Has same rank as `segment_ids`.}]>:$indices, 16164 Arg<TF_I32OrI64Tensor, [{A 1-D tensor. Values should be sorted and can be repeated.}]>:$segment_ids, 16165 Arg<TF_I32OrI64Tensor, [{Should equal the number of distinct segment IDs.}]>:$num_segments 16166 ); 16167 16168 let results = (outs 16169 Res<TF_FloatTensor, [{Has same shape as data, except for dimension 0 which 16170has size `k`, the number of segments.}]>:$output 16171 ); 16172 16173 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16174 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 16175 TF_DerivedOperandTypeAttr Tnumsegments = TF_DerivedOperandTypeAttr<3>; 16176 TF_DerivedOperandTypeAttr Tsegmentids = TF_DerivedOperandTypeAttr<2>; 16177} 16178 16179def TF_SparseSegmentSumOp : TF_Op<"SparseSegmentSum", [NoSideEffect]> { 16180 let summary = "Computes the sum along sparse segments of a tensor."; 16181 16182 let description = [{ 16183Read 16184[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 16185for an explanation of segments. 16186 16187Like `SegmentSum`, but `segment_ids` can have rank less than `data`'s first 16188dimension, selecting a subset of dimension 0, specified by `indices`. 16189 16190For example: 16191 16192```python 16193c = tf.constant([[1,2,3,4], [-1,-2,-3,-4], [5,6,7,8]]) 16194 16195# Select two rows, one segment. 16196tf.sparse_segment_sum(c, tf.constant([0, 1]), tf.constant([0, 0])) 16197# => [[0 0 0 0]] 16198 16199# Select two rows, two segment. 16200tf.sparse_segment_sum(c, tf.constant([0, 1]), tf.constant([0, 1])) 16201# => [[ 1 2 3 4] 16202# [-1 -2 -3 -4]] 16203 16204# Select all rows, two segments. 16205tf.sparse_segment_sum(c, tf.constant([0, 1, 2]), tf.constant([0, 0, 1])) 16206# => [[0 0 0 0] 16207# [5 6 7 8]] 16208 16209# Which is equivalent to: 16210tf.segment_sum(c, tf.constant([0, 0, 1])) 16211``` 16212 }]; 16213 16214 let arguments = (ins 16215 TF_IntOrFpTensor:$data, 16216 Arg<TF_I32OrI64Tensor, [{A 1-D tensor. Has same rank as `segment_ids`.}]>:$indices, 16217 Arg<TF_I32OrI64Tensor, [{A 1-D tensor. Values should be sorted and can be repeated.}]>:$segment_ids 16218 ); 16219 16220 let results = (outs 16221 Res<TF_IntOrFpTensor, [{Has same shape as data, except for dimension 0 which 16222has size `k`, the number of segments.}]>:$output 16223 ); 16224 16225 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16226 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 16227 TF_DerivedOperandTypeAttr Tsegmentids = TF_DerivedOperandTypeAttr<2>; 16228} 16229 16230def TF_SparseSoftmaxCrossEntropyWithLogitsOp : TF_Op<"SparseSoftmaxCrossEntropyWithLogits", [NoSideEffect]> { 16231 let summary = [{ 16232Computes softmax cross entropy cost and gradients to backpropagate. 16233 }]; 16234 16235 let description = [{ 16236Unlike `SoftmaxCrossEntropyWithLogits`, this operation does not accept 16237a matrix of label probabilities, but rather a single label per row 16238of features. This label is considered to have probability 1.0 for the 16239given row. 16240 16241Inputs are the logits, not probabilities. 16242 }]; 16243 16244 let arguments = (ins 16245 Arg<TF_FloatTensor, [{batch_size x num_classes matrix}]>:$features, 16246 Arg<TF_I32OrI64Tensor, [{batch_size vector with values in [0, num_classes). 16247This is the label for the given minibatch entry.}]>:$labels 16248 ); 16249 16250 let results = (outs 16251 Res<TF_FloatTensor, [{Per example loss (batch_size vector).}]>:$loss, 16252 Res<TF_FloatTensor, [{backpropagated gradients (batch_size x num_classes matrix).}]>:$backprop 16253 ); 16254 16255 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16256 TF_DerivedOperandTypeAttr Tlabels = TF_DerivedOperandTypeAttr<1>; 16257 16258 let hasVerifier = 1; 16259} 16260 16261def TF_SparseTensorDenseMatMulOp : TF_Op<"SparseTensorDenseMatMul", [NoSideEffect]> { 16262 let summary = [{ 16263Multiply SparseTensor (of rank 2) "A" by dense matrix "B". 16264 }]; 16265 16266 let description = [{ 16267No validity checking is performed on the indices of A. However, the following 16268input format is recommended for optimal behavior: 16269 16270if adjoint_a == false: 16271 A should be sorted in lexicographically increasing order. Use SparseReorder 16272 if you're not sure. 16273if adjoint_a == true: 16274 A should be sorted in order of increasing dimension 1 (i.e., "column major" 16275 order instead of "row major" order). 16276 }]; 16277 16278 let arguments = (ins 16279 Arg<TF_I32OrI64Tensor, [{2-D. The `indices` of the `SparseTensor`, size `[nnz, 2]` Matrix.}]>:$a_indices, 16280 Arg<TF_Tensor, [{1-D. The `values` of the `SparseTensor`, size `[nnz]` Vector.}]>:$a_values, 16281 Arg<TF_Int64Tensor, [{1-D. The `shape` of the `SparseTensor`, size `[2]` Vector.}]>:$a_shape, 16282 Arg<TF_Tensor, [{2-D. A dense Matrix.}]>:$b, 16283 16284 DefaultValuedAttr<BoolAttr, "false">:$adjoint_a, 16285 DefaultValuedAttr<BoolAttr, "false">:$adjoint_b 16286 ); 16287 16288 let results = (outs 16289 TF_Tensor:$product 16290 ); 16291 16292 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 16293 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<0>; 16294} 16295 16296def TF_SparseToDenseOp : TF_Op<"SparseToDense", [NoSideEffect]> { 16297 let summary = "Converts a sparse representation into a dense tensor."; 16298 16299 let description = [{ 16300Builds an array `dense` with shape `output_shape` such that 16301 16302``` 16303# If sparse_indices is scalar 16304dense[i] = (i == sparse_indices ? sparse_values : default_value) 16305 16306# If sparse_indices is a vector, then for each i 16307dense[sparse_indices[i]] = sparse_values[i] 16308 16309# If sparse_indices is an n by d matrix, then for each i in [0, n) 16310dense[sparse_indices[i][0], ..., sparse_indices[i][d-1]] = sparse_values[i] 16311``` 16312 16313All other values in `dense` are set to `default_value`. If `sparse_values` is a 16314scalar, all sparse indices are set to this single value. 16315 16316Indices should be sorted in lexicographic order, and indices must not 16317contain any repeats. If `validate_indices` is true, these properties 16318are checked during execution. 16319 }]; 16320 16321 let arguments = (ins 16322 Arg<TF_I32OrI64Tensor, [{0-D, 1-D, or 2-D. `sparse_indices[i]` contains the complete 16323index where `sparse_values[i]` will be placed.}]>:$sparse_indices, 16324 Arg<TF_I32OrI64Tensor, [{1-D. Shape of the dense output tensor.}]>:$output_shape, 16325 Arg<TF_Tensor, [{1-D. Values corresponding to each row of `sparse_indices`, 16326or a scalar value to be used for all sparse indices.}]>:$sparse_values, 16327 Arg<TF_Tensor, [{Scalar value to set for indices not specified in 16328`sparse_indices`.}]>:$default_value, 16329 16330 DefaultValuedAttr<BoolAttr, "true">:$validate_indices 16331 ); 16332 16333 let results = (outs 16334 Res<TF_Tensor, [{Dense output tensor of shape `output_shape`.}]>:$dense 16335 ); 16336 16337 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 16338 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<0>; 16339} 16340 16341def TF_SplitOp : TF_Op<"Split", [NoSideEffect]> { 16342 let summary = "Splits a tensor into `num_split` tensors along one dimension."; 16343 16344 let arguments = (ins 16345 Arg<TF_Int32Tensor, [{0-D. The dimension along which to split. Must be in the range 16346`[-rank(value), rank(value))`.}]>:$split_dim, 16347 Arg<TF_Tensor, [{The tensor to split.}]>:$value 16348 ); 16349 16350 let results = (outs 16351 Res<Variadic<TF_Tensor>, [{They are identically shaped tensors, whose shape matches that of `value` 16352except along `axis`, where their sizes are 16353`values.shape[split_dim] / num_split`.}]>:$output 16354 ); 16355 16356 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 16357 TF_DerivedResultSizeAttr num_split = TF_DerivedResultSizeAttr<0>; 16358 16359 let hasVerifier = 1; 16360} 16361 16362def TF_SplitVOp : TF_Op<"SplitV", [NoSideEffect]> { 16363 let summary = "Splits a tensor into `num_split` tensors along one dimension."; 16364 16365 let arguments = (ins 16366 Arg<TF_Tensor, [{The tensor to split.}]>:$value, 16367 Arg<TF_I32OrI64Tensor, [{list containing the sizes of each output tensor along the split 16368dimension. Must sum to the dimension of value along split_dim. 16369Can contain one -1 indicating that dimension is to be inferred.}]>:$size_splits, 16370 Arg<TF_Int32Tensor, [{0-D. The dimension along which to split. Must be in the range 16371`[-rank(value), rank(value))`.}]>:$split_dim 16372 ); 16373 16374 let results = (outs 16375 Res<Variadic<TF_Tensor>, [{Tensors whose shape matches that of `value` 16376except along `axis`, where their sizes are 16377`size_splits[i]`.}]>:$output 16378 ); 16379 16380 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16381 TF_DerivedOperandTypeAttr Tlen = TF_DerivedOperandTypeAttr<1>; 16382 TF_DerivedResultSizeAttr num_split = TF_DerivedResultSizeAttr<0>; 16383 16384 let hasVerifier = 1; 16385} 16386 16387def TF_SqrtOp : TF_Op<"Sqrt", [NoSideEffect, SameOperandsAndResultType]> { 16388 let summary = "Computes square root of x element-wise."; 16389 16390 let description = [{ 16391I.e., \\(y = \sqrt{x} = x^{1/2}\\). 16392 }]; 16393 16394 let arguments = (ins 16395 TF_FpOrComplexTensor:$x 16396 ); 16397 16398 let results = (outs 16399 TF_FpOrComplexTensor:$y 16400 ); 16401 16402 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16403} 16404 16405def TF_SqrtGradOp : TF_Op<"SqrtGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 16406 let summary = "Computes the gradient for the sqrt of `x` wrt its input."; 16407 16408 let description = [{ 16409Specifically, `grad = dy * 0.5 / y`, where `y = sqrt(x)`, and `dy` 16410is the corresponding input gradient. 16411 }]; 16412 16413 let arguments = (ins 16414 TF_FpOrComplexTensor:$y, 16415 TF_FpOrComplexTensor:$dy 16416 ); 16417 16418 let results = (outs 16419 TF_FpOrComplexTensor:$z 16420 ); 16421 16422 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16423} 16424 16425def TF_SquareOp : TF_Op<"Square", [NoSideEffect, SameOperandsAndResultType]> { 16426 let summary = "Computes square of x element-wise."; 16427 16428 let description = [{ 16429I.e., \\(y = x * x = x^2\\). 16430 }]; 16431 16432 let arguments = (ins 16433 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$x 16434 ); 16435 16436 let results = (outs 16437 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$y 16438 ); 16439 16440 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16441 16442 let hasCanonicalizer = 1; 16443 let extraClassDeclaration = [{ 16444 static bool isCompatibleReturnTypes(TypeRange inferred, TypeRange actual) { 16445 return ArraysAreCastCompatible(inferred, actual); 16446 } 16447 }]; 16448} 16449 16450def TF_SquaredDifferenceOp : TF_Op<"SquaredDifference", [Commutative, NoSideEffect, ResultsBroadcastableShape]>, 16451 WithBroadcastableBinOpBuilder { 16452 let summary = "Returns conj(x - y)(x - y) element-wise."; 16453 16454 let description = [{ 16455*NOTE*: `SquaredDifference` supports broadcasting. More about broadcasting 16456[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 16457 }]; 16458 16459 let arguments = (ins 16460 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$x, 16461 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$y 16462 ); 16463 16464 let results = (outs 16465 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>:$z 16466 ); 16467 16468 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16469} 16470 16471def TF_SqueezeOp : TF_Op<"Squeeze", [NoSideEffect]> { 16472 let summary = "Removes dimensions of size 1 from the shape of a tensor."; 16473 16474 let description = [{ 16475Given a tensor `input`, this operation returns a tensor of the same type with 16476all dimensions of size 1 removed. If you don't want to remove all size 1 16477dimensions, you can remove specific size 1 dimensions by specifying 16478`axis`. 16479 16480For example: 16481 16482``` 16483# 't' is a tensor of shape [1, 2, 1, 3, 1, 1] 16484shape(squeeze(t)) ==> [2, 3] 16485``` 16486 16487Or, to remove specific size 1 dimensions: 16488 16489``` 16490# 't' is a tensor of shape [1, 2, 1, 3, 1, 1] 16491shape(squeeze(t, [2, 4])) ==> [1, 2, 3, 1] 16492``` 16493 }]; 16494 16495 let arguments = (ins 16496 Arg<TF_Tensor, [{The `input` to squeeze.}]>:$input, 16497 16498 DefaultValuedAttr<I64ArrayAttr, "{}">:$squeeze_dims 16499 ); 16500 16501 let results = (outs 16502 Res<TF_Tensor, [{Contains the same data as `input`, but has one or more dimensions of 16503size 1 removed.}]>:$output 16504 ); 16505 16506 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16507 16508 let hasVerifier = 1; 16509} 16510 16511def TF_StackCloseV2Op : TF_Op<"StackCloseV2", []> { 16512 let summary = "Delete the stack from its resource container."; 16513 16514 let arguments = (ins 16515 Arg<TF_ResourceTensor, [{The handle to a stack.}], [TF_StackFree]>:$handle 16516 ); 16517 16518 let results = (outs); 16519} 16520 16521def TF_StackPopV2Op : TF_Op<"StackPopV2", []> { 16522 let summary = "Pop the element at the top of the stack."; 16523 16524 let arguments = (ins 16525 Arg<TF_ResourceTensor, [{The handle to a stack.}], [TF_StackRead, TF_StackWrite]>:$handle 16526 ); 16527 16528 let results = (outs 16529 Res<TF_Tensor, [{The tensor that is popped from the top of the stack.}]>:$elem 16530 ); 16531 16532 TF_DerivedResultTypeAttr elem_type = TF_DerivedResultTypeAttr<0>; 16533} 16534 16535def TF_StackPushV2Op : TF_Op<"StackPushV2", []> { 16536 let summary = "Push an element onto the stack."; 16537 16538 let arguments = (ins 16539 Arg<TF_ResourceTensor, [{The handle to a stack.}], [TF_StackRead, TF_StackWrite]>:$handle, 16540 Arg<TF_Tensor, [{The tensor to be pushed onto the stack.}]>:$elem, 16541 16542 DefaultValuedAttr<BoolAttr, "false">:$swap_memory 16543 ); 16544 16545 let results = (outs 16546 Res<TF_Tensor, [{The same tensor as the input 'elem'.}]>:$output 16547 ); 16548 16549 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 16550} 16551 16552def TF_StackV2Op : TF_Op<"StackV2", [TF_UniqueResourceAllocation]> { 16553 let summary = "A stack that produces elements in first-in last-out order."; 16554 16555 let arguments = (ins 16556 Arg<TF_Int32Tensor, [{The maximum size of the stack if non-negative. If negative, the stack 16557size is unlimited.}]>:$max_size, 16558 16559 TypeAttr:$elem_type, 16560 DefaultValuedAttr<StrAttr, "\"\"">:$stack_name 16561 ); 16562 16563 let results = (outs 16564 Res<TF_ResourceTensor, [{The handle to the stack.}], [TF_StackAlloc]>:$handle 16565 ); 16566} 16567 16568def TF_StatefulStandardNormalV2Op : TF_Op<"StatefulStandardNormalV2", []> { 16569 let summary = "Outputs random values from a normal distribution."; 16570 16571 let description = [{ 16572The generated values will have mean 0 and standard deviation 1. 16573 }]; 16574 16575 let arguments = (ins 16576 Arg<TF_ResourceTensor, [{The handle of the resource variable that stores the state of the RNG.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 16577 Arg<TF_Int64Tensor, [{The RNG algorithm.}]>:$algorithm, 16578 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape 16579 ); 16580 16581 let results = (outs 16582 Res<TF_FloatTensor, [{A tensor of the specified shape filled with random normal values.}]>:$output 16583 ); 16584 16585 TF_DerivedOperandTypeAttr shape_dtype = TF_DerivedOperandTypeAttr<2>; 16586 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 16587} 16588 16589def TF_StatefulTruncatedNormalOp : TF_Op<"StatefulTruncatedNormal", []> { 16590 let summary = "Outputs random values from a truncated normal distribution."; 16591 16592 let description = [{ 16593The generated values follow a normal distribution with mean 0 and standard 16594deviation 1, except that values whose magnitude is more than 2 standard 16595deviations from the mean are dropped and re-picked. 16596 }]; 16597 16598 let arguments = (ins 16599 Arg<TF_ResourceTensor, [{The handle of the resource variable that stores the state of the RNG.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 16600 Arg<TF_Int64Tensor, [{The RNG algorithm.}]>:$algorithm, 16601 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape 16602 ); 16603 16604 let results = (outs 16605 Res<TF_FloatTensor, [{Random values with specified shape.}]>:$output 16606 ); 16607 16608 TF_DerivedOperandTypeAttr shape_dtype = TF_DerivedOperandTypeAttr<2>; 16609 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 16610} 16611 16612def TF_StatefulUniformOp : TF_Op<"StatefulUniform", []> { 16613 let summary = "Outputs random values from a uniform distribution."; 16614 16615 let description = [{ 16616The generated values follow a uniform distribution in the range `[0, 1)`. The 16617lower bound 0 is included in the range, while the upper bound 1 is excluded. 16618 }]; 16619 16620 let arguments = (ins 16621 Arg<TF_ResourceTensor, [{The handle of the resource variable that stores the state of the RNG.}], [TF_VariableRead, TF_VariableWrite]>:$resource, 16622 Arg<TF_Int64Tensor, [{The RNG algorithm.}]>:$algorithm, 16623 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape 16624 ); 16625 16626 let results = (outs 16627 Res<TF_FloatTensor, [{Random values with specified shape.}]>:$output 16628 ); 16629 16630 TF_DerivedOperandTypeAttr shape_dtype = TF_DerivedOperandTypeAttr<2>; 16631 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 16632} 16633 16634def TF_StatelessMultinomialOp : TF_Op<"StatelessMultinomial", [NoSideEffect, TF_NoConstantFold]> { 16635 let summary = "Draws samples from a multinomial distribution."; 16636 16637 let arguments = (ins 16638 Arg<TF_IntOrFpTensor, [{2-D Tensor with shape `[batch_size, num_classes]`. Each slice `[i, :]` 16639represents the unnormalized log probabilities for all classes.}]>:$logits, 16640 Arg<TF_Int32Tensor, [{0-D. Number of independent samples to draw for each row slice.}]>:$num_samples, 16641 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed 16642 ); 16643 16644 let results = (outs 16645 Res<TF_I32OrI64Tensor, [{2-D Tensor with shape `[batch_size, num_samples]`. Each slice `[i, :]` 16646contains the drawn class labels with range `[0, num_classes)`.}]>:$output 16647 ); 16648 16649 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16650 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<2>; 16651 TF_DerivedResultTypeAttr output_dtype = TF_DerivedResultTypeAttr<0>; 16652} 16653 16654def TF_StatelessParameterizedTruncatedNormalOp : TF_Op<"StatelessParameterizedTruncatedNormal", [NoSideEffect, TF_NoConstantFold]> { 16655 let summary = ""; 16656 16657 let arguments = (ins 16658 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16659 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed, 16660 Arg<TensorOf<[TF_Float16, TF_Float32, TF_Float64]>, [{The mean parameter of each batch.}]>:$means, 16661 Arg<TensorOf<[TF_Float16, TF_Float32, TF_Float64]>, [{The standard deviation parameter of each batch. Must be greater than 0.}]>:$stddevs, 16662 Arg<TensorOf<[TF_Float16, TF_Float32, TF_Float64]>, [{The minimum cutoff. May be -infinity.}]>:$minvals, 16663 Arg<TensorOf<[TF_Float16, TF_Float32, TF_Float64]>, [{The maximum cutoff. May be +infinity, and must be more than the minval 16664for each batch.}]>:$maxvals 16665 ); 16666 16667 let results = (outs 16668 Res<TensorOf<[TF_Float16, TF_Float32, TF_Float64]>, [{The outputs are truncated normal samples and are a deterministic function of 16669`shape`, `seed`, `minvals`, `maxvals`, `means` and `stddevs`.}]>:$output 16670 ); 16671 16672 TF_DerivedOperandTypeAttr S = TF_DerivedOperandTypeAttr<0>; 16673 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<1>; 16674 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<2>; 16675} 16676 16677def TF_StatelessRandomBinomialOp : TF_Op<"StatelessRandomBinomial", [NoSideEffect, TF_NoConstantFold]> { 16678 let summary = [{ 16679Outputs deterministic pseudorandom random numbers from a binomial distribution. 16680 }]; 16681 16682 let description = [{ 16683Outputs random values from a binomial distribution. 16684 16685The outputs are a deterministic function of `shape`, `seed`, `counts`, and `probs`. 16686 }]; 16687 16688 let arguments = (ins 16689 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16690 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed, 16691 Arg<TensorOf<[TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{The counts of the binomial distribution. Must be broadcastable with `probs`, 16692and broadcastable with the rightmost dimensions of `shape`.}]>:$counts, 16693 Arg<TensorOf<[TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{The probability of success for the binomial distribution. Must be broadcastable 16694with `counts` and broadcastable with the rightmost dimensions of `shape`.}]>:$probs 16695 ); 16696 16697 let results = (outs 16698 Res<TensorOf<[TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{Random values with specified shape.}]>:$output 16699 ); 16700 16701 TF_DerivedOperandTypeAttr S = TF_DerivedOperandTypeAttr<0>; 16702 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 16703 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<1>; 16704 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 16705} 16706 16707def TF_StatelessRandomGammaV2Op : TF_Op<"StatelessRandomGammaV2", [NoSideEffect, TF_NoConstantFold]> { 16708 let summary = [{ 16709Outputs deterministic pseudorandom random numbers from a gamma distribution. 16710 }]; 16711 16712 let description = [{ 16713Outputs random values from a gamma distribution. 16714 16715The outputs are a deterministic function of `shape`, `seed`, and `alpha`. 16716 }]; 16717 16718 let arguments = (ins 16719 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16720 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed, 16721 Arg<TensorOf<[TF_Float16, TF_Float32, TF_Float64]>, [{The concentration of the gamma distribution. Shape must match the rightmost 16722dimensions of `shape`.}]>:$alpha 16723 ); 16724 16725 let results = (outs 16726 Res<TensorOf<[TF_Float16, TF_Float32, TF_Float64]>, [{Random values with specified shape.}]>:$output 16727 ); 16728 16729 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16730 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<1>; 16731 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<2>; 16732} 16733 16734def TF_StatelessRandomGetAlgOp : TF_Op<"StatelessRandomGetAlg", []> { 16735 let summary = "Picks the best counter-based RNG algorithm based on device."; 16736 16737 let description = [{ 16738This op picks the best counter-based RNG algorithm based on device. 16739 }]; 16740 16741 let arguments = (ins); 16742 16743 let results = (outs 16744 Res<TF_Int32Tensor, [{The RNG algorithm (shape int32[]).}]>:$alg 16745 ); 16746} 16747 16748def TF_StatelessRandomGetKeyCounterOp : TF_Op<"StatelessRandomGetKeyCounter", [NoSideEffect, TF_NoConstantFold]> { 16749 let summary = [{ 16750Scrambles seed into key and counter, using the best algorithm based on device. 16751 }]; 16752 16753 let description = [{ 16754This op scrambles a shape-[2] seed into a key and a counter, both needed by counter-based RNG algorithms. The scrambing uses the best algorithm based on device. The scrambling is opaque but approximately satisfies the property that different seed results in different key/counter pair (which will in turn result in different random numbers). 16755 }]; 16756 16757 let arguments = (ins 16758 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed 16759 ); 16760 16761 let results = (outs 16762 Res<TF_Uint64Tensor, [{Key for the counter-based RNG algorithm (shape uint64[1]).}]>:$key, 16763 Res<TF_Uint64Tensor, [{Counter for the counter-based RNG algorithm. Since counter size is algorithm-dependent, this output will be right-padded with zeros to reach shape uint64[2] (the current maximal counter size among algorithms).}]>:$counter 16764 ); 16765 16766 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<0>; 16767} 16768 16769def TF_StatelessRandomGetKeyCounterAlgOp : TF_Op<"StatelessRandomGetKeyCounterAlg", [NoSideEffect, TF_NoConstantFold]> { 16770 let summary = [{ 16771Picks the best algorithm based on device, and scrambles seed into key and counter. 16772 }]; 16773 16774 let description = [{ 16775This op picks the best counter-based RNG algorithm based on device, and scrambles a shape-[2] seed into a key and a counter, both needed by the counter-based algorithm. The scrambling is opaque but approximately satisfies the property that different seed results in different key/counter pair (which will in turn result in different random numbers). 16776 }]; 16777 16778 let arguments = (ins 16779 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed 16780 ); 16781 16782 let results = (outs 16783 Res<TF_Uint64Tensor, [{Key for the counter-based RNG algorithm (shape uint64[1]).}]>:$key, 16784 Res<TF_Uint64Tensor, [{Counter for the counter-based RNG algorithm. Since counter size is algorithm-dependent, this output will be right-padded with zeros to reach shape uint64[2] (the current maximal counter size among algorithms).}]>:$counter, 16785 Res<TF_Int32Tensor, [{The RNG algorithm (shape int32[]).}]>:$alg 16786 ); 16787 16788 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<0>; 16789} 16790 16791def TF_StatelessRandomNormalOp : TF_Op<"StatelessRandomNormal", [NoSideEffect, TF_NoConstantFold]> { 16792 let summary = [{ 16793Outputs deterministic pseudorandom values from a normal distribution. 16794 }]; 16795 16796 let description = [{ 16797The generated values will have mean 0 and standard deviation 1. 16798 16799The outputs are a deterministic function of `shape` and `seed`. 16800 }]; 16801 16802 let arguments = (ins 16803 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16804 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed 16805 ); 16806 16807 let results = (outs 16808 Res<TF_FloatTensor, [{Random values with specified shape.}]>:$output 16809 ); 16810 16811 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16812 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<1>; 16813 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 16814} 16815 16816def TF_StatelessRandomNormalV2Op : TF_Op<"StatelessRandomNormalV2", [NoSideEffect]> { 16817 let summary = [{ 16818Outputs deterministic pseudorandom values from a normal distribution. 16819 }]; 16820 16821 let description = [{ 16822The generated values will have mean 0 and standard deviation 1. 16823 16824The outputs are a deterministic function of `shape`, `key`, `counter` and `alg`. 16825 }]; 16826 16827 let arguments = (ins 16828 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16829 Arg<TF_Uint64Tensor, [{Key for the counter-based RNG algorithm (shape uint64[1]).}]>:$key, 16830 Arg<TF_Uint64Tensor, [{Initial counter for the counter-based RNG algorithm (shape uint64[2] or uint64[1] depending on the algorithm). If a larger vector is given, only the needed portion on the left (i.e. [:N]) will be used.}]>:$counter, 16831 Arg<TF_Int32Tensor, [{The RNG algorithm (shape int32[]).}]>:$alg 16832 ); 16833 16834 let results = (outs 16835 Res<TF_FloatTensor, [{Random values with specified shape.}]>:$output 16836 ); 16837 16838 TF_DerivedOperandTypeAttr Tshape = TF_DerivedOperandTypeAttr<0>; 16839 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 16840} 16841 16842def TF_StatelessRandomPoissonOp : TF_Op<"StatelessRandomPoisson", [NoSideEffect, TF_NoConstantFold]> { 16843 let summary = [{ 16844Outputs deterministic pseudorandom random numbers from a Poisson distribution. 16845 }]; 16846 16847 let description = [{ 16848Outputs random values from a Poisson distribution. 16849 16850The outputs are a deterministic function of `shape`, `seed`, and `lam`. 16851 }]; 16852 16853 let arguments = (ins 16854 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16855 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed, 16856 Arg<TensorOf<[TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{The rate of the Poisson distribution. Shape must match the rightmost dimensions 16857of `shape`.}]>:$lam 16858 ); 16859 16860 let results = (outs 16861 Res<TensorOf<[TF_Float16, TF_Float32, TF_Float64, TF_Int32, TF_Int64]>, [{Random values with specified shape.}]>:$output 16862 ); 16863 16864 TF_DerivedOperandTypeAttr Rtype = TF_DerivedOperandTypeAttr<2>; 16865 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16866 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<1>; 16867 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 16868} 16869 16870def TF_StatelessRandomUniformOp : TF_Op<"StatelessRandomUniform", [NoSideEffect, TF_NoConstantFold]> { 16871 let summary = [{ 16872Outputs deterministic pseudorandom random values from a uniform distribution. 16873 }]; 16874 16875 let description = [{ 16876The generated values follow a uniform distribution in the range `[0, 1)`. The 16877lower bound 0 is included in the range, while the upper bound 1 is excluded. 16878 16879The outputs are a deterministic function of `shape` and `seed`. 16880 }]; 16881 16882 let arguments = (ins 16883 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16884 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed 16885 ); 16886 16887 let results = (outs 16888 Res<TF_FloatTensor, [{Random values with specified shape.}]>:$output 16889 ); 16890 16891 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16892 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<1>; 16893 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 16894} 16895 16896def TF_StatelessRandomUniformFullIntOp : TF_Op<"StatelessRandomUniformFullInt", [NoSideEffect, TF_NoConstantFold]> { 16897 let summary = [{ 16898Outputs deterministic pseudorandom random integers from a uniform distribution. 16899 }]; 16900 16901 let description = [{ 16902The generated values are uniform integers covering the whole range of `dtype`. 16903 16904The outputs are a deterministic function of `shape` and `seed`. 16905 }]; 16906 16907 let arguments = (ins 16908 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16909 Arg<TensorOf<[TF_Int32, TF_Int64, TF_Uint32, TF_Uint64]>, [{2 seeds (shape [2]).}]>:$seed 16910 ); 16911 16912 let results = (outs 16913 Res<TensorOf<[TF_Int32, TF_Int64, TF_Uint32, TF_Uint64]>, [{Random values with specified shape.}]>:$output 16914 ); 16915 16916 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16917 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<1>; 16918 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 16919} 16920 16921def TF_StatelessRandomUniformFullIntV2Op : TF_Op<"StatelessRandomUniformFullIntV2", [NoSideEffect]> { 16922 let summary = [{ 16923Outputs deterministic pseudorandom random integers from a uniform distribution. 16924 }]; 16925 16926 let description = [{ 16927The generated values are uniform integers covering the whole range of `dtype`. 16928 16929The outputs are a deterministic function of `shape`, `key`, `counter` and `alg`. 16930 }]; 16931 16932 let arguments = (ins 16933 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16934 Arg<TF_Uint64Tensor, [{Key for the counter-based RNG algorithm (shape uint64[1]).}]>:$key, 16935 Arg<TF_Uint64Tensor, [{Initial counter for the counter-based RNG algorithm (shape uint64[2] or uint64[1] depending on the algorithm). If a larger vector is given, only the needed portion on the left (i.e. [:N]) will be used.}]>:$counter, 16936 Arg<TF_Int32Tensor, [{The RNG algorithm (shape int32[]).}]>:$alg 16937 ); 16938 16939 let results = (outs 16940 Res<TensorOf<[TF_Int32, TF_Int64, TF_Uint32, TF_Uint64]>, [{Random values with specified shape.}]>:$output 16941 ); 16942 16943 TF_DerivedOperandTypeAttr Tshape = TF_DerivedOperandTypeAttr<0>; 16944 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 16945} 16946 16947def TF_StatelessRandomUniformIntOp : TF_Op<"StatelessRandomUniformInt", [NoSideEffect, TF_NoConstantFold]> { 16948 let summary = [{ 16949Outputs deterministic pseudorandom random integers from a uniform distribution. 16950 }]; 16951 16952 let description = [{ 16953The generated values follow a uniform distribution in the range `[minval, maxval)`. 16954 16955The outputs are a deterministic function of `shape`, `seed`, `minval`, and `maxval`. 16956 }]; 16957 16958 let arguments = (ins 16959 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16960 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed, 16961 Arg<TF_I32OrI64Tensor, [{Minimum value (inclusive, scalar).}]>:$minval, 16962 Arg<TF_I32OrI64Tensor, [{Maximum value (exclusive, scalar).}]>:$maxval 16963 ); 16964 16965 let results = (outs 16966 Res<TF_I32OrI64Tensor, [{Random values with specified shape.}]>:$output 16967 ); 16968 16969 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 16970 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<1>; 16971 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<2>; 16972} 16973 16974def TF_StatelessRandomUniformIntV2Op : TF_Op<"StatelessRandomUniformIntV2", [NoSideEffect]> { 16975 let summary = [{ 16976Outputs deterministic pseudorandom random integers from a uniform distribution. 16977 }]; 16978 16979 let description = [{ 16980The generated values follow a uniform distribution in the range `[minval, maxval)`. 16981 16982The outputs are a deterministic function of `shape`, `key`, `counter`, `alg`, `minval` and `maxval`. 16983 }]; 16984 16985 let arguments = (ins 16986 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 16987 Arg<TF_Uint64Tensor, [{Key for the counter-based RNG algorithm (shape uint64[1]).}]>:$key, 16988 Arg<TF_Uint64Tensor, [{Initial counter for the counter-based RNG algorithm (shape uint64[2] or uint64[1] depending on the algorithm). If a larger vector is given, only the needed portion on the left (i.e. [:N]) will be used.}]>:$counter, 16989 Arg<TF_Int32Tensor, [{The RNG algorithm (shape int32[]).}]>:$alg, 16990 Arg<TensorOf<[TF_Int32, TF_Int64, TF_Uint32, TF_Uint64]>, [{Minimum value (inclusive, scalar).}]>:$minval, 16991 Arg<TensorOf<[TF_Int32, TF_Int64, TF_Uint32, TF_Uint64]>, [{Maximum value (exclusive, scalar).}]>:$maxval 16992 ); 16993 16994 let results = (outs 16995 Res<TensorOf<[TF_Int32, TF_Int64, TF_Uint32, TF_Uint64]>, [{Random values with specified shape.}]>:$output 16996 ); 16997 16998 TF_DerivedOperandTypeAttr Tshape = TF_DerivedOperandTypeAttr<0>; 16999 TF_DerivedOperandTypeAttr dtype = TF_DerivedOperandTypeAttr<4>; 17000} 17001 17002def TF_StatelessRandomUniformV2Op : TF_Op<"StatelessRandomUniformV2", [NoSideEffect]> { 17003 let summary = [{ 17004Outputs deterministic pseudorandom random values from a uniform distribution. 17005 }]; 17006 17007 let description = [{ 17008The generated values follow a uniform distribution in the range `[0, 1)`. The 17009lower bound 0 is included in the range, while the upper bound 1 is excluded. 17010 17011The outputs are a deterministic function of `shape`, `key`, `counter` and `alg`. 17012 }]; 17013 17014 let arguments = (ins 17015 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 17016 Arg<TF_Uint64Tensor, [{Key for the counter-based RNG algorithm (shape uint64[1]).}]>:$key, 17017 Arg<TF_Uint64Tensor, [{Initial counter for the counter-based RNG algorithm (shape uint64[2] or uint64[1] depending on the algorithm). If a larger vector is given, only the needed portion on the left (i.e. [:N]) will be used.}]>:$counter, 17018 Arg<TF_Int32Tensor, [{The RNG algorithm (shape int32[]).}]>:$alg 17019 ); 17020 17021 let results = (outs 17022 Res<TF_FloatTensor, [{Random values with specified shape.}]>:$output 17023 ); 17024 17025 TF_DerivedOperandTypeAttr Tshape = TF_DerivedOperandTypeAttr<0>; 17026 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 17027} 17028 17029def TF_StatelessTruncatedNormalOp : TF_Op<"StatelessTruncatedNormal", [NoSideEffect, TF_NoConstantFold]> { 17030 let summary = [{ 17031Outputs deterministic pseudorandom values from a truncated normal distribution. 17032 }]; 17033 17034 let description = [{ 17035The generated values follow a normal distribution with mean 0 and standard 17036deviation 1, except that values whose magnitude is more than 2 standard 17037deviations from the mean are dropped and re-picked. 17038 17039The outputs are a deterministic function of `shape` and `seed`. 17040 }]; 17041 17042 let arguments = (ins 17043 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 17044 Arg<TF_I32OrI64Tensor, [{2 seeds (shape [2]).}]>:$seed 17045 ); 17046 17047 let results = (outs 17048 Res<TF_FloatTensor, [{Random values with specified shape.}]>:$output 17049 ); 17050 17051 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17052 TF_DerivedOperandTypeAttr Tseed = TF_DerivedOperandTypeAttr<1>; 17053 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 17054} 17055 17056def TF_StatelessTruncatedNormalV2Op : TF_Op<"StatelessTruncatedNormalV2", [NoSideEffect]> { 17057 let summary = [{ 17058Outputs deterministic pseudorandom values from a truncated normal distribution. 17059 }]; 17060 17061 let description = [{ 17062The generated values follow a normal distribution with mean 0 and standard 17063deviation 1, except that values whose magnitude is more than 2 standard 17064deviations from the mean are dropped and re-picked. 17065 17066The outputs are a deterministic function of `shape`, `key`, `counter` and `alg`. 17067 }]; 17068 17069 let arguments = (ins 17070 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 17071 Arg<TF_Uint64Tensor, [{Key for the counter-based RNG algorithm (shape uint64[1]).}]>:$key, 17072 Arg<TF_Uint64Tensor, [{Initial counter for the counter-based RNG algorithm (shape uint64[2] or uint64[1] depending on the algorithm). If a larger vector is given, only the needed portion on the left (i.e. [:N]) will be used.}]>:$counter, 17073 Arg<TF_Int32Tensor, [{The RNG algorithm (shape int32[]).}]>:$alg 17074 ); 17075 17076 let results = (outs 17077 Res<TF_FloatTensor, [{Random values with specified shape.}]>:$output 17078 ); 17079 17080 TF_DerivedOperandTypeAttr Tshape = TF_DerivedOperandTypeAttr<0>; 17081 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 17082} 17083 17084def TF_StaticRegexFullMatchOp : TF_Op<"StaticRegexFullMatch", [NoSideEffect, SameOperandsAndResultShape]> { 17085 let summary = "Check if the input matches the regex pattern."; 17086 17087 let description = [{ 17088The input is a string tensor of any shape. The pattern is the 17089regular expression to be matched with every element of the input tensor. 17090The boolean values (True or False) of the output tensor indicate 17091if the input matches the regex pattern provided. 17092 17093The pattern follows the re2 syntax (https://github.com/google/re2/wiki/Syntax) 17094 }]; 17095 17096 let arguments = (ins 17097 Arg<TF_StrTensor, [{A string tensor of the text to be processed.}]>:$input, 17098 17099 StrAttr:$pattern 17100 ); 17101 17102 let results = (outs 17103 Res<TF_BoolTensor, [{A bool tensor with the same shape as `input`.}]>:$output 17104 ); 17105} 17106 17107def TF_StopGradientOp : TF_Op<"StopGradient", [NoSideEffect, TF_AllTypesMatch<["input", "output"]>]> { 17108 let summary = "Stops gradient computation."; 17109 17110 let description = [{ 17111When executed in a graph, this op outputs its input tensor as-is. 17112 17113When building ops to compute gradients, this op prevents the contribution of 17114its inputs to be taken into account. Normally, the gradient generator adds ops 17115to a graph to compute the derivatives of a specified 'loss' by recursively 17116finding out inputs that contributed to its computation. If you insert this op 17117in the graph it inputs are masked from the gradient generator. They are not 17118taken into account for computing gradients. 17119 17120This is useful any time you want to compute a value with TensorFlow but need 17121to pretend that the value was a constant. For example, the softmax function 17122for a vector x can be written as 17123 17124```python 17125 17126 def softmax(x): 17127 numerator = tf.exp(x) 17128 denominator = tf.reduce_sum(numerator) 17129 return numerator / denominator 17130``` 17131 17132This however is susceptible to overflow if the values in x are large. An 17133alternative more stable way is to subtract the maximum of x from each of the 17134values. 17135 17136```python 17137 17138 def stable_softmax(x): 17139 z = x - tf.reduce_max(x) 17140 numerator = tf.exp(z) 17141 denominator = tf.reduce_sum(numerator) 17142 return numerator / denominator 17143``` 17144 17145However, when we backprop through the softmax to x, we dont want to backprop 17146through the `tf.reduce_max(x)` (if the max values are not unique then the 17147gradient could flow to the wrong input) calculation and treat that as a 17148constant. Therefore, we should write this out as 17149 17150```python 17151 17152 def stable_softmax(x): 17153 z = x - tf.stop_gradient(tf.reduce_max(x)) 17154 numerator = tf.exp(z) 17155 denominator = tf.reduce_sum(numerator) 17156 return numerator / denominator 17157``` 17158 17159Some other examples include: 17160 17161* The *EM* algorithm where the *M-step* should not involve backpropagation 17162 through the output of the *E-step*. 17163* Contrastive divergence training of Boltzmann machines where, when 17164 differentiating the energy function, the training must not backpropagate 17165 through the graph that generated the samples from the model. 17166* Adversarial training, where no backprop should happen through the adversarial 17167 example generation process. 17168 }]; 17169 17170 let arguments = (ins 17171 TF_Tensor:$input 17172 ); 17173 17174 let results = (outs 17175 TF_Tensor:$output 17176 ); 17177 17178 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17179} 17180 17181def TF_StridedSliceOp : TF_Op<"StridedSlice", [NoSideEffect]> { 17182 let summary = "Return a strided slice from `input`."; 17183 17184 let description = [{ 17185Note, most python users will want to use the Python `Tensor.__getitem__` 17186or `Variable.__getitem__` rather than this op directly. 17187 17188The goal of this op is to produce a new tensor with a subset of 17189the elements from the `n` dimensional `input` tensor. The subset is chosen using 17190a sequence of `m` sparse range specifications encoded into the arguments 17191of this function. Note, in some cases 17192`m` could be equal to `n`, but this need not be the case. Each 17193range specification entry can be one of the following: 17194 17195- An ellipsis (...). Ellipses are used to imply zero or more 17196 dimensions of full-dimension selection and are produced using 17197 `ellipsis_mask`. For example, `foo[...]` is the identity slice. 17198 17199- A new axis. This is used to insert a new shape=1 dimension and is 17200 produced using `new_axis_mask`. For example, `foo[:, ...]` where 17201 `foo` is shape `(3, 4)` produces a `(1, 3, 4)` tensor. 17202 17203 17204- A range `begin:end:stride`. This is used to specify how much to choose from 17205 a given dimension. `stride` can be any integer but 0. `begin` is an integer 17206 which represents the index of the first value to select while `end` represents 17207 the index of the last value to select. The number of values selected in each 17208 dimension is `end - begin` if `stride > 0` and `begin - end` if `stride < 0`. 17209 `begin` and `end` can be negative where `-1` is the last element, `-2` is 17210 the second to last. `begin_mask` controls whether to replace the explicitly 17211 given `begin` with an implicit effective value of `0` if `stride > 0` and 17212 `-1` if `stride < 0`. `end_mask` is analogous but produces the number 17213 required to create the largest open interval. For example, given a shape 17214 `(3,)` tensor `foo[:]`, the effective `begin` and `end` are `0` and `3`. Do 17215 not assume this is equivalent to `foo[0:-1]` which has an effective `begin` 17216 and `end` of `0` and `2`. Another example is `foo[-2::-1]` which reverses the 17217 first dimension of a tensor while dropping the last two (in the original 17218 order elements). For example `foo = [1,2,3,4]; foo[-2::-1]` is `[4,3]`. 17219 17220- A single index. This is used to keep only elements that have a given 17221 index. For example (`foo[2, :]` on a shape `(5,6)` tensor produces a 17222 shape `(6,)` tensor. This is encoded in `begin` and `end` and 17223 `shrink_axis_mask`. 17224 17225Each conceptual range specification is encoded in the op's argument. This 17226encoding is best understand by considering a non-trivial example. In 17227particular, 17228`foo[1, 2:4, None, ..., :-3:-1, :]` will be encoded as 17229 17230``` 17231begin = [1, 2, x, x, 0, x] # x denotes don't care (usually 0) 17232end = [2, 4, x, x, -3, x] 17233strides = [1, 1, x, x, -1, 1] 17234begin_mask = 1<<4 | 1<<5 = 48 17235end_mask = 1<<5 = 32 17236ellipsis_mask = 1<<3 = 8 17237new_axis_mask = 1<<2 = 4 17238shrink_axis_mask = 1<<0 = 1 17239``` 17240 17241In this case if `foo.shape` is (5, 5, 5, 5, 5, 5) the final shape of 17242the slice becomes (2, 1, 5, 5, 2, 5). 17243Let us walk step by step through each argument specification. 17244 172451. The first argument in the example slice is turned into `begin = 1` and 17246`end = begin + 1 = 2`. To disambiguate from the original spec `2:4` we 17247also set the appropriate bit in `shrink_axis_mask`. 17248 172492. `2:4` is contributes 2, 4, 1 to begin, end, and stride. All masks have 17250zero bits contributed. 17251 172523. None is a synonym for `tf.newaxis`. This means insert a dimension of size 1 17253dimension in the final shape. Dummy values are contributed to begin, 17254end and stride, while the new_axis_mask bit is set. 17255 172564. `...` grab the full ranges from as many dimensions as needed to 17257fully specify a slice for every dimension of the input shape. 17258 172595. `:-3:-1` shows the use of negative indices. A negative index `i` associated 17260with a dimension that has shape `s` is converted to a positive index 17261`s + i`. So `-1` becomes `s-1` (i.e. the last element). This conversion 17262is done internally so begin, end and strides receive x, -3, and -1. 17263The appropriate begin_mask bit is set to indicate the start range is the 17264full range (ignoring the x). 17265 172666. `:` indicates that the entire contents of the corresponding dimension 17267is selected. This is equivalent to `::` or `0::1`. begin, end, and strides 17268receive 0, 0, and 1, respectively. The appropriate bits in `begin_mask` and 17269`end_mask` are also set. 17270 17271*Requirements*: 17272 `0 != strides[i] for i in [0, m)` 17273 `ellipsis_mask must be a power of two (only one ellipsis)` 17274 }]; 17275 17276 let arguments = (ins 17277 TF_Tensor:$input, 17278 Arg<TensorOf<[TF_Int16, TF_Int32, TF_Int64]>, [{`begin[k]` specifies the offset into the `k`th range specification. 17279The exact dimension this corresponds to will be determined by context. 17280Out-of-bounds values will be silently clamped. If the `k`th bit of 17281`begin_mask` then `begin[k]` is ignored and the full range of the 17282appropriate dimension is used instead. Negative values causes indexing 17283to start from the highest element e.g. If `foo==[1,2,3]` then `foo[-1]==3`.}]>:$begin, 17284 Arg<TensorOf<[TF_Int16, TF_Int32, TF_Int64]>, [{`end[i]` is like `begin` with the exception that `end_mask` is 17285used to determine full ranges.}]>:$end, 17286 Arg<TensorOf<[TF_Int16, TF_Int32, TF_Int64]>, [{`strides[i]` specifies the increment in the `i`th specification 17287after extracting a given element. Negative indices will reverse 17288the original order. Out or range values are 17289clamped to `[0,dim[i]) if slice[i]>0` or `[-1,dim[i]-1] if slice[i] < 0`}]>:$strides, 17290 17291 DefaultValuedAttr<I64Attr, "0">:$begin_mask, 17292 DefaultValuedAttr<I64Attr, "0">:$end_mask, 17293 DefaultValuedAttr<I64Attr, "0">:$ellipsis_mask, 17294 DefaultValuedAttr<I64Attr, "0">:$new_axis_mask, 17295 DefaultValuedAttr<I64Attr, "0">:$shrink_axis_mask 17296 ); 17297 17298 let results = (outs 17299 TF_Tensor:$output 17300 ); 17301 17302 TF_DerivedOperandTypeAttr Index = TF_DerivedOperandTypeAttr<1>; 17303 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17304 17305 let hasFolder = 1; 17306 17307 let hasVerifier = 1; 17308 17309 let extraClassDeclaration = [{ 17310 // If sliced shape is able to be deduced, returns true, updates 17311 // `begin_indices`, `end_indices`, and `strides` with their canonical 17312 // values, respectively. 17313 bool GetSlicedBoundRanges( 17314 ::llvm::SmallVectorImpl<int64_t> *slice_begin, 17315 ::llvm::SmallVectorImpl<int64_t> *slice_end, 17316 ::llvm::SmallVectorImpl<int64_t> *slice_stride); 17317 }]; 17318} 17319 17320def TF_StridedSliceGradOp : TF_Op<"StridedSliceGrad", [NoSideEffect]> { 17321 let summary = "Returns the gradient of `StridedSlice`."; 17322 17323 let description = [{ 17324Since `StridedSlice` cuts out pieces of its `input` which is size 17325`shape`, its gradient will have the same shape (which is passed here 17326as `shape`). The gradient will be zero in any element that the slice 17327does not select. 17328 17329Arguments are the same as StridedSliceGrad with the exception that 17330`dy` is the input gradient to be propagated and `shape` is the 17331shape of `StridedSlice`'s `input`. 17332 }]; 17333 17334 let arguments = (ins 17335 TF_I32OrI64Tensor:$shape, 17336 TF_I32OrI64Tensor:$begin, 17337 TF_I32OrI64Tensor:$end, 17338 TF_I32OrI64Tensor:$strides, 17339 TF_Tensor:$dy, 17340 17341 DefaultValuedAttr<I64Attr, "0">:$begin_mask, 17342 DefaultValuedAttr<I64Attr, "0">:$end_mask, 17343 DefaultValuedAttr<I64Attr, "0">:$ellipsis_mask, 17344 DefaultValuedAttr<I64Attr, "0">:$new_axis_mask, 17345 DefaultValuedAttr<I64Attr, "0">:$shrink_axis_mask 17346 ); 17347 17348 let results = (outs 17349 TF_Tensor:$output 17350 ); 17351 17352 TF_DerivedOperandTypeAttr Index = TF_DerivedOperandTypeAttr<0>; 17353 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<4>; 17354 17355 let hasVerifier = 1; 17356 17357 let extraClassDeclaration = [{ 17358 // If sliced shape is able to be deduced, returns true, updates `shape` 17359 // with the final shape after performing StridedSlice, and updates 17360 // `begin_indices`, `end_indices`, and `strides` with their canonical 17361 // values, respectively. 17362 bool GetSlicedShapeAndBoundRanges( 17363 ::llvm::SmallVectorImpl<int64_t> *input_shape, 17364 ::llvm::SmallVectorImpl<int64_t> *slice_begin, 17365 ::llvm::SmallVectorImpl<int64_t> *slice_end, 17366 ::llvm::SmallVectorImpl<int64_t> *slice_stride); 17367 }]; 17368} 17369 17370def TF_StringJoinOp : TF_Op<"StringJoin", [NoSideEffect]> { 17371 let summary = [{ 17372Joins the strings in the given list of string tensors into one tensor; 17373 }]; 17374 17375 let description = [{ 17376with the given separator (default is an empty separator). 17377 17378Examples: 17379 17380>>> s = ["hello", "world", "tensorflow"] 17381>>> tf.strings.join(s, " ") 17382<tf.Tensor: shape=(), dtype=string, numpy=b'hello world tensorflow'> 17383 }]; 17384 17385 let arguments = (ins 17386 Arg<Variadic<TF_StrTensor>, [{A list of string tensors. The tensors must all have the same shape, 17387or be scalars. Scalars may be mixed in; these will be broadcast to the shape 17388of non-scalar inputs.}]>:$inputs, 17389 17390 DefaultValuedAttr<StrAttr, "\"\"">:$separator 17391 ); 17392 17393 let results = (outs 17394 TF_StrTensor:$output 17395 ); 17396 17397 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 17398} 17399 17400def TF_StringStripOp : TF_Op<"StringStrip", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 17401 let summary = "Strip leading and trailing whitespaces from the Tensor."; 17402 17403 let description = [{ 17404Examples: 17405 17406>>> tf.strings.strip(["\nTensorFlow", " The python library "]).numpy() 17407array([b'TensorFlow', b'The python library'], dtype=object) 17408 }]; 17409 17410 let arguments = (ins 17411 Arg<TF_StrTensor, [{A string `Tensor` of any shape.}]>:$input 17412 ); 17413 17414 let results = (outs 17415 Res<TF_StrTensor, [{A string `Tensor` of the same shape as the input.}]>:$output 17416 ); 17417} 17418 17419def TF_StringToHashBucketFastOp : TF_Op<"StringToHashBucketFast", [NoSideEffect]> { 17420 let summary = [{ 17421Converts each string in the input Tensor to its hash mod by a number of buckets. 17422 }]; 17423 17424 let description = [{ 17425The hash function is deterministic on the content of the string within the 17426process and will never change. However, it is not suitable for cryptography. 17427This function may be used when CPU time is scarce and inputs are trusted or 17428unimportant. There is a risk of adversaries constructing inputs that all hash 17429to the same bucket. To prevent this problem, use a strong hash function with 17430`tf.string_to_hash_bucket_strong`. 17431 17432Examples: 17433 17434>>> tf.strings.to_hash_bucket_fast(["Hello", "TensorFlow", "2.x"], 3).numpy() 17435array([0, 2, 2]) 17436 }]; 17437 17438 let arguments = (ins 17439 Arg<TF_StrTensor, [{The strings to assign a hash bucket.}]>:$input, 17440 17441 ConfinedAttr<I64Attr, [IntMinValue<1>]>:$num_buckets 17442 ); 17443 17444 let results = (outs 17445 Res<TF_Int64Tensor, [{A Tensor of the same shape as the input `string_tensor`.}]>:$output 17446 ); 17447} 17448 17449def TF_SubOp : TF_Op<"Sub", [NoSideEffect, ResultsBroadcastableShape, TF_CwiseBinary, TF_SameOperandsAndResultElementTypeResolveRef]>, 17450 WithBroadcastableBinOpBuilder { 17451 let summary = "Returns x - y element-wise."; 17452 17453 let description = [{ 17454*NOTE*: `Subtract` supports broadcasting. More about broadcasting 17455[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 17456 }]; 17457 17458 let arguments = (ins 17459 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$x, 17460 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$y 17461 ); 17462 17463 let results = (outs 17464 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$z 17465 ); 17466 17467 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17468 17469 let hasCanonicalizer = 1; 17470 17471 let hasFolder = 1; 17472} 17473 17474def TF_SumOp : TF_Op<"Sum", [NoSideEffect]> { 17475 let summary = "Computes the sum of elements across dimensions of a tensor."; 17476 17477 let description = [{ 17478Reduces `input` along the dimensions given in `axis`. Unless 17479`keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in 17480`axis`. If `keep_dims` is true, the reduced dimensions are 17481retained with length 1. 17482 }]; 17483 17484 let arguments = (ins 17485 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The tensor to reduce.}]>:$input, 17486 Arg<TF_I32OrI64Tensor, [{The dimensions to reduce. Must be in the range 17487`[-rank(input), rank(input))`.}]>:$reduction_indices, 17488 17489 DefaultValuedAttr<BoolAttr, "false">:$keep_dims 17490 ); 17491 17492 let results = (outs 17493 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The reduced tensor.}]>:$output 17494 ); 17495 17496 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17497 TF_DerivedOperandTypeAttr Tidx = TF_DerivedOperandTypeAttr<1>; 17498 17499 let builders = [ 17500 OpBuilder<(ins "Value":$input, "Value":$reduction_indices, 17501 "BoolAttr":$keep_dims)> 17502 ]; 17503 17504 let hasFolder = 1; 17505} 17506 17507def TF_SvdOp : TF_Op<"Svd", [NoSideEffect]> { 17508 let summary = [{ 17509Computes the singular value decompositions of one or more matrices. 17510 }]; 17511 17512 let description = [{ 17513Computes the SVD of each inner matrix in `input` such that 17514`input[..., :, :] = u[..., :, :] * diag(s[..., :, :]) * transpose(v[..., :, :])` 17515 17516```python 17517# a is a tensor containing a batch of matrices. 17518# s is a tensor of singular values for each matrix. 17519# u is the tensor containing the left singular vectors for each matrix. 17520# v is the tensor containing the right singular vectors for each matrix. 17521s, u, v = svd(a) 17522s, _, _ = svd(a, compute_uv=False) 17523``` 17524 }]; 17525 17526 let arguments = (ins 17527 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{A tensor of shape `[..., M, N]` whose inner-most 2 dimensions 17528form matrices of size `[M, N]`. Let `P` be the minimum of `M` and `N`.}]>:$input, 17529 17530 DefaultValuedAttr<BoolAttr, "true">:$compute_uv, 17531 DefaultValuedAttr<BoolAttr, "false">:$full_matrices 17532 ); 17533 17534 let results = (outs 17535 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Singular values. Shape is `[..., P]`.}]>:$s, 17536 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Left singular vectors. If `full_matrices` is `False` then shape is 17537`[..., M, P]`; if `full_matrices` is `True` then shape is 17538`[..., M, M]`. Undefined if `compute_uv` is `False`.}]>:$u, 17539 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>, [{Left singular vectors. If `full_matrices` is `False` then shape is 17540`[..., N, P]`. If `full_matrices` is `True` then shape is `[..., N, N]`. 17541Undefined if `compute_uv` is false.}]>:$v 17542 ); 17543 17544 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17545} 17546 17547def TF_SymbolicGradientOp : TF_Op<"SymbolicGradient", [NoSideEffect]> { 17548 let summary = [{ 17549Computes the gradient function for function f via backpropagation. 17550 }]; 17551 17552 let arguments = (ins 17553 Arg<Variadic<TF_Tensor>, [{a list of input tensors of size N + M;}]>:$input, 17554 17555 SymbolRefAttr:$f 17556 ); 17557 17558 let results = (outs 17559 Res<Variadic<TF_Tensor>, [{a list of output tensors of size N;}]>:$output 17560 ); 17561 17562 TF_DerivedOperandTypeListAttr Tin = TF_DerivedOperandTypeListAttr<0>; 17563 TF_DerivedResultTypeListAttr Tout = TF_DerivedResultTypeListAttr<0>; 17564} 17565 17566def TF_TPUCompilationResultOp : TF_Op<"TPUCompilationResult", [TF_MustExecute]> { 17567 let summary = "Returns the result of a TPU compilation."; 17568 17569 let description = [{ 17570This operation returns the result of a TPU compilation as a serialized 17571CompilationResultProto, which holds a status and an error message if an error 17572occurred during compilation. 17573 }]; 17574 17575 let arguments = (ins); 17576 17577 let results = (outs 17578 TF_StrTensor:$output 17579 ); 17580} 17581 17582def TF_TPUCompileSucceededAssertOp : TF_Op<"TPUCompileSucceededAssert", [TF_MustExecute]> { 17583 let summary = "Asserts that compilation succeeded."; 17584 17585 let description = [{ 17586This op produces no output and closes the device during failure to ensure all 17587pending device interactions fail. 17588 17589'compilation_status' is a serialized CompilationResultProto. 17590 }]; 17591 17592 let arguments = (ins 17593 TF_StrTensor:$compilation_status 17594 ); 17595 17596 let results = (outs); 17597} 17598 17599def TF_TPUCopyWithLayoutOp : TF_Op<"TPUCopyWithLayout", [NoSideEffect]> { 17600 let summary = "Op that copies host tensor to device with specified layout."; 17601 17602 let description = [{ 17603For internal use only. 17604 }]; 17605 17606 let arguments = (ins 17607 TF_Tensor:$input, 17608 TF_Int64Tensor:$layout 17609 ); 17610 17611 let results = (outs 17612 TF_Tensor:$output 17613 ); 17614 17615 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17616} 17617 17618def TF_TPUEmbeddingActivationsOp : TF_Op<"TPUEmbeddingActivations", [NoSideEffect]> { 17619 let summary = "An op enabling differentiation of TPU Embeddings."; 17620 17621 let description = [{ 17622This op simply returns its first input, which is assumed to have been sliced 17623from the Tensors returned by TPUEmbeddingDequeueActivations. The presence of 17624this op, and its first argument being a trainable Variable, enables automatic 17625differentiation of graphs containing embeddings via the TPU Embedding Python 17626libraries. 17627 }]; 17628 17629 let arguments = (ins 17630 Arg<TF_Float32Tensor, [{A trainable variable, enabling optimizers to find this op.}]>:$embedding_variable, 17631 Arg<TF_Float32Tensor, [{The embedding activations Tensor to return.}]>:$sliced_activations, 17632 17633 ConfinedAttr<I64Attr, [IntMinValue<0>]>:$table_id, 17634 ConfinedAttr<I64Attr, [IntMinValue<0>]>:$lookup_id 17635 ); 17636 17637 let results = (outs 17638 TF_Float32Tensor:$output 17639 ); 17640} 17641 17642def TF_TPUExecuteOp : TF_Op<"TPUExecute", [DeclareOpInterfaceMethods<MemoryEffectsOpInterface>]> { 17643 let summary = "Op that loads and executes a TPU program on a TPU device."; 17644 17645 let description = [{ 17646For the internal use of the distributed TPU compiler. 17647 }]; 17648 17649 let arguments = (ins 17650 Variadic<TF_Tensor>:$args, 17651 TF_StrTensor:$key 17652 ); 17653 17654 let results = (outs 17655 Variadic<TF_Tensor>:$results 17656 ); 17657 17658 TF_DerivedOperandTypeListAttr Targs = TF_DerivedOperandTypeListAttr<0>; 17659 TF_DerivedResultTypeListAttr Tresults = TF_DerivedResultTypeListAttr<0>; 17660} 17661 17662def TF_TPUExecuteAndUpdateVariablesOp : TF_Op<"TPUExecuteAndUpdateVariables", [DeclareOpInterfaceMethods<MemoryEffectsOpInterface>]> { 17663 let summary = [{ 17664Op that executes a program with optional in-place variable updates. 17665 }]; 17666 17667 let description = [{ 17668It (optionally) reads device variables, loads and executes a TPU program on a 17669TPU device, and then (optionally) in-place updates variables using the program 17670outputs, as specified in attributes device_var_reads_indices (program input 17671indices from directly reading variables) and device_var_updates_indices (program 17672output indices used to update variables, -1 means no-update/read-only). Such 17673program outputs are consumed by these variables will not appear in the op 17674output. For the internal use of the distributed TPU compiler. 17675 }]; 17676 17677 let arguments = (ins 17678 Variadic<TF_Tensor>:$args, 17679 TF_StrTensor:$key, 17680 17681 I64ArrayAttr:$device_var_reads_indices, 17682 I64ArrayAttr:$device_var_updates_indices 17683 ); 17684 17685 let results = (outs 17686 Variadic<TF_Tensor>:$results 17687 ); 17688 17689 TF_DerivedOperandTypeListAttr Targs = TF_DerivedOperandTypeListAttr<0>; 17690 TF_DerivedResultTypeListAttr Tresults = TF_DerivedResultTypeListAttr<0>; 17691 17692 let hasVerifier = 1; 17693} 17694 17695def TF_TPUGetLayoutOp : TF_Op<"TPUGetLayoutOp", [NoSideEffect]> { 17696 let summary = [{ 17697Op that retrieves the layout of an input or output determined by TPUCompile. 17698 }]; 17699 17700 let description = [{ 17701For internal use only. 17702 }]; 17703 17704 let arguments = (ins 17705 TF_StrTensor:$cache_key, 17706 17707 I64Attr:$index, 17708 BoolAttr:$is_output 17709 ); 17710 17711 let results = (outs 17712 TF_Int64Tensor:$layout 17713 ); 17714} 17715 17716def TF_TPUOrdinalSelectorOp : TF_Op<"TPUOrdinalSelector", []> { 17717 let summary = "A TPU core selector Op."; 17718 17719 let description = [{ 17720This Op produces a set of TPU cores (for warm-up) or a single TPU core 17721(for regular inference) to execute the TPU program on. The output is 17722consumed by TPUPartitionedCall. 17723 }]; 17724 17725 let arguments = (ins); 17726 17727 let results = (outs 17728 Res<TF_Int32Tensor, [{A vector 1 or more TPU cores.}]>:$device_ordinals 17729 ); 17730} 17731 17732def TF_TPUReplicateMetadataOp : TF_Op<"TPUReplicateMetadata", []> { 17733 let summary = [{ 17734Metadata indicating how the TPU computation should be replicated. 17735 }]; 17736 17737 let description = [{ 17738This operation holds the metadata common to operations of a `tpu.replicate()` computation subgraph. 17739 }]; 17740 17741 let arguments = (ins 17742 ConfinedAttr<I64Attr, [IntMinValue<0>]>:$num_replicas, 17743 DefaultValuedAttr<I64Attr, "1">:$num_cores_per_replica, 17744 DefaultValuedAttr<StrAttr, "\"\"">:$topology, 17745 DefaultValuedAttr<BoolAttr, "true">:$use_tpu, 17746 DefaultValuedAttr<I64ArrayAttr, "{}">:$device_assignment, 17747 DefaultValuedAttr<I64ArrayAttr, "{}">:$computation_shape, 17748 DefaultValuedAttr<StrArrayAttr, "{}">:$host_compute_core, 17749 DefaultValuedAttr<StrArrayAttr, "{}">:$padding_map, 17750 DefaultValuedAttr<StrAttr, "\"STEP_MARK_AT_ENTRY\"">:$step_marker_location, 17751 DefaultValuedAttr<BoolAttr, "false">:$allow_soft_placement, 17752 DefaultValuedAttr<BoolAttr, "false">:$use_spmd_for_xla_partitioning, 17753 DefaultValuedAttr<StrAttr, "\"\"">:$tpu_compile_options_proto 17754 ); 17755 17756 let results = (outs); 17757} 17758 17759def TF_TPUReplicatedInputOp : TF_Op<"TPUReplicatedInput", [NoSideEffect]> { 17760 let summary = "Connects N inputs to an N-way replicated TPU computation."; 17761 17762 let description = [{ 17763This operation holds a replicated input to a `tpu.replicate()` computation subgraph. 17764Each replicated input has the same shape and type alongside the output. 17765 17766For example: 17767``` 17768%a = "tf.opA"() 17769%b = "tf.opB"() 17770%replicated_input = "tf.TPUReplicatedInput"(%a, %b) 17771%computation = "tf.Computation"(%replicated_input) 17772``` 17773The above computation has a replicated input of two replicas. 17774 }]; 17775 17776 let arguments = (ins 17777 Variadic<TF_Tensor>:$inputs, 17778 17779 DefaultValuedAttr<BoolAttr, "false">:$is_mirrored_variable, 17780 DefaultValuedAttr<I64Attr, "-1">:$index, 17781 DefaultValuedAttr<BoolAttr, "false">:$is_packed 17782 ); 17783 17784 let results = (outs 17785 TF_Tensor:$output 17786 ); 17787 17788 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 17789 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17790} 17791 17792def TF_TPUReplicatedOutputOp : TF_Op<"TPUReplicatedOutput", [NoSideEffect]> { 17793 let summary = "Connects N outputs from an N-way replicated TPU computation."; 17794 17795 let description = [{ 17796This operation holds a replicated output from a `tpu.replicate()` computation subgraph. 17797Each replicated output has the same shape and type alongside the input. 17798 17799For example: 17800``` 17801%computation = "tf.Computation"() 17802%replicated_output:2 = "tf.TPUReplicatedOutput"(%computation) 17803``` 17804The above computation has a replicated output of two replicas. 17805 }]; 17806 17807 let arguments = (ins 17808 TF_Tensor:$input 17809 ); 17810 17811 let results = (outs 17812 Variadic<TF_Tensor>:$outputs 17813 ); 17814 17815 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17816 TF_DerivedResultSizeAttr num_replicas = TF_DerivedResultSizeAttr<0>; 17817} 17818 17819def TF_TPUReshardVariablesOp : TF_Op<"TPUReshardVariables", []> { 17820 let summary = "Op that reshards on-device TPU variables to specified state."; 17821 17822 let description = [{ 17823Op that reshards on-device TPU variables to specified state. Internal use only. 17824 17825The sharding state is represented as the key of the compilation that generated 17826the sharding/unsharding programs along with the main program. new_format_key 17827specifies the desired state, and format_state_var is the current state of the 17828variables. 17829 }]; 17830 17831 let arguments = (ins 17832 Arg<Variadic<TF_ResourceTensor>, "", [TF_VariableRead, TF_VariableWrite]>:$vars, 17833 TF_StrTensor:$new_format_key, 17834 Arg<TF_ResourceTensor, "", [TF_VariableRead, TF_VariableWrite]>:$format_state_var 17835 ); 17836 17837 let results = (outs); 17838 17839 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 17840} 17841 17842def TF_TPURoundRobinOp : TF_Op<"TPURoundRobin", []> { 17843 let summary = "Round-robin load balancing on TPU cores."; 17844 17845 let description = [{ 17846A load balancing op that round-robins among TPU cores. 17847 17848This op round-robins between the integers in [0, NumTPUCoresVisiblePerHost]. It 17849is useful for interfacing with TensorFlow ops that take as input a TPU core on 17850which to execute computations, such as `TPUPartitionedCall`. 17851 17852device_ordinal: An integer in [0, NumTPUCoresVisiblePerHost]. 17853 }]; 17854 17855 let arguments = (ins); 17856 17857 let results = (outs 17858 TF_Int32Tensor:$device_ordinal 17859 ); 17860} 17861 17862def TF_TakeDatasetOp : TF_Op<"TakeDataset", [NoSideEffect]> { 17863 let summary = [{ 17864Creates a dataset that contains `count` elements from the `input_dataset`. 17865 }]; 17866 17867 let arguments = (ins 17868 TF_VariantTensor:$input_dataset, 17869 Arg<TF_Int64Tensor, [{A scalar representing the number of elements from the `input_dataset` 17870that should be taken. A value of `-1` indicates that all of `input_dataset` 17871is taken.}]>:$count, 17872 17873 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 17874 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 17875 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 17876 ); 17877 17878 let results = (outs 17879 TF_VariantTensor:$handle 17880 ); 17881} 17882 17883def TF_TakeWhileDatasetOp : TF_Op<"TakeWhileDataset", [NoSideEffect]> { 17884 let summary = [{ 17885Creates a dataset that stops iteration when predicate` is false. 17886 }]; 17887 17888 let description = [{ 17889The `predicate` function must return a scalar boolean and accept the 17890following arguments: 17891 17892* One tensor for each component of an element of `input_dataset`. 17893* One tensor for each value in `other_arguments`. 17894 }]; 17895 17896 let arguments = (ins 17897 TF_VariantTensor:$input_dataset, 17898 Arg<Variadic<TF_Tensor>, [{A list of tensors, typically values that were captured when 17899building a closure for `predicate`.}]>:$other_arguments, 17900 17901 SymbolRefAttr:$predicate, 17902 ConfinedAttr<TypeArrayAttr, [ArrayMinCount<1>]>:$output_types, 17903 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 17904 DefaultValuedAttr<StrAttr, "\"\"">:$metadata 17905 ); 17906 17907 let results = (outs 17908 TF_VariantTensor:$handle 17909 ); 17910 17911 TF_DerivedOperandTypeListAttr Targuments = TF_DerivedOperandTypeListAttr<1>; 17912} 17913 17914def TF_TanOp : TF_Op<"Tan", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 17915 let summary = "Computes tan of x element-wise."; 17916 17917 let description = [{ 17918Given an input tensor, this function computes tangent of every 17919 element in the tensor. Input range is `(-inf, inf)` and 17920 output range is `(-inf, inf)`. If input lies outside the boundary, `nan` 17921 is returned. 17922 17923 ```python 17924 x = tf.constant([-float("inf"), -9, -0.5, 1, 1.2, 200, 10000, float("inf")]) 17925 tf.math.tan(x) ==> [nan 0.45231566 -0.5463025 1.5574077 2.572152 -1.7925274 0.32097113 nan] 17926 ``` 17927 }]; 17928 17929 let arguments = (ins 17930 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$x 17931 ); 17932 17933 let results = (outs 17934 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8]>:$y 17935 ); 17936 17937 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17938} 17939 17940def TF_TanhOp : TF_Op<"Tanh", [NoSideEffect, TF_LayoutAgnostic, TF_SameOperandsAndResultTypeResolveRef]> { 17941 let summary = "Computes hyperbolic tangent of `x` element-wise."; 17942 17943 let description = [{ 17944Given an input tensor, this function computes hyperbolic tangent of every 17945 element in the tensor. Input range is `[-inf, inf]` and 17946 output range is `[-1,1]`. 17947 17948 >>> x = tf.constant([-float("inf"), -5, -0.5, 1, 1.2, 2, 3, float("inf")]) 17949 >>> tf.math.tanh(x) 17950 <tf.Tensor: shape=(8,), dtype=float32, numpy= 17951 array([-1.0, -0.99990916, -0.46211717, 0.7615942 , 0.8336547 , 17952 0.9640276 , 0.9950547 , 1.0], dtype=float32)> 17953 }]; 17954 17955 let arguments = (ins 17956 TF_FpOrComplexTensor:$x 17957 ); 17958 17959 let results = (outs 17960 TF_FpOrComplexTensor:$y 17961 ); 17962 17963 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17964} 17965 17966def TF_TanhGradOp : TF_Op<"TanhGrad", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 17967 let summary = "Computes the gradient for the tanh of `x` wrt its input."; 17968 17969 let description = [{ 17970Specifically, `grad = dy * (1 - y*y)`, where `y = tanh(x)`, and `dy` 17971is the corresponding input gradient. 17972 }]; 17973 17974 let arguments = (ins 17975 TF_FpOrComplexTensor:$y, 17976 TF_FpOrComplexTensor:$dy 17977 ); 17978 17979 let results = (outs 17980 TF_FpOrComplexTensor:$z 17981 ); 17982 17983 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 17984} 17985 17986def TF_TensorArrayCloseV3Op : TF_Op<"TensorArrayCloseV3", []> { 17987 let summary = "Delete the TensorArray from its resource container."; 17988 17989 let description = [{ 17990This enables the user to close and release the resource in the middle 17991of a step/run. 17992 }]; 17993 17994 let arguments = (ins 17995 Arg<TF_ResourceTensor, [{The handle to a TensorArray (output of TensorArray or TensorArrayGrad).}], [TF_TensorArrayFree]>:$handle 17996 ); 17997 17998 let results = (outs); 17999} 18000 18001def TF_TensorArrayConcatV3Op : TF_Op<"TensorArrayConcatV3", []> { 18002 let summary = "Concat the elements from the TensorArray into value `value`."; 18003 18004 let description = [{ 18005Takes `T` elements of shapes 18006 18007 ``` 18008 (n0 x d0 x d1 x ...), (n1 x d0 x d1 x ...), ..., (n(T-1) x d0 x d1 x ...) 18009 ``` 18010 18011and concatenates them into a Tensor of shape: 18012 18013 ```(n0 + n1 + ... + n(T-1) x d0 x d1 x ...)``` 18014 18015All elements must have the same shape (excepting the first dimension). 18016 }]; 18017 18018 let arguments = (ins 18019 Arg<TF_ResourceTensor, [{The handle to a TensorArray.}], [TF_TensorArrayRead]>:$handle, 18020 Arg<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_in, 18021 18022 DefaultValuedAttr<TF_ShapeAttr, "llvm::None">:$element_shape_except0 18023 ); 18024 18025 let results = (outs 18026 Res<TF_Tensor, [{All of the elements in the TensorArray, concatenated along the first 18027axis.}]>:$value, 18028 Res<TF_Int64Tensor, [{A vector of the row sizes of the original T elements in the 18029value output. In the example above, this would be the values: 18030`(n1, n2, ..., n(T-1))`.}]>:$lengths 18031 ); 18032 18033 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 18034} 18035 18036def TF_TensorArrayGatherV3Op : TF_Op<"TensorArrayGatherV3", []> { 18037 let summary = [{ 18038Gather specific elements from the TensorArray into output `value`. 18039 }]; 18040 18041 let description = [{ 18042All elements selected by `indices` must have the same shape. 18043 }]; 18044 18045 let arguments = (ins 18046 Arg<TF_ResourceTensor, [{The handle to a TensorArray.}], [TF_TensorArrayRead]>:$handle, 18047 Arg<TF_Int32Tensor, [{The locations in the TensorArray from which to read tensor elements.}]>:$indices, 18048 Arg<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_in, 18049 18050 DefaultValuedAttr<TF_ShapeAttr, "llvm::None">:$element_shape 18051 ); 18052 18053 let results = (outs 18054 Res<TF_Tensor, [{All of the elements in the TensorArray, concatenated along a new 18055axis (the new dimension 0).}]>:$value 18056 ); 18057 18058 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 18059} 18060 18061def TF_TensorArrayGradV3Op : TF_Op<"TensorArrayGradV3", []> { 18062 let summary = [{ 18063Creates a TensorArray for storing the gradients of values in the given handle. 18064 }]; 18065 18066 let description = [{ 18067If the given TensorArray gradient already exists, returns a reference to it. 18068 18069Locks the size of the original TensorArray by disabling its dynamic size flag. 18070 18071**A note about the input flow_in:** 18072 18073The handle flow_in forces the execution of the gradient lookup to occur 18074only after certain other operations have occurred. For example, when 18075the forward TensorArray is dynamically sized, writes to this TensorArray 18076may resize the object. The gradient TensorArray is statically sized based 18077on the size of the forward TensorArray when this operation executes. 18078Furthermore, the size of the forward TensorArray is frozen by this call. 18079As a result, the flow is used to ensure that the call to generate the gradient 18080TensorArray only happens after all writes are executed. 18081 18082In the case of dynamically sized TensorArrays, gradient computation should 18083only be performed on read operations that have themselves been chained via 18084flow to occur only after all writes have executed. That way the final size 18085of the forward TensorArray is known when this operation is called. 18086 18087**A note about the source attribute:** 18088 18089TensorArray gradient calls use an accumulator TensorArray object. If 18090multiple gradients are calculated and run in the same session, the multiple 18091gradient nodes may accidentally flow through the same accumulator TensorArray. 18092This double counts and generally breaks the TensorArray gradient flow. 18093 18094The solution is to identify which gradient call this particular 18095TensorArray gradient is being called in. This is performed by identifying 18096a unique string (e.g. "gradients", "gradients_1", ...) from the input 18097gradient Tensor's name. This string is used as a suffix when creating 18098the TensorArray gradient object here (the attribute `source`). 18099 18100The attribute `source` is added as a suffix to the forward TensorArray's 18101name when performing the creation / lookup, so that each separate gradient 18102calculation gets its own TensorArray accumulator. 18103 }]; 18104 18105 let arguments = (ins 18106 Arg<TF_ResourceTensor, [{The handle to the forward TensorArray.}], [TF_TensorArrayRead, TF_TensorArrayWrite]>:$handle, 18107 Arg<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_in, 18108 18109 StrAttr:$source 18110 ); 18111 18112 let results = (outs 18113 Res<TF_ResourceTensor, "", [TF_TensorArrayAlloc]>:$grad_handle, 18114 TF_Float32Tensor:$flow_out 18115 ); 18116} 18117 18118def TF_TensorArrayReadV3Op : TF_Op<"TensorArrayReadV3", []> { 18119 let summary = "Read an element from the TensorArray into output `value`."; 18120 18121 let arguments = (ins 18122 Arg<TF_ResourceTensor, [{The handle to a TensorArray.}], [TF_TensorArrayRead]>:$handle, 18123 TF_Int32Tensor:$index, 18124 Arg<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_in 18125 ); 18126 18127 let results = (outs 18128 Res<TF_Tensor, [{The tensor that is read from the TensorArray.}]>:$value 18129 ); 18130 18131 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 18132} 18133 18134def TF_TensorArrayScatterV3Op : TF_Op<"TensorArrayScatterV3", []> { 18135 let summary = [{ 18136Scatter the data from the input value into specific TensorArray elements. 18137 }]; 18138 18139 let description = [{ 18140`indices` must be a vector, its length must match the first dim of `value`. 18141 }]; 18142 18143 let arguments = (ins 18144 Arg<TF_ResourceTensor, [{The handle to a TensorArray.}], [TF_TensorArrayRead, TF_TensorArrayWrite]>:$handle, 18145 Arg<TF_Int32Tensor, [{The locations at which to write the tensor elements.}]>:$indices, 18146 Arg<TF_Tensor, [{The concatenated tensor to write to the TensorArray.}]>:$value, 18147 Arg<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_in 18148 ); 18149 18150 let results = (outs 18151 Res<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_out 18152 ); 18153 18154 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 18155} 18156 18157def TF_TensorArraySizeV3Op : TF_Op<"TensorArraySizeV3", []> { 18158 let summary = "Get the current size of the TensorArray."; 18159 18160 let arguments = (ins 18161 Arg<TF_ResourceTensor, [{The handle to a TensorArray (output of TensorArray or TensorArrayGrad).}], [TF_TensorArrayRead]>:$handle, 18162 Arg<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_in 18163 ); 18164 18165 let results = (outs 18166 Res<TF_Int32Tensor, [{The current size of the TensorArray.}]>:$size 18167 ); 18168} 18169 18170def TF_TensorArraySplitV3Op : TF_Op<"TensorArraySplitV3", []> { 18171 let summary = [{ 18172Split the data from the input value into TensorArray elements. 18173 }]; 18174 18175 let description = [{ 18176Assuming that `lengths` takes on values 18177 18178 ```(n0, n1, ..., n(T-1))``` 18179 18180and that `value` has shape 18181 18182 ```(n0 + n1 + ... + n(T-1) x d0 x d1 x ...)```, 18183 18184this splits values into a TensorArray with T tensors. 18185 18186TensorArray index t will be the subtensor of values with starting position 18187 18188 ```(n0 + n1 + ... + n(t-1), 0, 0, ...)``` 18189 18190and having size 18191 18192 ```nt x d0 x d1 x ...``` 18193 }]; 18194 18195 let arguments = (ins 18196 Arg<TF_ResourceTensor, [{The handle to a TensorArray.}], [TF_TensorArrayRead, TF_TensorArrayWrite]>:$handle, 18197 Arg<TF_Tensor, [{The concatenated tensor to write to the TensorArray.}]>:$value, 18198 Arg<TF_Int64Tensor, [{The vector of lengths, how to split the rows of value into the 18199TensorArray.}]>:$lengths, 18200 Arg<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_in 18201 ); 18202 18203 let results = (outs 18204 Res<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_out 18205 ); 18206 18207 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<1>; 18208} 18209 18210def TF_TensorArrayV3Op : TF_Op<"TensorArrayV3", []> { 18211 let summary = "An array of Tensors of given size."; 18212 18213 let description = [{ 18214Write data via Write and read via Read or Pack. 18215 }]; 18216 18217 let arguments = (ins 18218 Arg<TF_Int32Tensor, [{The size of the array.}]>:$size, 18219 18220 TypeAttr:$dtype, 18221 DefaultValuedAttr<TF_ShapeAttr, "llvm::None">:$element_shape, 18222 DefaultValuedAttr<BoolAttr, "false">:$dynamic_size, 18223 DefaultValuedAttr<BoolAttr, "true">:$clear_after_read, 18224 DefaultValuedAttr<BoolAttr, "false">:$identical_element_shapes, 18225 DefaultValuedAttr<StrAttr, "\"\"">:$tensor_array_name 18226 ); 18227 18228 let results = (outs 18229 Res<TF_ResourceTensor, [{The handle to the TensorArray.}], [TF_TensorArrayAlloc]>:$handle, 18230 Res<TF_Float32Tensor, [{A scalar used to control gradient flow.}]>:$flow 18231 ); 18232} 18233 18234def TF_TensorArrayWriteV3Op : TF_Op<"TensorArrayWriteV3", []> { 18235 let summary = "Push an element onto the tensor_array."; 18236 18237 let arguments = (ins 18238 Arg<TF_ResourceTensor, [{The handle to a TensorArray.}], [TF_TensorArrayRead, TF_TensorArrayWrite]>:$handle, 18239 Arg<TF_Int32Tensor, [{The position to write to inside the TensorArray.}]>:$index, 18240 Arg<TF_Tensor, [{The tensor to write to the TensorArray.}]>:$value, 18241 Arg<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_in 18242 ); 18243 18244 let results = (outs 18245 Res<TF_Float32Tensor, [{A float scalar that enforces proper chaining of operations.}]>:$flow_out 18246 ); 18247 18248 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<2>; 18249} 18250 18251def TF_TensorListConcatV2Op : TF_Op<"TensorListConcatV2", [NoSideEffect]> { 18252 let summary = "Concats all tensors in the list along the 0th dimension."; 18253 18254 let description = [{ 18255Requires that all tensors have the same shape except the first dimension. 18256 18257input_handle: The input list. 18258element_shape: The shape of the uninitialized elements in the list. If the first 18259 dimension is not -1, it is assumed that all list elements have the same 18260 leading dim. 18261leading_dims: The list of leading dims of uninitialized list elements. Used if 18262 the leading dim of input_handle.element_shape or the element_shape input arg 18263 is not already set. 18264tensor: The concated result. 18265lengths: Output tensor containing sizes of the 0th dimension of tensors in the list, used for computing the gradient. 18266 }]; 18267 18268 let arguments = (ins 18269 TF_VariantTensor:$input_handle, 18270 TF_I32OrI64Tensor:$element_shape, 18271 TF_Int64Tensor:$leading_dims 18272 ); 18273 18274 let results = (outs 18275 TF_Tensor:$tensor, 18276 TF_Int64Tensor:$lengths 18277 ); 18278 18279 TF_DerivedOperandTypeAttr shape_type = TF_DerivedOperandTypeAttr<1>; 18280 TF_DerivedResultTypeAttr element_dtype = TF_DerivedResultTypeAttr<0>; 18281} 18282 18283def TF_TensorListElementShapeOp : TF_Op<"TensorListElementShape", [NoSideEffect]> { 18284 let summary = "The shape of the elements of the given list, as a tensor."; 18285 18286 let description = [{ 18287input_handle: the list 18288 element_shape: the shape of elements of the list 18289 }]; 18290 18291 let arguments = (ins 18292 TF_VariantTensor:$input_handle 18293 ); 18294 18295 let results = (outs 18296 TF_I32OrI64Tensor:$element_shape 18297 ); 18298 18299 TF_DerivedResultTypeAttr shape_type = TF_DerivedResultTypeAttr<0>; 18300 18301 let hasFolder = 1; 18302} 18303 18304def TF_TensorListFromTensorOp : TF_Op<"TensorListFromTensor", [NoSideEffect]> { 18305 let summary = [{ 18306Creates a TensorList which, when stacked, has the value of `tensor`. 18307 }]; 18308 18309 let description = [{ 18310Each tensor in the result list corresponds to one row of the input tensor. 18311 18312tensor: The input tensor. 18313output_handle: The list. 18314 }]; 18315 18316 let arguments = (ins 18317 TF_Tensor:$tensor, 18318 TF_I32OrI64Tensor:$element_shape 18319 ); 18320 18321 let results = (outs 18322 TF_VariantTensor:$output_handle 18323 ); 18324 18325 TF_DerivedOperandTypeAttr element_dtype = TF_DerivedOperandTypeAttr<0>; 18326 TF_DerivedOperandTypeAttr shape_type = TF_DerivedOperandTypeAttr<1>; 18327} 18328 18329def TF_TensorListGatherOp : TF_Op<"TensorListGather", [NoSideEffect]> { 18330 let summary = "Creates a Tensor by indexing into the TensorList."; 18331 18332 let description = [{ 18333Each row in the produced Tensor corresponds to the element in the TensorList 18334specified by the given index (see `tf.gather`). 18335 18336input_handle: The input tensor list. 18337indices: The indices used to index into the list. 18338values: The tensor. 18339 }]; 18340 18341 let arguments = (ins 18342 TF_VariantTensor:$input_handle, 18343 TF_Int32Tensor:$indices, 18344 TF_Int32Tensor:$element_shape 18345 ); 18346 18347 let results = (outs 18348 TF_Tensor:$values 18349 ); 18350 18351 TF_DerivedResultTypeAttr element_dtype = TF_DerivedResultTypeAttr<0>; 18352} 18353 18354def TF_TensorListGetItemOp : TF_Op<"TensorListGetItem", [NoSideEffect]> { 18355 let summary = ""; 18356 18357 let arguments = (ins 18358 TF_VariantTensor:$input_handle, 18359 TF_Int32Tensor:$index, 18360 TF_Int32Tensor:$element_shape 18361 ); 18362 18363 let results = (outs 18364 TF_Tensor:$item 18365 ); 18366 18367 TF_DerivedResultTypeAttr element_dtype = TF_DerivedResultTypeAttr<0>; 18368 18369 let hasCanonicalizer = 1; 18370} 18371 18372def TF_TensorListLengthOp : TF_Op<"TensorListLength", [NoSideEffect]> { 18373 let summary = "Returns the number of tensors in the input tensor list."; 18374 18375 let description = [{ 18376input_handle: the input list 18377length: the number of tensors in the list 18378 }]; 18379 18380 let arguments = (ins 18381 TF_VariantTensor:$input_handle 18382 ); 18383 18384 let results = (outs 18385 TF_Int32Tensor:$length 18386 ); 18387} 18388 18389def TF_TensorListPopBackOp : TF_Op<"TensorListPopBack", [NoSideEffect]> { 18390 let summary = [{ 18391Returns the last element of the input list as well as a list with all but that element. 18392 }]; 18393 18394 let description = [{ 18395Fails if the list is empty. 18396 18397input_handle: the input list 18398tensor: the withdrawn last element of the list 18399element_dtype: the type of elements in the list 18400element_shape: the shape of the output tensor 18401 }]; 18402 18403 let arguments = (ins 18404 TF_VariantTensor:$input_handle, 18405 TF_Int32Tensor:$element_shape 18406 ); 18407 18408 let results = (outs 18409 TF_VariantTensor:$output_handle, 18410 TF_Tensor:$tensor 18411 ); 18412 18413 TF_DerivedResultTypeAttr element_dtype = TF_DerivedResultTypeAttr<1>; 18414} 18415 18416def TF_TensorListPushBackOp : TF_Op<"TensorListPushBack", [NoSideEffect]> { 18417 let summary = [{ 18418Returns a list which has the passed-in `Tensor` as last element and the other elements of the given list in `input_handle`. 18419 }]; 18420 18421 let description = [{ 18422tensor: The tensor to put on the list. 18423input_handle: The old list. 18424output_handle: A list with the elements of the old list followed by tensor. 18425element_dtype: the type of elements in the list. 18426element_shape: a shape compatible with that of elements in the list. 18427 }]; 18428 18429 let arguments = (ins 18430 TF_VariantTensor:$input_handle, 18431 TF_Tensor:$tensor 18432 ); 18433 18434 let results = (outs 18435 TF_VariantTensor:$output_handle 18436 ); 18437 18438 TF_DerivedOperandTypeAttr element_dtype = TF_DerivedOperandTypeAttr<1>; 18439} 18440 18441def TF_TensorListResizeOp : TF_Op<"TensorListResize", [NoSideEffect]> { 18442 let summary = "Resizes the list."; 18443 18444 let description = [{ 18445input_handle: the input list 18446size: size of the output list 18447 }]; 18448 18449 let arguments = (ins 18450 TF_VariantTensor:$input_handle, 18451 TF_Int32Tensor:$size 18452 ); 18453 18454 let results = (outs 18455 TF_VariantTensor:$output_handle 18456 ); 18457} 18458 18459def TF_TensorListScatterIntoExistingListOp : TF_Op<"TensorListScatterIntoExistingList", [NoSideEffect]> { 18460 let summary = "Scatters tensor at indices in an input list."; 18461 18462 let description = [{ 18463Each member of the TensorList corresponds to one row of the input tensor, 18464specified by the given index (see `tf.gather`). 18465 18466input_handle: The list to scatter into. 18467tensor: The input tensor. 18468indices: The indices used to index into the list. 18469output_handle: The TensorList. 18470 }]; 18471 18472 let arguments = (ins 18473 TF_VariantTensor:$input_handle, 18474 TF_Tensor:$tensor, 18475 TF_Int32Tensor:$indices 18476 ); 18477 18478 let results = (outs 18479 TF_VariantTensor:$output_handle 18480 ); 18481 18482 TF_DerivedOperandTypeAttr element_dtype = TF_DerivedOperandTypeAttr<1>; 18483} 18484 18485def TF_TensorListSetItemOp : TF_Op<"TensorListSetItem", [NoSideEffect]> { 18486 let summary = ""; 18487 18488 let arguments = (ins 18489 TF_VariantTensor:$input_handle, 18490 TF_Int32Tensor:$index, 18491 TF_Tensor:$item 18492 ); 18493 18494 let results = (outs 18495 TF_VariantTensor:$output_handle 18496 ); 18497 18498 TF_DerivedOperandTypeAttr element_dtype = TF_DerivedOperandTypeAttr<2>; 18499} 18500 18501def TF_TensorListStackOp : TF_Op<"TensorListStack", [NoSideEffect]> { 18502 let summary = "Stacks all tensors in the list."; 18503 18504 let description = [{ 18505Requires that all tensors have the same shape. 18506 18507input_handle: the input list 18508tensor: the gathered result 18509num_elements: optional. If not -1, the number of elements in the list. 18510 }]; 18511 18512 let arguments = (ins 18513 TF_VariantTensor:$input_handle, 18514 TF_Int32Tensor:$element_shape, 18515 18516 DefaultValuedAttr<I64Attr, "-1">:$num_elements 18517 ); 18518 18519 let results = (outs 18520 TF_Tensor:$tensor 18521 ); 18522 18523 TF_DerivedResultTypeAttr element_dtype = TF_DerivedResultTypeAttr<0>; 18524 18525 let hasVerifier = 1; 18526} 18527 18528def TF_TensorScatterAddOp : TF_Op<"TensorScatterAdd", [NoSideEffect]> { 18529 let summary = [{ 18530Adds sparse `updates` to an existing tensor according to `indices`. 18531 }]; 18532 18533 let description = [{ 18534This operation creates a new tensor by adding sparse `updates` to the passed 18535in `tensor`. 18536This operation is very similar to `tf.compat.v1.scatter_nd_add`, except that the 18537updates are added onto an existing tensor (as opposed to a variable). If the 18538memory for the existing tensor cannot be re-used, a copy is made and updated. 18539 18540`indices` is an integer tensor containing indices into a new tensor of shape 18541`tensor.shape`. The last dimension of `indices` can be at most the rank of 18542`tensor.shape`: 18543 18544``` 18545indices.shape[-1] <= tensor.shape.rank 18546``` 18547 18548The last dimension of `indices` corresponds to indices into elements 18549(if `indices.shape[-1] = tensor.shape.rank`) or slices 18550(if `indices.shape[-1] < tensor.shape.rank`) along dimension 18551`indices.shape[-1]` of `tensor.shape`. `updates` is a tensor with shape 18552 18553``` 18554indices.shape[:-1] + tensor.shape[indices.shape[-1]:] 18555``` 18556 18557The simplest form of `tensor_scatter_nd_add` is to add individual elements to a 18558tensor by index. For example, say we want to add 4 elements in a rank-1 18559tensor with 8 elements. 18560 18561In Python, this scatter add operation would look like this: 18562 18563>>> indices = tf.constant([[4], [3], [1], [7]]) 18564>>> updates = tf.constant([9, 10, 11, 12]) 18565>>> tensor = tf.ones([8], dtype=tf.int32) 18566>>> updated = tf.tensor_scatter_nd_add(tensor, indices, updates) 18567>>> updated 18568<tf.Tensor: shape=(8,), dtype=int32, 18569numpy=array([ 1, 12, 1, 11, 10, 1, 1, 13], dtype=int32)> 18570 18571We can also, insert entire slices of a higher rank tensor all at once. For 18572example, if we wanted to insert two slices in the first dimension of a 18573rank-3 tensor with two matrices of new values. 18574 18575In Python, this scatter add operation would look like this: 18576 18577>>> indices = tf.constant([[0], [2]]) 18578>>> updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6], 18579... [7, 7, 7, 7], [8, 8, 8, 8]], 18580... [[5, 5, 5, 5], [6, 6, 6, 6], 18581... [7, 7, 7, 7], [8, 8, 8, 8]]]) 18582>>> tensor = tf.ones([4, 4, 4],dtype=tf.int32) 18583>>> updated = tf.tensor_scatter_nd_add(tensor, indices, updates) 18584>>> updated 18585<tf.Tensor: shape=(4, 4, 4), dtype=int32, 18586numpy=array([[[6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8], [9, 9, 9, 9]], 18587 [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]], 18588 [[6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8], [9, 9, 9, 9]], 18589 [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]]], dtype=int32)> 18590 18591Note: on CPU, if an out of bound index is found, an error is returned. 18592On GPU, if an out of bound index is found, the index is ignored. 18593 }]; 18594 18595 let arguments = (ins 18596 Arg<TF_Tensor, [{Tensor to copy/update.}]>:$tensor, 18597 Arg<TF_I32OrI64Tensor, [{Index tensor.}]>:$indices, 18598 Arg<TF_Tensor, [{Updates to scatter into output.}]>:$updates 18599 ); 18600 18601 let results = (outs 18602 Res<TF_Tensor, [{A new tensor copied from tensor and updates added according to the indices.}]>:$output 18603 ); 18604 18605 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 18606 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 18607 18608 let builders = [ 18609 OpBuilder<(ins "Value":$tensor, "Value":$indices, "Value":$updates), 18610 [{build($_builder, $_state, tensor.getType(), tensor, indices, updates);}]> 18611 ]; 18612} 18613 18614def TF_TensorScatterMaxOp : TF_Op<"TensorScatterMax", [NoSideEffect]> { 18615 let summary = [{ 18616Apply a sparse update to a tensor taking the element-wise maximum. 18617 }]; 18618 18619 let description = [{ 18620Returns a new tensor copied from `tensor` whose values are element-wise maximum between 18621tensor and updates according to the indices. 18622 18623>>> tensor = [0, 0, 0, 0, 0, 0, 0, 0] 18624>>> indices = [[1], [4], [5]] 18625>>> updates = [1, -1, 1] 18626>>> tf.tensor_scatter_nd_max(tensor, indices, updates).numpy() 18627array([0, 1, 0, 0, 0, 1, 0, 0], dtype=int32) 18628 18629Refer to `tf.tensor_scatter_nd_update` for more details. 18630 }]; 18631 18632 let arguments = (ins 18633 Arg<TF_Tensor, [{Tensor to update.}]>:$tensor, 18634 Arg<TF_I32OrI64Tensor, [{Index tensor.}]>:$indices, 18635 Arg<TF_Tensor, [{Updates to scatter into output.}]>:$updates 18636 ); 18637 18638 let results = (outs 18639 Res<TF_Tensor, [{A new tensor copied from tensor whose values are element-wise maximum between tensor and updates according to the indices.}]>:$output 18640 ); 18641 18642 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 18643 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 18644} 18645 18646def TF_TensorScatterMinOp : TF_Op<"TensorScatterMin", [NoSideEffect]> { 18647 let summary = ""; 18648 18649 let arguments = (ins 18650 Arg<TF_Tensor, [{Tensor to update.}]>:$tensor, 18651 Arg<TF_I32OrI64Tensor, [{Index tensor.}]>:$indices, 18652 Arg<TF_Tensor, [{Updates to scatter into output.}]>:$updates 18653 ); 18654 18655 let results = (outs 18656 Res<TF_Tensor, [{A new tensor copied from tensor whose values are element-wise minimum between tensor and updates according to the indices.}]>:$output 18657 ); 18658 18659 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 18660 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 18661} 18662 18663def TF_TensorScatterSubOp : TF_Op<"TensorScatterSub", [NoSideEffect]> { 18664 let summary = [{ 18665Subtracts sparse `updates` from an existing tensor according to `indices`. 18666 }]; 18667 18668 let description = [{ 18669This operation creates a new tensor by subtracting sparse `updates` from the 18670passed in `tensor`. 18671This operation is very similar to `tf.scatter_nd_sub`, except that the updates 18672are subtracted from an existing tensor (as opposed to a variable). If the memory 18673for the existing tensor cannot be re-used, a copy is made and updated. 18674 18675`indices` is an integer tensor containing indices into a new tensor of shape 18676`shape`. The last dimension of `indices` can be at most the rank of `shape`: 18677 18678 indices.shape[-1] <= shape.rank 18679 18680The last dimension of `indices` corresponds to indices into elements 18681(if `indices.shape[-1] = shape.rank`) or slices 18682(if `indices.shape[-1] < shape.rank`) along dimension `indices.shape[-1]` of 18683`shape`. `updates` is a tensor with shape 18684 18685 indices.shape[:-1] + shape[indices.shape[-1]:] 18686 18687The simplest form of tensor_scatter_sub is to subtract individual elements 18688from a tensor by index. For example, say we want to insert 4 scattered elements 18689in a rank-1 tensor with 8 elements. 18690 18691In Python, this scatter subtract operation would look like this: 18692 18693```python 18694 indices = tf.constant([[4], [3], [1], [7]]) 18695 updates = tf.constant([9, 10, 11, 12]) 18696 tensor = tf.ones([8], dtype=tf.int32) 18697 updated = tf.tensor_scatter_nd_sub(tensor, indices, updates) 18698 print(updated) 18699``` 18700 18701The resulting tensor would look like this: 18702 18703 [1, -10, 1, -9, -8, 1, 1, -11] 18704 18705We can also, insert entire slices of a higher rank tensor all at once. For 18706example, if we wanted to insert two slices in the first dimension of a 18707rank-3 tensor with two matrices of new values. 18708 18709In Python, this scatter add operation would look like this: 18710 18711```python 18712 indices = tf.constant([[0], [2]]) 18713 updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6], 18714 [7, 7, 7, 7], [8, 8, 8, 8]], 18715 [[5, 5, 5, 5], [6, 6, 6, 6], 18716 [7, 7, 7, 7], [8, 8, 8, 8]]]) 18717 tensor = tf.ones([4, 4, 4],dtype=tf.int32) 18718 updated = tf.tensor_scatter_nd_sub(tensor, indices, updates) 18719 print(updated) 18720``` 18721 18722The resulting tensor would look like this: 18723 18724 [[[-4, -4, -4, -4], [-5, -5, -5, -5], [-6, -6, -6, -6], [-7, -7, -7, -7]], 18725 [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]], 18726 [[-4, -4, -4, -4], [-5, -5, -5, -5], [-6, -6, -6, -6], [-7, -7, -7, -7]], 18727 [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]]] 18728 18729Note that on CPU, if an out of bound index is found, an error is returned. 18730On GPU, if an out of bound index is found, the index is ignored. 18731 }]; 18732 18733 let arguments = (ins 18734 Arg<TF_Tensor, [{Tensor to copy/update.}]>:$tensor, 18735 Arg<TF_I32OrI64Tensor, [{Index tensor.}]>:$indices, 18736 Arg<TF_Tensor, [{Updates to scatter into output.}]>:$updates 18737 ); 18738 18739 let results = (outs 18740 Res<TF_Tensor, [{A new tensor copied from tensor and updates subtracted according to the indices.}]>:$output 18741 ); 18742 18743 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 18744 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 18745} 18746 18747def TF_TensorScatterUpdateOp : TF_Op<"TensorScatterUpdate", [NoSideEffect]> { 18748 let summary = [{ 18749Scatter `updates` into an existing tensor according to `indices`. 18750 }]; 18751 18752 let description = [{ 18753This operation creates a new tensor by applying sparse `updates` to the passed 18754in `tensor`. 18755This operation is very similar to `tf.scatter_nd`, except that the updates are 18756scattered onto an existing tensor (as opposed to a zero-tensor). If the memory 18757for the existing tensor cannot be re-used, a copy is made and updated. 18758 18759If `indices` contains duplicates, then we pick the last update for the index. 18760 18761If an out of bound index is found on CPU, an error is returned. 18762 18763**WARNING**: There are some GPU specific semantics for this operation. 18764- If an out of bound index is found, the index is ignored. 18765- The order in which updates are applied is nondeterministic, so the output 18766will be nondeterministic if `indices` contains duplicates. 18767 18768`indices` is an integer tensor containing indices into a new tensor of shape 18769`shape`. 18770 18771* `indices` must have at least 2 axes: `(num_updates, index_depth)`. 18772* The last axis of `indices` is how deep to index into `tensor` so this index 18773 depth must be less than the rank of `tensor`: `indices.shape[-1] <= tensor.ndim` 18774 18775if `indices.shape[-1] = tensor.rank` this Op indexes and updates scalar elements. 18776if `indices.shape[-1] < tensor.rank` it indexes and updates slices of the input 18777`tensor`. 18778 18779Each `update` has a rank of `tensor.rank - indices.shape[-1]`. 18780The overall shape of `updates` is: 18781 18782``` 18783indices.shape[:-1] + tensor.shape[indices.shape[-1]:] 18784``` 18785 18786For usage examples see the python [tf.tensor_scatter_nd_update]( 18787https://www.tensorflow.org/api_docs/python/tf/tensor_scatter_nd_update) function 18788 }]; 18789 18790 let arguments = (ins 18791 Arg<TF_Tensor, [{Tensor to copy/update.}]>:$tensor, 18792 Arg<TensorOf<[TF_Int16, TF_Int32, TF_Int64, TF_Uint16]>, [{Index tensor.}]>:$indices, 18793 Arg<TF_Tensor, [{Updates to scatter into output.}]>:$updates 18794 ); 18795 18796 let results = (outs 18797 Res<TF_Tensor, [{A new tensor with the given shape and updates applied according 18798to the indices.}]>:$output 18799 ); 18800 18801 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 18802 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 18803 18804 let hasVerifier = 1; 18805 18806 let builders = [ 18807 OpBuilder<(ins "Value":$tensor, "Value":$indices, "Value":$updates), 18808 [{build($_builder, $_state, tensor.getType(), tensor, indices, updates);}]> 18809 ]; 18810} 18811 18812def TF_TensorSliceDatasetOp : TF_Op<"TensorSliceDataset", [NoSideEffect, TF_NoConstantFold]> { 18813 let summary = [{ 18814Creates a dataset that emits each dim-0 slice of `components` once. 18815 }]; 18816 18817 let arguments = (ins 18818 Variadic<TF_Tensor>:$components, 18819 18820 ConfinedAttr<TF_ShapeAttrArray, [ArrayMinCount<1>]>:$output_shapes, 18821 DefaultValuedAttr<BoolAttr, "false">:$is_files, 18822 DefaultValuedAttr<StrAttr, "\"\"">:$metadata, 18823 DefaultValuedAttr<BoolAttr, "false">:$replicate_on_split 18824 ); 18825 18826 let results = (outs 18827 TF_VariantTensor:$handle 18828 ); 18829 18830 TF_DerivedOperandTypeListAttr Toutput_types = TF_DerivedOperandTypeListAttr<0>; 18831} 18832 18833def TF_TensorStridedSliceUpdateOp : TF_Op<"TensorStridedSliceUpdate", [NoSideEffect]> { 18834 let summary = "Assign `value` to the sliced l-value reference of `input`."; 18835 18836 let description = [{ 18837The values of `value` are assigned to the positions in the tensor `input` that 18838are selected by the slice parameters. The slice parameters `begin` `end` 18839`strides` etc. work exactly as in `StridedSlice`. 18840 18841NOTE this op currently does not support broadcasting and so `value`'s shape 18842must be exactly the shape produced by the slice of `input`. 18843 }]; 18844 18845 let arguments = (ins 18846 TF_Tensor:$input, 18847 TF_I32OrI64Tensor:$begin, 18848 TF_I32OrI64Tensor:$end, 18849 TF_I32OrI64Tensor:$strides, 18850 TF_Tensor:$value, 18851 18852 DefaultValuedAttr<I64Attr, "0">:$begin_mask, 18853 DefaultValuedAttr<I64Attr, "0">:$end_mask, 18854 DefaultValuedAttr<I64Attr, "0">:$ellipsis_mask, 18855 DefaultValuedAttr<I64Attr, "0">:$new_axis_mask, 18856 DefaultValuedAttr<I64Attr, "0">:$shrink_axis_mask 18857 ); 18858 18859 let results = (outs 18860 TF_Tensor:$output 18861 ); 18862 18863 TF_DerivedOperandTypeAttr Index = TF_DerivedOperandTypeAttr<1>; 18864 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 18865} 18866 18867def TF_TileOp : TF_Op<"Tile", [NoSideEffect]> { 18868 let summary = "Constructs a tensor by tiling a given tensor."; 18869 18870 let description = [{ 18871This operation creates a new tensor by replicating `input` `multiples` times. 18872The output tensor's i'th dimension has `input.dims(i) * multiples[i]` elements, 18873and the values of `input` are replicated `multiples[i]` times along the 'i'th 18874dimension. For example, tiling `[a b c d]` by `[2]` produces 18875`[a b c d a b c d]`. 18876 18877>>> a = tf.constant([[1,2,3],[4,5,6]], tf.int32) 18878>>> b = tf.constant([1,2], tf.int32) 18879>>> tf.tile(a, b) 18880<tf.Tensor: shape=(2, 6), dtype=int32, numpy= 18881array([[1, 2, 3, 1, 2, 3], 18882 [4, 5, 6, 4, 5, 6]], dtype=int32)> 18883>>> c = tf.constant([2,1], tf.int32) 18884>>> tf.tile(a, c) 18885<tf.Tensor: shape=(4, 3), dtype=int32, numpy= 18886array([[1, 2, 3], 18887 [4, 5, 6], 18888 [1, 2, 3], 18889 [4, 5, 6]], dtype=int32)> 18890>>> d = tf.constant([2,2], tf.int32) 18891>>> tf.tile(a, d) 18892<tf.Tensor: shape=(4, 6), dtype=int32, numpy= 18893array([[1, 2, 3, 1, 2, 3], 18894 [4, 5, 6, 4, 5, 6], 18895 [1, 2, 3, 1, 2, 3], 18896 [4, 5, 6, 4, 5, 6]], dtype=int32)> 18897 }]; 18898 18899 let arguments = (ins 18900 Arg<TF_Tensor, [{1-D or higher.}]>:$input, 18901 Arg<TF_I32OrI64Tensor, [{1-D. Length must be the same as the number of dimensions in `input`}]>:$multiples 18902 ); 18903 18904 let results = (outs 18905 TF_Tensor:$output 18906 ); 18907 18908 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 18909 TF_DerivedOperandTypeAttr Tmultiples = TF_DerivedOperandTypeAttr<1>; 18910 18911 let hasVerifier = 1; 18912 18913 let hasFolder = 1; 18914} 18915 18916def TF_TimestampOp : TF_Op<"Timestamp", []> { 18917 let summary = "Provides the time since epoch in seconds."; 18918 18919 let description = [{ 18920Returns the timestamp as a `float64` for seconds since the Unix epoch. 18921 18922Note: the timestamp is computed when the op is executed, not when it is added 18923to the graph. 18924 }]; 18925 18926 let arguments = (ins); 18927 18928 let results = (outs 18929 TF_Float64Tensor:$ts 18930 ); 18931} 18932 18933def TF_TopKUniqueOp : TF_Op<"TopKUnique", [NoSideEffect]> { 18934 let summary = "Returns the TopK unique values in the array in sorted order."; 18935 18936 let description = [{ 18937The running time is proportional to the product of K and the input 18938size. Sorting the whole array is more efficient for sufficiently large 18939values of K. The median-of-medians algorithm is probably faster, but 18940difficult to implement efficiently in XLA. If there are fewer than K 18941unique numbers (not NANs), the results are padded with negative 18942infinity. NaNs are never returned. Subnormal numbers are flushed to 18943zero. If an element appears at multiple indices, the highest index is 18944returned. If a TopK element never appears in the input due to padding 18945values, the indices are padded with negative one. If a padding value 18946appears in the input and padding is needed, the highest index of the 18947padding value will be returned. The semantics are not the same as 18948kth_order_statistic. 18949 }]; 18950 18951 let arguments = (ins 18952 TF_Float32Tensor:$input, 18953 18954 I64Attr:$k 18955 ); 18956 18957 let results = (outs 18958 TF_Float32Tensor:$topk, 18959 TF_Int32Tensor:$topk_indices 18960 ); 18961} 18962 18963def TF_TopKV2Op : TF_Op<"TopKV2", [NoSideEffect]> { 18964 let summary = [{ 18965Finds values and indices of the `k` largest elements for the last dimension. 18966 }]; 18967 18968 let description = [{ 18969If the input is a vector (rank-1), finds the `k` largest entries in the vector 18970and outputs their values and indices as vectors. Thus `values[j]` is the 18971`j`-th largest entry in `input`, and its index is `indices[j]`. 18972 18973For matrices (resp. higher rank input), computes the top `k` entries in each 18974row (resp. vector along the last dimension). Thus, 18975 18976 values.shape = indices.shape = input.shape[:-1] + [k] 18977 18978If two elements are equal, the lower-index element appears first. 18979 }]; 18980 18981 let arguments = (ins 18982 Arg<TF_IntOrFpTensor, [{1-D or higher with last dimension at least `k`.}]>:$input, 18983 Arg<TF_Int32Tensor, [{0-D. Number of top elements to look for along the last dimension (along each 18984row for matrices).}]>:$k, 18985 18986 DefaultValuedAttr<BoolAttr, "true">:$sorted 18987 ); 18988 18989 let results = (outs 18990 Res<TF_IntOrFpTensor, [{The `k` largest elements along each last dimensional slice.}]>:$values, 18991 Res<TF_Int32Tensor, [{The indices of `values` within the last dimension of `input`.}]>:$indices 18992 ); 18993 18994 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 18995 18996 let hasVerifier = 1; 18997} 18998 18999def TF_TopKWithUniqueOp : TF_Op<"TopKWithUnique", [NoSideEffect]> { 19000 let summary = "Returns the TopK values in the array in sorted order."; 19001 19002 let description = [{ 19003This is a combination of MakeUnique and TopKUnique. The returned top-K will 19004have its lower bits replaced by iota, thus it will be close to the original 19005value but not exactly the same. The running time is proportional to the product 19006of K and the input size. NaNs are never returned. Subnormal numbers are flushed 19007to zero. 19008 }]; 19009 19010 let arguments = (ins 19011 TF_Float32Tensor:$input, 19012 19013 I64Attr:$k 19014 ); 19015 19016 let results = (outs 19017 TF_Float32Tensor:$topk, 19018 TF_Int32Tensor:$topk_indices 19019 ); 19020} 19021 19022def TF_TransposeOp : TF_Op<"Transpose", [NoSideEffect]> { 19023 let summary = "Shuffle dimensions of x according to a permutation."; 19024 19025 let description = [{ 19026The output `y` has the same rank as `x`. The shapes of `x` and `y` satisfy: 19027 `y.shape[i] == x.shape[perm[i]] for i in [0, 1, ..., rank(x) - 1]` 19028 }]; 19029 19030 let arguments = (ins 19031 TF_Tensor:$x, 19032 TF_I32OrI64Tensor:$perm 19033 ); 19034 19035 let results = (outs 19036 TF_Tensor:$y 19037 ); 19038 19039 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19040 TF_DerivedOperandTypeAttr Tperm = TF_DerivedOperandTypeAttr<1>; 19041 19042 let builders = [ 19043 OpBuilder<(ins "Value":$x, "Value":$perm)> 19044 ]; 19045 19046 let hasVerifier = 1; 19047 19048 let hasFolder = 1; 19049} 19050 19051def TF_TridiagonalMatMulOp : TF_Op<"TridiagonalMatMul", [NoSideEffect]> { 19052 let summary = "Calculate product with tridiagonal matrix."; 19053 19054 let description = [{ 19055Calculates product of two matrices, where left matrix is a tridiagonal matrix. 19056 }]; 19057 19058 let arguments = (ins 19059 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float32, TF_Float64]>, [{Tensor of shape `[..., 1, M]`, representing superdiagonals of 19060tri-diagonal matrices to the left of multiplication. Last element is ignored.}]>:$superdiag, 19061 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float32, TF_Float64]>, [{Tensor of shape `[..., 1, M]`, representing main diagonals of tri-diagonal 19062matrices to the left of multiplication.}]>:$maindiag, 19063 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float32, TF_Float64]>, [{Tensor of shape `[..., 1, M]`, representing subdiagonals of tri-diagonal 19064matrices to the left of multiplication. First element is ignored.}]>:$subdiag, 19065 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float32, TF_Float64]>, [{Tensor of shape `[..., M, N]`, representing MxN matrices to the right of 19066multiplication.}]>:$rhs 19067 ); 19068 19069 let results = (outs 19070 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float32, TF_Float64]>, [{Tensor of shape `[..., M, N]` containing the product.}]>:$output 19071 ); 19072 19073 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19074} 19075 19076def TF_TridiagonalSolveOp : TF_Op<"TridiagonalSolve", [NoSideEffect]> { 19077 let summary = "Solves tridiagonal systems of equations."; 19078 19079 let description = [{ 19080Solves tridiagonal systems of equations. 19081 Supports batch dimensions and multiple right-hand sides per each left-hand 19082 side. 19083 On CPU, solution is computed via Gaussian elimination with or without partial 19084 pivoting, depending on `partial_pivoting` attribute. On GPU, Nvidia's cuSPARSE 19085 library is used: https://docs.nvidia.com/cuda/cusparse/index.html#gtsv 19086 Partial pivoting is not yet supported by XLA backends. 19087 }]; 19088 19089 let arguments = (ins 19090 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float32, TF_Float64]>, [{Tensor of shape `[..., 3, M]` whose innermost 2 dimensions represent the 19091tridiagonal matrices with three rows being the superdiagonal, diagonals, and 19092subdiagonals, in order. The last element of the superdiagonal and the first 19093element of the subdiagonal is ignored.}]>:$diagonals, 19094 Arg<TensorOf<[TF_Complex128, TF_Complex64, TF_Float32, TF_Float64]>, [{Tensor of shape `[..., M, K]`, representing K right-hand sides per each 19095left-hand side.}]>:$rhs, 19096 19097 DefaultValuedAttr<BoolAttr, "true">:$partial_pivoting, 19098 DefaultValuedAttr<BoolAttr, "false">:$perturb_singular 19099 ); 19100 19101 let results = (outs 19102 Res<TensorOf<[TF_Complex128, TF_Complex64, TF_Float32, TF_Float64]>, [{Tensor of shape `[..., M, K]` containing the solutions}]>:$output 19103 ); 19104 19105 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19106} 19107 19108def TF_TruncateDivOp : TF_Op<"TruncateDiv", [NoSideEffect, ResultsBroadcastableShape]>, 19109 WithBroadcastableBinOpBuilder { 19110 let summary = "Returns x / y element-wise for integer types."; 19111 19112 let description = [{ 19113Truncation designates that negative numbers will round fractional quantities 19114toward zero. I.e. -7 / 5 = -1. This matches C semantics but it is different 19115than Python semantics. See `FloorDiv` for a division function that matches 19116Python Semantics. 19117 19118*NOTE*: `TruncateDiv` supports broadcasting. More about broadcasting 19119[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 19120 }]; 19121 19122 let arguments = (ins 19123 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$x, 19124 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$y 19125 ); 19126 19127 let results = (outs 19128 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$z 19129 ); 19130 19131 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19132 19133 let hasCanonicalizer = 1; 19134} 19135 19136def TF_TruncateModOp : TF_Op<"TruncateMod", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 19137 WithBroadcastableBinOpBuilder { 19138 let summary = [{ 19139Returns element-wise remainder of division. This emulates C semantics in that 19140 }]; 19141 19142 let description = [{ 19143the result here is consistent with a truncating divide. E.g. `truncate(x / y) * 19144y + truncate_mod(x, y) = x`. 19145 19146*NOTE*: `TruncateMod` supports broadcasting. More about broadcasting 19147[here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) 19148 }]; 19149 19150 let arguments = (ins 19151 TF_FpOrI32OrI64Tensor:$x, 19152 TF_FpOrI32OrI64Tensor:$y 19153 ); 19154 19155 let results = (outs 19156 TF_FpOrI32OrI64Tensor:$z 19157 ); 19158 19159 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19160} 19161 19162def TF_TruncatedNormalOp : TF_Op<"TruncatedNormal", [TF_CannotDuplicate]> { 19163 let summary = "Outputs random values from a truncated normal distribution."; 19164 19165 let description = [{ 19166The generated values follow a normal distribution with mean 0 and standard 19167deviation 1, except that values whose magnitude is more than 2 standard 19168deviations from the mean are dropped and re-picked. 19169 }]; 19170 19171 let arguments = (ins 19172 Arg<TF_I32OrI64Tensor, [{The shape of the output tensor.}]>:$shape, 19173 19174 DefaultValuedAttr<I64Attr, "0">:$seed, 19175 DefaultValuedAttr<I64Attr, "0">:$seed2 19176 ); 19177 19178 let results = (outs 19179 Res<TF_FloatTensor, [{A tensor of the specified shape filled with random truncated normal 19180values.}]>:$output 19181 ); 19182 19183 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19184 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 19185} 19186 19187def TF_UncompressElementOp : TF_Op<"UncompressElement", [NoSideEffect]> { 19188 let summary = "Uncompresses a compressed dataset element."; 19189 19190 let arguments = (ins 19191 TF_VariantTensor:$compressed 19192 ); 19193 19194 let results = (outs 19195 Variadic<TF_Tensor>:$components 19196 ); 19197 19198 TF_DerivedResultShapeListAttr output_shapes = TF_DerivedResultShapeListAttr<0>; 19199 TF_DerivedResultTypeListAttr output_types = TF_DerivedResultTypeListAttr<0>; 19200} 19201 19202def TF_UniqueOp : TF_Op<"Unique", [NoSideEffect]> { 19203 let summary = "Finds unique elements in a 1-D tensor."; 19204 19205 let description = [{ 19206This operation returns a tensor `y` containing all of the unique elements of `x` 19207sorted in the same order that they occur in `x`; `x` does not need to be sorted. 19208This operation also returns a tensor `idx` the same size as `x` that contains 19209the index of each value of `x` in the unique output `y`. In other words: 19210 19211`y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]` 19212 19213Examples: 19214 19215``` 19216# tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8] 19217y, idx = unique(x) 19218y ==> [1, 2, 4, 7, 8] 19219idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4] 19220``` 19221 19222``` 19223# tensor 'x' is [4, 5, 1, 2, 3, 3, 4, 5] 19224y, idx = unique(x) 19225y ==> [4, 5, 1, 2, 3] 19226idx ==> [0, 1, 2, 3, 4, 4, 0, 1] 19227``` 19228 }]; 19229 19230 let arguments = (ins 19231 Arg<TF_Tensor, [{1-D.}]>:$x 19232 ); 19233 19234 let results = (outs 19235 Res<TF_Tensor, [{1-D.}]>:$y, 19236 Res<TF_I32OrI64Tensor, [{1-D.}]>:$idx 19237 ); 19238 19239 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19240 TF_DerivedResultTypeAttr out_idx = TF_DerivedResultTypeAttr<1>; 19241} 19242 19243def TF_UnpackOp : TF_Op<"Unpack", [NoSideEffect]> { 19244 let summary = [{ 19245Unpacks a given dimension of a rank-`R` tensor into `num` rank-`(R-1)` tensors. 19246 }]; 19247 19248 let description = [{ 19249Unpacks `num` tensors from `value` by chipping it along the `axis` dimension. 19250For example, given a tensor of shape `(A, B, C, D)`; 19251 19252If `axis == 0` then the i'th tensor in `output` is the slice `value[i, :, :, :]` 19253 and each tensor in `output` will have shape `(B, C, D)`. (Note that the 19254 dimension unpacked along is gone, unlike `split`). 19255 19256If `axis == 1` then the i'th tensor in `output` is the slice `value[:, i, :, :]` 19257 and each tensor in `output` will have shape `(A, C, D)`. 19258Etc. 19259 19260This is the opposite of `pack`. 19261 }]; 19262 19263 let arguments = (ins 19264 Arg<TF_Tensor, [{1-D or higher, with `axis` dimension size equal to `num`.}]>:$value, 19265 19266 DefaultValuedAttr<I64Attr, "0">:$axis 19267 ); 19268 19269 let results = (outs 19270 Res<Variadic<TF_Tensor>, [{The list of tensors unpacked from `value`.}]>:$output 19271 ); 19272 19273 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19274 TF_DerivedResultSizeAttr num = TF_DerivedResultSizeAttr<0>; 19275 19276 let hasVerifier = 1; 19277 19278 let hasCanonicalizer = 1; 19279} 19280 19281def TF_UnsortedSegmentMaxOp : TF_Op<"UnsortedSegmentMax", [NoSideEffect]> { 19282 let summary = "Computes the maximum along segments of a tensor."; 19283 19284 let description = [{ 19285Read 19286[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 19287for an explanation of segments. 19288 19289This operator is similar to `tf.math.unsorted_segment_sum`, 19290Instead of computing the sum over segments, it computes the maximum such that: 19291 19292\\(output_i = \max_{j...} data[j...]\\) where max is over tuples `j...` such 19293that `segment_ids[j...] == i`. 19294 19295If the maximum is empty for a given segment ID `i`, it outputs the smallest 19296possible value for the specific numeric type, 19297`output[i] = numeric_limits<T>::lowest()`. 19298 19299If the given segment ID `i` is negative, then the corresponding value is 19300dropped, and will not be included in the result. 19301 19302Caution: On CPU, values in `segment_ids` are always validated to be less than 19303`num_segments`, and an error is thrown for out-of-bound indices. On GPU, this 19304does not throw an error for out-of-bound indices. On Gpu, out-of-bound indices 19305result in safe but unspecified behavior, which may include ignoring 19306out-of-bound indices or outputting a tensor with a 0 stored in the first 19307dimension of its shape if `num_segments` is 0. 19308 19309<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 19310<img style="width:100%" src="https://www.tensorflow.org/images/UnsortedSegmentMax.png" alt> 19311</div> 19312 19313For example: 19314 19315>>> c = tf.constant([[1,2,3,4], [5,6,7,8], [4,3,2,1]]) 19316>>> tf.math.unsorted_segment_max(c, tf.constant([0, 1, 0]), num_segments=2).numpy() 19317array([[4, 3, 3, 4], 19318 [5, 6, 7, 8]], dtype=int32) 19319 }]; 19320 19321 let arguments = (ins 19322 TF_IntOrFpTensor:$data, 19323 Arg<TF_I32OrI64Tensor, [{A tensor whose shape is a prefix of `data.shape`. 19324The values must be less than `num_segments`. 19325 19326Caution: The values are always validated to be in range on CPU, never validated 19327on GPU.}]>:$segment_ids, 19328 TF_I32OrI64Tensor:$num_segments 19329 ); 19330 19331 let results = (outs 19332 Res<TF_IntOrFpTensor, [{Has same shape as data, except for the first `segment_ids.rank` 19333dimensions, which are replaced with a single dimension which has size 19334`num_segments`.}]>:$output 19335 ); 19336 19337 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19338 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 19339 TF_DerivedOperandTypeAttr Tnumsegments = TF_DerivedOperandTypeAttr<2>; 19340 19341 let hasVerifier = 1; 19342} 19343 19344def TF_UnsortedSegmentMinOp : TF_Op<"UnsortedSegmentMin", [NoSideEffect]> { 19345 let summary = "Computes the minimum along segments of a tensor."; 19346 19347 let description = [{ 19348Read 19349[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 19350for an explanation of segments. 19351 19352This operator is similar to `tf.math.unsorted_segment_sum`, 19353Instead of computing the sum over segments, it computes the minimum such that: 19354 19355\\(output_i = \min_{j...} data_[j...]\\) where min is over tuples `j...` such 19356that `segment_ids[j...] == i`. 19357 19358If the minimum is empty for a given segment ID `i`, it outputs the largest 19359possible value for the specific numeric type, 19360`output[i] = numeric_limits<T>::max()`. 19361 19362For example: 19363 19364>>> c = tf.constant([[1,2,3,4], [5,6,7,8], [4,3,2,1]]) 19365>>> tf.math.unsorted_segment_min(c, tf.constant([0, 1, 0]), num_segments=2).numpy() 19366array([[1, 2, 2, 1], 19367 [5, 6, 7, 8]], dtype=int32) 19368 19369If the given segment ID `i` is negative, then the corresponding value is 19370dropped, and will not be included in the result. 19371 19372Caution: On CPU, values in `segment_ids` are always validated to be less than 19373`num_segments`, and an error is thrown for out-of-bound indices. On GPU, this 19374does not throw an error for out-of-bound indices. On Gpu, out-of-bound indices 19375result in safe but unspecified behavior, which may include ignoring 19376out-of-bound indices or outputting a tensor with a 0 stored in the first 19377dimension of its shape if `num_segments` is 0. 19378 }]; 19379 19380 let arguments = (ins 19381 TF_IntOrFpTensor:$data, 19382 Arg<TF_I32OrI64Tensor, [{A tensor whose shape is a prefix of `data.shape`. 19383The values must be less than `num_segments`. 19384 19385Caution: The values are always validated to be in range on CPU, never validated 19386on GPU.}]>:$segment_ids, 19387 TF_I32OrI64Tensor:$num_segments 19388 ); 19389 19390 let results = (outs 19391 Res<TF_IntOrFpTensor, [{Has same shape as data, except for the first `segment_ids.rank` 19392dimensions, which are replaced with a single dimension which has size 19393`num_segments`.}]>:$output 19394 ); 19395 19396 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19397 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 19398 TF_DerivedOperandTypeAttr Tnumsegments = TF_DerivedOperandTypeAttr<2>; 19399 19400 let hasVerifier = 1; 19401} 19402 19403def TF_UnsortedSegmentProdOp : TF_Op<"UnsortedSegmentProd", [NoSideEffect]> { 19404 let summary = "Computes the product along segments of a tensor."; 19405 19406 let description = [{ 19407Read 19408[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 19409for an explanation of segments. 19410 19411This operator is similar to `tf.math.unsorted_segment_sum`, 19412Instead of computing the sum over segments, it computes the product of all 19413entries belonging to a segment such that: 19414 19415\\(output_i = \prod_{j...} data[j...]\\) where the product is over tuples 19416`j...` such that `segment_ids[j...] == i`. 19417 19418For example: 19419 19420>>> c = tf.constant([[1,2,3,4], [5,6,7,8], [4,3,2,1]]) 19421>>> tf.math.unsorted_segment_prod(c, tf.constant([0, 1, 0]), num_segments=2).numpy() 19422array([[4, 6, 6, 4], 19423 [5, 6, 7, 8]], dtype=int32) 19424 19425If there is no entry for a given segment ID `i`, it outputs 1. 19426 19427If the given segment ID `i` is negative, then the corresponding value is 19428dropped, and will not be included in the result. 19429Caution: On CPU, values in `segment_ids` are always validated to be less than 19430`num_segments`, and an error is thrown for out-of-bound indices. On GPU, this 19431does not throw an error for out-of-bound indices. On Gpu, out-of-bound indices 19432result in safe but unspecified behavior, which may include ignoring 19433out-of-bound indices or outputting a tensor with a 0 stored in the first 19434dimension of its shape if `num_segments` is 0. 19435 }]; 19436 19437 let arguments = (ins 19438 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$data, 19439 Arg<TF_I32OrI64Tensor, [{A tensor whose shape is a prefix of `data.shape`. 19440The values must be less than `num_segments`. 19441 19442Caution: The values are always validated to be in range on CPU, never validated 19443on GPU.}]>:$segment_ids, 19444 TF_I32OrI64Tensor:$num_segments 19445 ); 19446 19447 let results = (outs 19448 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Has same shape as data, except for the first `segment_ids.rank` 19449dimensions, which are replaced with a single dimension which has size 19450`num_segments`.}]>:$output 19451 ); 19452 19453 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19454 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 19455 TF_DerivedOperandTypeAttr Tnumsegments = TF_DerivedOperandTypeAttr<2>; 19456 19457 let hasVerifier = 1; 19458} 19459 19460def TF_UnsortedSegmentSumOp : TF_Op<"UnsortedSegmentSum", [NoSideEffect]> { 19461 let summary = "Computes the sum along segments of a tensor."; 19462 19463 let description = [{ 19464Read 19465[the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation) 19466for an explanation of segments. 19467 19468Computes a tensor such that 19469\\(output[i] = \sum_{j...} data[j...]\\) where the sum is over tuples `j...` such 19470that `segment_ids[j...] == i`. Unlike `SegmentSum`, `segment_ids` 19471need not be sorted and need not cover all values in the full 19472range of valid values. 19473 19474If the sum is empty for a given segment ID `i`, `output[i] = 0`. 19475If the given segment ID `i` is negative, the value is dropped and will not be 19476added to the sum of the segment. 19477 19478`num_segments` should equal the number of distinct segment IDs. 19479 19480Caution: On CPU, values in `segment_ids` are always validated to be less than 19481`num_segments`, and an error is thrown for out-of-bound indices. On GPU, this 19482does not throw an error for out-of-bound indices. On Gpu, out-of-bound indices 19483result in safe but unspecified behavior, which may include ignoring 19484out-of-bound indices or outputting a tensor with a 0 stored in the first 19485dimension of its shape if `num_segments` is 0. 19486 19487<div style="width:70%; margin:auto; margin-bottom:10px; margin-top:20px;"> 19488<img style="width:100%" src="https://www.tensorflow.org/images/UnsortedSegmentSum.png" alt> 19489</div> 19490 19491>>> c = [[1,2,3,4], [5,6,7,8], [4,3,2,1]] 19492>>> tf.math.unsorted_segment_sum(c, [0, 1, 0], num_segments=2).numpy() 19493array([[5, 5, 5, 5], 19494 [5, 6, 7, 8]], dtype=int32) 19495 }]; 19496 19497 let arguments = (ins 19498 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$data, 19499 Arg<TF_I32OrI64Tensor, [{A tensor whose shape is a prefix of `data.shape`. 19500The values must be less than `num_segments`. 19501 19502Caution: The values are always validated to be in range on CPU, never validated 19503on GPU.}]>:$segment_ids, 19504 TF_I32OrI64Tensor:$num_segments 19505 ); 19506 19507 let results = (outs 19508 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Has same shape as data, except for the first `segment_ids.rank` 19509dimensions, which are replaced with a single dimension which has size 19510`num_segments`.}]>:$output 19511 ); 19512 19513 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19514 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 19515 TF_DerivedOperandTypeAttr Tnumsegments = TF_DerivedOperandTypeAttr<2>; 19516 19517 let hasVerifier = 1; 19518} 19519 19520def TF_UpperBoundOp : TF_Op<"UpperBound", [NoSideEffect]> { 19521 let summary = [{ 19522Applies upper_bound(sorted_search_values, values) along each row. 19523 }]; 19524 19525 let description = [{ 19526Each set of rows with the same index in (sorted_inputs, values) is treated 19527independently. The resulting row is the equivalent of calling 19528`np.searchsorted(sorted_inputs, values, side='right')`. 19529 19530The result is not a global index to the entire 19531`Tensor`, but rather just the index in the last dimension. 19532 19533A 2-D example: 19534 sorted_sequence = [[0, 3, 9, 9, 10], 19535 [1, 2, 3, 4, 5]] 19536 values = [[2, 4, 9], 19537 [0, 2, 6]] 19538 19539 result = UpperBound(sorted_sequence, values) 19540 19541 result == [[1, 2, 4], 19542 [0, 2, 5]] 19543 }]; 19544 19545 let arguments = (ins 19546 Arg<TF_Tensor, [{2-D Tensor where each row is ordered.}]>:$sorted_inputs, 19547 Arg<TF_Tensor, [{2-D Tensor with the same numbers of rows as `sorted_search_values`. Contains 19548the values that will be searched for in `sorted_search_values`.}]>:$values 19549 ); 19550 19551 let results = (outs 19552 Res<TF_I32OrI64Tensor, [{A `Tensor` with the same shape as `values`. It contains the last scalar index 19553into the last dimension where values can be inserted without changing the 19554ordered property.}]>:$output 19555 ); 19556 19557 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19558 TF_DerivedResultTypeAttr out_type = TF_DerivedResultTypeAttr<0>; 19559} 19560 19561def TF_VarIsInitializedOp : TF_Op<"VarIsInitializedOp", []> { 19562 let summary = [{ 19563Checks whether a resource handle-based variable has been initialized. 19564 }]; 19565 19566 let arguments = (ins 19567 Arg<TF_ResourceTensor, [{the input resource handle.}], [TF_VariableRead]>:$resource 19568 ); 19569 19570 let results = (outs 19571 Res<TF_BoolTensor, [{a scalar boolean which is true if the variable has been 19572initialized.}]>:$is_initialized 19573 ); 19574 19575 let hasCanonicalizer = 1; 19576} 19577 19578def TF_VariableOp : TF_Op<"Variable", []> { 19579 let summary = "Use VariableV2 instead."; 19580 19581 let arguments = (ins 19582 TF_ShapeAttr:$shape, 19583 DefaultValuedAttr<StrAttr, "\"\"">:$container, 19584 DefaultValuedAttr<StrAttr, "\"\"">:$shared_name 19585 ); 19586 19587 let results = (outs 19588 TF_Tensor:$ref 19589 ); 19590 19591 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 19592 19593 let hasCanonicalizer = 1; 19594} 19595 19596def TF_VariableShapeOp : TF_Op<"VariableShape", []> { 19597 let summary = "Returns the shape of the variable pointed to by `resource`."; 19598 19599 let description = [{ 19600This operation returns a 1-D integer tensor representing the shape of `input`. 19601 19602For example: 19603 19604``` 19605# 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]] 19606shape(t) ==> [2, 2, 3] 19607``` 19608 }]; 19609 19610 let arguments = (ins 19611 Arg<TF_ResourceTensor, "", [TF_VariableRead]>:$input 19612 ); 19613 19614 let results = (outs 19615 TF_I32OrI64Tensor:$output 19616 ); 19617 19618 TF_DerivedResultTypeAttr out_type = TF_DerivedResultTypeAttr<0>; 19619 19620 let hasVerifier = 1; 19621 19622 let hasFolder = 1; 19623} 19624 19625def TF_VariableV2Op : TF_Op<"VariableV2", []> { 19626 let summary = [{ 19627Holds state in the form of a tensor that persists across steps. 19628 }]; 19629 19630 let description = [{ 19631Outputs a ref to the tensor state so it may be read or modified. 19632TODO(zhifengc/mrry): Adds a pointer to a more detail document 19633about sharing states in tensorflow. 19634 }]; 19635 19636 let arguments = (ins 19637 TF_ShapeAttr:$shape, 19638 DefaultValuedAttr<StrAttr, "\"\"">:$container, 19639 DefaultValuedAttr<StrAttr, "\"\"">:$shared_name 19640 ); 19641 19642 let results = (outs 19643 Res<TF_Tensor, [{A reference to the variable tensor.}]>:$ref 19644 ); 19645 19646 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 19647} 19648 19649def TF_WhereOp : TF_Op<"Where", [NoSideEffect]> { 19650 let summary = "Returns locations of nonzero / true values in a tensor."; 19651 19652 let description = [{ 19653This operation returns the coordinates of true elements in `condition`. The 19654coordinates are returned in a 2-D tensor where the first dimension (rows) 19655represents the number of true elements, and the second dimension (columns) 19656represents the coordinates of the true elements. Keep in mind, the shape of 19657the output tensor can vary depending on how many true values there are in 19658`condition`. Indices are output in row-major order. 19659 19660For example: 19661 19662``` 19663# 'input' tensor is [[True, False] 19664# [True, False]] 19665# 'input' has two true values, so output has two coordinates. 19666# 'input' has rank of 2, so coordinates have two indices. 19667where(input) ==> [[0, 0], 19668 [1, 0]] 19669 19670# `condition` tensor is [[[True, False] 19671# [True, False]] 19672# [[False, True] 19673# [False, True]] 19674# [[False, False] 19675# [False, True]]] 19676# 'input' has 5 true values, so output has 5 coordinates. 19677# 'input' has rank of 3, so coordinates have three indices. 19678where(input) ==> [[0, 0, 0], 19679 [0, 1, 0], 19680 [1, 0, 1], 19681 [1, 1, 1], 19682 [2, 1, 1]] 19683 19684# `condition` tensor is [[[1.5, 0.0] 19685# [-0.5, 0.0]] 19686# [[0.0, 0.25] 19687# [0.0, 0.75]] 19688# [[0.0, 0.0] 19689# [0.0, 0.01]]] 19690# 'input' has 5 nonzero values, so output has 5 coordinates. 19691# 'input' has rank of 3, so coordinates have three indices. 19692where(input) ==> [[0, 0, 0], 19693 [0, 1, 0], 19694 [1, 0, 1], 19695 [1, 1, 1], 19696 [2, 1, 1]] 19697 19698# `condition` tensor is [[[1.5 + 0.0j, 0.0 + 0.0j] 19699# [0.0 + 0.5j, 0.0 + 0.0j]] 19700# [[0.0 + 0.0j, 0.25 + 1.5j] 19701# [0.0 + 0.0j, 0.75 + 0.0j]] 19702# [[0.0 + 0.0j, 0.0 + 0.0j] 19703# [0.0 + 0.0j, 0.01 + 0.0j]]] 19704# 'input' has 5 nonzero magnitude values, so output has 5 coordinates. 19705# 'input' has rank of 3, so coordinates have three indices. 19706where(input) ==> [[0, 0, 0], 19707 [0, 1, 0], 19708 [1, 0, 1], 19709 [1, 1, 1], 19710 [2, 1, 1]] 19711``` 19712 }]; 19713 19714 let arguments = (ins 19715 TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$input 19716 ); 19717 19718 let results = (outs 19719 TF_Int64Tensor:$index 19720 ); 19721 19722 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19723} 19724 19725def TF_XdivyOp : TF_Op<"Xdivy", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 19726 WithBroadcastableBinOpBuilder { 19727 let summary = "Returns 0 if x == 0, and x / y otherwise, elementwise."; 19728 19729 let arguments = (ins 19730 TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>:$x, 19731 TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>:$y 19732 ); 19733 19734 let results = (outs 19735 TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>:$z 19736 ); 19737 19738 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19739 19740 let hasCanonicalizer = 1; 19741} 19742 19743def TF_XlaAllReduceOp : TF_Op<"XlaAllReduce", [NoSideEffect, TF_NoConstantFold]> { 19744 let summary = "Wraps the XLA AllReduce operator"; 19745 19746 let description = [{ 19747documented at https://www.tensorflow.org/xla/operation_semantics#allreduce. 19748 }]; 19749 19750 let arguments = (ins 19751 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Int32, TF_Uint32]>, [{Array or a non-empty tuple of arrays to reduce across replicas.}]>:$input, 19752 Arg<TF_Int32Tensor, [{Groups between which the reductions are performed.}]>:$group_assignment, 19753 19754 TF_AnyStrAttrOf<["Min", "Max", "Mul", "Add", "Mean"]>:$reduce_op, 19755 TF_AnyStrAttrOf<["CrossReplica", "CrossReplicaAndPartition"]>:$mode 19756 ); 19757 19758 let results = (outs 19759 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Int32, TF_Uint32]>:$output 19760 ); 19761 19762 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19763} 19764 19765def TF_XlaBroadcastHelperOp : TF_Op<"XlaBroadcastHelper", [InferTensorType, NoSideEffect, TF_NoConstantFold]> { 19766 let summary = "Helper operator for performing XLA-style broadcasts"; 19767 19768 let description = [{ 19769Broadcasts `lhs` and `rhs` to the same rank, by adding size 1 dimensions to 19770whichever of `lhs` and `rhs` has the lower rank, using XLA's broadcasting rules 19771for binary operators. 19772 }]; 19773 19774 let arguments = (ins 19775 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the LHS input tensor}]>:$lhs, 19776 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the RHS input tensor}]>:$rhs, 19777 Arg<TF_I32OrI64Tensor, [{an XLA-style broadcast dimension specification}]>:$broadcast_dims 19778 ); 19779 19780 let results = (outs 19781 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the broadcasted LHS tensor}]>:$lhs_output, 19782 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the broadcasted RHS tensor}]>:$rhs_output 19783 ); 19784 19785 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19786 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<2>; 19787 19788 let extraClassDeclaration = [{ 19789 // InferTypeOpInterface: 19790 static bool isCompatibleReturnTypes(TypeRange l, TypeRange r) { 19791 return ArraysAreCastCompatible(l, r); 19792 } 19793 }]; 19794} 19795 19796def TF_XlaCallModuleOp : TF_Op<"XlaCallModule", [NoSideEffect]> { 19797 let summary = "Temporary op for experimenting with jax2tf."; 19798 19799 let description = [{ 19800DO NOT USE THIS OP. It has no backwards compatibility guarantees. It is also 19801very likely to change. This op will be used only in jax2tf under an 19802experimental flag. 19803 19804This is an experimental op to allow a smooth evolution of jax2tf towards 19805emitting and serializing MHLO directly from JAX. At the moment this op 19806carries a serialized MHLO module, therefore there are no backward-compatibility 19807guarantees, and should not be used for serialization. 19808Eventually, the op will carry a MHLO object, which will have 19809backwards-compatibility guarantees. 19810 19811The serialized module must return a tuple if and only if the Sout is an empty 19812list or a list with more than 1 elements. The length of Tout and Sout must 19813match. This op always returns a tuple of results, even if the module returns 19814a single result. 19815 19816The handling of dynamic shapes is work-in-progress. At the moment, the 19817JAX lowering for dynamic shapes will prepend one dimension parameter to the 19818serialized module for each dimension whose value must be passed in. 19819The "args" correspond to the non-dimension arguments. During compilation 19820we compute the values of the dimension arguments based on the static shapes of 19821the "args". In order to do this, we encode for each dimension argument a 19822specification of how to compute its value, as a string, in the form 19823"<arg_idx>.<axis_idx>". 19824E.g., the specification "2.1" denotes the value args[2].shape[1]. 19825 }]; 19826 19827 let arguments = (ins 19828 Arg<Variadic<TF_Tensor>, [{A list of `Tensor` with possibly different types to be passed as arguments 19829to the HLO module.}]>:$args, 19830 19831 StrAttr:$module, 19832 TF_ShapeAttrArray:$Sout, 19833 StrArrayAttr:$dim_args_spec 19834 ); 19835 19836 let results = (outs 19837 Variadic<TF_Tensor>:$output 19838 ); 19839 19840 TF_DerivedOperandTypeListAttr Tin = TF_DerivedOperandTypeListAttr<0>; 19841 TF_DerivedResultTypeListAttr Tout = TF_DerivedResultTypeListAttr<0>; 19842} 19843 19844def TF_XlaClusterOutputOp : TF_Op<"XlaClusterOutput", [NoSideEffect, TF_NoConstantFold]> { 19845 let summary = [{ 19846Operator that connects the output of an XLA computation to other consumer graph nodes. 19847 }]; 19848 19849 let arguments = (ins 19850 TF_Tensor:$input 19851 ); 19852 19853 let results = (outs 19854 TF_Tensor:$outputs 19855 ); 19856 19857 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19858} 19859 19860def TF_XlaConvOp : TF_Op<"XlaConv", [NoSideEffect, TF_NoConstantFold]> { 19861 let summary = "Wraps the XLA ConvGeneralDilated operator, documented at"; 19862 19863 let description = [{ 19864https://www.tensorflow.org/performance/xla/operation_semantics#conv_convolution 19865. 19866 }]; 19867 19868 let arguments = (ins 19869 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the input tensor}]>:$lhs, 19870 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the kernel tensor}]>:$rhs, 19871 Arg<TF_I32OrI64Tensor, [{the inter-window strides}]>:$window_strides, 19872 Arg<TF_I32OrI64Tensor, [{the padding to apply at the start and end of each input dimensions}]>:$padding, 19873 Arg<TF_I32OrI64Tensor, [{dilation to apply between input elements}]>:$lhs_dilation, 19874 Arg<TF_I32OrI64Tensor, [{dilation to apply between kernel elements}]>:$rhs_dilation, 19875 Arg<TF_I32OrI64Tensor, [{number of feature groups for grouped convolution.}]>:$feature_group_count, 19876 19877 StrAttr:$dimension_numbers, 19878 StrAttr:$precision_config 19879 ); 19880 19881 let results = (outs 19882 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$output 19883 ); 19884 19885 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19886 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<2>; 19887 19888 let hasCanonicalizer = 1; 19889} 19890 19891def TF_XlaConvV2Op : TF_Op<"XlaConvV2", [NoSideEffect, TF_NoConstantFold]> { 19892 let summary = "Wraps the XLA ConvGeneralDilated operator, documented at"; 19893 19894 let description = [{ 19895https://www.tensorflow.org/performance/xla/operation_semantics#conv_convolution 19896. 19897 }]; 19898 19899 let arguments = (ins 19900 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{input tensor}]>:$lhs, 19901 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{kernel tensor}]>:$rhs, 19902 Arg<TF_I32OrI64Tensor, [{inter-window strides}]>:$window_strides, 19903 Arg<TF_I32OrI64Tensor, [{padding to apply at the start and end of each input dimensions}]>:$padding, 19904 Arg<TF_I32OrI64Tensor, [{dilation to apply between input elements}]>:$lhs_dilation, 19905 Arg<TF_I32OrI64Tensor, [{dilation to apply between kernel elements}]>:$rhs_dilation, 19906 Arg<TF_I32OrI64Tensor, [{number of feature groups for grouped convolution.}]>:$feature_group_count, 19907 19908 StrAttr:$dimension_numbers, 19909 StrAttr:$precision_config, 19910 DefaultValuedAttr<I64Attr, "1">:$batch_group_count 19911 ); 19912 19913 let results = (outs 19914 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$output 19915 ); 19916 19917 TF_DerivedOperandTypeAttr LhsT = TF_DerivedOperandTypeAttr<0>; 19918 TF_DerivedOperandTypeAttr RhsT = TF_DerivedOperandTypeAttr<1>; 19919 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<2>; 19920 TF_DerivedResultTypeAttr preferred_element_type = TF_DerivedResultTypeAttr<0>; 19921 19922 let hasVerifier = 1; 19923} 19924 19925def TF_XlaDotOp : TF_Op<"XlaDot", [NoSideEffect, TF_NoConstantFold]> { 19926 let summary = "Wraps the XLA DotGeneral operator, documented at"; 19927 19928 let description = [{ 19929https://www.tensorflow.org/performance/xla/operation_semantics#dotgeneral 19930. 19931 }]; 19932 19933 let arguments = (ins 19934 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the LHS tensor}]>:$lhs, 19935 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the RHS tensor}]>:$rhs, 19936 19937 StrAttr:$dimension_numbers, 19938 StrAttr:$precision_config 19939 ); 19940 19941 let results = (outs 19942 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$output 19943 ); 19944 19945 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 19946} 19947 19948def TF_XlaDotV2Op : TF_Op<"XlaDotV2", [NoSideEffect, TF_NoConstantFold]> { 19949 let summary = "Wraps the XLA DotGeneral operator, documented at"; 19950 19951 let description = [{ 19952https://www.tensorflow.org/performance/xla/operation_semantics#dotgeneral 19953. 19954 }]; 19955 19956 let arguments = (ins 19957 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the LHS tensor}]>:$lhs, 19958 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the RHS tensor}]>:$rhs, 19959 19960 StrAttr:$dimension_numbers, 19961 StrAttr:$precision_config 19962 ); 19963 19964 let results = (outs 19965 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$output 19966 ); 19967 19968 TF_DerivedOperandTypeAttr LhsT = TF_DerivedOperandTypeAttr<0>; 19969 TF_DerivedOperandTypeAttr RhsT = TF_DerivedOperandTypeAttr<1>; 19970 TF_DerivedResultTypeAttr preferred_element_type = TF_DerivedResultTypeAttr<0>; 19971} 19972 19973def TF_XlaDynamicSliceOp : TF_Op<"XlaDynamicSlice", [NoSideEffect, TF_NoConstantFold]> { 19974 let summary = "Wraps the XLA DynamicSlice operator, documented at"; 19975 19976 let description = [{ 19977https://www.tensorflow.org/performance/xla/operation_semantics#dynamicslice 19978. 19979 19980DynamicSlice extracts a sub-array from the input array at dynamic 19981start_indices. The size of the slice in each dimension is passed in 19982size_indices, which specify the end point of exclusive slice intervals in each 19983dimension -- [start, start + size). The shape of start_indices must have rank 1, 19984with dimension size equal to the rank of operand. 19985 }]; 19986 19987 let arguments = (ins 19988 Arg<TF_Tensor, [{A `Tensor` of type T.}]>:$input, 19989 Arg<TF_I32OrI64Tensor, [{List of N integers containing the slice size for each 19990dimension. Each value must be strictly greater than zero, and start + size 19991must be less than or equal to the size of the dimension to avoid 19992implementation defined behavior.}]>:$start_indices, 19993 TF_I32OrI64Tensor:$size_indices 19994 ); 19995 19996 let results = (outs 19997 TF_Tensor:$output 19998 ); 19999 20000 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20001 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 20002} 20003 20004def TF_XlaDynamicUpdateSliceOp : TF_Op<"XlaDynamicUpdateSlice", [NoSideEffect, TF_NoConstantFold]> { 20005 let summary = "Wraps the XLA DynamicUpdateSlice operator, documented at"; 20006 20007 let description = [{ 20008https://www.tensorflow.org/performance/xla/operation_semantics#dynamicupdateslice 20009. 20010 20011XlaDynamicUpdateSlice generates a result which is the value of the `input` 20012operand, with a slice update overwritten at `indices`. The shape of `update` 20013determines the shape of the sub-array of the result which is updated. The shape 20014of indices must be rank == 1, with dimension size equal to the rank of `input`. 20015 20016Handling of out-of-bounds slice indices is implementation-defined. 20017 }]; 20018 20019 let arguments = (ins 20020 Arg<TF_Tensor, [{A `Tensor` of type T.}]>:$input, 20021 Arg<TF_Tensor, [{A `Tensor` of type T. Same rank as `input`.}]>:$update, 20022 Arg<TF_I32OrI64Tensor, [{A vector of indices into `input`. Must have length equal to the rank of 20023`input`.}]>:$indices 20024 ); 20025 20026 let results = (outs 20027 Res<TF_Tensor, [{A `Tensor` of type T.}]>:$output 20028 ); 20029 20030 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20031 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<2>; 20032} 20033 20034def TF_XlaEinsumOp : TF_Op<"XlaEinsum", [NoSideEffect, TF_NoConstantFold]> { 20035 let summary = [{ 20036An op which supports basic einsum op with 2 inputs and 1 output. 20037 }]; 20038 20039 let description = [{ 20040This op has better TPU performance since it doesn't have explicitly reshape and 20041transpose operations as tf.einsum does. 20042 }]; 20043 20044 let arguments = (ins 20045 TensorOf<[TF_Bfloat16, TF_Complex64, TF_Float32]>:$a, 20046 TensorOf<[TF_Bfloat16, TF_Complex64, TF_Float32]>:$b, 20047 20048 StrAttr:$equation 20049 ); 20050 20051 let results = (outs 20052 TensorOf<[TF_Bfloat16, TF_Complex64, TF_Float32]>:$product 20053 ); 20054 20055 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20056} 20057 20058def TF_XlaGatherOp : TF_Op<"XlaGather", [NoSideEffect, TF_NoConstantFold]> { 20059 let summary = "Wraps the XLA Gather operator documented at"; 20060 20061 let description = [{ 20062https://www.tensorflow.org/xla/operation_semantics#gather 20063 }]; 20064 20065 let arguments = (ins 20066 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The array we're gathering from.}]>:$operand, 20067 Arg<TF_I32OrI64Tensor, [{Array containing the starting indices of the slices we gather.}]>:$start_indices, 20068 Arg<TF_I32OrI64Tensor, [{slice_sizes[i] is the bounds for the slice on dimension i.}]>:$slice_sizes, 20069 20070 StrAttr:$dimension_numbers, 20071 BoolAttr:$indices_are_sorted 20072 ); 20073 20074 let results = (outs 20075 TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$output 20076 ); 20077 20078 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20079 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 20080} 20081 20082def TF_XlaKeyValueSortOp : TF_Op<"XlaKeyValueSort", [NoSideEffect, TF_NoConstantFold]> { 20083 let summary = "Wraps the XLA Sort operator, documented at"; 20084 20085 let description = [{ 20086https://www.tensorflow.org/performance/xla/operation_semantics#sort 20087. 20088 20089Sorts a tensor. Currently only sorts in ascending order are supported. 20090 }]; 20091 20092 let arguments = (ins 20093 Arg<TF_IntOrFpTensor, [{A `Tensor` of type K.}]>:$keys, 20094 Arg<TF_Tensor, [{A `Tensor` of type V.}]>:$values 20095 ); 20096 20097 let results = (outs 20098 Res<TF_IntOrFpTensor, [{A `Tensor` of type K.}]>:$sorted_keys, 20099 Res<TF_Tensor, [{A `Tensor` of type V.}]>:$sorted_values 20100 ); 20101 20102 TF_DerivedOperandTypeAttr K = TF_DerivedOperandTypeAttr<0>; 20103 TF_DerivedOperandTypeAttr V = TF_DerivedOperandTypeAttr<1>; 20104} 20105 20106def TF_XlaOptimizationBarrierOp : TF_Op<"XlaOptimizationBarrier", [NoSideEffect]> { 20107 let summary = "Wraps the XLA OptimizationBarrier operator."; 20108 20109 let description = [{ 20110Documented at https://www.tensorflow.org/xla/operation_semantics#optimizationbarrier. 20111 }]; 20112 20113 let arguments = (ins 20114 Arg<Variadic<TF_Tensor>, [{A Tuple of Arrays of any type.}]>:$input 20115 ); 20116 20117 let results = (outs 20118 Variadic<TF_Tensor>:$output 20119 ); 20120 20121 TF_DerivedOperandTypeListAttr T = TF_DerivedOperandTypeListAttr<0>; 20122} 20123 20124def TF_XlaPadOp : TF_Op<"XlaPad", [NoSideEffect, TF_NoConstantFold]> { 20125 let summary = "Wraps the XLA Pad operator, documented at"; 20126 20127 let description = [{ 20128https://www.tensorflow.org/performance/xla/operation_semantics#pad 20129. 20130 }]; 20131 20132 let arguments = (ins 20133 Arg<TF_Tensor, [{A `Tensor` of type T.}]>:$input, 20134 Arg<TF_Tensor, [{A scalar `Tensor` of type T.}]>:$padding_value, 20135 Arg<TF_I32OrI64Tensor, [{the padding to apply at the start of each input dimensions. Must 20136be a compile-time constant 1D tensor of length equal to rank of input.}]>:$padding_low, 20137 Arg<TF_I32OrI64Tensor, [{the padding to apply at the end of each input dimension. Must 20138be a compile-time constant 1D tensor of length equal to rank of input.}]>:$padding_high, 20139 Arg<TF_I32OrI64Tensor, [{the padding to apply between each input element. Must 20140be a compile-time constant 1D tensor of length equal to rank of input, 20141containing only non-negative values.}]>:$padding_interior 20142 ); 20143 20144 let results = (outs 20145 Res<TF_Tensor, [{A `Tensor` of type T.}]>:$output 20146 ); 20147 20148 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20149 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<2>; 20150} 20151 20152def TF_XlaRecvOp : TF_Op<"XlaRecv", [TF_RecvSideEffect]> { 20153 let summary = [{ 20154Receives the named tensor from another XLA computation. Wraps the XLA Recv 20155 }]; 20156 20157 let description = [{ 20158operator documented at 20159 https://www.tensorflow.org/performance/xla/operation_semantics#recv . 20160 }]; 20161 20162 let arguments = (ins 20163 StrAttr:$tensor_name, 20164 TF_ShapeAttr:$shape 20165 ); 20166 20167 let results = (outs 20168 Res<TF_Tensor, [{The tensor to receive.}]>:$tensor 20169 ); 20170 20171 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<0>; 20172} 20173 20174def TF_XlaRecvFromHostOp : TF_Op<"XlaRecvFromHost", [TF_RecvSideEffect]> { 20175 let summary = "An op to receive a tensor from the host."; 20176 20177 let description = [{ 20178output: the tensor that will be received from the host. 20179Toutput: element type for output. 20180shape: shape for output. 20181key: A unique identifier for this region used to match up host transfers. 20182 }]; 20183 20184 let arguments = (ins 20185 TF_ShapeAttr:$shape, 20186 StrAttr:$key 20187 ); 20188 20189 let results = (outs 20190 TF_Tensor:$output 20191 ); 20192 20193 TF_DerivedResultTypeAttr Toutput = TF_DerivedResultTypeAttr<0>; 20194} 20195 20196def TF_XlaRecvTPUEmbeddingActivationsOp : TF_Op<"XlaRecvTPUEmbeddingActivations", [TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 20197 let summary = "An op that receives embedding activations on the TPU."; 20198 20199 let description = [{ 20200The TPU system performs the embedding lookups and aggregations. The results of 20201these aggregations are visible to the Tensorflow Graph as the outputs of a 20202XlaRecvTPUEmbeddingActivations Op. This op returns a list containing one 20203Tensor of activations per table specified in the model. 20204 }]; 20205 20206 let arguments = (ins 20207 Arg<TF_VariantTensor, [{A Tensor with type=DT_VARIANT containing the deduplication 20208data. The tensor is an XLA nested tuple containing N elements (where N is 20209the ratio of the number of embedding to tensor cores per TPU chip). Each 20210element of the nested tuple is a tuple of rank 1 tensors. Each tensor either 20211contains indices (DT_UINT32) for embedding lookup on the TensorCore or 20212weights (DT_FLOAT) to apply to the output of the embedding lookup operation.}]>:$deduplication_data, 20213 20214 StrAttr:$config 20215 ); 20216 20217 let results = (outs 20218 Res<Variadic<TF_Float32Tensor>, [{A TensorList of embedding activations containing one Tensor per 20219embedding table in the model.}]>:$outputs 20220 ); 20221 20222 TF_DerivedResultSizeAttr num_tables = TF_DerivedResultSizeAttr<0>; 20223} 20224 20225def TF_XlaRecvTPUEmbeddingDeduplicationDataOp : TF_Op<"XlaRecvTPUEmbeddingDeduplicationData", []> { 20226 let summary = [{ 20227Receives deduplication data (indices and weights) from the embedding core. 20228 }]; 20229 20230 let description = [{ 20231The deduplication data is a Tensor with type=DT_VARIANT. The tensor itself is an 20232XLA nested tuple containing N elements (where N is the ratio of the number of 20233embedding to tensor cores per TPU chip). Each element of the nested tuple is a 20234tuple of rank 1 tensors. Each tensor either contains indices (DT_UINT32) for 20235embedding lookup on the TensorCore or weights (DT_FLOAT) to apply to the output 20236of the embedding lookup operation. 20237 }]; 20238 20239 let arguments = (ins 20240 StrAttr:$config 20241 ); 20242 20243 let results = (outs 20244 TF_VariantTensor:$output 20245 ); 20246} 20247 20248def TF_XlaReduceOp : TF_Op<"XlaReduce", [NoSideEffect]> { 20249 let summary = "Wraps the XLA Reduce operator, documented at"; 20250 20251 let description = [{ 20252https://www.tensorflow.org/performance/xla/operation_semantics#reduce . 20253 }]; 20254 20255 let arguments = (ins 20256 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the input tensor}]>:$input, 20257 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{a scalar representing the initial value for the reduction}]>:$init_value, 20258 20259 I64ArrayAttr:$dimensions_to_reduce, 20260 SymbolRefAttr:$reducer 20261 ); 20262 20263 let results = (outs 20264 TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$output 20265 ); 20266 20267 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20268 20269 let hasCanonicalizer = 1; 20270} 20271 20272def TF_XlaReducePrecisionOp : TF_Op<"XlaReducePrecision", [NoSideEffect]> { 20273 let summary = "Wraps the XLA ReducePrecision operator"; 20274 20275 let description = [{ 20276documented at https://www.tensorflow.org/xla/operation_semantics#reduceprecision. 20277 }]; 20278 20279 let arguments = (ins 20280 Arg<TF_FloatTensor, [{array of floating-point type.}]>:$operand, 20281 20282 I64Attr:$exponent_bits, 20283 I64Attr:$mantissa_bits 20284 ); 20285 20286 let results = (outs 20287 TF_FloatTensor:$output 20288 ); 20289 20290 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20291} 20292 20293def TF_XlaReduceScatterOp : TF_Op<"XlaReduceScatter", [NoSideEffect]> { 20294 let summary = "Wraps the XLA ReduceScatter operator"; 20295 20296 let description = [{ 20297documented at https://www.tensorflow.org/xla/operation_semantics#reducescatter. 20298 }]; 20299 20300 let arguments = (ins 20301 Arg<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Int32, TF_Uint32]>, [{Array or a non-empty tuple of arrays to reduce across replicas.}]>:$input, 20302 Arg<TF_Int32Tensor, [{Groups between which the reductions are performed.}]>:$group_assignment, 20303 Arg<TF_Int32Tensor, [{Dimension to scatter.}]>:$scatter_dimension, 20304 20305 TF_AnyStrAttrOf<["Min", "Max", "Mul", "Add", "Mean"]>:$reduce_op 20306 ); 20307 20308 let results = (outs 20309 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32, TF_Int32, TF_Uint32]>:$output 20310 ); 20311 20312 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20313} 20314 20315def TF_XlaReduceWindowOp : TF_Op<"XlaReduceWindow", [NoSideEffect]> { 20316 let summary = "Wraps the XLA ReduceWindow operator, documented at"; 20317 20318 let description = [{ 20319https://www.tensorflow.org/performance/xla/operation_semantics#reducewindow . 20320 }]; 20321 20322 let arguments = (ins 20323 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the input tensor}]>:$input, 20324 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{a scalar representing the initial value for the reduction}]>:$init_value, 20325 Arg<TF_I32OrI64Tensor, [{the shape of the window}]>:$window_dimensions, 20326 Arg<TF_I32OrI64Tensor, [{the inter-window strides}]>:$window_strides, 20327 TF_I32OrI64Tensor:$base_dilations, 20328 TF_I32OrI64Tensor:$window_dilations, 20329 Arg<TF_I32OrI64Tensor, [{the padding to apply at the start and end of each input dimensions}]>:$padding, 20330 20331 SymbolRefAttr:$computation 20332 ); 20333 20334 let results = (outs 20335 TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$output 20336 ); 20337 20338 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20339 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<2>; 20340 20341 let hasVerifier = 1; 20342} 20343 20344def TF_XlaRemoveDynamicDimensionSizeOp : TF_Op<"XlaRemoveDynamicDimensionSize", [NoSideEffect]> { 20345 let summary = "Inverse of XlaSetDynamicDimensionSize."; 20346 20347 let description = [{ 20348Make an xla bounded dynamic dimension into a static dimension. The bound of the 20349size of dimension `dim_index` becomes the static dimension size. 20350 }]; 20351 20352 let arguments = (ins 20353 TF_Tensor:$input, 20354 TF_Int32Tensor:$dim_index 20355 ); 20356 20357 let results = (outs 20358 TF_Tensor:$output 20359 ); 20360 20361 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20362} 20363 20364def TF_XlaReplicaIdOp : TF_Op<"XlaReplicaId", [NoSideEffect, TF_NoConstantFold]> { 20365 let summary = "Replica ID."; 20366 20367 let arguments = (ins); 20368 20369 let results = (outs 20370 TF_Int32Tensor:$id 20371 ); 20372 20373 // Constant folding is disabled for this op as it is a runtime op and can't 20374 // constant folded at the compile time. 20375} 20376 20377def TF_XlaRngBitGeneratorOp : TF_Op<"XlaRngBitGenerator", [NoSideEffect]> { 20378 let summary = "Stateless PRNG bit generator."; 20379 20380 let description = [{ 20381Wraps the XLA RngBitGenerator operator, documented at 20382 https://www.tensorflow.org/performance/xla/operation_semantics#rngbitgenerator. 20383 }]; 20384 20385 let arguments = (ins 20386 Arg<TF_Int32Tensor, [{The PRNG algorithm to use, one of 20387tf.random.Algorithm.{PHILOX, THREEFRY, AUTO_SELECT}.}]>:$algorithm, 20388 Arg<TF_Uint64Tensor, [{Initial state for the PRNG algorithm. For THREEFRY, it should be 20389a u64[2] and for PHILOX a u64[3].}]>:$initial_state, 20390 Arg<TF_I32OrI64Tensor, [{The output shape of the generated data.}]>:$shape 20391 ); 20392 20393 let results = (outs 20394 TF_Uint64Tensor:$output_key, 20395 TensorOf<[TF_Int32, TF_Int64, TF_Uint32, TF_Uint64]>:$output 20396 ); 20397 20398 TF_DerivedOperandTypeAttr Tshape = TF_DerivedOperandTypeAttr<2>; 20399 TF_DerivedResultTypeAttr dtype = TF_DerivedResultTypeAttr<1>; 20400} 20401 20402def TF_XlaScatterOp : TF_Op<"XlaScatter", [NoSideEffect]> { 20403 let summary = "Wraps the XLA Scatter operator documented at"; 20404 20405 let description = [{ 20406https://www.tensorflow.org/xla/operation_semantics#scatter. 20407 }]; 20408 20409 let arguments = (ins 20410 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Array to be scattered into.}]>:$operand, 20411 Arg<TF_I32OrI64Tensor, [{Array containing the starting indices of the slices that must 20412be scattered to.}]>:$scatter_indices, 20413 Arg<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Array containing the values that must be used for scattering.}]>:$updates, 20414 20415 SymbolRefAttr:$update_computation, 20416 StrAttr:$dimension_numbers, 20417 BoolAttr:$indices_are_sorted 20418 ); 20419 20420 let results = (outs 20421 TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$output 20422 ); 20423 20424 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20425 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 20426} 20427 20428def TF_XlaSelectAndScatterOp : TF_Op<"XlaSelectAndScatter", [NoSideEffect]> { 20429 let summary = "Wraps the XLA SelectAndScatter operator, documented at"; 20430 20431 let description = [{ 20432https://www.tensorflow.org/performance/xla/operation_semantics#selectandscatter 20433. 20434 }]; 20435 20436 let arguments = (ins 20437 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the input tensor}]>:$operand, 20438 Arg<TF_I32OrI64Tensor, [{the shape of the window}]>:$window_dimensions, 20439 Arg<TF_I32OrI64Tensor, [{the inter-window strides}]>:$window_strides, 20440 Arg<TF_I32OrI64Tensor, [{the padding to apply at the start and end of each input dimensions}]>:$padding, 20441 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{a tensor of values to scatter}]>:$source, 20442 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{a scalar representing the initial value for the output tensor}]>:$init_value, 20443 20444 SymbolRefAttr:$select, 20445 SymbolRefAttr:$scatter 20446 ); 20447 20448 let results = (outs 20449 TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>:$output 20450 ); 20451 20452 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20453 TF_DerivedOperandTypeAttr Tindices = TF_DerivedOperandTypeAttr<1>; 20454 20455 let hasVerifier = 1; 20456} 20457 20458def TF_XlaSelfAdjointEigOp : TF_Op<"XlaSelfAdjointEig", [NoSideEffect]> { 20459 let summary = [{ 20460Computes the eigen decomposition of a batch of self-adjoint matrices 20461 }]; 20462 20463 let description = [{ 20464(Note: Only real inputs are supported). 20465 20466Computes the eigenvalues and eigenvectors of the innermost N-by-N matrices in 20467tensor such that tensor[...,:,:] * v[..., :,i] = e[..., i] * v[...,:,i], for 20468i=0...N-1. 20469 }]; 20470 20471 let arguments = (ins 20472 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the input tensor.}]>:$a, 20473 20474 BoolAttr:$lower, 20475 I64Attr:$max_iter, 20476 F32Attr:$epsilon 20477 ); 20478 20479 let results = (outs 20480 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The eigenvalues in ascending order, each repeated according to its 20481multiplicity.}]>:$w, 20482 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{The column v[..., :, i] is the normalized eigenvector corresponding to the 20483eigenvalue w[..., i].}]>:$v 20484 ); 20485 20486 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20487} 20488 20489def TF_XlaSendOp : TF_Op<"XlaSend", [TF_SendSideEffect]> { 20490 let summary = [{ 20491Sends the named tensor to another XLA computation. Wraps the XLA Send operator 20492 }]; 20493 20494 let description = [{ 20495documented at 20496 https://www.tensorflow.org/performance/xla/operation_semantics#send . 20497 }]; 20498 20499 let arguments = (ins 20500 Arg<TF_Tensor, [{The tensor to send.}]>:$tensor, 20501 20502 StrAttr:$tensor_name 20503 ); 20504 20505 let results = (outs); 20506 20507 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20508} 20509 20510def TF_XlaSendTPUEmbeddingGradientsOp : TF_Op<"XlaSendTPUEmbeddingGradients", [AttrSizedOperandSegments, TF_MustExecute, TF_TPUEmbeddingReadEffect]> { 20511 let summary = "An op that performs gradient updates of embedding tables."; 20512 20513 let description = [{ 20514The gradients argument is a TensorList having the same length and shapes as the 20515return value of XlaRecvTPUEmbeddingActivations, but contains gradients of the 20516model's loss with respect to the embedding activations. The embedding tables are 20517updated from these gradients via the optimizer specified in the 20518TPUEmbeddingConfiguration proto given to tpu.initialize_system. 20519 }]; 20520 20521 let arguments = (ins 20522 Arg<Variadic<TF_Float32Tensor>, [{A TensorList of gradients with which to update embedding tables.}]>:$gradients, 20523 Arg<Variadic<TF_Float32Tensor>, [{A TensorList of learning rates used for updating the embedding 20524tables via the optimizer. The length of the TensorList must be equal to the 20525number of dynamic learning rate tags specified in the 20526TPUEmbeddingConfiguration proto.}]>:$learning_rates, 20527 Arg<TF_VariantTensor, [{A Tensor with type=DT_VARIANT containing the deduplication 20528data. The tensor is an XLA nested tuple containing N elements (where N is 20529the ratio of the number of embedding to tensor cores per TPU chip). Each 20530element of the nested tuple is a tuple of rank 1 tensors. Each tensor either 20531contains indices (DT_UINT32) for embedding lookup on the TensorCore or 20532weights (DT_FLOAT) to apply to the output of the embedding lookup operation.}]>:$deduplication_data, 20533 20534 StrAttr:$config 20535 ); 20536 20537 let results = (outs); 20538 20539 TF_DerivedOperandSizeAttr NumLearningRateTags = TF_DerivedOperandSizeAttr<1>; 20540 TF_DerivedOperandSizeAttr NumTables = TF_DerivedOperandSizeAttr<0>; 20541} 20542 20543def TF_XlaSendToHostOp : TF_Op<"XlaSendToHost", [TF_SendSideEffect]> { 20544 let summary = "An op to send a tensor to the host."; 20545 20546 let description = [{ 20547input: the tensor that will be sent to the host. 20548Tinput: element type for input. 20549key: A unique identifier for this region used to match up host transfers. 20550 }]; 20551 20552 let arguments = (ins 20553 TF_Tensor:$input, 20554 20555 StrAttr:$key 20556 ); 20557 20558 let results = (outs); 20559 20560 TF_DerivedOperandTypeAttr Tinput = TF_DerivedOperandTypeAttr<0>; 20561} 20562 20563def TF_XlaSetDynamicDimensionSizeOp : TF_Op<"XlaSetDynamicDimensionSize", [InferTensorType, NoSideEffect, TF_NoConstantFold]> { 20564 let summary = "Make a static dimension into a xla bounded dynamic dimension."; 20565 20566 let description = [{ 20567The current static dimension size will become the bound and the second 20568 operand becomes the dynamic size of the dimension. 20569 }]; 20570 20571 let arguments = (ins 20572 TF_Tensor:$input, 20573 TF_Int32Tensor:$dim_index, 20574 TF_Int32Tensor:$size 20575 ); 20576 20577 let results = (outs 20578 TF_Tensor:$output 20579 ); 20580 20581 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20582 20583 let extraClassDeclaration = [{ 20584 // InferTypeOpInterface: 20585 static bool isCompatibleReturnTypes(TypeRange l, TypeRange r) { 20586 return ArraysAreCastCompatible(l, r); 20587 } 20588 }]; 20589} 20590 20591def TF_XlaSortOp : TF_Op<"XlaSort", [NoSideEffect]> { 20592 let summary = "Wraps the XLA Sort operator, documented at"; 20593 20594 let description = [{ 20595https://www.tensorflow.org/performance/xla/operation_semantics#sort 20596. 20597 20598Sorts a tensor. Currently only sorts in ascending order are supported. 20599 }]; 20600 20601 let arguments = (ins 20602 Arg<TF_Tensor, [{A `Tensor` of type T.}]>:$input 20603 ); 20604 20605 let results = (outs 20606 Res<TF_Tensor, [{A `Tensor` of type T.}]>:$output 20607 ); 20608 20609 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20610} 20611 20612def TF_XlaSvdOp : TF_Op<"XlaSvd", [NoSideEffect]> { 20613 let summary = [{ 20614Computes the eigen decomposition of a batch of self-adjoint matrices 20615 }]; 20616 20617 let description = [{ 20618(Note: Only real inputs are supported). 20619 20620Computes the eigenvalues and eigenvectors of the innermost M-by-N matrices in 20621tensor such that tensor[...,:,:] = u[..., :, :] * Diag(s[..., :]) * Transpose(v[...,:,:]). 20622 }]; 20623 20624 let arguments = (ins 20625 Arg<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{the input tensor.}]>:$a, 20626 20627 I64Attr:$max_iter, 20628 F32Attr:$epsilon, 20629 StrAttr:$precision_config 20630 ); 20631 20632 let results = (outs 20633 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Singular values. The values are sorted in reverse order of magnitude, so 20634s[..., 0] is the largest value, s[..., 1] is the second largest, etc.}]>:$s, 20635 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Left singular vectors.}]>:$u, 20636 Res<TensorOf<[TF_Bfloat16, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>, [{Right singular vectors.}]>:$v 20637 ); 20638 20639 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20640} 20641 20642def TF_XlaVariadicReduceOp : TF_Op<"XlaVariadicReduce", [NoSideEffect, SameVariadicOperandSize]> { 20643 let summary = "Wraps the variadic XLA Reduce operator."; 20644 20645 let description = [{ 20646Semantics are documented at 20647 https://www.tensorflow.org/performance/xla/operation_semantics#variadic_reduce. 20648 20649This version is limited to operands of the same dtype. 20650XlaVariadicReduceV2 is a version that supports heterogeneous operands. 20651 }]; 20652 20653 let arguments = (ins 20654 Arg<Variadic<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>>, [{the input tensor(s)}]>:$input, 20655 Arg<Variadic<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>>, [{scalar initial value(s) for the reduction}]>:$init_value, 20656 20657 I64ArrayAttr:$dimensions_to_reduce, 20658 SymbolRefAttr:$reducer 20659 ); 20660 20661 let results = (outs 20662 Variadic<TensorOf<[TF_Bfloat16, TF_Bool, TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64, TF_Int16, TF_Int32, TF_Int64, TF_Int8, TF_Qint32, TF_Qint8, TF_Quint8, TF_Uint16, TF_Uint32, TF_Uint64, TF_Uint8]>>:$output 20663 ); 20664 20665 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 20666 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20667 20668 let hasVerifier = 1; 20669 20670 let hasCanonicalizer = 1; 20671} 20672 20673def TF_XlaVariadicReduceV2Op : TF_Op<"XlaVariadicReduceV2", [AttrSizedOperandSegments, NoSideEffect]> { 20674 let summary = "Wraps the variadic XLA Reduce operator."; 20675 20676 let description = [{ 20677Semantics are documented at 20678 https://www.tensorflow.org/performance/xla/operation_semantics#variadic_reduce. 20679 20680This is an expanded version of XlaVariadicReduce, with support for 20681operands of different dtypes, and improved shape inference. 20682 }]; 20683 20684 let arguments = (ins 20685 Arg<Variadic<TF_Tensor>, [{the input tensor(s)}]>:$inputs, 20686 Arg<Variadic<TF_Tensor>, [{scalar initial value(s) for the reduction}]>:$init_values, 20687 20688 I64ArrayAttr:$dimensions_to_reduce, 20689 SymbolRefAttr:$reducer 20690 ); 20691 20692 let results = (outs 20693 Variadic<TF_Tensor>:$outputs 20694 ); 20695 20696 TF_DerivedOperandTypeListAttr T = TF_DerivedOperandTypeListAttr<0>; 20697 20698 let hasVerifier = 1; 20699} 20700 20701def TF_XlaVariadicSortOp : TF_Op<"XlaVariadicSort", [NoSideEffect]> { 20702 let summary = "Wraps the XLA Sort operator, documented at"; 20703 20704 let description = [{ 20705https://www.tensorflow.org/performance/xla/operation_semantics#sort 20706. 20707 20708Sorts one or more tensors, with support for custom comparator, dimension, and 20709is_stable attributes. 20710 }]; 20711 20712 let arguments = (ins 20713 Arg<Variadic<TF_Tensor>, [{A list of `Tensor` of identical shape but possibly different types.}]>:$inputs, 20714 Arg<TF_Int32Tensor, [{The dimension along which to sort. Must be a compile-time constant.}]>:$dimension, 20715 20716 SymbolRefAttr:$comparator, 20717 BoolAttr:$is_stable 20718 ); 20719 20720 let results = (outs 20721 Res<Variadic<TF_Tensor>, [{A list of `Tensor` of same shape and types as the `input`.}]>:$outputs 20722 ); 20723 20724 TF_DerivedOperandTypeListAttr T = TF_DerivedOperandTypeListAttr<0>; 20725 20726 20727 let hasVerifier = 1; 20728} 20729 20730def TF_Xlog1pyOp : TF_Op<"Xlog1py", [NoSideEffect, TF_SameOperandsAndResultElementTypeResolveRef]> { 20731 let summary = "Returns 0 if x == 0, and x * log1p(y) otherwise, elementwise."; 20732 20733 let arguments = (ins 20734 TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>:$x, 20735 TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>:$y 20736 ); 20737 20738 let results = (outs 20739 TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>:$z 20740 ); 20741 20742 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20743} 20744 20745def TF_XlogyOp : TF_Op<"Xlogy", [NoSideEffect, ResultsBroadcastableShape, TF_SameOperandsAndResultElementTypeResolveRef]>, 20746 WithBroadcastableBinOpBuilder { 20747 let summary = "Returns 0 if x == 0, and x * log(y) otherwise, elementwise."; 20748 20749 let arguments = (ins 20750 TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>:$x, 20751 TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>:$y 20752 ); 20753 20754 let results = (outs 20755 TensorOf<[TF_Complex128, TF_Complex64, TF_Float16, TF_Float32, TF_Float64]>:$z 20756 ); 20757 20758 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20759} 20760 20761def TF_ZerosLikeOp : TF_Op<"ZerosLike", [Idempotent, NoSideEffect, SameOperandsAndResultType]> { 20762 let summary = "Returns a tensor of zeros with the same shape and type as x."; 20763 20764 let arguments = (ins 20765 Arg<TF_Tensor, [{a tensor of type T.}]>:$x 20766 ); 20767 20768 let results = (outs 20769 Res<TF_Tensor, [{a tensor of the same shape and type as x but filled with zeros.}]>:$y 20770 ); 20771 20772 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20773} 20774 20775def TF_ZetaOp : TF_Op<"Zeta", [NoSideEffect, ResultsBroadcastableShape]>, 20776 WithBroadcastableBinOpBuilder { 20777 let summary = [{ 20778Compute the Hurwitz zeta function \\(\zeta(x, q)\\). 20779 }]; 20780 20781 let description = [{ 20782The Hurwitz zeta function is defined as: 20783 20784 20785\\(\zeta(x, q) = \sum_{n=0}^{\infty} (q + n)^{-x}\\) 20786 }]; 20787 20788 let arguments = (ins 20789 TF_F32OrF64Tensor:$x, 20790 TF_F32OrF64Tensor:$q 20791 ); 20792 20793 let results = (outs 20794 TF_F32OrF64Tensor:$z 20795 ); 20796 20797 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20798} 20799 20800def TF__ArrayToListOp : TF_Op<"_ArrayToList", [NoSideEffect]> { 20801 let summary = "Converts an array of tensors to a list of tensors."; 20802 20803 let arguments = (ins 20804 Variadic<TF_Tensor>:$input 20805 ); 20806 20807 let results = (outs 20808 Variadic<TF_Tensor>:$output 20809 ); 20810 20811 TF_DerivedOperandSizeAttr N = TF_DerivedOperandSizeAttr<0>; 20812 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20813 TF_DerivedResultTypeListAttr out_types = TF_DerivedResultTypeListAttr<0>; 20814} 20815 20816def TF__EagerConstOp : TF_Op<"_EagerConst", [NoSideEffect]> { 20817 let summary = ""; 20818 20819 let arguments = (ins 20820 TF_Tensor:$input 20821 ); 20822 20823 let results = (outs 20824 TF_Tensor:$output 20825 ); 20826 20827 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20828} 20829 20830def TF__FusedBatchNormExOp : TF_Op<"_FusedBatchNormEx", [NoSideEffect]> { 20831 let summary = "Internal FusedBatchNorm operation: reserved for internal use."; 20832 20833 let description = [{ 20834Do not invoke this operator directly in Python. A fusion optimization is 20835expected to create these operators. 20836 }]; 20837 20838 let arguments = (ins 20839 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>:$x, 20840 TF_Float32Tensor:$scale, 20841 TF_Float32Tensor:$offset, 20842 TF_Float32Tensor:$mean, 20843 TF_Float32Tensor:$variance, 20844 Variadic<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>>:$side_input, 20845 20846 DefaultValuedAttr<F32Attr, "0.0001f">:$epsilon, 20847 DefaultValuedAttr<F32Attr, "1.0f">:$exponential_avg_factor, 20848 DefaultValuedAttr<StrAttr, "\"Identity\"">:$activation_mode, 20849 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 20850 DefaultValuedAttr<BoolAttr, "true">:$is_training 20851 ); 20852 20853 let results = (outs 20854 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>:$y, 20855 TF_Float32Tensor:$batch_mean, 20856 TF_Float32Tensor:$batch_variance, 20857 TF_Float32Tensor:$reserve_space_1, 20858 TF_Float32Tensor:$reserve_space_2, 20859 TF_Float32Tensor:$reserve_space_3 20860 ); 20861 20862 TF_DerivedOperandSizeAttr num_side_inputs = TF_DerivedOperandSizeAttr<5>; 20863 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20864 TF_DerivedOperandTypeAttr U = TF_DerivedOperandTypeAttr<1>; 20865} 20866 20867def TF__FusedConv2DOp : TF_Op<"_FusedConv2D", [NoSideEffect]> { 20868 let summary = [{ 20869Performs a convolution followed by a specified series of operations. 20870 }]; 20871 20872 let description = [{ 20873The inputs to the convolution are `input` and `filter`. The series of operations 20874that follows is specified by the `fused_ops` attribute, which is a list of TF op 20875names specified as strings (e.g. "Relu"). They are performed in order, where the 20876(first) input to each op is the output of the preceding op. The first input and 20877the output of each fused_op must be of type T. 20878 20879Currently supported fused_op combinations are: [X] and [X,A], where X is one of 20880{"BiasAdd","FusedBatchNorm"} and A is one of {"Elu","Relu","Relu6"}. 20881 20882* The first input to op X is the Conv2D result, and the additional input(s) to X 20883are specified by `args`. 20884* If there is an op A specified, the output of op X is the input to op A, and op 20885A produces the _FusedConv2D output. Otherwise, op X produces the _FusedConv2D 20886output. 20887 20888*NOTE*: Do not invoke this operator directly in Python. Grappler is expected to 20889create these operators. 20890 }]; 20891 20892 let arguments = (ins 20893 TensorOf<[TF_Float16, TF_Float32, TF_Float64]>:$input, 20894 TensorOf<[TF_Float16, TF_Float32, TF_Float64]>:$filter, 20895 Variadic<TensorOf<[TF_Float16, TF_Float32, TF_Float64]>>:$args, 20896 20897 I64ArrayAttr:$strides, 20898 TF_AnyStrAttrOf<["SAME", "VALID", "EXPLICIT"]>:$padding, 20899 DefaultValuedAttr<I64ArrayAttr, "{}">:$explicit_paddings, 20900 DefaultValuedAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format, 20901 DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1}">:$dilations, 20902 DefaultValuedAttr<BoolAttr, "true">:$use_cudnn_on_gpu, 20903 DefaultValuedAttr<StrArrayAttr, "{}">:$fused_ops, 20904 DefaultValuedAttr<F32Attr, "0.0001f">:$epsilon, 20905 DefaultValuedAttr<F32Attr, "0.2f">:$leakyrelu_alpha 20906 ); 20907 20908 let results = (outs 20909 TensorOf<[TF_Float16, TF_Float32, TF_Float64]>:$output 20910 ); 20911 20912 TF_DerivedOperandSizeAttr num_args = TF_DerivedOperandSizeAttr<2>; 20913 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20914} 20915 20916def TF__FusedMatMulOp : TF_Op<"_FusedMatMul", [NoSideEffect, TF_SameOperandsAndResultElementTypeResolveRef]> { 20917 let summary = [{ 20918Performs a MatMul followed by a specified series of operations. 20919 }]; 20920 20921 let description = [{ 20922The inputs to the MatMul are specified by `a` and `b`. The series of operations 20923that follows is specified by the `fused_ops` attribute, which is a list of TF op 20924names specified as strings (e.g. "Relu"). They are performed in order, where the 20925(first) input to each op is the output of the preceding op. The first input and 20926the output of each fused_op must be of type T. 20927 20928Currently supported fused_op combinations are: ["BiasAdd"] and ["BiasAdd",A], 20929where A is one of {"Elu","Relu","Relu6"}. 20930 20931* The first input to BiasAdd is the MatMul result, and the additional BiasAdd 20932input is specified by `args`. 20933* If there is an op A specified, the output of the BiasAdd is the input to op A, 20934and op A produces the _FusedConv2D output. Otherwise, the BiasAdd produces the 20935_FusedConv2D output. 20936 20937*NOTE*: Do not invoke this operator directly in Python. Grappler is 20938expected to create these operators. 20939 }]; 20940 20941 let arguments = (ins 20942 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>:$a, 20943 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>:$b, 20944 Variadic<TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>>:$args, 20945 20946 DefaultValuedAttr<BoolAttr, "false">:$transpose_a, 20947 DefaultValuedAttr<BoolAttr, "false">:$transpose_b, 20948 DefaultValuedAttr<StrArrayAttr, "{}">:$fused_ops, 20949 DefaultValuedAttr<F32Attr, "0.0001f">:$epsilon, 20950 DefaultValuedAttr<F32Attr, "0.2f">:$leakyrelu_alpha 20951 ); 20952 20953 let results = (outs 20954 TensorOf<[TF_Bfloat16, TF_Float16, TF_Float32]>:$product 20955 ); 20956 20957 TF_DerivedOperandSizeAttr num_args = TF_DerivedOperandSizeAttr<2>; 20958 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 20959} 20960 20961def TF__HostRecvOp : TF_Op<"_HostRecv", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, TF_RecvSideEffect]> { 20962 let summary = "Receives the named tensor from send_device on recv_device."; 20963 20964 let description = [{ 20965_HostRecv produces its output on host memory whereas _Recv produces its 20966output on device memory. 20967 }]; 20968 20969 let arguments = (ins 20970 StrAttr:$tensor_name, 20971 StrAttr:$send_device, 20972 I64Attr:$send_device_incarnation, 20973 StrAttr:$recv_device, 20974 DefaultValuedAttr<BoolAttr, "false">:$client_terminated 20975 ); 20976 20977 let results = (outs 20978 Res<TF_Tensor, [{The tensor to receive.}]>:$tensor 20979 ); 20980 20981 TF_DerivedResultTypeAttr tensor_type = TF_DerivedResultTypeAttr<0>; 20982} 20983 20984def TF__HostSendOp : TF_Op<"_HostSend", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, TF_SendSideEffect]> { 20985 let summary = "Sends the named tensor from send_device to recv_device."; 20986 20987 let description = [{ 20988_HostSend requires its input on host memory whereas _Send requires its 20989input on device memory. 20990 }]; 20991 20992 let arguments = (ins 20993 Arg<TF_Tensor, [{The tensor to send.}]>:$tensor, 20994 20995 StrAttr:$tensor_name, 20996 StrAttr:$send_device, 20997 I64Attr:$send_device_incarnation, 20998 StrAttr:$recv_device, 20999 DefaultValuedAttr<BoolAttr, "false">:$client_terminated 21000 ); 21001 21002 let results = (outs); 21003 21004 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 21005} 21006 21007def TF__ListToArrayOp : TF_Op<"_ListToArray", [NoSideEffect]> { 21008 let summary = "Converts a list of tensors to an array of tensors."; 21009 21010 let arguments = (ins 21011 Variadic<TF_Tensor>:$input 21012 ); 21013 21014 let results = (outs 21015 Variadic<TF_Tensor>:$output 21016 ); 21017 21018 TF_DerivedOperandTypeListAttr Tin = TF_DerivedOperandTypeListAttr<0>; 21019 TF_DerivedResultSizeAttr N = TF_DerivedResultSizeAttr<0>; 21020 TF_DerivedResultTypeAttr T = TF_DerivedResultTypeAttr<0>; 21021} 21022 21023def TF__RecvOp : TF_Op<"_Recv", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, TF_RecvSideEffect]> { 21024 let summary = "Receives the named tensor from send_device on recv_device."; 21025 21026 let arguments = (ins 21027 StrAttr:$tensor_name, 21028 StrAttr:$send_device, 21029 I64Attr:$send_device_incarnation, 21030 StrAttr:$recv_device, 21031 DefaultValuedAttr<BoolAttr, "false">:$client_terminated 21032 ); 21033 21034 let results = (outs 21035 Res<TF_Tensor, [{The tensor to receive.}]>:$tensor 21036 ); 21037 21038 TF_DerivedResultTypeAttr tensor_type = TF_DerivedResultTypeAttr<0>; 21039} 21040 21041def TF__SendOp : TF_Op<"_Send", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, TF_SendSideEffect]> { 21042 let summary = "Sends the named tensor from send_device to recv_device."; 21043 21044 let arguments = (ins 21045 Arg<TF_Tensor, [{The tensor to send.}]>:$tensor, 21046 21047 StrAttr:$tensor_name, 21048 StrAttr:$send_device, 21049 I64Attr:$send_device_incarnation, 21050 StrAttr:$recv_device, 21051 DefaultValuedAttr<BoolAttr, "false">:$client_terminated 21052 ); 21053 21054 let results = (outs); 21055 21056 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 21057} 21058 21059def TF__TPUCompileMlirOp : TF_Op<"_TPUCompileMlir", [TF_MustExecute]> { 21060 let summary = [{ 21061Compiles a computations for execution on one or more TPU devices. 21062 }]; 21063 21064 let description = [{ 21065For the internal use of the distributed TPU compiler. 21066 21067'mlir_module' is a serialized MLIR module with a `main` function that contains 21068target computation. 21069'dynamic_shapes' contains dynamic shapes of arguments whose shapes were not 21070known statically at TPUReplication rewrite time. 21071'metadata' is a serialized TPUCompileMetadataProto describing the shapes and 21072types of the inputs to the computation, as well as a mapping onto the TPU pod 21073topology. 21074'program' output is a string key that is passed to the TPUExecute op and used to 21075look up the program in the compilation cache. 21076 }]; 21077 21078 let arguments = (ins 21079 Variadic<TF_Int64Tensor>:$dynamic_shapes, 21080 21081 DefaultValuedAttr<StrAttr, "\"\"">:$mlir_module, 21082 StrAttr:$metadata 21083 ); 21084 21085 let results = (outs 21086 TF_StrTensor:$compilation_status, 21087 Variadic<TF_StrTensor>:$program 21088 ); 21089 21090 TF_DerivedOperandSizeAttr NumDynamicShapes = TF_DerivedOperandSizeAttr<0>; 21091 TF_DerivedResultSizeAttr num_computations = TF_DerivedResultSizeAttr<1>; 21092} 21093 21094def TF__TPUCompileMlirPlaceholderProgramKeyOp : TF_Op<"_TPUCompileMlirPlaceholderProgramKey", [TF_MustExecute]> { 21095 let summary = [{ 21096Placeholder program key (compilation cache key) of a _TPUCompileMlir `program`. 21097 }]; 21098 21099 let description = [{ 21100This op can be used when certain rewrite passes materialize ops that require a 21101program key but the _TPUCompileMlir op has not been added yet. Subsequent 21102rewrite passes must replace this op with a _TPUCompileMlir op `program` output. 21103 }]; 21104 21105 let arguments = (ins); 21106 21107 let results = (outs 21108 TF_StrTensor:$program 21109 ); 21110} 21111 21112def TF__UnaryOpsCompositionOp : TF_Op<"_UnaryOpsComposition", [NoSideEffect, TF_SameOperandsAndResultTypeResolveRef]> { 21113 let summary = [{ 21114*NOTE*: Do not invoke this operator directly in Python. Graph rewrite pass is 21115 }]; 21116 21117 let description = [{ 21118expected to create these operators. 21119 }]; 21120 21121 let arguments = (ins 21122 TensorOf<[TF_Float16, TF_Float32, TF_Float64]>:$x, 21123 21124 StrArrayAttr:$op_names 21125 ); 21126 21127 let results = (outs 21128 TensorOf<[TF_Float16, TF_Float32, TF_Float64]>:$y 21129 ); 21130 21131 TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>; 21132} 21133 21134def TF__XlaHostComputeMlirOp : TF_Op<"_XlaHostComputeMlir", [TF_RecvSideEffect, TF_SendSideEffect, TF_XlaHostComputeSideEffect]> { 21135 let summary = [{ 21136A pseudo-op to represent host-side computation in an XLA program. 21137 }]; 21138 21139 let arguments = (ins 21140 Arg<Variadic<TF_Tensor>, [{A list of tensors that will be sent to the host.}]>:$inputs, 21141 21142 StrAttr:$send_key, 21143 StrAttr:$recv_key, 21144 DefaultValuedAttr<StrAttr, "\"\"">:$host_mlir_module 21145 ); 21146 21147 let results = (outs 21148 Res<Variadic<TF_Tensor>, [{A list of tensors that will be returned to the device.}]>:$outputs 21149 ); 21150 21151 TF_DerivedOperandTypeListAttr Tinputs = TF_DerivedOperandTypeListAttr<0>; 21152 TF_DerivedResultTypeListAttr Toutputs = TF_DerivedResultTypeListAttr<0>; 21153 21154 let extraClassDeclaration = [{ 21155 func::FuncOp GetHostFunc(mlir::OwningOpRef<mlir::ModuleOp>* mlir_module); 21156 }]; 21157 21158 let hasVerifier = 1; 21159} 21160 21161def TF__XlaRecvAtHostOp : TF_Op<"_XlaRecvAtHost", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, TF_RecvSideEffect]> { 21162 let summary = [{ 21163A placeholder op to receive values from a running XLA computation. 21164 }]; 21165 21166 let arguments = (ins 21167 Arg<TF_StrTensor, [{The key sent at runtime by the compile node to identify which 21168execution the transfer corresponds to.}]>:$dynamic_key, 21169 21170 StrAttr:$key, 21171 I64Attr:$device_ordinal 21172 ); 21173 21174 let results = (outs 21175 Res<Variadic<TF_Tensor>, [{A list of tensors that will be received from the XLA computation.}]>:$outputs 21176 ); 21177 21178 TF_DerivedResultTypeListAttr Toutputs = TF_DerivedResultTypeListAttr<0>; 21179} 21180 21181def TF__XlaRecvAtHostV2Op : TF_Op<"_XlaRecvAtHostV2", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, TF_RecvSideEffect]> { 21182 let summary = [{ 21183A placeholder op to receive values from a running XLA computation with support for a runtime device ordinal. 21184 }]; 21185 21186 let arguments = (ins 21187 Arg<TF_StrTensor, [{The key sent at runtime by the compile node to identify which 21188execution the transfer corresponds to.}]>:$dynamic_key, 21189 Arg<TF_Int64Tensor, [{The device id relative to the associated host device.}]>:$device_ordinal, 21190 21191 StrAttr:$key 21192 ); 21193 21194 let results = (outs 21195 Res<Variadic<TF_Tensor>, [{A list of tensors that will be received from the XLA computation.}]>:$outputs 21196 ); 21197 21198 TF_DerivedResultTypeListAttr Toutputs = TF_DerivedResultTypeListAttr<0>; 21199} 21200 21201def TF__XlaSendFromHostOp : TF_Op<"_XlaSendFromHost", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, TF_SendSideEffect]> { 21202 let summary = "A placeholder op to send values to a running XLA computation."; 21203 21204 let arguments = (ins 21205 Arg<Variadic<TF_Tensor>, [{A list of tensors that will be sent to the XLA computation.}]>:$inputs, 21206 Arg<TF_StrTensor, [{The key sent at runtime by the compile node to identify which 21207execution the transfer corresponds to.}]>:$dynamic_key, 21208 21209 StrAttr:$key, 21210 I64Attr:$device_ordinal 21211 ); 21212 21213 let results = (outs); 21214 21215 TF_DerivedOperandTypeListAttr Tinputs = TF_DerivedOperandTypeListAttr<0>; 21216} 21217 21218def TF__XlaSendFromHostV2Op : TF_Op<"_XlaSendFromHostV2", [DeclareOpInterfaceMethods<TF_GetResourceInstanceInterface>, TF_SendSideEffect]> { 21219 let summary = [{ 21220A placeholder op to send values to a running XLA computation with support for a runtime device ordinal. 21221 }]; 21222 21223 let arguments = (ins 21224 Arg<Variadic<TF_Tensor>, [{A list of tensors that will be sent to the XLA computation.}]>:$inputs, 21225 Arg<TF_StrTensor, [{The key sent at runtime by the compile node to identify which 21226execution the transfer corresponds to.}]>:$dynamic_key, 21227 Arg<TF_Int64Tensor, [{The device id relative to the associated host device.}]>:$device_ordinal, 21228 21229 StrAttr:$key 21230 ); 21231 21232 let results = (outs); 21233 21234 TF_DerivedOperandTypeListAttr Tinputs = TF_DerivedOperandTypeListAttr<0>; 21235} 21236
{kind=link}
{kind=link}
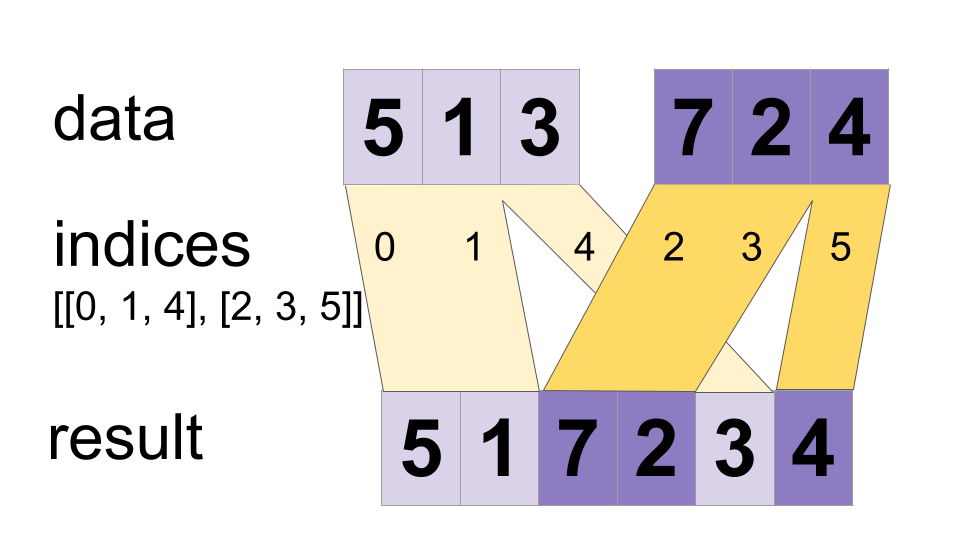{kind=link}
{kind=link}
{kind=link}
{kind=link}
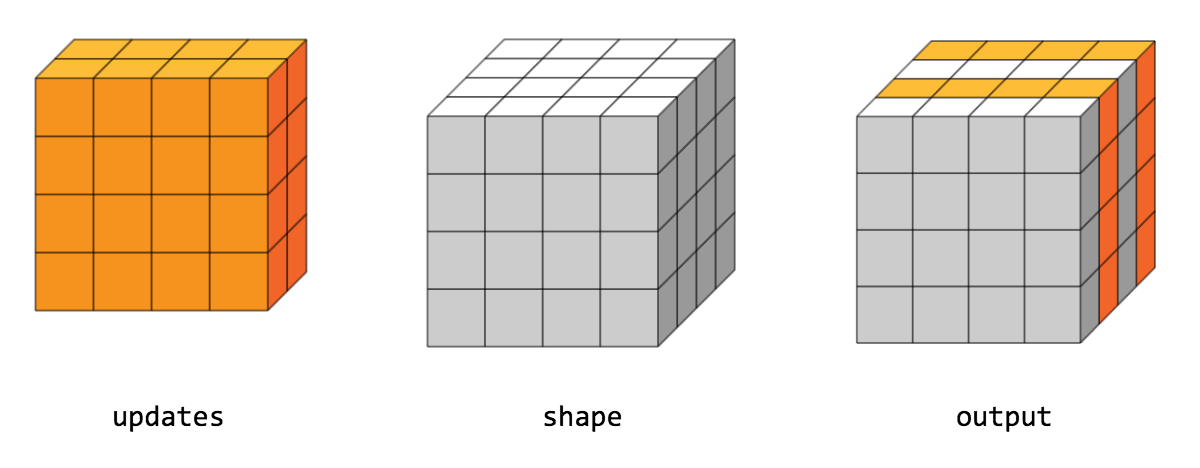{kind=link}
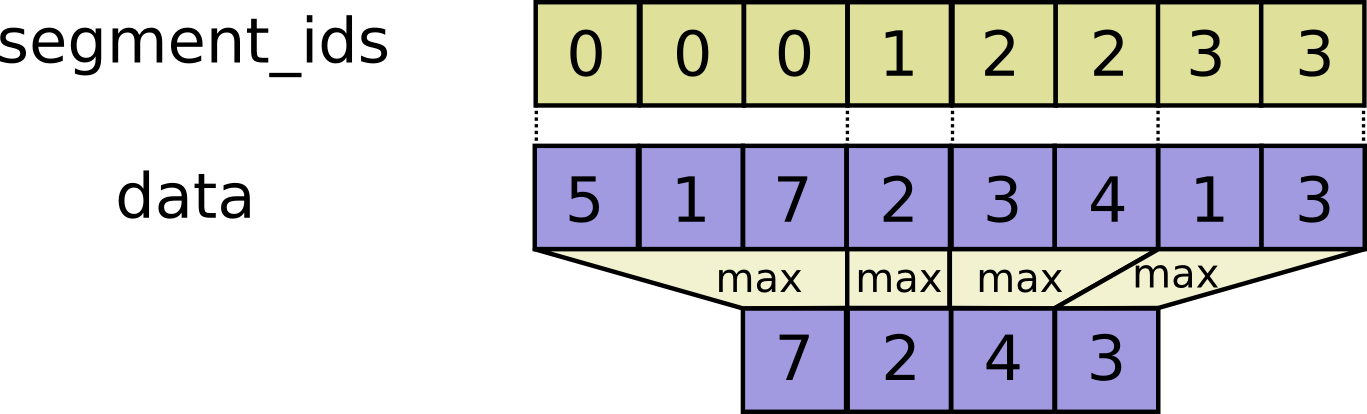{kind=link}
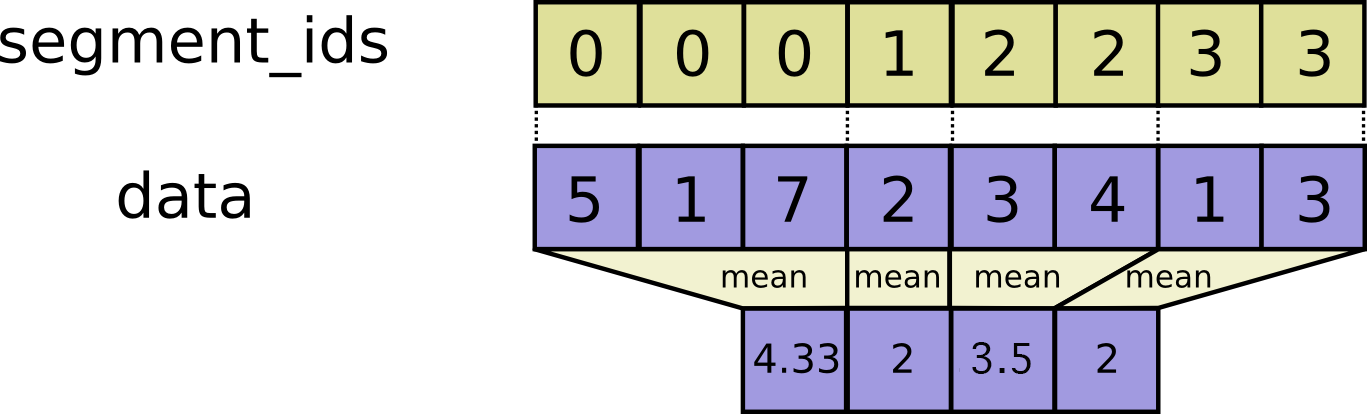{kind=link}
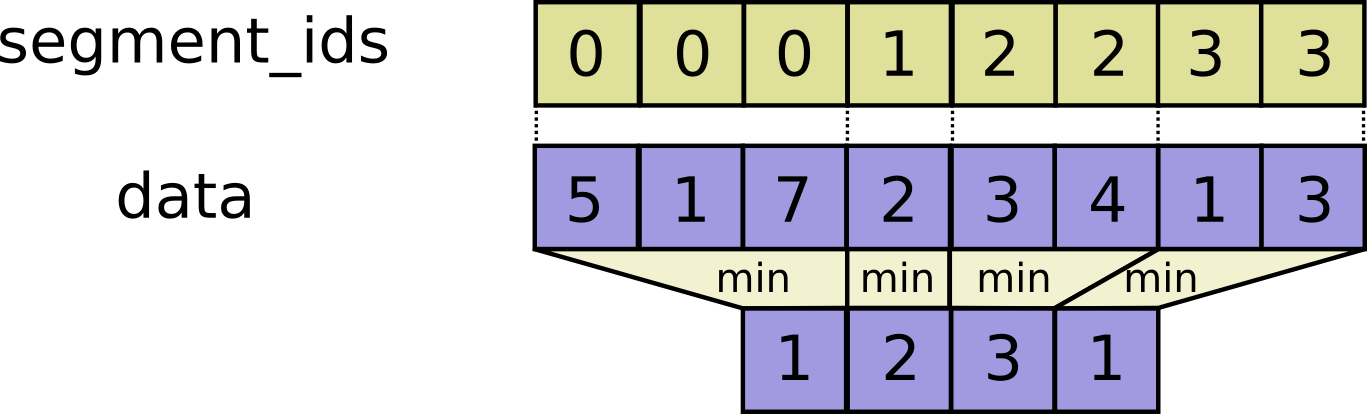{kind=link}
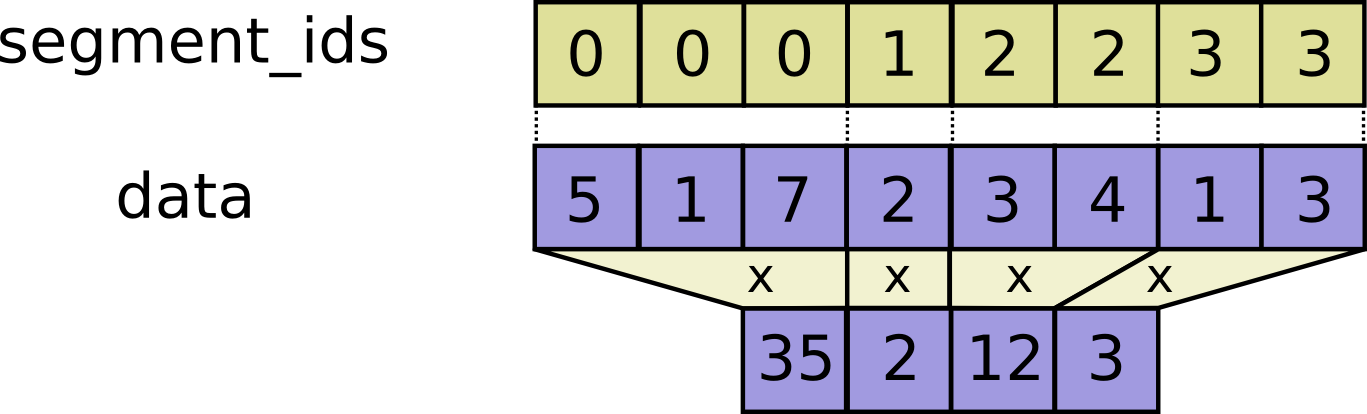{kind=link}
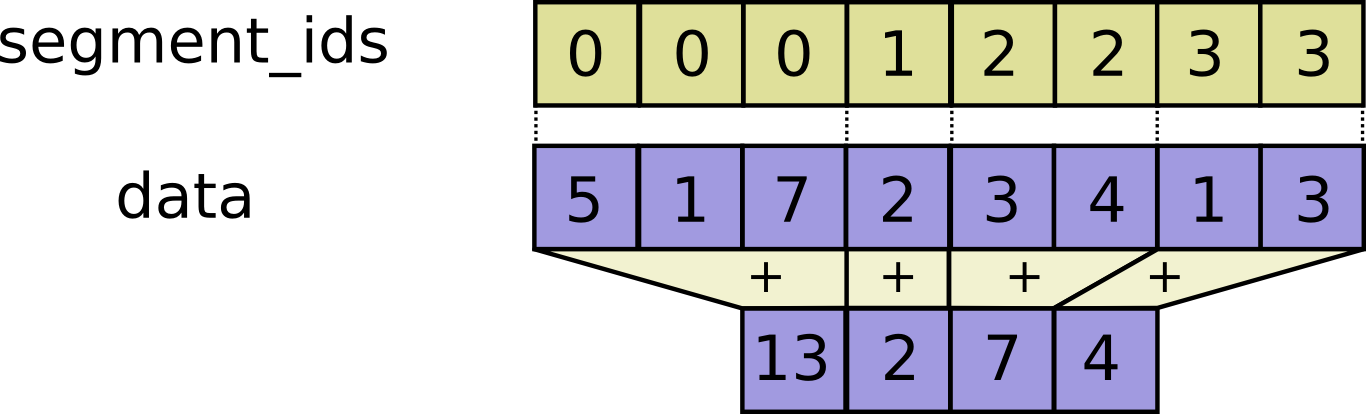{kind=link}
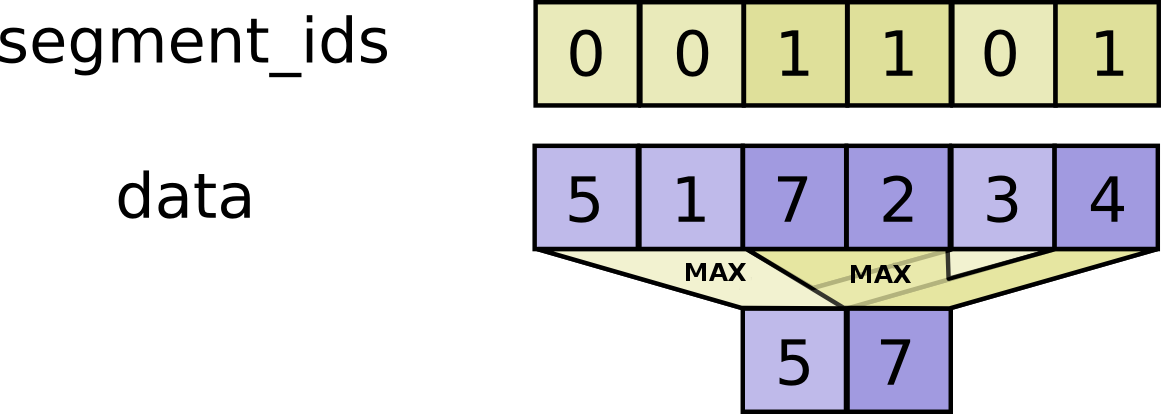{kind=link}
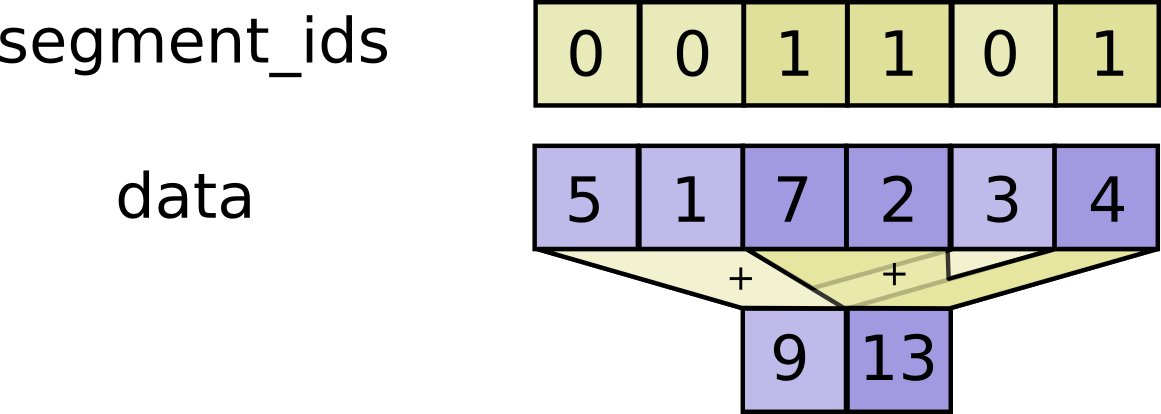{kind=link}